
How Can We Help?
Pure API vs XML SynchronisationPure API vs XML Synchronisation
There are a number of key differences between the Pure API and XML synchronisation jobs, so it is worth carefully considering these and the best approach to use in implementing an integration. Particularly for those familiar with Pure's current XML synchronisation functionality, there are some major differences in paradigm and behaviour that should be considered when implementing using the API. The below table provides a summary of the considerations with further detail and examples provided following:
| Topic | XML Synchronisation | Pure API |
|---|---|---|
| Difference of Protocols |
|
|
| Scope of the dataset |
|
|
| Timeliness of integration |
|
|
| Locking of records |
|
|
| Managing relation lists |
|
|
| Flexibility of integration |
|
|
| Maturity |
|
|
| Error handling and logging |
|
|
| Coverage & Functionality |
|
|
| Broader applications |
|
|
Difference of protocols
A big reason for implementing the Pure API is that it is the industry best practice and standard protocol used for building integrations. The XML "load file" format of the Pure synchronisation is a pattern that it still used but for many integration teams there may not have the familiarity or skillsets to create such XML files, while the SCRUD Pure API methods with JSON objects is likely to be much more comfortable. Additionally, some of the "features" of the XML synchronisation (such as the ID lookup and fallback patterns), while helpful for quickly creating records and error handling, are potentially less intuitive and can lead to confusion due to the multiple ways data can be represented and the unintended consequences if this lookup logic isn't well understood.
| Pure XML Format | Pure API JSON Format |
|---|---|
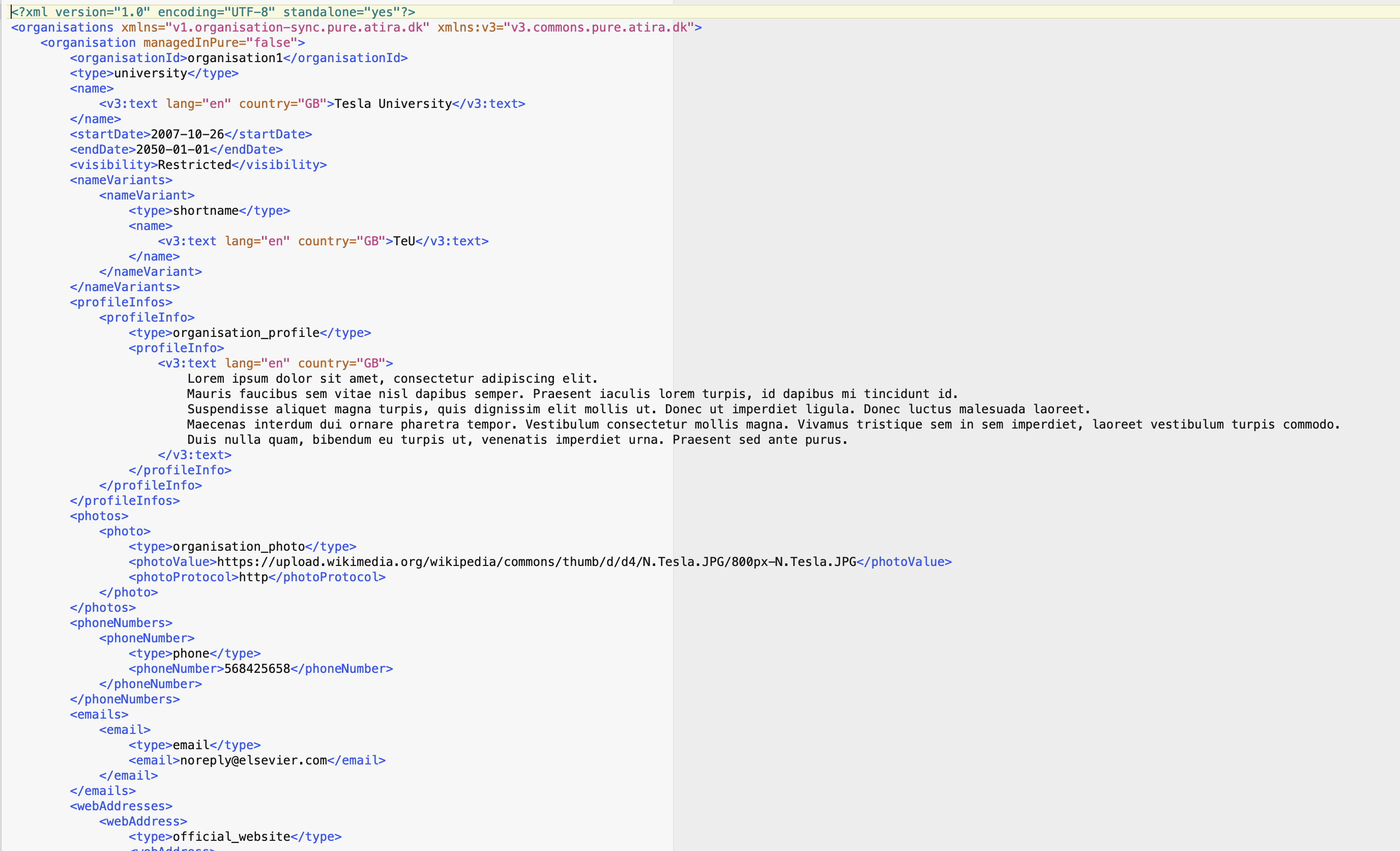 |
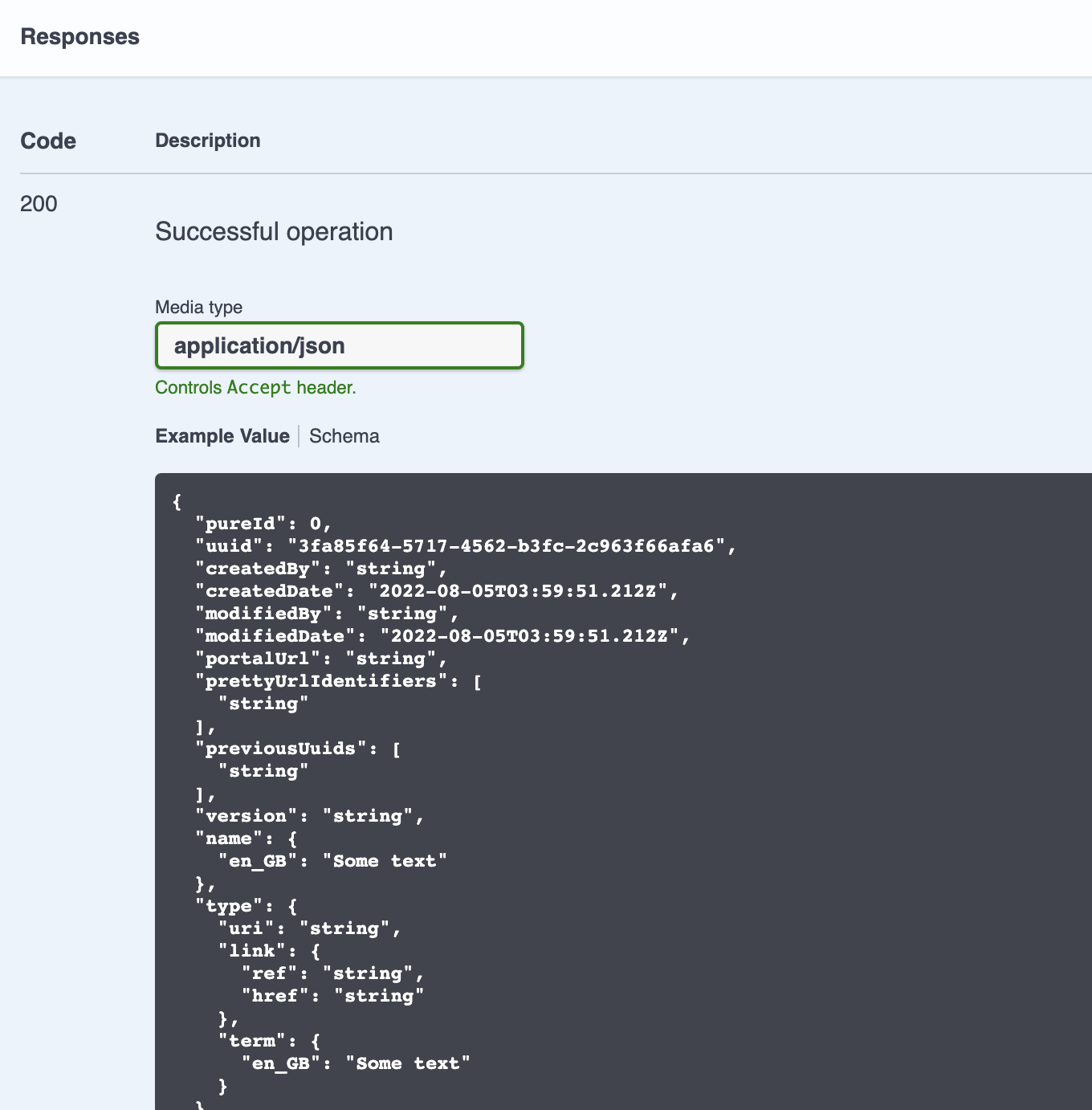 |
Scope of the dataset
While the XML synchronisation deals in a single file containing all records, the Pure API uses a single call to create each record. This means the XML synchronisation processes a complete "dump" of data, whereas the API is used for individual records. An iterative call of the API could be used to process a complete set of the records, but it is not possible to use the XML synchronisation to update just a couple of records (if there is only a couple of changes in the XML then the rest of the content will be ignored, but all records must be present or else the will be "retired" or deleted, depending on the content type). This leads to the next consideration.
