
How Can We Help?
5.18.05.18.0
Highlights of this release
 Expansion of available journal metrics from Web of Science
Expansion of available journal metrics from Web of Science
Pure is working hard to ensuring relevant metrics are supported, and easy to access and maintain. Pure now allows customers to capture the full suite of metrics from Web of Science (WoS) InCites Journal Citation Report (JCR), and WoS category Impact Factors. Metrics can be added manually to journals or uploaded in bulk using a .csv file downloaded from WoS and/or InCites.
 New: Global Reporter role - give access to use Reporting without giving Editing rights
New: Global Reporter role - give access to use Reporting without giving Editing rights
With this release, we have introduced global reporter roles for all content types. These new roles will grant access to the new reporting module, and it will be possible to report on the selected content types. It is now possible to open the new reporting module up for more users so they can start using the new reporting module. These roles can be combined with others to give access to the new reporting module for more users without having to provide editorial rights to users. If the global reporter roles are the only role that a user has, then the user can only see the new reporting tab, and use the new reporting module without being able to see the rest of Pure.
 Portal Homepage - Showcase your unique identity - New option to add 'hero image'
Portal Homepage - Showcase your unique identity - New option to add 'hero image'
Pure customers can now incorporate a large'"hero image', front-and-center on the homepage. People are highly visual, and high quality, full-screen imagery at the top of the portal landing page can help create a positive first impression, drawing them in to the Portal, while also showcasing what makes the institution unique. This is a taste of things to come, as we are working for future releases to enable more multimedia integration across the Portal, helping customers put their "best foot forward" at every level of their institution.
Portal Search: discover more efficiently and intuitively - search filter placement improved
Search filters are now in a persistent column on the left-hand side of the page, an experience more portal visitors would be familiar with from popular websites. This redesign makes search filters more prominent, their function more clear, and overall easier to use. Part of a continuing series of Portal user experience enhancements underway.
Watch the 5.18 New & Noteworthy seminar
We are pleased to announce that version 5.18.0 (4.37.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 9 June 2020
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 10 June 2020 (APAC + Europe) and 11 June 2020 (North/South America).
- Production environments (including hosted Pure Portal) will be updated 24 June 2020 (APAC + Europe) and 25 June 2020 (North/South America).
Advance Notice
Download the 5.18.0 Release Notes
last updated 8 June 2020
Webinars
Watch and listen to all our New and Noteworthy webinars which are available at our Pure Academy New and Noteworthy resource center.
1. Web accessibility news
We continue to work towards being fully WCAG 2.1 AA compliant by February 2021, by ensuring an accessible design in new features.
In addition to this ongoing work, we have implemented the following improvements to existing features:
1.1. Portal accessibility work
During this release, the Portal team continued our work towards making the Pure Portal fully WCAG 2.1 AA compliant. This time we focused mostly on improving the keyboard accessibility of the Portal.
While the development work was mostly completed, we were unfortunately unable to get these changes fully tested and verified in time to merge with this release, owing in part to the challenges presented by the current global situation. These improvements will therefore be held over until our next major release (5.19.0, coming October 2020).
2. Privacy and personal data
The protection of privacy and personal data is extremely important to Pure. Based on guidance provided by GDPR (and similar frameworks), we continually add improvements to how Pure handles sensitive data, and we continually provide tools for users to manage their own and others' data in Pure.
In this release, the following features that support the protection of user privacy and personal data have been introduced:
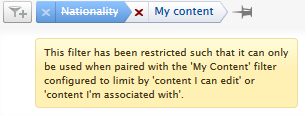
2.1. Configurable filters for sensitive person information
To alleviate potential stressors for customers in regards to their users having access to personal data, we have introduced dependency rules for filters. For non-administrative roles, filters that can isolate sensitive data will only be available when the My content filter is active. This removes the ability for users to filter on persons across the institution on sensitive data. Currently, this is limited to the Persons content type and Nationality filter, but can be expanded in the future, depending on customer needs.

Click here for more details...
Steps to enable the restriction and the effects of this restriction are shown below.
Instructions |
Screenshot |
|---|---|
|
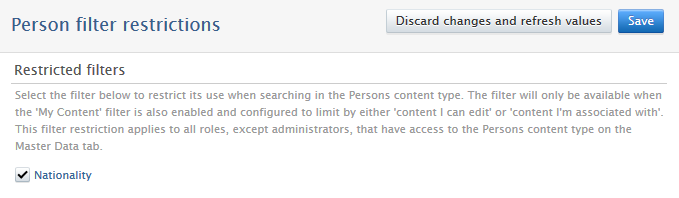
Enabling dependency filter To enable the dependency rules, navigate to Administrator > Persons > Person filter restrictions. Check Nationality and save the configuration. |
|
|
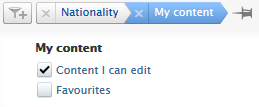
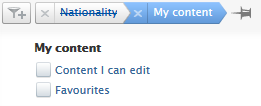
Dependency filter in action For all non-administrative, organization-level roles with access to the Persons content type on the Master data tab, if the filter dependency feature is enabled, users will not be able to use the Nationality filter. |
|
3. Pure Core: Administration
3.1. Configurable eligibility classifications for Funding Opportunities
Funding opportunity eligibility classifications were previously static and limited. Users with relevant roles can now extend and/or disable eligibility requirement classifications to cater for a broader range of criteria. This applies to both general eligibility requirements and academic degree eligibility requirements.
