
How Can We Help?
5.1.05.1.0
We are pleased to announce that version 5.1.0 (4.20.0) of Pure is now released.
Always read through the release notes before installing or upgrading to a new version of Pure. In particular, pay attention to the section "Before installing or upgrading" - failure to adhering to this, may result in loss of functionality.
Released date: 01.10.2014
Before Installing or Upgrading
Java 8 support: As of version 5.1.0 (4.20.0), Pure requires Java 8. This means that, as part of the update to 5.1.0 (4.20.0) a newer version of Java must be installed. Guide for Java upgrade is available here Upgrade Java for Pure
Note for deploying on AAU, SDU and UC The student project portal was previously called student-portal. In the release the web application for this portal was therefore also called student-portal. This has changed and the portal application is now distributed as "portal-student". If you deploy this application using its default name the application URL will change unless the tomcat (or apache) is configured to expose the new "portal-student" under the old name http://server/student-portal"
Run analyse on the database after the upgrade: after each upgrade of Pure, you should run a analysing command on your database, this can be done while Pure is running, and will insure that the performance of Pure stays as good as possible. If you have a maintenance agreement, we will do this as part of the upgrade. The command to execute this depends on the database type:MS SQL:exec sp_updatestats;Oracle: exec dbms_stats.gather_schema_stats(null, null, degree=>2, cascade=>true, force=>true);PostgreSQL: vacuum analyze;
Reindex a full reindex is need after upgrade to make sure all new search functionalities is working as intended
Future changes
Internet Explorer 8 (IE8) will not be supported in Pure from version 5.3/4.22 and forward:
As of version 5.3/4.22 of Pure, which will be released in June 2015, Pure will no longer support IE8. IE8 users will from Pure version 5.2/4.21 (to be release February 2015) be meet with a warning about this in the interface. Users can choose to hide the warning for a month, after which the warning will be shown again. In Pure version 5.1/4.20 there will be no warning.
Tomcat 7 will not be supported in Pure from version 5.2/4.21 and forward:
As of version 5.2.0/4.21.0 of Pure, Tomcat 8 is required.
Integration with SciVal
Feature name: Integration with SciVal. Analysis of publication sets and metrics
Roles affected: All
Feature purpose: Connect Pure with SciVal for those customers that have both products.
Feature description:
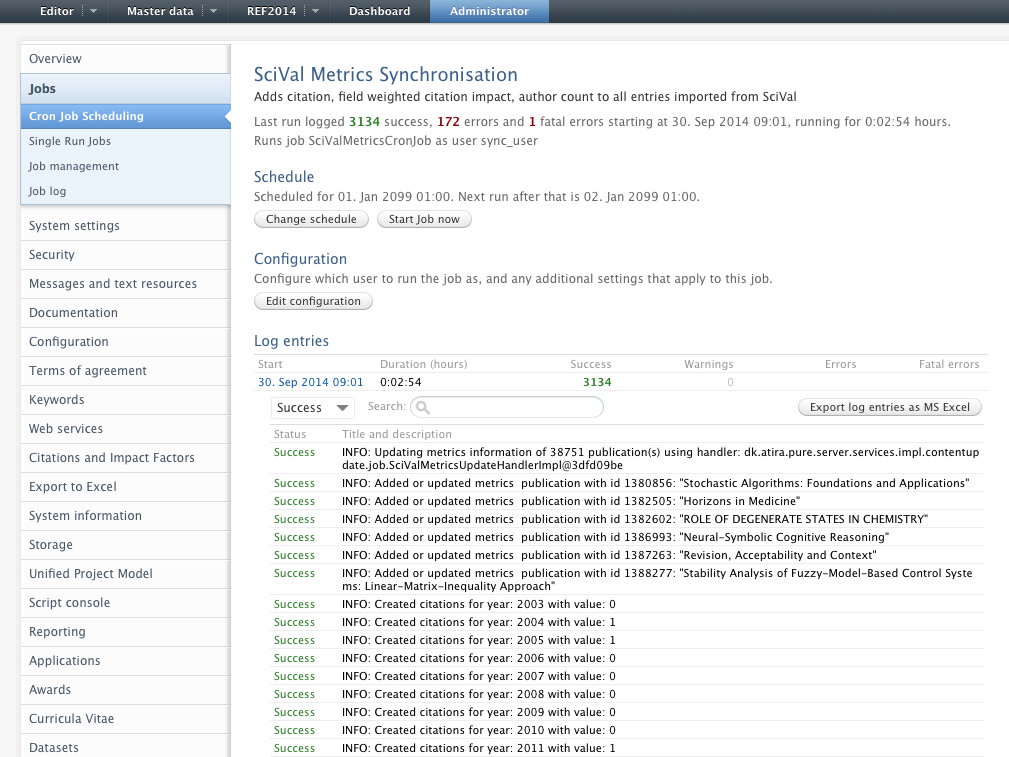
Two functionalities were added in this feature:
- SciVal has a function where users can create their own publication sets for analysis.
It is now possible to initiate the creation of such a publication set from within Pure.
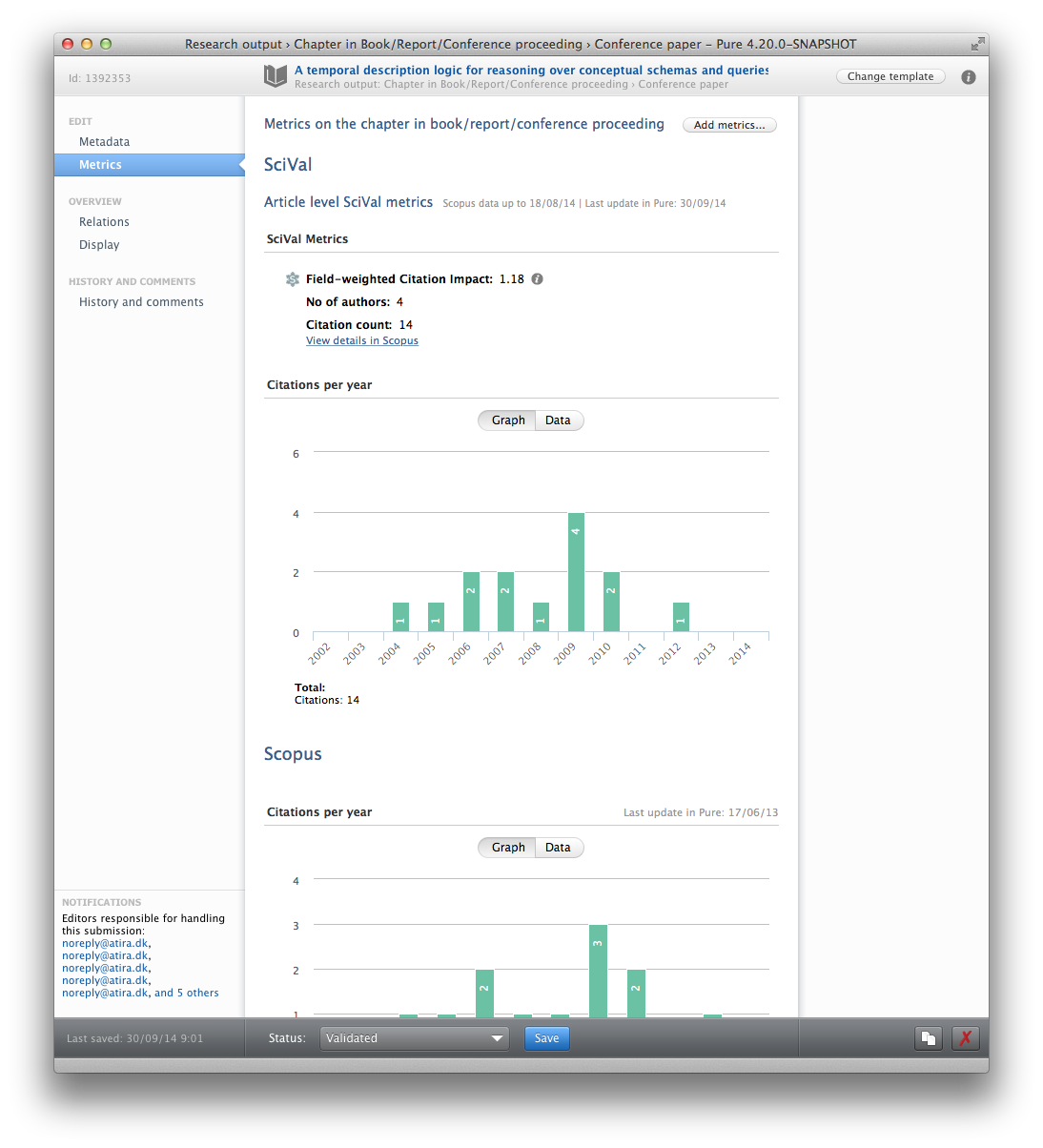
This is done either from the main content list or from within the relation tab of project, person and organisation editors. - Pure can now import the following publication metrics from SciVal
- Author count
- Total citations
- Field-Weighted Citation Impact (FWCI) actual citation count relative to the expected world citation count. See full description in the Snowball Metrics Recipe Book
- Citations divided by year.
With this feature citations can be imported both from SciVal and Scopus. When using SciVal as a source you should consider not using Scopus as they will represent the same metrics but be updated in at different intervals.