Additionally, the synchronisation jobs require all mandatory fields to be specified even if the job isn't updating them. This may mean that data is included in the XML file as placeholder values for which Pure is meant to be the source of truth. This field can be set to Not Sync in the job configuration, but if it was ever accidentally changed, values in Pure would be overwritten with incorrect data. A common example of this would be for an Awards synchronisation for records created in Pure to add budget expenditure records. Even though only the budget values are meant to be updated, the XML file requires a number of mandatory fields, such as title and type, for which Pure is likely the source of truth. The Pure API will only update the fields included in the JSON request body, and mandatory checks are performed only when creating new objects, so those fields can be omitted when performing an update. This also means that the content being sent to Pure is cleaner than the XML as there isn't extraneous placeholder content included.
| XML Synchronisation expects all records | API can be used to create, update or delete single record |
|---|---|
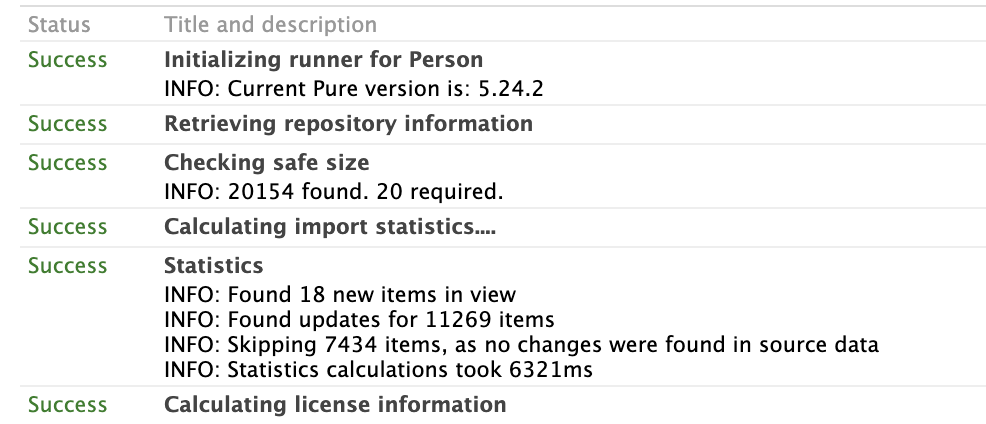 |
 |
Timeliness of integration
Due to the quantity of records required for XML synchronisation and the processing required to generate the file and then load it into Pure, XML synchronisation jobs are often run on a nightly basis, to collect all changes from the day and update them in Pure. Due to the potential for individual record updates, the Pure API can be used in an event driven way, to update records in Pure in real-time. Consideration should be given when building the integration on the volume and relevance of daily changes in the source system. If there is a large volume of relatively meaningless changes to Pure, then this may create unnecessary processing time, while a daily refresh may sufficient.
| XML Synchronisation is based on a configurable schedule |
|---|
 |
Locking of records
The XML Synchronisation jobs are designed to control certain fields of a record where the source of truth is another system (using the "Sync" locking strategy). With the Pure API this is achieved with a combination of a “lock” sub resource and setup of the synchronization jobs in Pure. Check this guide for more details.