Click here for more details...
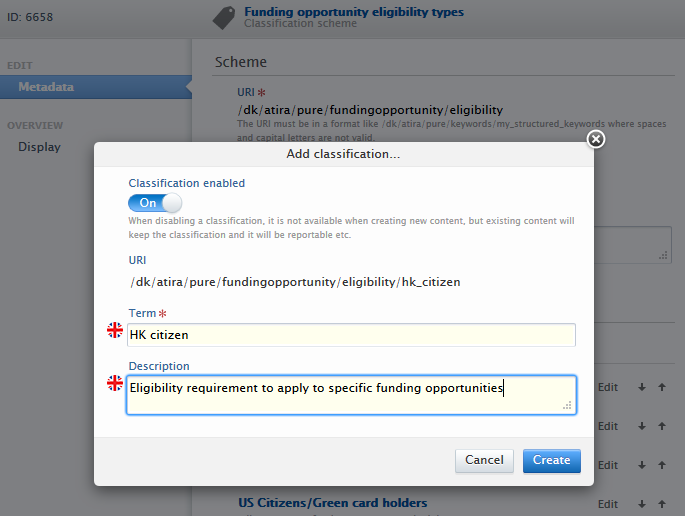
To add or modify eligibility requirement classifications, users with appropriate roles should navigate to Master data > Classification schemes then search for Funding opportunity academic degree eligibility types or Funding opportunity eligibility types.
Current classifications can be re-ordered using the arrow buttons, and modified or disabled using the 'Edit' button associated with each classification. New classifications can be added by clicking on 'Add classification', providing input in the 'Term' and 'Description' fields and clicking the 'Create' button.
3.2. Metrics
3.2.1. Expansion of journal metrics from Web of Science
The use of metrics to support research-based assessment and evaluations are common among Pure customers. The number of metrics available to institute administrators are increasing at a rapid pace and Pure is working hard to ensuring relevant metrics are supported, and easy to access and maintain. Pure now allows customers to capture the full suite of metrics from Web of Science (WoS) InCites Journal Citation Report (JCR), and WoS category Impact Factors. Metrics can be added manually to journals or uploaded in bulk using a .csv file downloaded from WoS and/or InCites.
Click here for more details...
The manual or upload addition of WoS metrics needs to be enabled in Administrator > System settings > Metrics > Enable relevant metrics and addition routes.
The full list of JCR metrics requires a subscription to InCites and the list of metrics now available to add to journals includes:
|
Rank JCR Abbreviated Title ISSN Total Cites |
Journal Impact Factor Impact Factor without Journal Self Cites 5-Year Impact Factor Immediacy Index Citable Items Cited Half-Life |
Citing Half-life Eigenfactor Score Article Influence Score % Articles in Citable Items Average Journal Impact Factor Percentile Normalized Eigenfactor |
Instructions |
Screenshots |
|---|---|
|
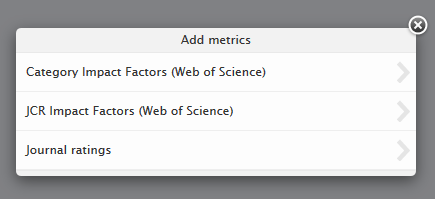
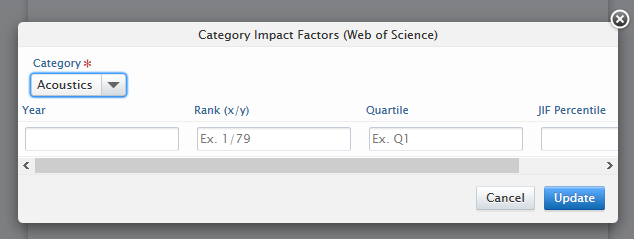
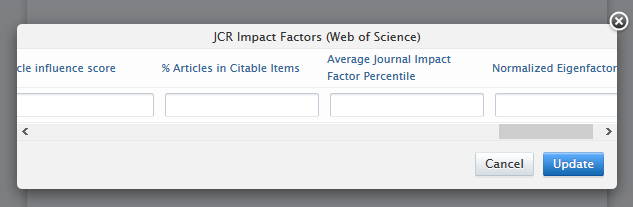