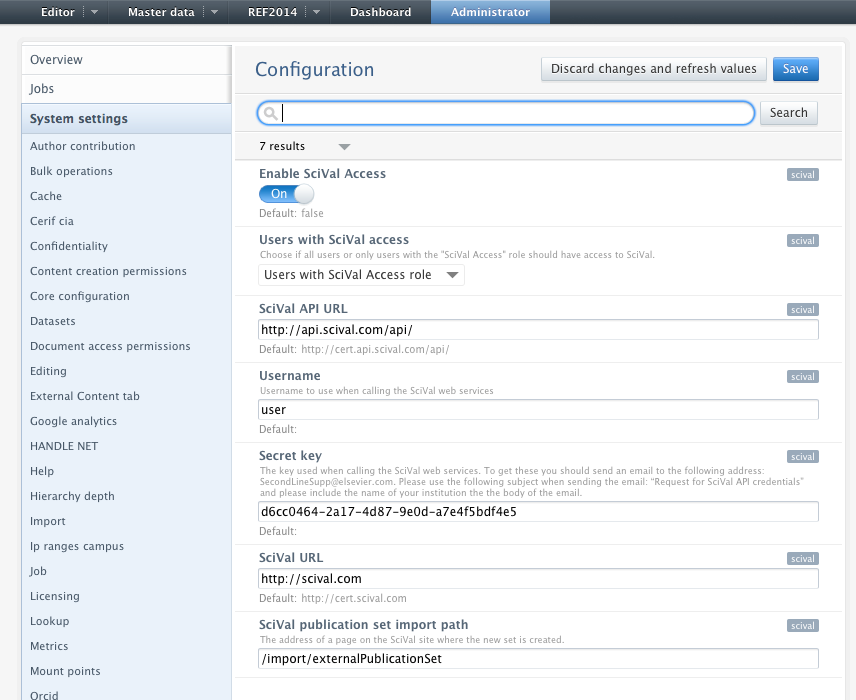
To use the metric import feature the job needs to be configured with credentials for accessing SciVal. To get these you should send an email to the following address: SecondLineSupp@elsevier.com
Please use the following subject when sending the email: “Request for SciVal API credentials” and please include the name of your institution the the body of the email.
Screenshots:
 |
 |
 |
Search
Roles affected: All
Feature purpose: Improve quality of text based searches in pure
Feature description: The search subsystem has undergone a major overhaul for 5.1 to improve the search result quality. The result scoring algorithm has been changed from TD/IDF to OkapiBM25 with field level weights. The index now also contains improved support for CJK characters to ensure most asian languages are properly handled.
Index structure
Each content object is now indexed into 3 buckets:
Primary field: Title / name elements
Secondary field: Content metadata (abstract, author names etc.)
Tertiary field: Contents of full text files.
At search time all 3 fields are searched, but with varying weights. Terms that are matched in the primary field rank higher than matches in the secondary or tertiary fields.
Search / Query changes
One of the major changes is how users enter searches. Previously pure used the raw lucene query syntax (see http://lucene.apache.org/core/4_9_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#package_description) which was error-prone if the query was complex or could not be parsed by lucene (which resulted in no matches found).
The changes to the query parsing applies to both portal and the admin back end (See note on "Searching in portal")
The new query parser is more simple but will always execute the search. The new parser supports the following kinds of searches:
|
Search for all words
|
To search for all content that must contain all of the defined words, you simply write the words that must be matched. The example below will match all content that contains the words computer and science
|
|
Search for an exact word or phrase
|
Use quotes to search for an exact word or set of words in content. This is helpful when searching for titles or quotes in a text. But only use this if you're looking for an exact word or phrase, otherwise you'll exclude many helpful results by mistake.
|
|
Exclude a word
|
Add a dash (
|
|
Fill in the blank
|
Add an asterisk within a search as a placeholder for any unknown or wildcard terms. You cannot write an asterisk in front of a token - i.e. *ter is an invalid
|
|
Search for either word
|
If you want to search for content that may have just one of several words, include
|
Advanced users can still use the full Lucene query syntax if they pre-pend their search string with '^', but this should generally no longer be needed.
In the back end, the general search field has been improved with a advanced search drop down designed to help users learn to use the various query options:
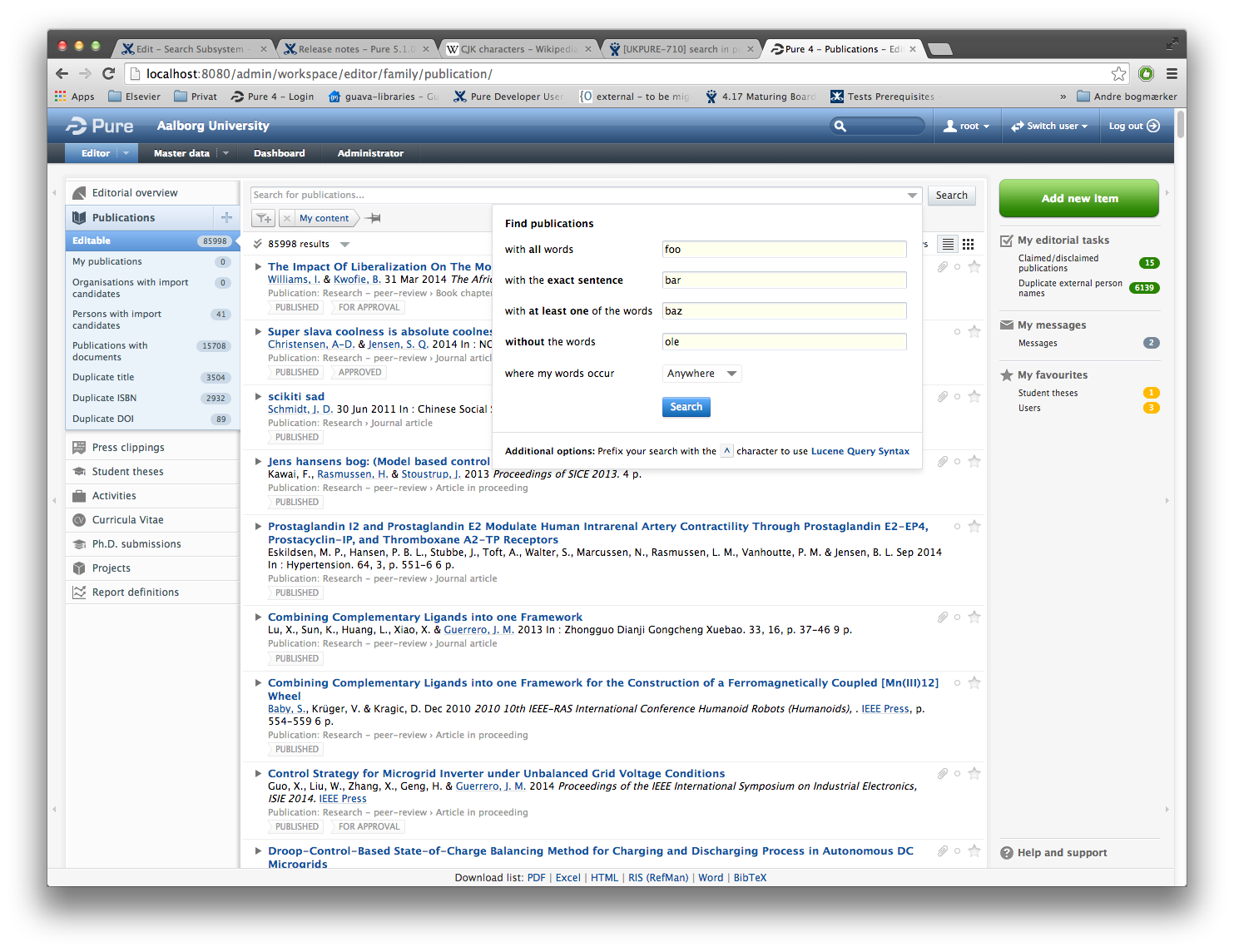
Searching in the Portal
Contact us
The search support in the portals do not always sort results by the lucene ranking order (some portals are configured to sort by publication date, last name etc.). To get this changed, you need to contact us, to plan the migration.
Notes: Re-index is needed
Updated Datasets model and integration to DataCite Metadata Store
Roles affected: Editors and administrators of datasets
Feature purpose: Updates to the datasets model based on feedback from customers.