| Managing locking of records with an XML Synchronisation |
|---|
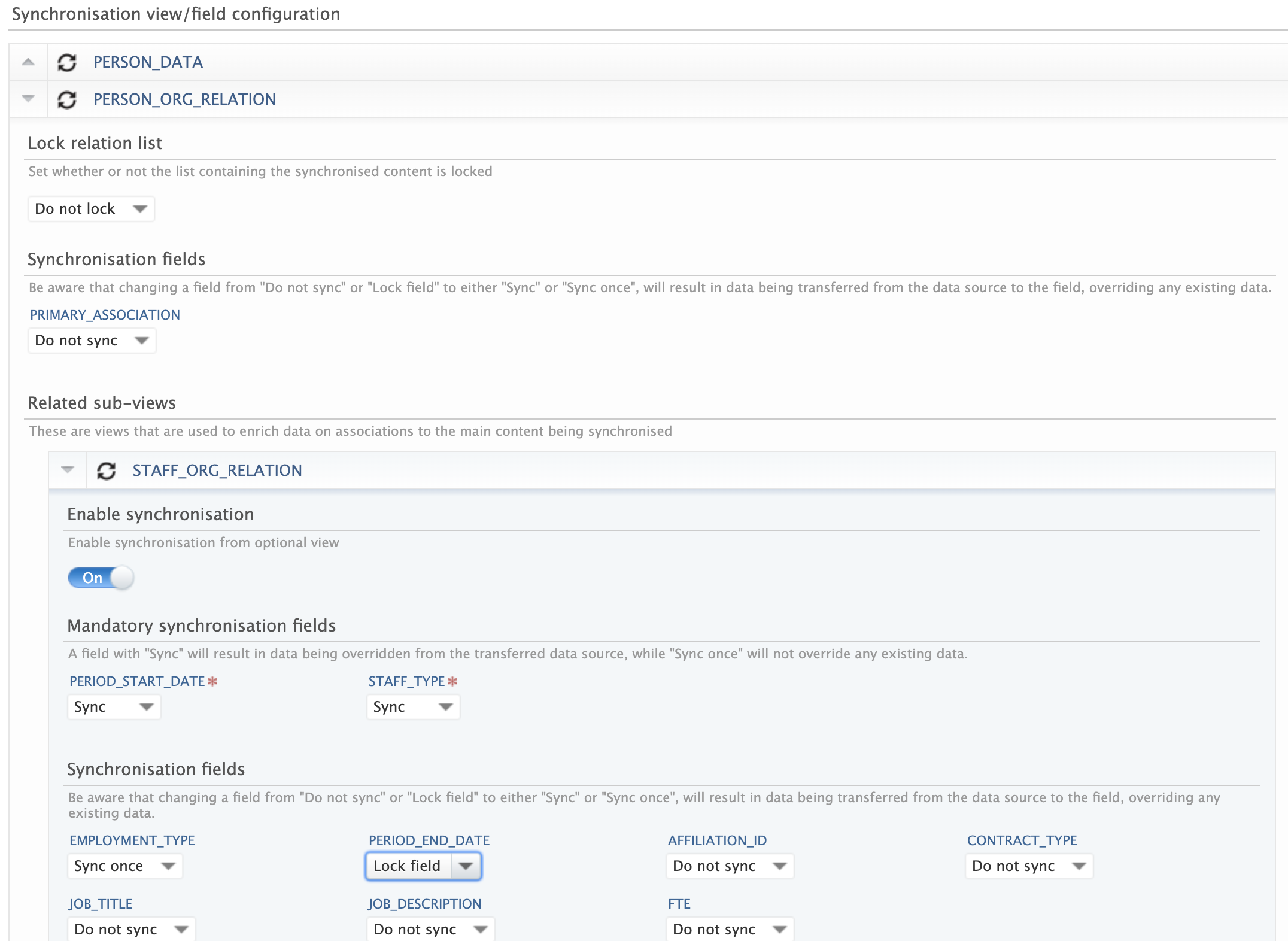 |
Managing relation lists
With XML synchronisation, there is an option to "Lock Relation Lists". If set, this will mean that new items cannot be added via the Pure interface, and the only related items in the list will be in the XML. As mentioned previously, this is presently not supported via the Pure API.