Manual addition of metrics to a journal Users with appropriate editing rights can add metrics found in the JCR Impact Factors report. and the WoS subject category metrics, by clicking on Add metrics on the Metrics tab of the journal editor. Users should select which journal metric they wish to add, and provide the relevant data in the appropriate column. Required fields are shown with a '*'. |
For Category impact factors
For JCR Impact Factors
|
|
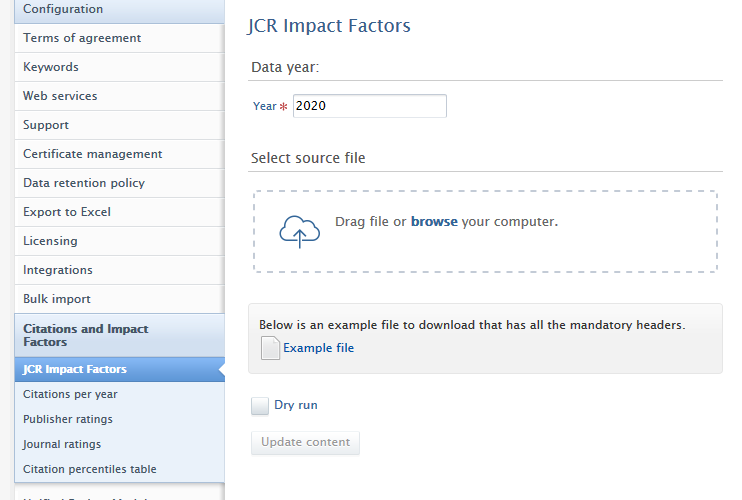
Upload of bulk journal metric data Administrators can upload journal metric data for the JCR Impact Factors, using the .csv upload feature in Administrator > Citations and Impact Factors > JCR Impact factors. A sample .csv file is provided for reference. The input file must match the column layout in the sample file. Selecting 'Dry run' will provide a short summary of changes, without affecting any data. To update the content, uncheck 'Dry run'. Not all fields require data for a succesful upload, but blank placeholders must be added if they are missing from the .csv file. Note: Users cannot upload WoS subject category metrics as WoS does not provide a .csv/.xlsx download option for these metrics. |
 |
3.2.2. Visibility of journal metrics in renders
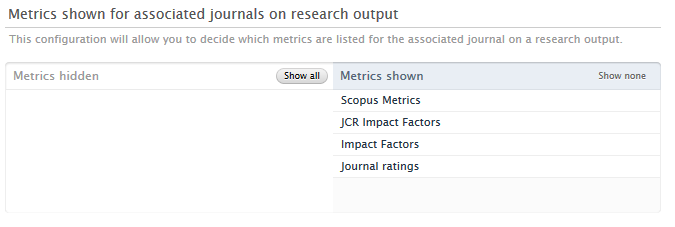
With an increasing number of available journal-level metrics, Administrators can now specify which journal metrics should be displayed in the short render of the associated journal on a research output.
Click here for more details...
Administrators can configure which metrics are shown on the short render of the associated journal by navigating to Administrator > Journal > Metrics visibility for associated journals
To hide metrics in the render, administrators should move the relevant metric to the left-hand column of the selector tool. Metrics in the right hand column of the selector tool will be shown in the render.
Note: this configuration only removes the journal metrics from the render on a research output. Users can still see all journal metrics on the metrics tab of a journal.
3.3. Automated search using Web of Science ResearcherID