Feature description:
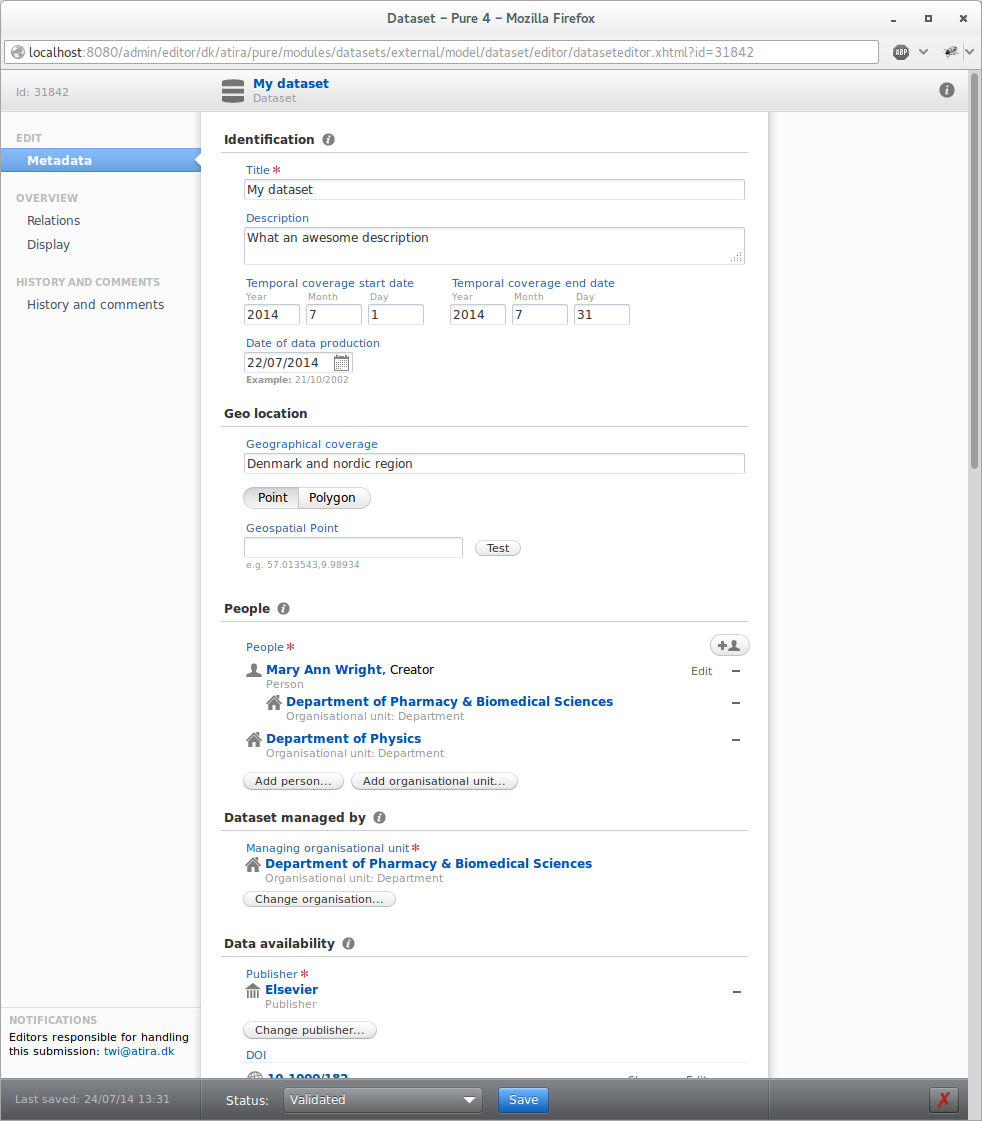
The datasets model changes include:
- Workflow (Entry in progress, for validation, validated)
- Temporal coverage
- Geographical coverage and geo location
- Date of data production
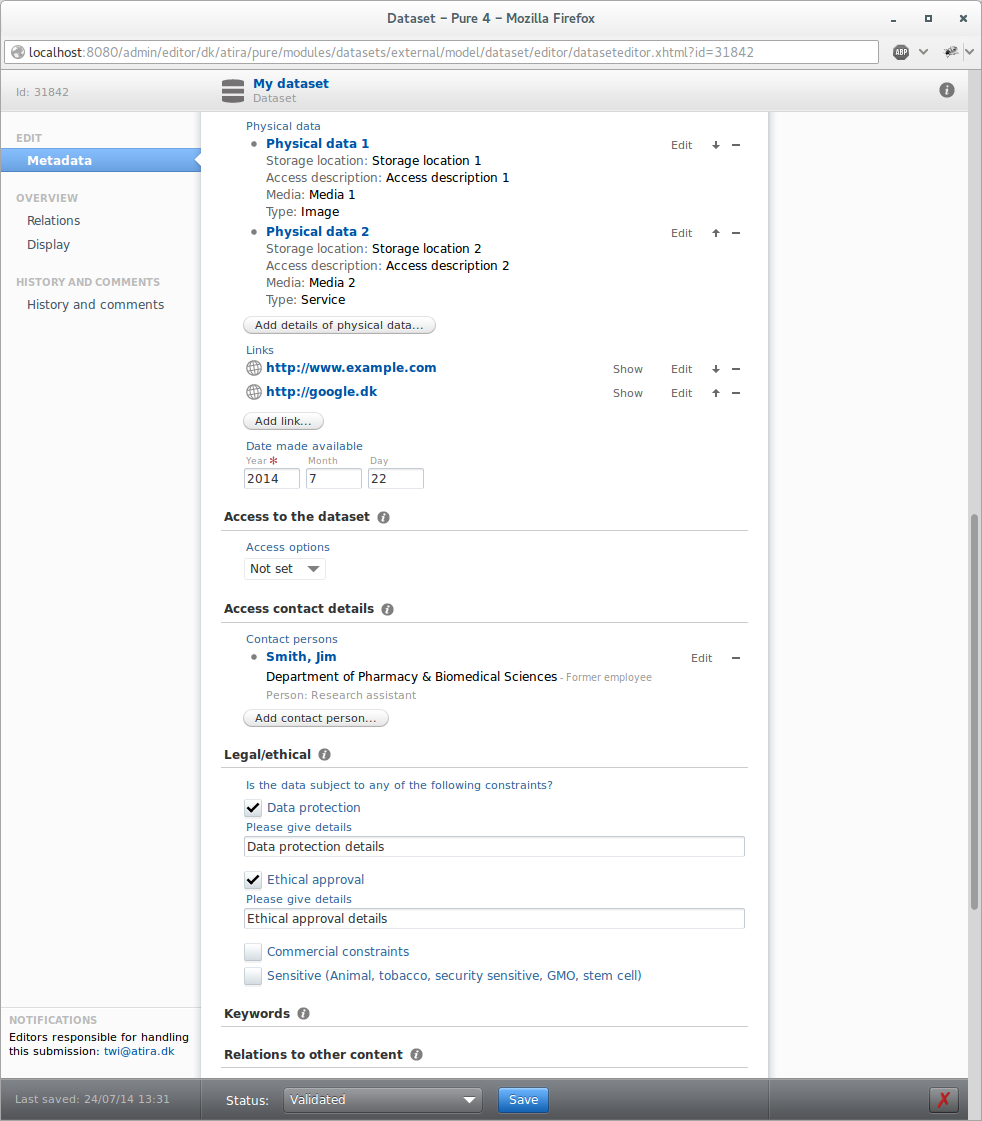
- Information on physical data and location
- Legal and ethical conditions (optional)
- Max file size support, when file upload is enabled for datasets (Configured under administrator tab) a maximum file size can be specified. Defaults to 1024 MB.
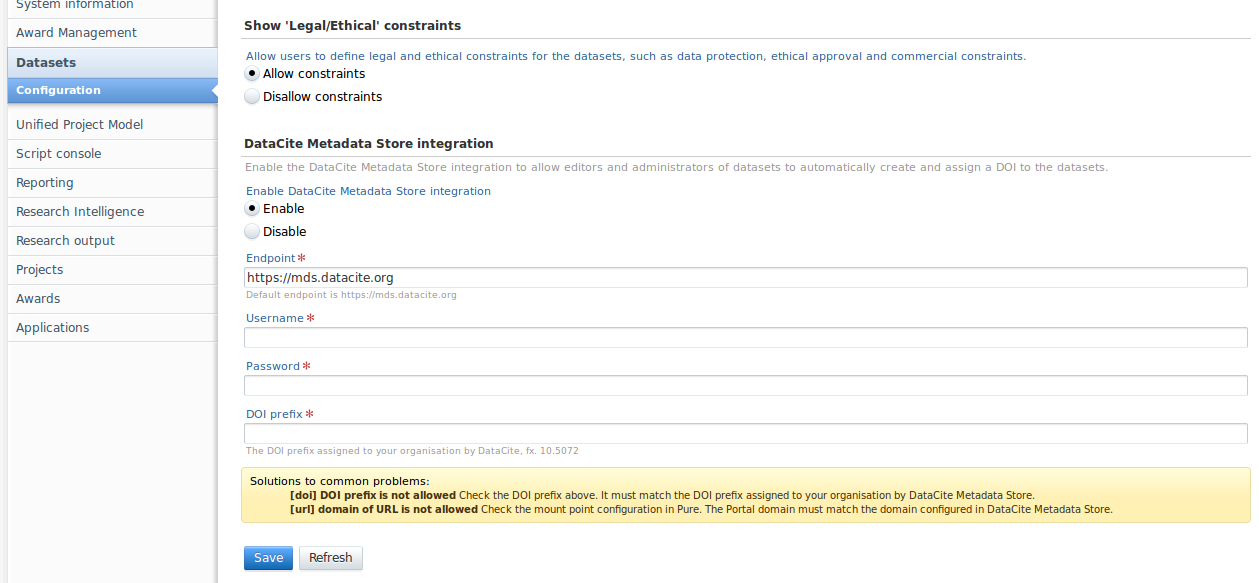
Furthermore we have also integrated to the DataCite Metadata Store to make it possible to mint DOI's directly from inside Pure.
To use this integration you must first register with DataCite by contacting them at contact@datacite.org and requesting the necessary access. More information on this is found on the Metadata Store website at https://mds.datacite.org
Once you have received the credentials you must configure Pure via the Datasets configuration on the Administrator tab as seen below in the screenshots section.
When the DataCite Metadata Store integration is enabled and configured editors and administrators of datasets will be able to mint a new DOI by clicking the "Create DOI from DataCite" button.

The "Create DOI from DataCite" button is only visible to editors and administrators once the dataset is saved.
Until this requirement is fulfilled personal users, editors and administrators will be able to manually add an existing DOI as seen below.

Screenshots:
 |
 |
 |
Local File storage configuration
Feature name: Local file storage configuration
Affected Bases: All
Roles affected: Administrator
Feature purpose: Enable runtime configuration of local file storage options, and to enable extension to the storage space of existing stores.
Feature description: It is possible to configure additional local storages and add additional storage space to existing stores.
From that administration tab the menu item Storage -> Local Storage gives you access to the local file store configuration.
A Local File Store maps to one or more base directories known as mount points. A file store consists of one or more mount points in which files are stored, which can be extended while pure runs with no down time. A file store is somewhat similar to a Volume Group in LVM. It is possible to define an arbitrary number of file stores to best suit the storage requirements of the pure installation
The file store defines a logical grouping of files that are related based on state or type. This store defines this through the use of filters.
The system determines which file store to place files in based on the content type the file belongs to (i.e. research output, data sets etc.) and additional filters that are defined for the store.
Filters supported are:
- Visibility (require the files or content is publicly visible)
- Workflow status (for example require that the publication is validated)
- File embargo (only contain files where the embargo date has been passed)
- Publication status classification (peer-reviewed, non-peer reviewed)
With this filtering options it is possible to define stores that will only contain files for content types that are displayed in the portal, and then define mount points that are on fast SSD devices or similar.
A new storage can be added by clicking the "add" button
- store name: A system wide unique name that defines this storage
- mount point(s): One or more mounted partitions on the file system that defines where the files will be stored
- Conditions for storage: Defines which content type's files to store, and the requirements for the content/file state that must be matched before storing the files in the storage.
An existing storage can be modified, and it is possible to extend the storage space by adding new mount points.