If this "Lock Relation Lists" field is set to "Do not lock", then new items can be added manually, and the XML Synchronisation will ignore these items. This means that manually created data in these list relations won't be overwritten by the synchronisation, but it also means that they can't be updated or "taken over". As the Pure API doesn't lock or control records, it can update any relation in the list, whether created via the API or manually.
|
The Pure API will presume that when you are updating an item in a list that you are updating the list itself as well. This allows you to remove records from the list by not including them, but does mean that items could be accidentally deleted if they aren't included. The full content of the items isn't needed, just the Pure IDs. So for instance, to add a new author to an output, your request body might include the following:
|
Flexibility of integration
By default the XML synchronisation expects to create all the records it manages in Pure. This can be expanded in settings for the synchronisation job to "take control" of a record, but the presumption is that the source of truth is in another system and the XML synchronisation will load those values into Pure. The API can be used for this same use case but also for other options where you might have certain fields that you want to update from another system (for example adding the cost-code to an award once it has been created in the finance system) or performing ad-hoc bulk updates to records where internal processes have changed and fields need to be changed within Pure.
Maturity
The XML Synchronisation functionality in Pure has been in the product for many years and used across the world by institutions of all shapes and sizes to manage their integrations. It is well tested in the field, and while it has its limitations it is stable and rarely updated. As the Pure API is under current development it is, by nature, more likely to change as improvements and new content types are added. While institutions are beginning to use it for integrations, it doesn't have the same track record that the XML synchronisations have. The Pure development team has worked hard to build a stable and scalable API platform, but it should still be considered by institutions depending on their appetite for risk in the technologies that are used. Any breaking changes to the API format will be clearly outlined in the release notes for that version so make sure to always check this closely if you are building an ongoing integration using the API.
| Example of Notification of Breaking Changes in the Release Notes |
|---|
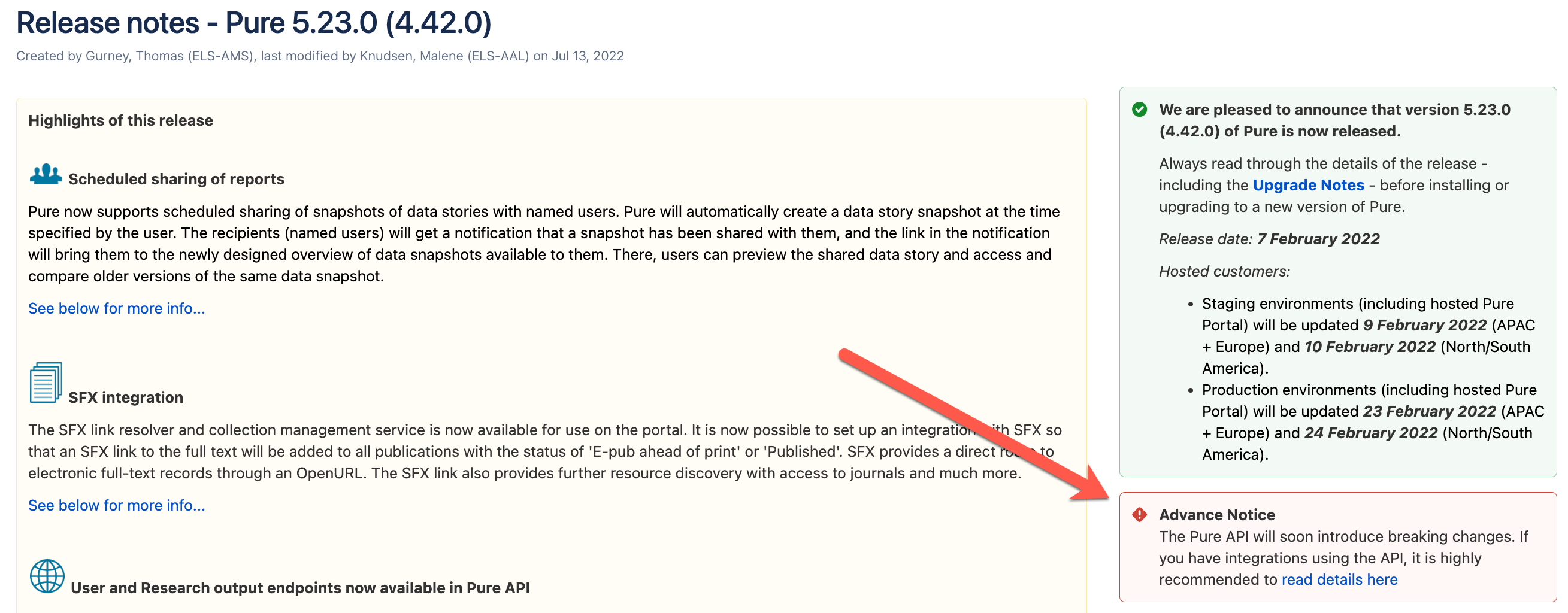 |
Error handling and logging
Summary logs for synchronisation jobs are kept within Pure with an overview interface showing the number of success, warning and error messages for each run. Additionally, the job can be configured to notify a specified email address if the log breaches a certain threshold of message/error level. There is no such functionality with the Pure API, as each create or update call will respond with its own status message. This means when building an integration using the Pure API, consideration needs to be given to how these error messages will be handled and surfaced, so that issues can be rectified. This also presents the opportunity for the integration to send the error and status messages to a central logging tool that may be used across all the organisation for other integrations. With the XML synchronisation this is not possible as all logs are stored internally in Pure.