Pure will now use any Web of Science (WoS) ResearcherIDs attached to a person profile for automated search. Support for using WoS' ResearcherID to search for content when importing from WoS as an online import source was introduced in 5.17.0 (see 5.17.0 release notes). We have now extended functionality such that the ResearcherID is now part of the automated search feature. Automated search using ResearcherID is only available with the premium WoS, not WoS Lite.
Click here for more details...
To add a ResearcherID, enable automated search on that ID and view import candidates resulting from this search follow the instructions below.
Instructions |
Screenshot |
|---|---|
|
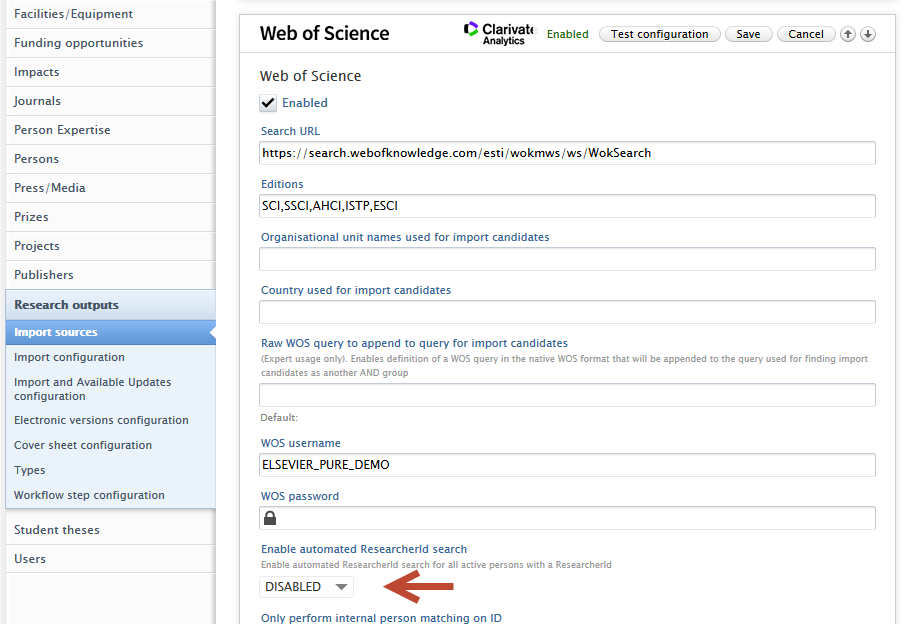
Enable Automated import via ResearcherID To enable, go to Administrator > Research output > Import sources > Web of Science then Enable automated ResearcherId search |
 |
|
Adding ResearcherID to person profile To add a ResearcherID to a person profile, within the Metadata menu tab of a person profile editor, select 'ResearcherID' from the ID Type drop down in the ID section. Enter the ID, click Create and save the person profile. |
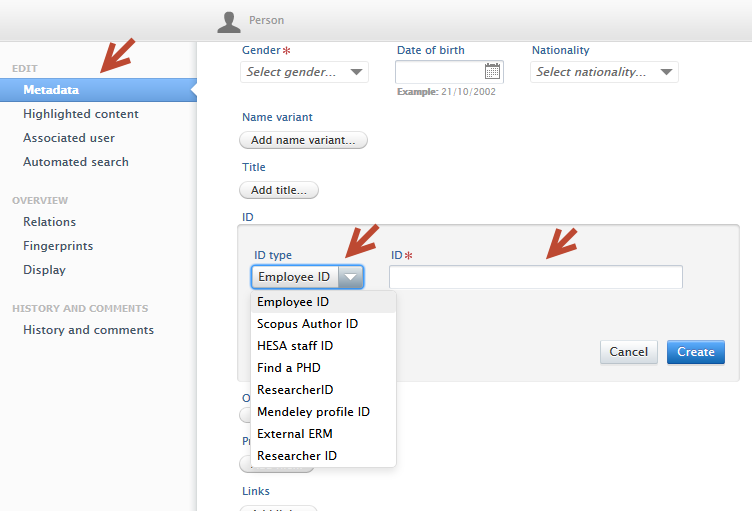 |
|
To enable automated search on ResearcherID From the Automated search menu tab of person profile editor, enable Web of Science. |
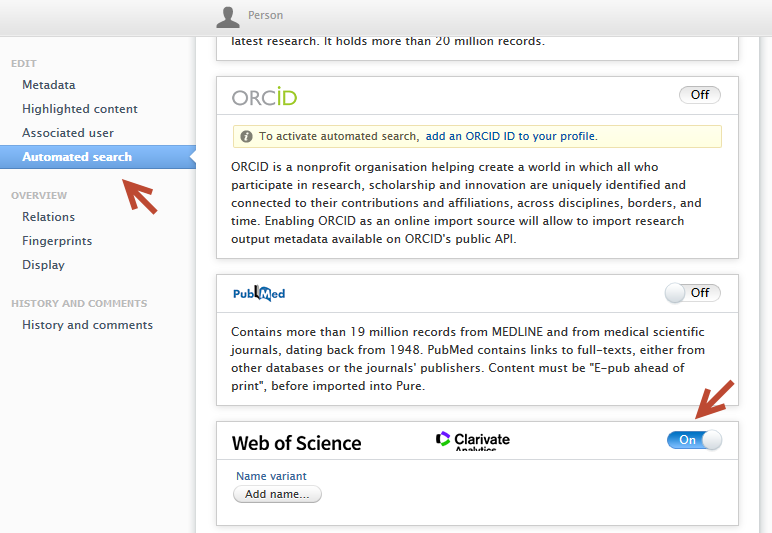 |
|
Viewing import candidates The cron job, Search for Import Candidates, will use the supplied ResearcherID to query Web of Science and add any results as import candidates in the Persons with import candidates filter under Research outputs on the main Editor tab. |
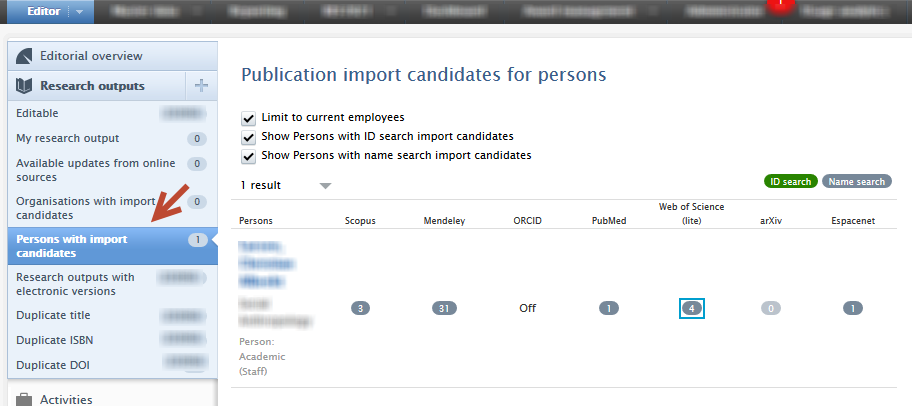 |
3.4. Scopus journal merge check and cleanup
We have introduced a job to clean journals that have had incorrect ISSNs/eISSNs erroneously added via import or automated means. The job will search for all ISSN/eISSNs on a journal record and check via Scopus that the identifiers are correct for that journal. Any incorrect assignments will be corrected and any related content will be checked via their original record and assigned to the correct journal. This job will not correct manually merged journals.