When stores are added or modified, the system will move the existing files according to the new rules on the next full file synchronization job run (each night), and modified content will be moved when the "Preserved Content Update" job performs one of the incremental runs
Deletion of existing stores is possible as well. If a store is set to be deleted, the system will gradually move the files to other stores according to the rules, and when everything has been moved successfully, the store will be removed. Any errors that happen during this, are logged in the "Preserved Content Update" job log.
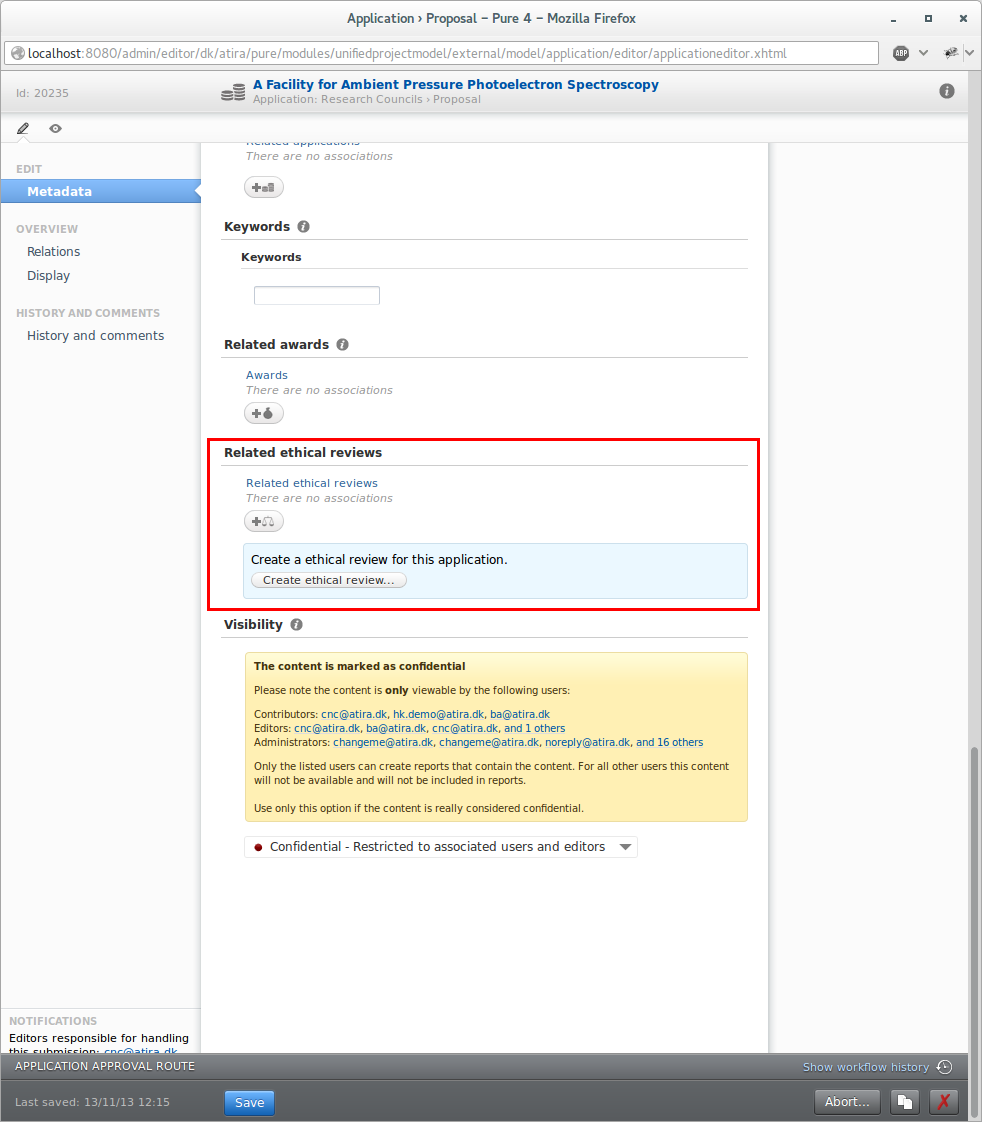
Ethical Review model in Award Management
Affected Bases: All customers with Award Management module
Roles affected: personal users, editor and administrator of ethical review, and administrators
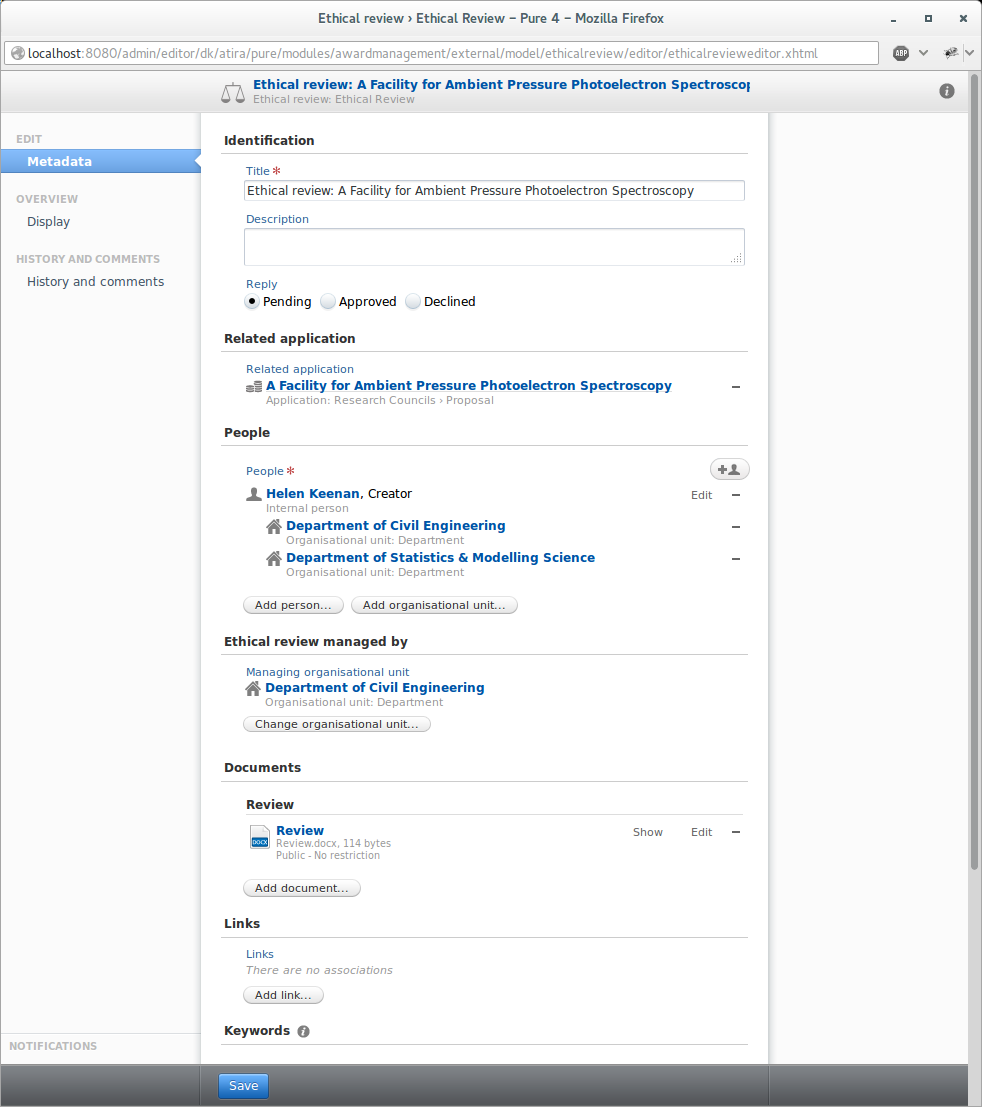
Feature purpose: Provides a new content type for tracking the Ethical Review process with optional workflow.
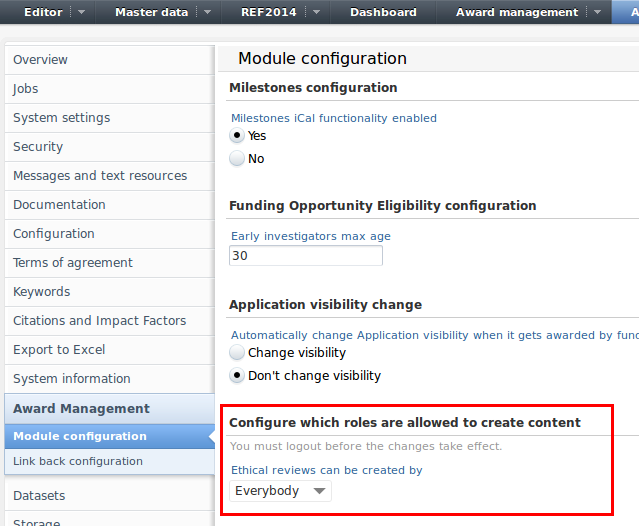
Feature description: Configure which roles are allowed to create ethical reviews via the award management module configuration screen.
If allowed ethical reviews can be created through the application editor.