| XML Synchronisation Logging in Pure | Sample API Error Response |
|---|---|
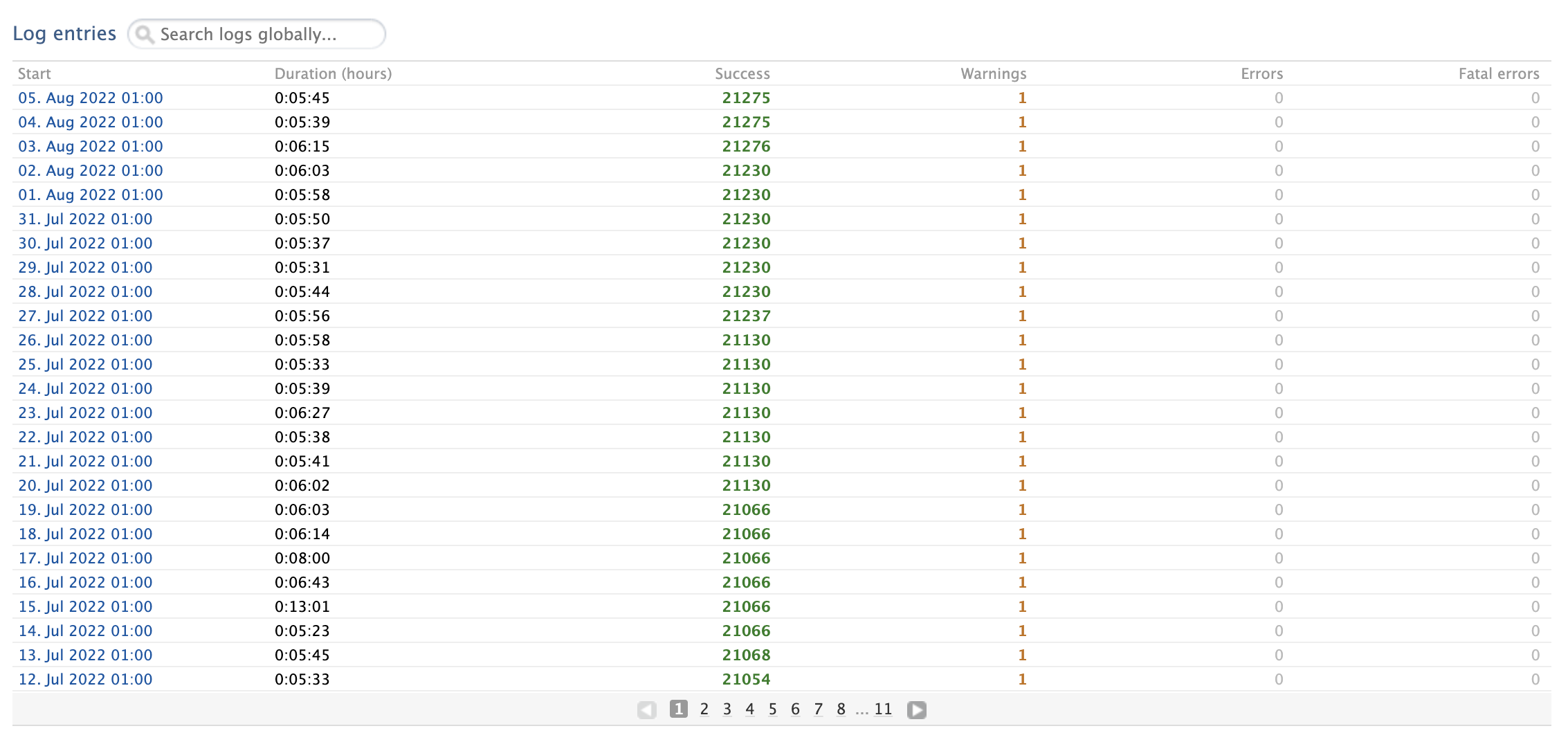 |
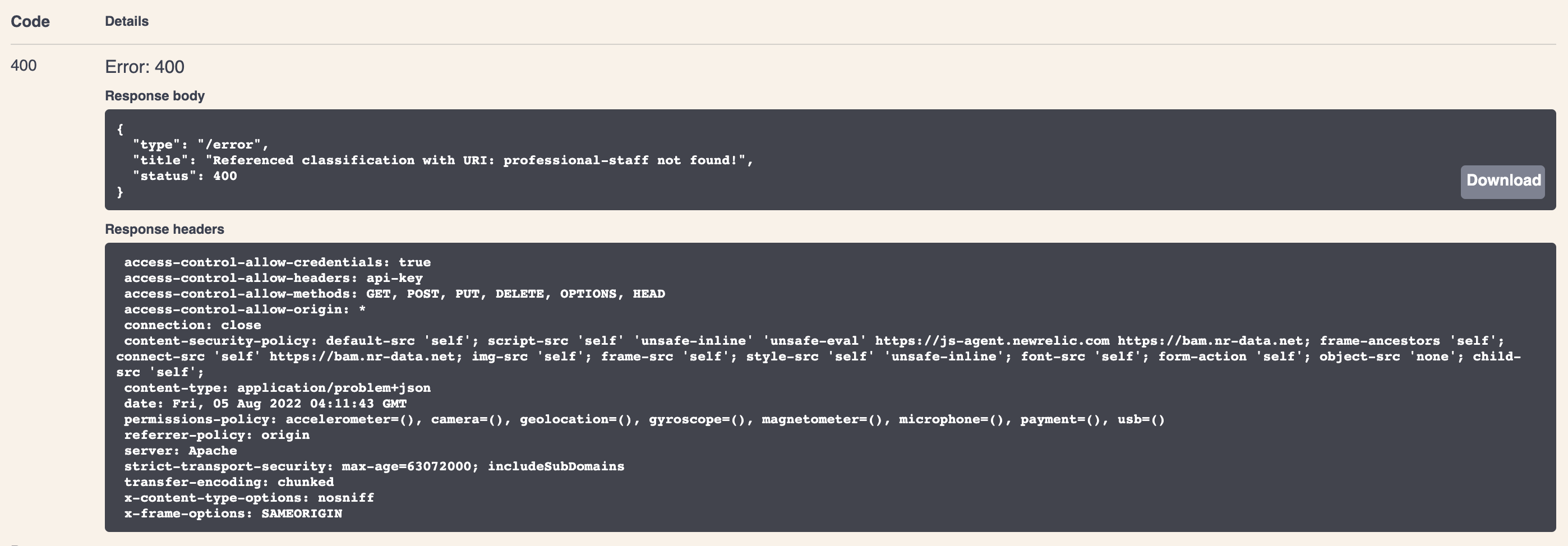 |
Coverage & Functionality
Not all content is presently available in Pure API. This may mean that some integrations are not presently possible via the Pure API and will have to be via XML. Inversely though, the Pure API has the benefit of being under active development, and as such new features are being included that may not have been possible via the XML Synchronisation. A key example of this is the addition of User Roles in 5.23.1, which for the first time, allows programmatic role management against users. This allows for more sophisticated provisioning of users (for instance, roles could be determined based on positions of staff or automatically allocated following approval of a service request). As the Pure API evolves this criteria is likely to be weighted towards the Pure API more as more content types are added and additional functionality included.
Broader applications
As outlined above, the XML synchronisation is purpose built for loading data from another system into Pure, with a complete set of data provided each time from the source of truth system. The Pure API allows for many more applications as it can create and update individual records as well as individual fields on those records. This means that integrations can be more targeted and event driven. For example, an integration might identify newly created applications in Pure, this integration then allocates space for them in the university's cloud storage before calling the Pure API to add the ID for this storage folder to the application.
Published at August 18, 2025