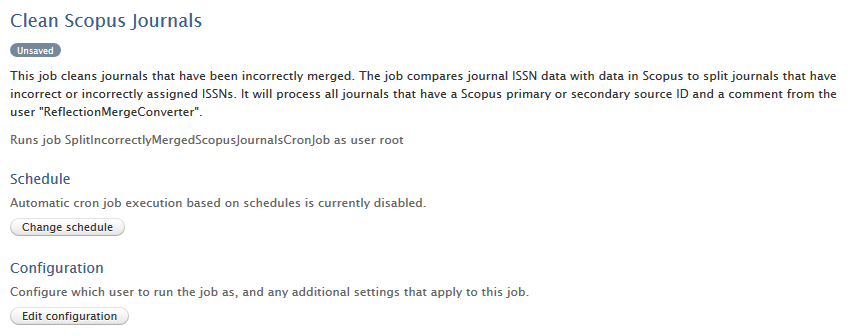
Click here for more details...
To enable this job, administrative users should search for the job title 'Clean Scopus Journals' in Administrator > Jobs, and the job can be configured to run at a specific schedule. Dry-run mode is available to examine results of the process before they are committed.
Results of the job can be viewed in the job log, and contains information about the journal being cleaned and resultant new journals. The actions of the job can also be viewed in the audit log.

3.5. Continuous export of Pure data and control of data usage permissions
Pure data export has always been requested on an ad-hoc basis for a specific issue or feature. To make it easier for customers, and for us to be able to deliver a better service and product, it is now possible to enable data export as a continuous export. For full transparency, we have expanded on the options of filtering out sensitive data, which are excluded by default. Customers will always have the ability to opt-out of continuous data export if they no longer want to send data to us.
Click here for more details...
The feature is still located under Administrator > Support > Database export. For a more thorough description of how we manage customer data, refer to the wiki page Customer Data Management .
If a customer opts in for the continuous export functionality:
- Each month an export of the customer's data will be sent to the Elsevier Pure team, where the customer is in control of what we are allowed to use the data for.
- The export will be sent at the end of the month and will be retained for 35 days, and then automatically deleted.
Instructions |
Screenshot |
|---|---|
|
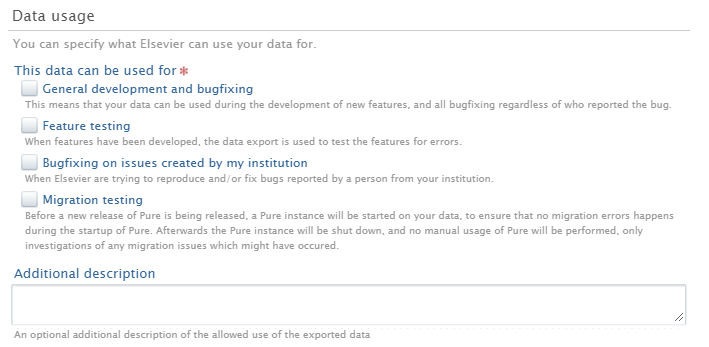
Data Usage The following data usage options are available. Customers must select at least one option. An explanation of each option is provided below: General development and bug fixing
Feature testing
Bug fixing on issues created by my institution
Migration testing
|
 |
|
Sensitive data Customers can clearly specify whether sensitive data should be included in a data export. By default no fields are included. Note: your institution may have more options, depending on your modules. |
 |
|
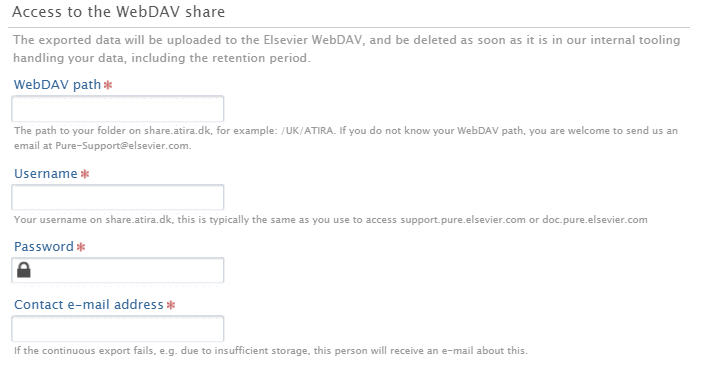
WebDAV share
Note, WebDav is deprecated from primo April 2024. Data dumps are now stored in Amazon Web Services (AWS)
Customers need to specify access to our WebDAV share, where the dump will be upload, and later removed as soon as it is in our internal systems. If you need help in completing this, please reach out to Pure-Support@elsevier.com. Once configured and saved:
One time data extraction Customers still have the option to send data as a one-time export. The same configuration options regarding data access, and sensitive data can still be specified in the WebDAV share configuration. One time exports with different data restrictions can be made even if you have continuous export configured. |
 |
4. Pure Core: Web services
4.1. Updated ResearchOutput POST publishedBeforeDate and publishedAfterDate
To simplify querying using publishedBeforeDate and publishedAfterDate we have changed its type from a datetime to a date. Going forward you now query without time, as this is redundant in regards to the field itself in Pure.