Screenshots:
 |
 |
 |
Researcher commitment on Projects
Affected Bases: All customers with Unified Project model
Roles affected: personal users, editor and administrator of projects
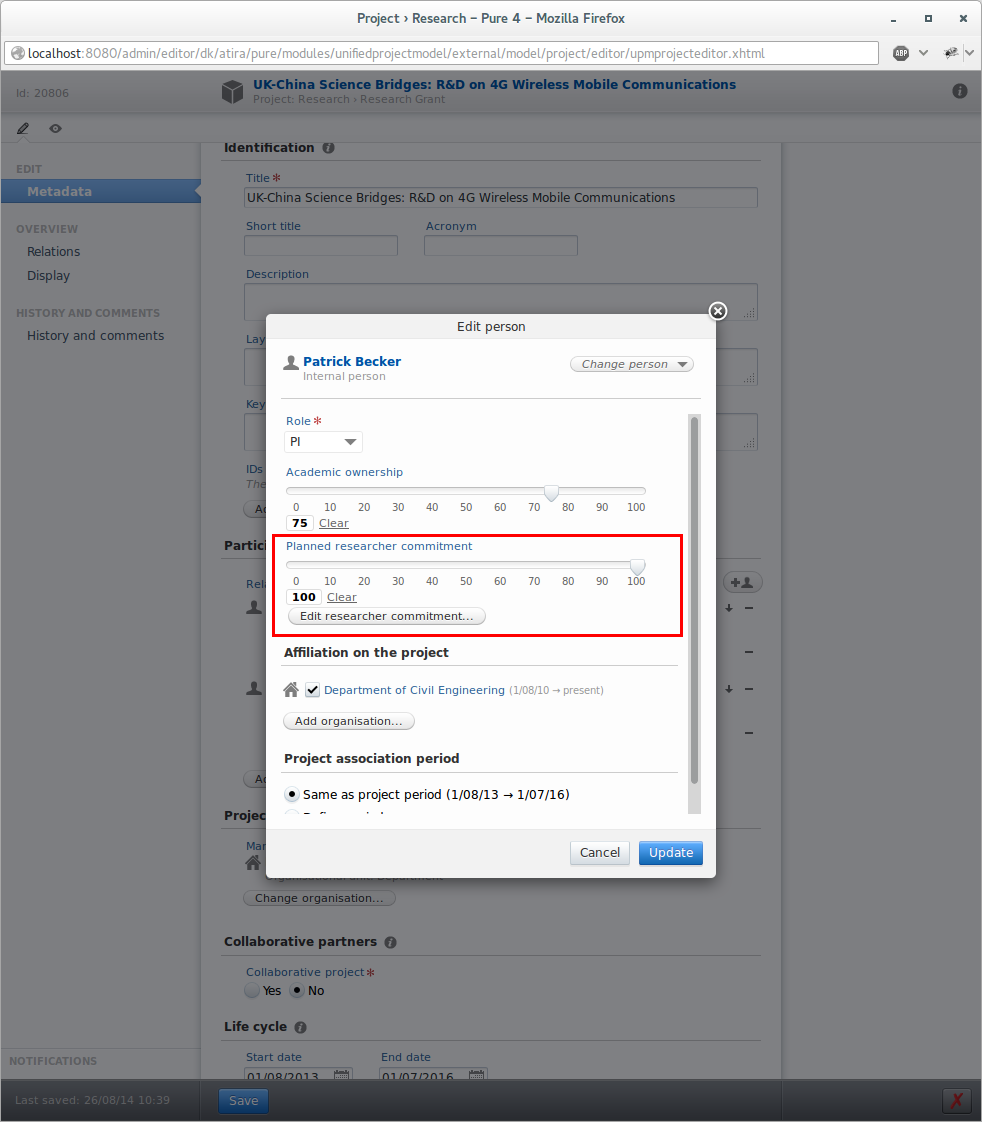
Feature purpose: Allow tracking of planned and actual researcher commitment per month in the duration of the project.
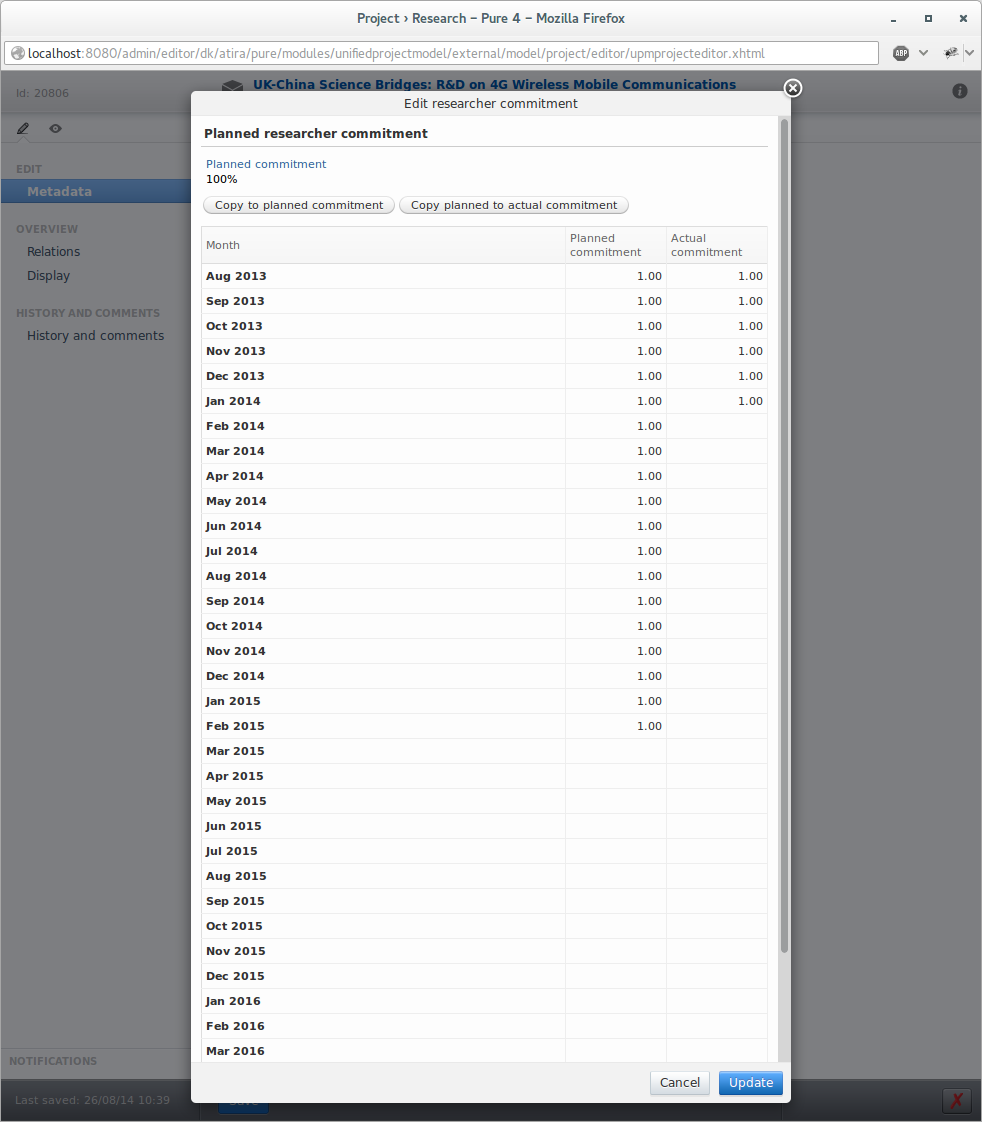
Feature description: On the participant association for internal persons on a project you can add the planned researcher commitment using the slider. Afterwards you can edit the monthly planned and actual commitment using the edit button. For your convenience you can distribute the planned commitment from the slider to all monthly values as well as copy the planned values to the actual values.
Configuration for researcher commitment is located on the Administrator tab in Pure together with the other Unified Project Model configuration options.
Reporting functions has been added including:
- Yearly planned researcher commitment
- Yearly actual researcher commitment
- Count of related publications
- Related publications per actual researcher commitment
Screenshots:
 |
 |
 |
Only the first 20 authors are shown for publications in the list view
Roles affected: All
Feature purpose: Publications with a lot of authors take up a lot of space on the list view. The view is now smaller and more consistent.
Feature description: The short render of a publication used in the list view in the backend user interface is now limited to only show the first 20 authors, and a link saying how many authors are remaining. This list can be expanded to show all authors, see screenshots for example. This feature is similar to what is often used on the portals.
