
How Can We Help?
Open data and PureOpen data and Pure
Open Science is based on the principle that research must be reproducible and data should be accessible to all. With the growth of the Open Science movement, Open Data is also becoming more and more important. Research data must be FAIR, meaning it should Findable, Accessible, Interoperable, and Reusable. For these requirements to be met, governments and funding agencies have developed (or adhered) to specific standards that research data must comply with. DataCite and OpenAire have developed standards and specific data schemas aimed at making research data interoperable.
DataCite is an international non-profit organization that aims to improve data citation by improving discoverability of data and supporting archiving. It provides persistent identifiers (DOIs) for research data and other research outputs, so that data becomes discoverable and associated metadata is made available to the community. In order to make data citable, searchable and accessible datasets are associated with metadata that meets basic standards and adheres to uniform, consistent schema. The metadata consists of descriptions of and facts and figures about the data and aims at making your data reusable and interoperable. More information on DataCite can be found here.
OpenAire is a network of Open Access repositories, archives and journals, that supports the implementation of the European Council (EC) and European Research Council (ERC) Open Access policies. It provides interoperability services that connect research and enable researchers, content providers, funders and research administrators to easily adopt Open Science. It promotes common access policies and protocols for all research results by setting common data standards for an effective and open global research ecosystem. OpenAIRE gathers together research output related to European funding streams, with the aim of supporting open science and tracking research impact.
OpenAire has adopted the DataCite Metadata Schema as the basis for harvesting and importing metadata about datasets from data archives. The OpenAIRE Guidelines for Data Archive Managers 2.0 provide instructions on a dataset's metadata, such that it is compatible with the OpenAIRE infrastructure. OpenAIRE uses the OAI-PMH v2.0 protocol for harvesting dataset metadata. Metadata must be encoded in the DataCite metadata format. More information on OpenAire Guidelines for Data Archives can be found here.
In Pure we want to make sure that your datasets are compliant with Open Access policies, meaning that your datasets are easily findable and accessible, and the metadata associated to your datasets includes all the information required for compliance.
In this section our integrations with Data Monitor (for importing datasets) and Datacite (for registering datasets) are described.
Registering datasets at DataCite
Registering datasets at DataCite
DataCite provides a domain agnostic metadata schema and provide interoperability through a small number of properties - making interoperability possible in the simplest manner possible and as a result keep the technical barriers for implementation as low as possible. The DataCite Metadata Schema is a list of core metadata properties chosen for an accurate and consistent identification of a resource for citation and retrieval purposes, along with recommended use instructions. The metadata schema properties are listed below:
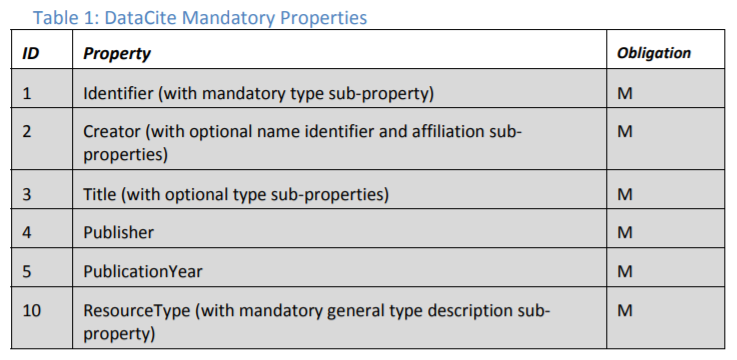
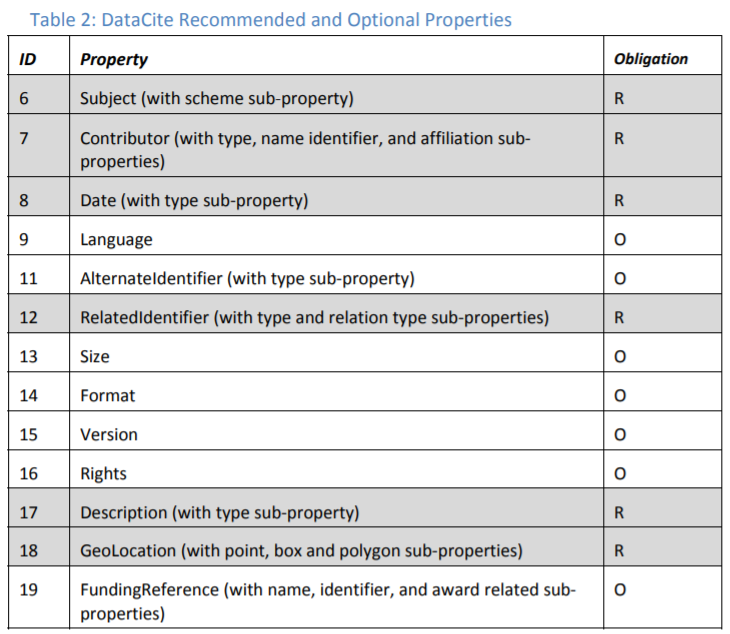
More information on the DataCite Metadata Schema can be found here.
Pure has an integration with DataCite, allowing researchers and research managers to register their datasets at DataCite directly for Pure. To use this integration you must first register with DataCite by contacting them at contact@datacite.org and requesting the necessary access. More information on this is found on the Metadata Store website at https://mds.datacite.org.
For more details on Pure's integration with DataCite and on how to mint DOIs from Pure, please see our release notes.
Integration with Data Monitor
Integration with Data Monitor
Data Monitor is a search engine for datasets. It allows scientists and researchers to search for many different data types and formats across a variety of domain-specific and cross-domain institutional data repositories and other data sources. Researchers can quickly preview and assess datasets before accessing them in the destination repository. Data Monitor indexes both metadata and the data itself, making it easier to discover datasets. Researchers can preview available datasets and select which to import. Through the integration with Data Monitor, datasets can be periodically synchronized into Pure. These datasets can then be validated and are available in Pure for other purposes, such as being shown on the Pure Portal or available in reports.
Below is a list of the metadata fields that are retrieved from Data Monitor (available in the Pure Dataset record as read only):
| OpenAire | Pure | Description |
|---|---|---|
| Identifier (M) | DOI | |
| Creator (M) | Persons (with the role ‘Creator’ assigned by default) | |
| Title (M) | Title | |
| Publisher (M) | Publisher (default is set to Managing Org) | |
| Publication Year (M) | Publication Year | |
| Subject (R) | Keywords / Subject categories | |
| Contributor (MA/O) | Persons | |
| Date (M) | Date | |
| Language (R) | Original Language | |
| Resource Type (R) | Content Type | |
| Alternate Identifier (O) | Other ID | |
| Related Identifier (MA) | DOI of related Research Output | |
| Size (O) | --- | In Pure you get the Files (represented as links back to the original record) |
| Format (O) | --- | (see above) |
| Version (O) | --- | |
| Rights (MA) | License | |
| Description (MA) | Description | |
| Geolocation (O) | Geolocation |
Data Monitor has two separate offerings; a free api or a paid (enriched) api. With the free api, research managers are able to search for datasets relevant to their institution by searching with the Mendeley Institution ID. The discovery of relevant datasets with the paid api is improved, by allowing administrators to also match datasets to the Scopus and SciVal affiliation ID. Once datasets are matched to your institution, further matching is performed on the author, using the Scopus, Scival or ORCID author ID.
More information on how to enable the integration of Pure with Data Monitor can be found here (see 5.1. DataSearch takes over from Mendeley Data).
Further details can also be found in the release notes of Pure 5.16, 5.17, 5.19.
Published at December 04, 2023