Old query example:
<?xml version="1.0"?><researchOutputsQuery><publishedBeforeDate>2019-01-01T00:00:00.001Z</publishedBeforeDate></researchOutputsQuery> |
New query example:
<?xml version="1.0"?><researchOutputsQuery><publishedBeforeDate>2019-01-01</publishedBeforeDate></researchOutputsQuery> |
4.2. Updated type of hostedPublicationTitle, hostedPublicationSubTitle, and publicationSeries.name to reflect that they are based on formatted values.
New type injects attribute 'formatted' into the XML elements hostedPublicationTitle, hostedPublicationSubTitle, and publicationSeries.name.
New result example:
<publicationSeries><publicationSerie pureId="18577"><name formatted="true">Name</name></publicationSerie></publicationSeries><hostPublicationTitle formatted="true">Host Publication</hostPublicationTitle><hostPublicationSubTitle formatted="true">Sub Title</hostPublicationSubTitle> |
4.3. Added support for querying for book series journals on Research Output
If you have configured the Pure research output model to have book series as journals you can now query for them using a POST query.
New POST example:
<researchOutputsQuery><forBookSeries><uuids><uuid>5698fdcc-7f73-4fb3-9b9f-e40faf87ddbf</uuid></uuids></forBookSeries></researchOutputsQuery> |
4.4. Added organizations support to Pure API
The early access Pure API now supports the management of organizations in addition to external organizations.
Click here for more details...
The Pure API is an evolution of the existing REST web services, to support a backwards-compatible read and write REST JSON endpoint for using and managing research information data in Pure.
In order to achieve these objectives, we've made several changes to how the web service endpoints are structured and the format of the managed entities in the new API.
- The endpoints for an entity are structured so it is clear where you can expect REST or RPC semantics - this should make it easy for developers to interact with the API with a minimal upfront time investment
- The entity format is optimized in regards to JSON data modelling best practices and with an expectation of the model evolving in a backwards-compatible manner in the future
- The API specification is defined and published as an OpenAPI 3 specification enabling service users to quickly generate a client while at the same time providing developers with useful documentation on the API and its semantics
- The entity API includes several helper operations that return the allowed values for the different parts of the entity model where this is relevant - this should make it easy for developers to submit valid changes to the write portions of the API
- All modification requests are made on behalf of a specified Pure user and clearly audit logged with both user and API key details
- As we expect the API to be able to support older clients updating against a newer version of the API all PUT requests have JSON merge patch semantics - this ensures that older clients do not inadvertently clear new properties that they don't know about
When the module has been successfully enabled a Swagger UI representation of the OpenAPI 3 specification will be available at https://{your Pure hostname}/ws/api/api-docs/index.html?url=/ws/api/openapi.yaml . Alternatively the latest API on the development community sandbox server can be found in this Swagger UI. A sample Java client that can be used as a starting point for developing a client can be found on the GitHub page.
Information |
Screenshot |
|---|---|
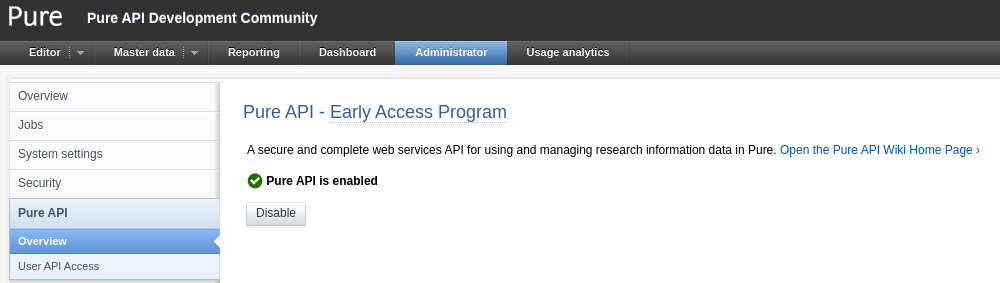
|
The early access Pure API can be enabled in the Pure administrator section. Please note that enabling or disabling the Pure API module requires a restart of Pure in order to take effect. |
 |
All use of the new endpoints requires an API key that is generated in the "User API Access" section of the "Pure API" administrator pages.
The main difference from the existing web service API keys is that the new Pure API requires a user that the system using the API key will act on behalf of.
5. Integrations
5.1. ORCID Updates
In this release we have made a number of updates to the ORCID integration:
5.1.1. Update to configuration of publication export
It is now possible to configure which publications should be exported to ORCID based on the publication status.
Click here for more details...
The ORCID configuration can be found by going to Administrator > Integrations > Export to ORCID. A new section, Publications, can be found.
