
How Can We Help?
General synchronisation informationGeneral synchronisation information
Synchronisation Non-explicit Id Matching
Synchronisation Non-explicit Id Matching
When using non explicit id matching, the lookup for the content is handled in the following way and order:
- Lookup is done through Pure id matching (the pure id is the id the content in question has inside Pure, and given by Pure when the content is created.)
- Lookup is done through source id matching (the source id is the id the content was given when it was imported into Pure from an external source. This can be through synchronisation, import jobs etc.)
- Lookup is done through classification defined id matching (classification defined ids are ids that content can be given inside Pure through the editor.)
- Lookup is done through Pure UUID matching.
- All the above steps are taken and the result is returned. If more than one result is matched, due to for example duplicate ids, then the first result matched will be returned.
How to find classification values for the synchronisations
How to find classification values for the synchronisations
Classifications in Pure are used to fill out all the dropdown boxes in Pure. That also mean that you can change many of them because the set of classifications in a schema can be changed.
To find the string to use in the view and xml for classifications you just search for the schema that is present in the specification for the column.
E.g. to find information about the different titles on a person:
- This is what you see in the view:

2. When you know the schema then you can search for the uri in Pure:
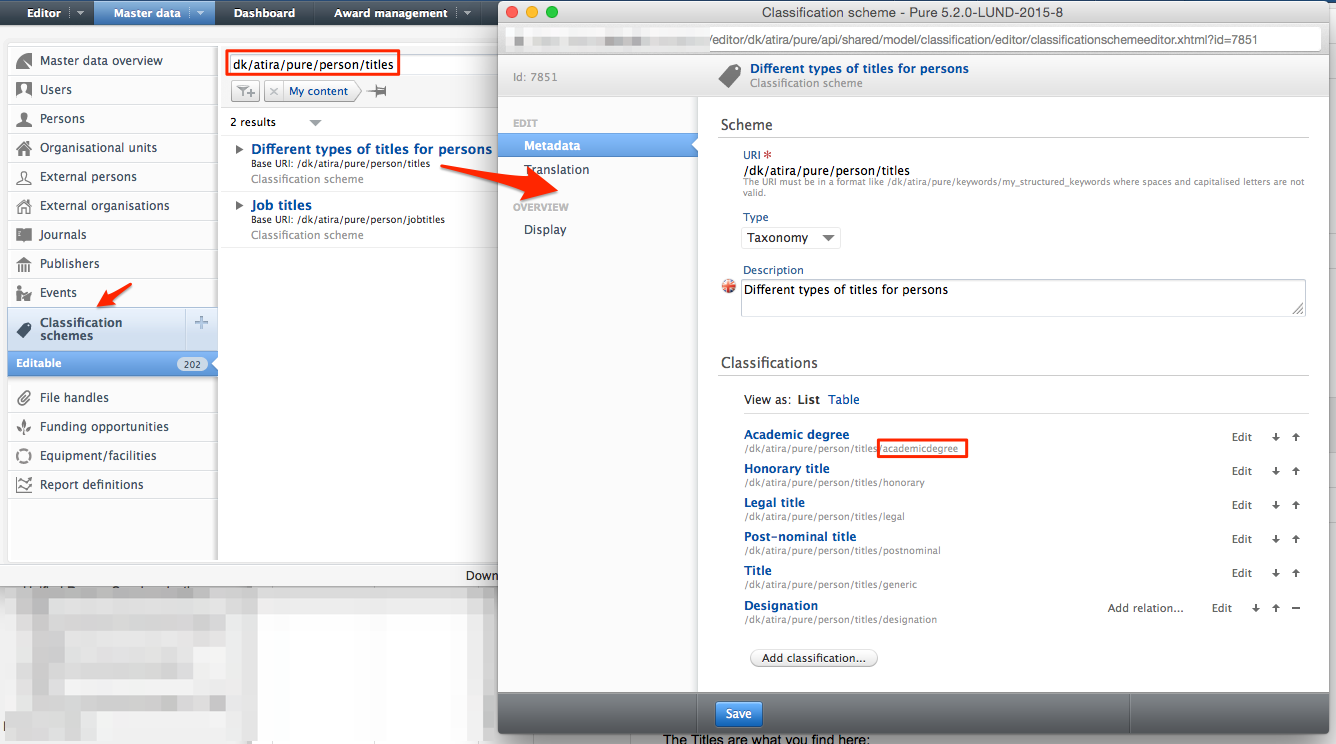
In most of the cases it is the last part of the uri that should be used in the view/xml. So to add an academic degree "academicdegree" must be put in the view/xml.
Securing access to a synchronization source
Securing access to a synchronization source
For both of our supported synchronization methods we expect the customer to expose a data source to our environment over the internet.
There are a number of options to provide a defense in depth strategy to this potentially sensitive data source. Our recommendations are:
- Only allow access from our outgoing IPs (see Hosting and installation, Outgoing IPs (NAT Gateways)) on the needed ports to the data source. Please note that these IP's are shared across all hosted customers in the region so this cannot be a stand-alone measure
- Ensure encrypted communication
- For XML based solutions make sure to use TLS
- For database based solutions we recommend tunneling the traffic through an SSL tunnel (see SSH Tunnel from Pure server to Customer network) if the database doesn't natively support encrypted communications
- Ensure that the data source requires authentication
- For XML based solutions we support Basic auth, Header based auth, and S3 credentials if hosted in AWS
- For database based solutions we support the normal database username/password authentication mechanism
Note, that option 2b and 3b will be discontinued as of June 2026. See Moving from database to XML synchronizations for more information.
Generally we recommend that customers consider partitioning the components and data so that only data needed for the Pure synchronization is included in the data source where access is provided. This would in particular mean not to expose a multi-tenant database in this manner.
Pure API or XML synchronization?
Pure API or XML synchronization?
As the work on the Pure API progresses, a lot of our customers are wondering if they should start planning for rewriting their synchronizations to leverage this.
As the Pure API is still missing a number of features that are built in to the synchronization functionality, our recommendation is to use the XML synchronization for most use-cases.
Currently, the XML synchronization framework offers the following features:
-
It is batch oriented, making it ideal for processes that run on a schedule that is managed inside Pure.
- Easy to coordinate with other jobs, i.e. users and organizations, should be run before persons.
- Identity management happens in Pure, the customer doesn't have to concern themselves with Pure identifiers.
- Supports content and field locking strategies.
- Monitoring of result can be found inside Pure in the job logs.
- The synchronizations sanitize data to get in through Pure validation rules. This could be removing unwanted XHTML elements, adding organizations to other places in the model, where it is needed to generate valid content.
The Pure API supports the following features:
- It is event oriented, making it ideal for reacting to changes in the source systems (if they're expressed as events or messages).
- Only understands Pure UUIDs for content identity, any matching between source identifiers and the Pure UUID has to happen in the service client.
- Does not directly support content and field locking (it can be faked, though - see Synchronization workaround).
Published at February 26, 2025