Screenshots:
 |
 |
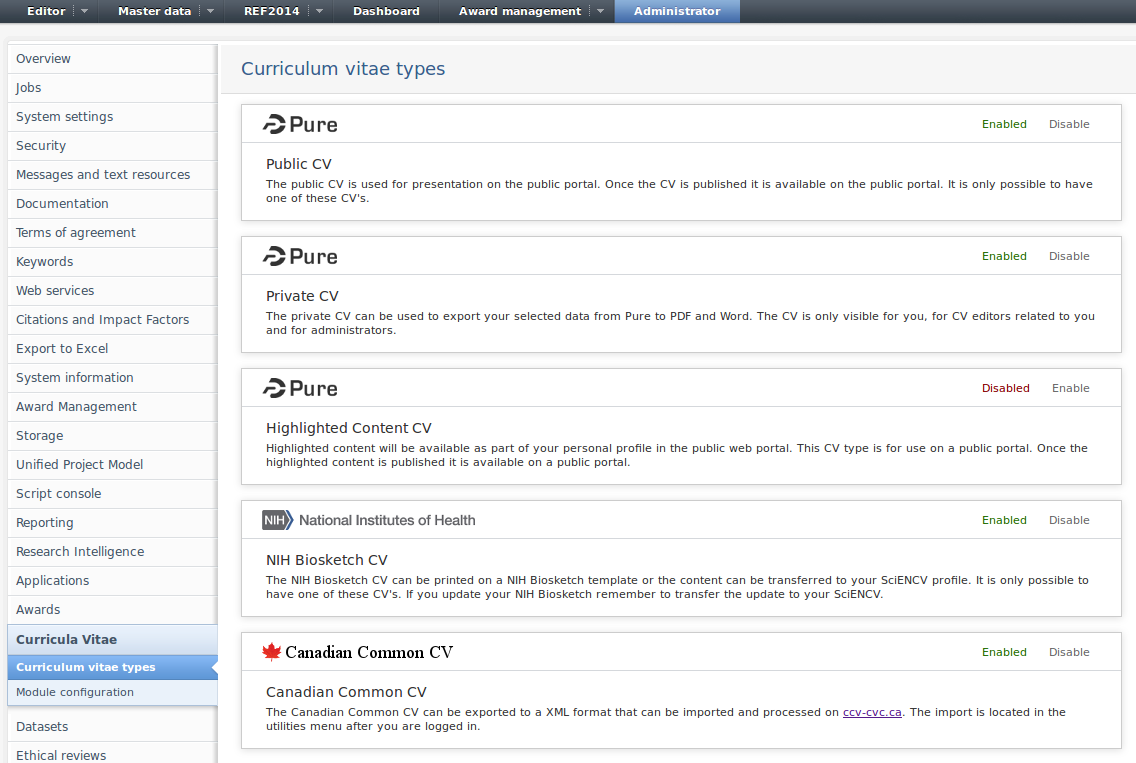
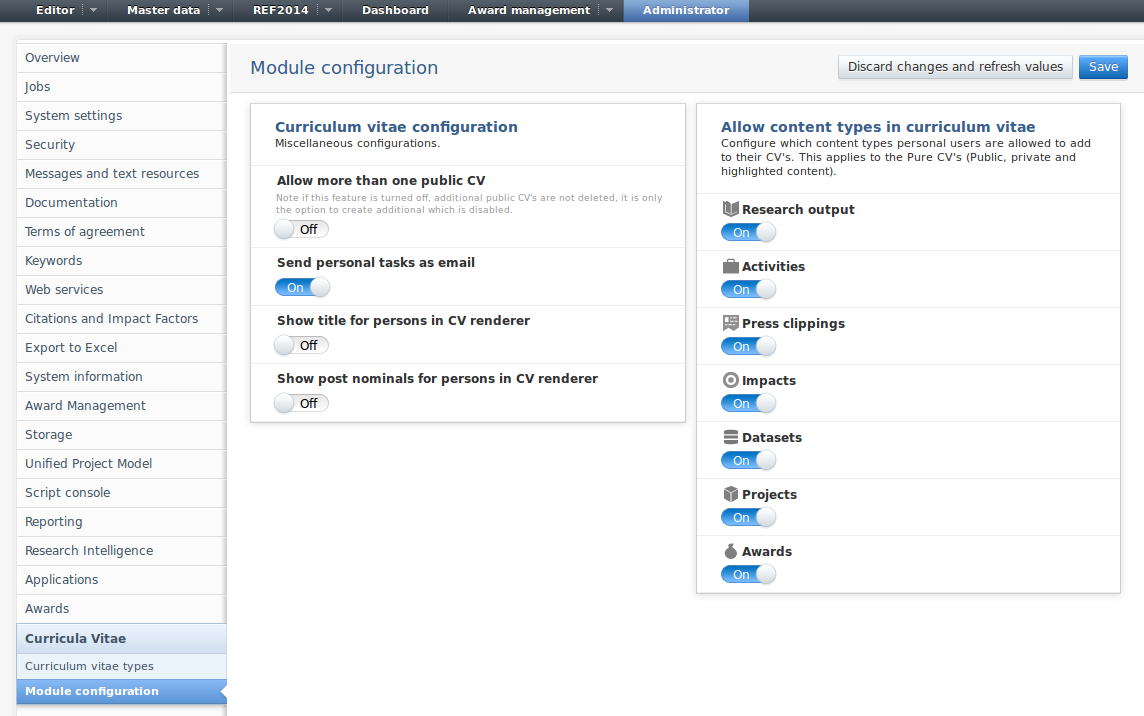
CV module configuration
Affected Bases: All customers with CV
Roles affected: CV editors and administrators
Feature purpose: Streamline CV module configuration options.
Feature description: The CV configuration options has been extracted to a standalone menu item on Pure's administrator tab. Below this menu item you can configure which of the available CV templates can be used as well as which content types are allowed in CV's and various other options.
Screenshots:
 |
 |
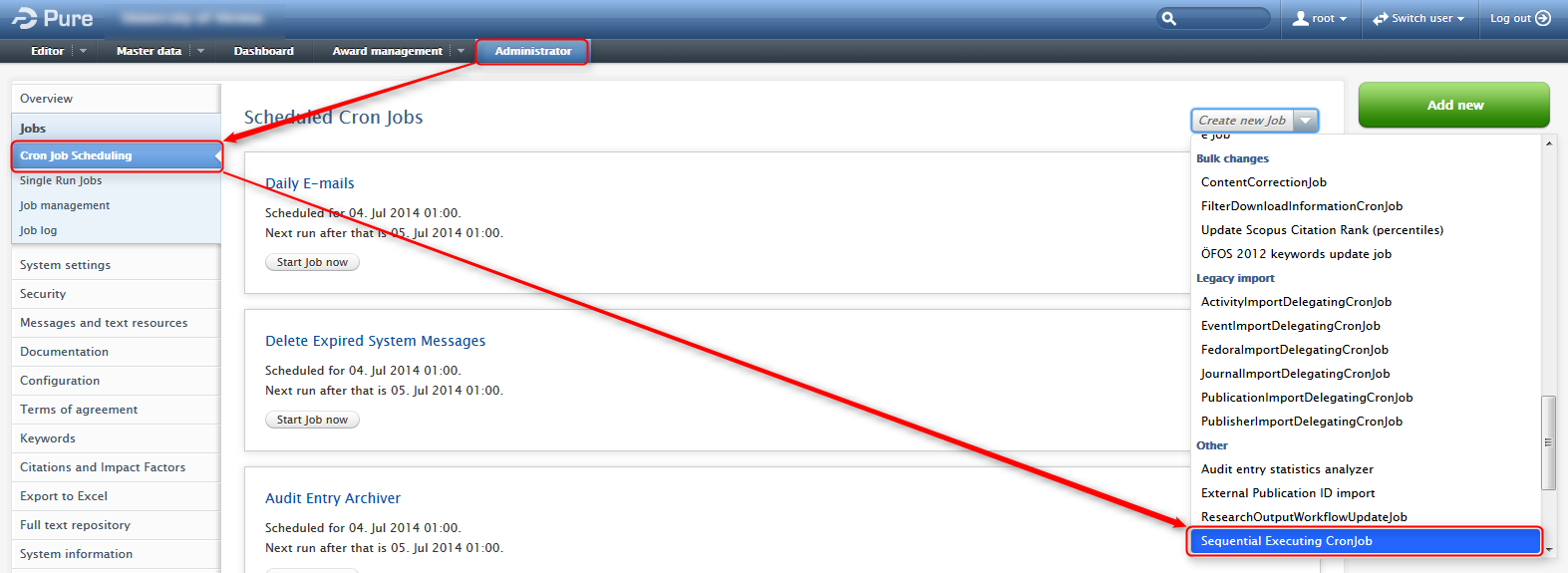
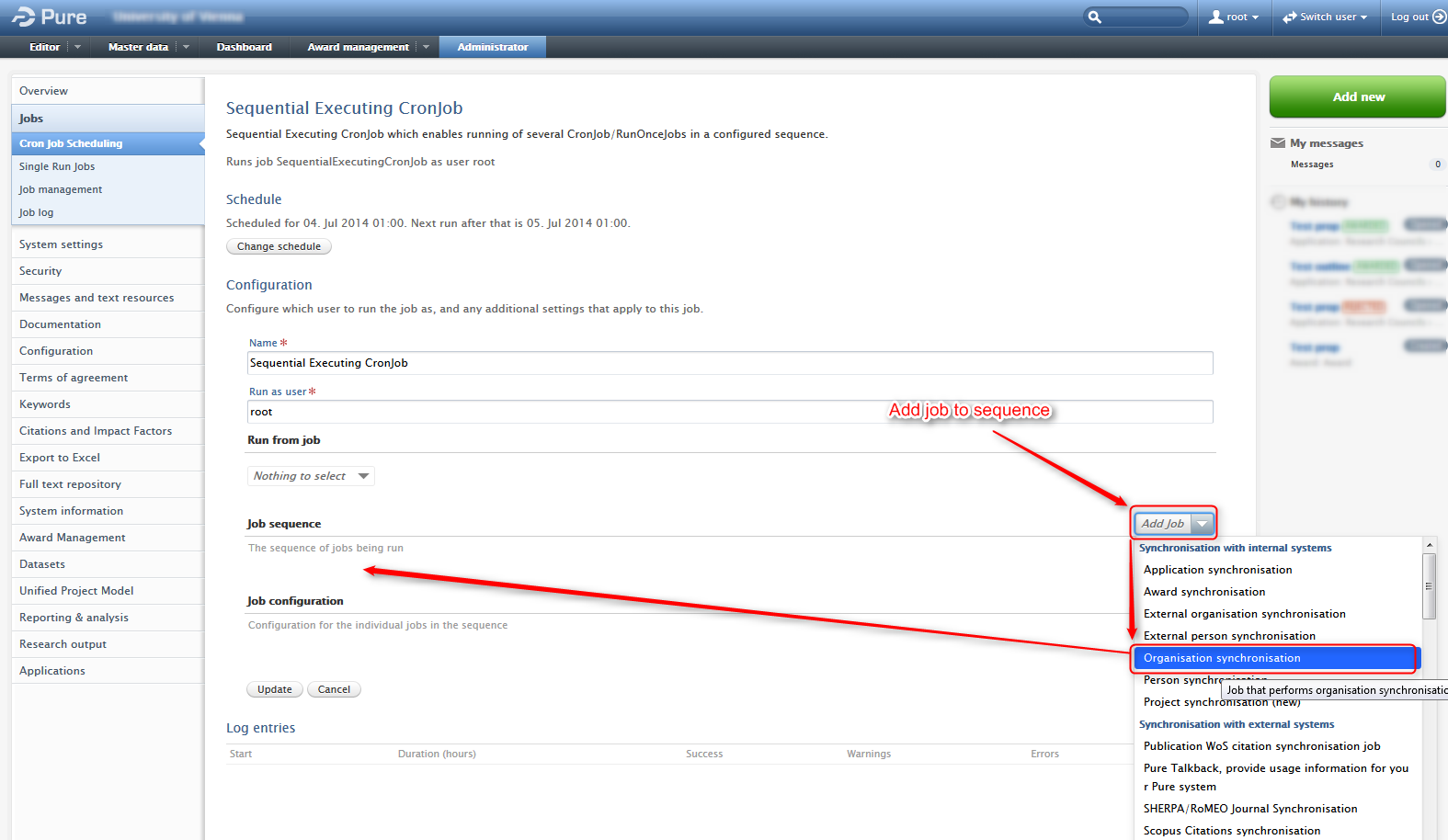
Sequential Executing CronJob
Roles affected: Administrator
Feature purpose: Sequential execution of cronjobs.