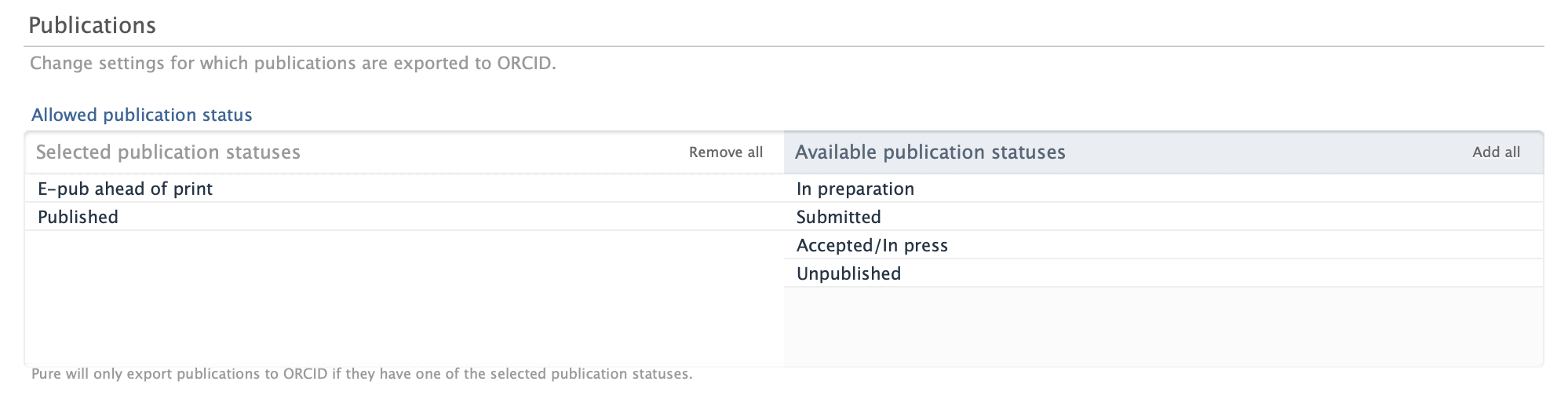
In this section customers can change the settings for which publications should be exported to ORCID.
In the new Allowed publication status configuration, you can choose which publications should be exported to ORCID based on their publication status.
The default value is to only export E-pub ahead of print and Published, but you can select any publication statuses that you want to export to ORCID.
5.1.2. Update to configuration of affiliations export
The configuration has been updated with two new settings, Export detailed affiliations and Export only active affiliations
Click here for more details...
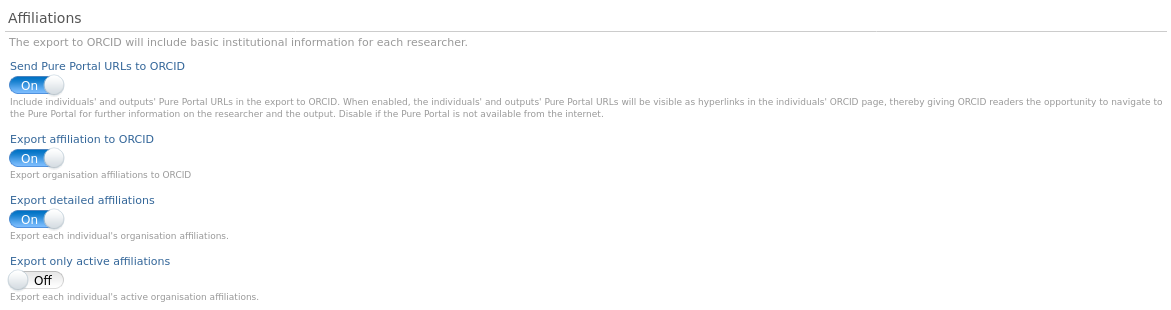
Enabling Export detailed affiliations will export all the person's staff and student affiliations, creating an employment in ORCID for each staff affiliation and an education for each student affiliation.
The following fields from the selected root organization are populated in ORCID:
- Organization
- City
- Country
For each affiliation the following data is added:
- Department
- Role
- Start/End dates
Enabling Export only active affiliations will only export the person's active staff and student affiliations.
5.1.3. Update to configuration of sync of former persons
It is now possible to configure whether or not Pure should sync former persons with ORCID.
Click here for more details...