Feature description: The "Sequential Executing CronJob" has been added to the list of available cron jobs. This job is special in the regards that it can run a sequence of other cron jobs. Only one of these CronJobs are currently available and it is therefore only possible to specify one sequence of jobs and not multiple. A possible use case for this job is when you want several jobs to run at a given time, in a specific sequence, for example, organisation synchronization and person synchronization.
Screenshots:
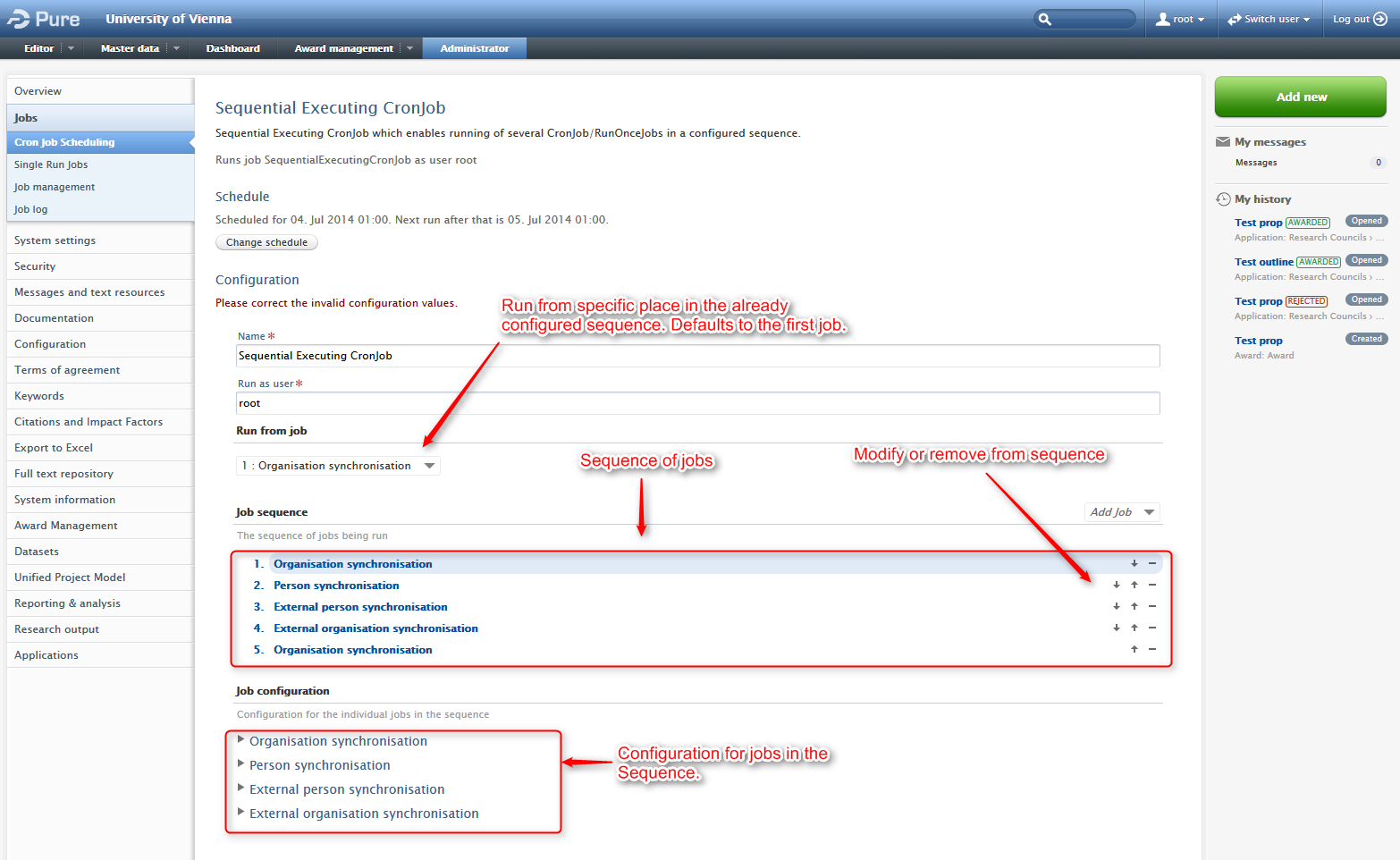
Configuration of Views from UI / Unified Synchronizations
Roles affected: Administrators
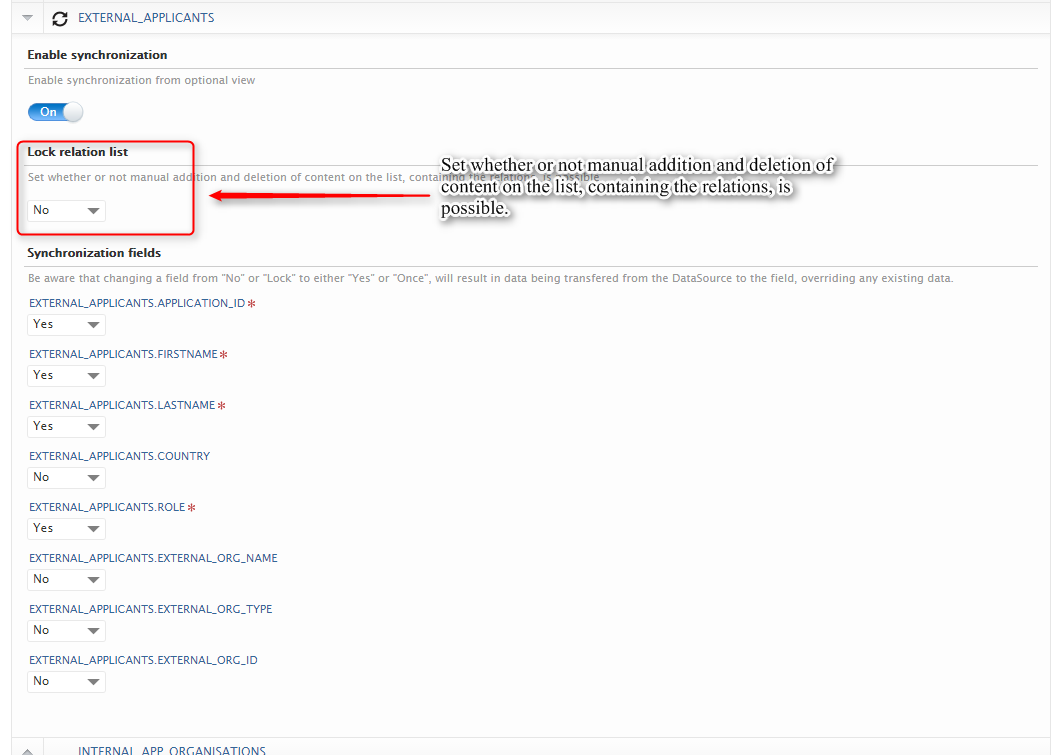
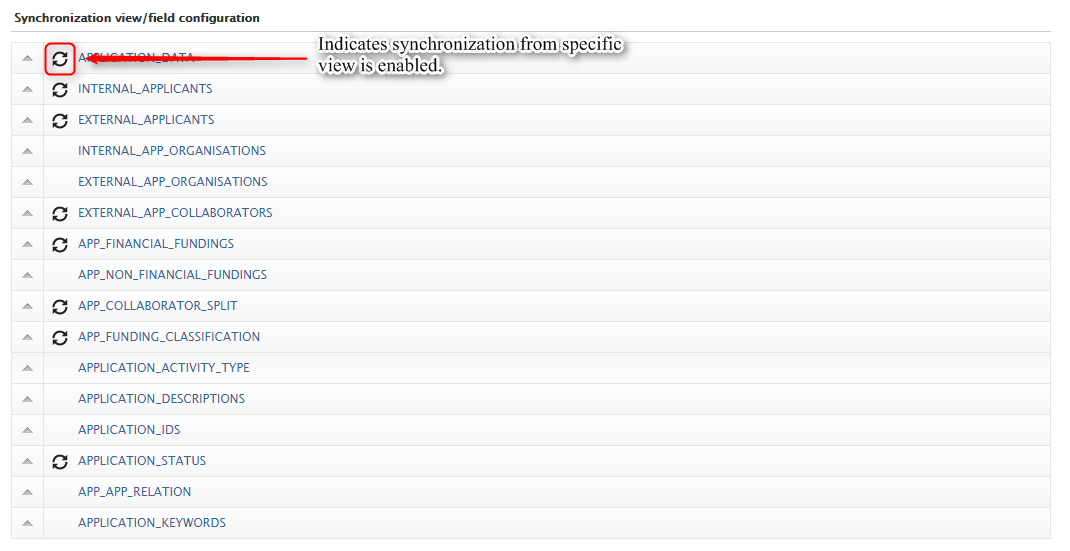
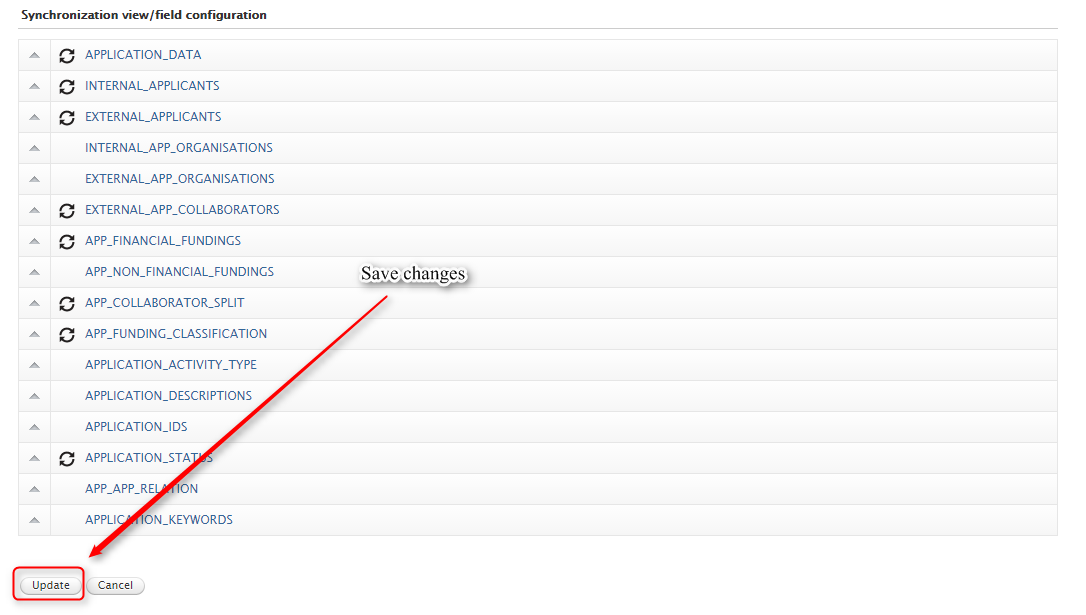
Feature purpose: Easy configuration of what views and columns should be synchronized through the already existing cron job configuration UI.
Feature description: For the unified synchronization jobs (UPMProject-, Award-, and Application-synchronization) it is now possible to setup the view and column configurations through the cron job UI. The new feature will only be accessable on synchronizations, which formerly were configurable through an uploaded XML file. Any uploaded XML configurations used for these jobs, will be migrated to the new configuration object in Pure.
Screenshots:
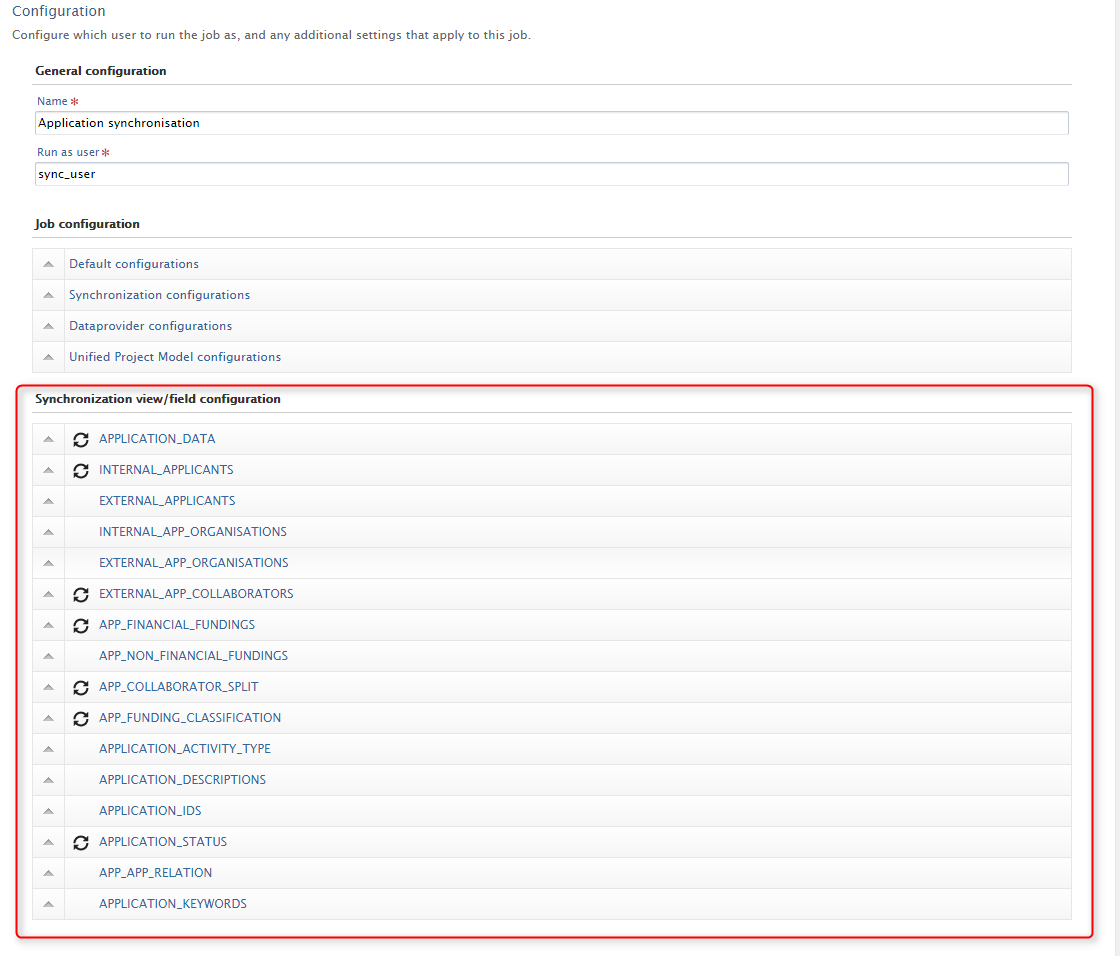 |
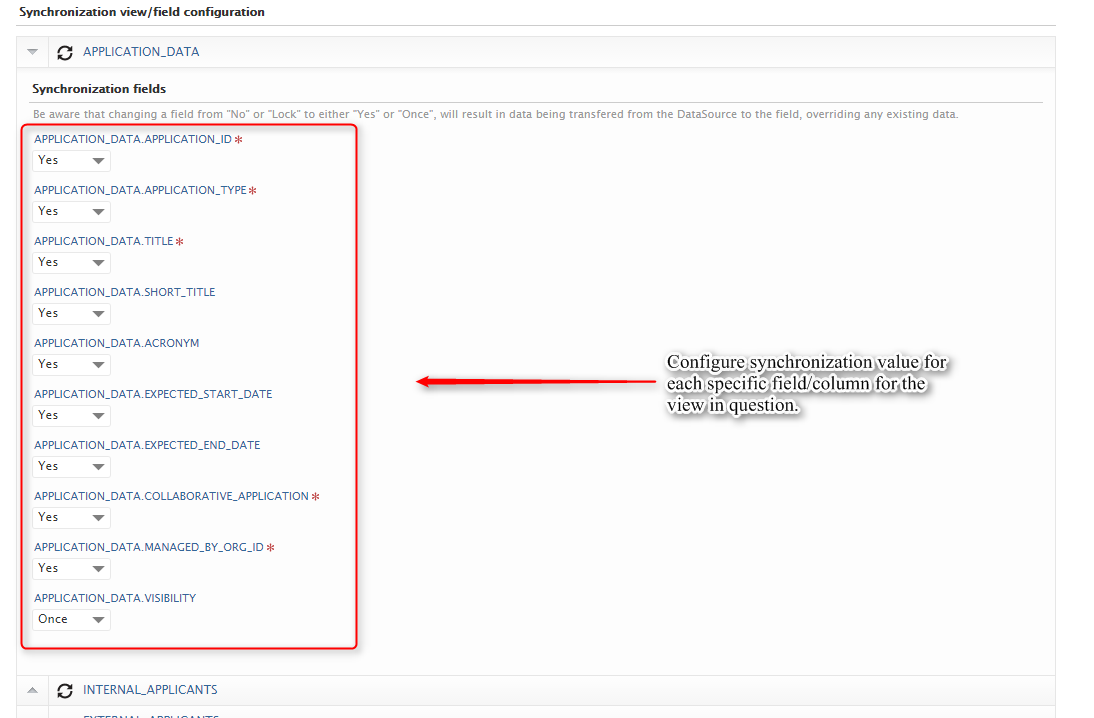 |
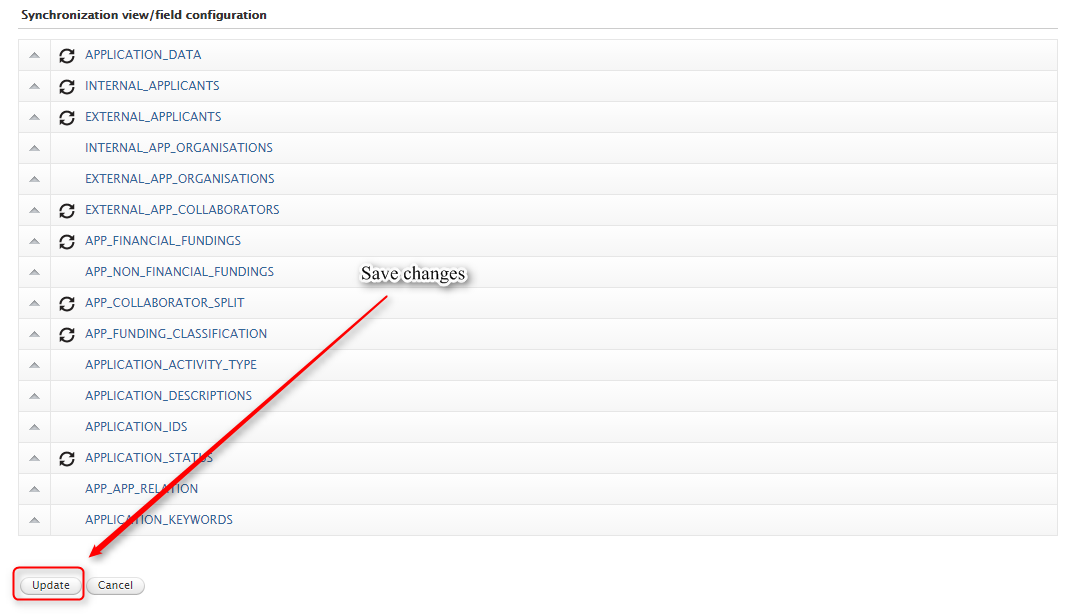 |
 |
 |
 |
Published at November 28, 2023