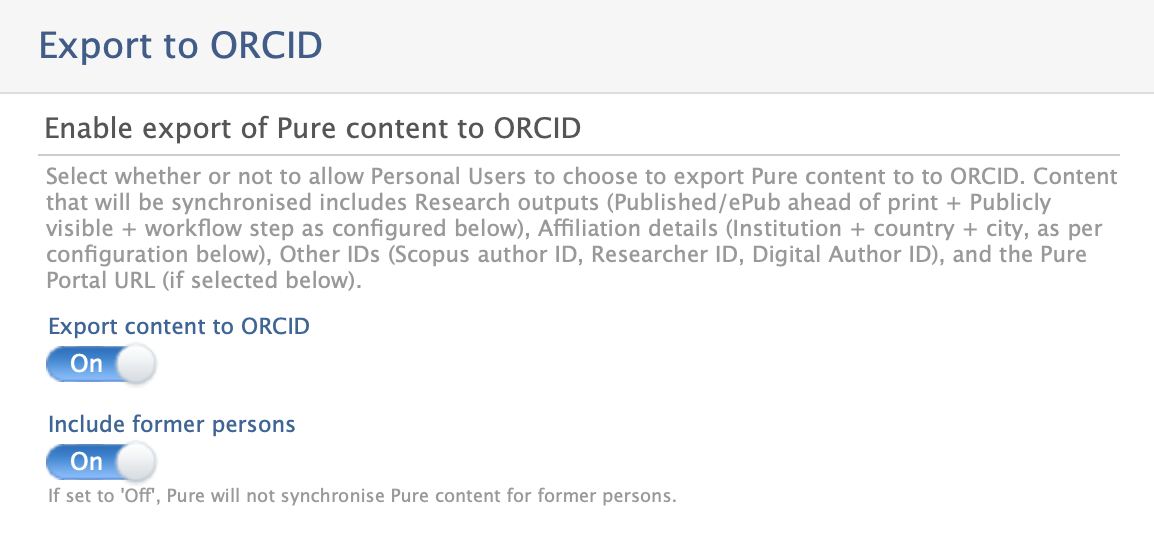
By default, Export to ORCID is enabled.
Disabling Include former persons will skip former persons when synchronizing ORCID. Content exported to ORCID from Pure will not be deleted for former persons.
Enabling Include former persons will have pure synchronize former persons as well as active persons.
5.2. DBLP integration
In this release we have added the integration to the DBLP computer science bibliography, a comprehensive database containing open bibliographic information on more than 5 million scientific publications.
Click here for more details...
Instructions on how to enable, add and search for content from DBLP are shown below:
Instructions |
Screenshot |
|---|---|
| To enable DBLP as an import source, go to Administrator > Research Output > Import Sources | 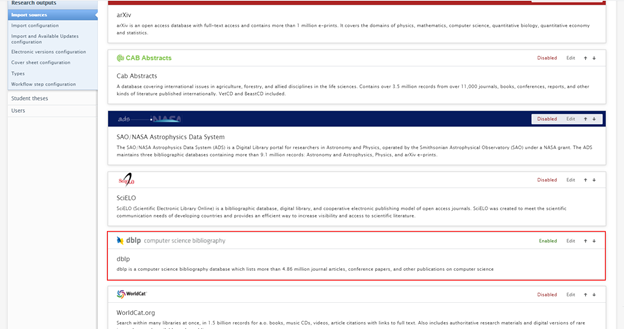 |
| To search and import content, go to ‘Add content’ and in Research Output > Import from online sources select ‘dblp’. | 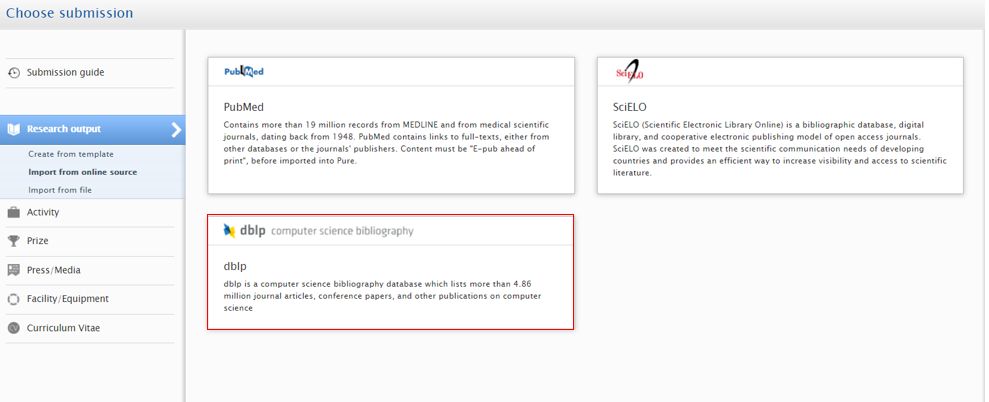 |
|
Search for content using the search bar. It is then possible to import or remove import candidates. Note: if an import candidate is removed, it will not be included in future searches. |
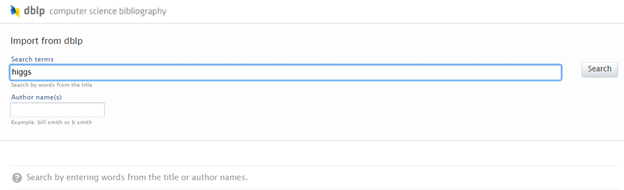 |
5.3. SCIELO integration - Improvements
The Scientific Electronic Library SCIELO is an open bibliographic database covering a selection of scientific journals. Initially covering scientific literature from Brazil, it now indexes research from 16 countries in South America and South Africa. In this release we have improved the integration with SCIELO by introducing additional fields to search for content.
In addition to searching for content by using words from the Title, Abstract, Author Names, Organizational Unit, and DOI, the following fields have been introduced:
- Publication date (by year range)
- Keywords
Click here for more details...
Instructions on how to enable, add and search for content from SCIELO are shown below:
Instructions |
Screenshot |
|---|---|
| To enable SCIELO as an import source, go to Administrator > Research Output > Import Sources | 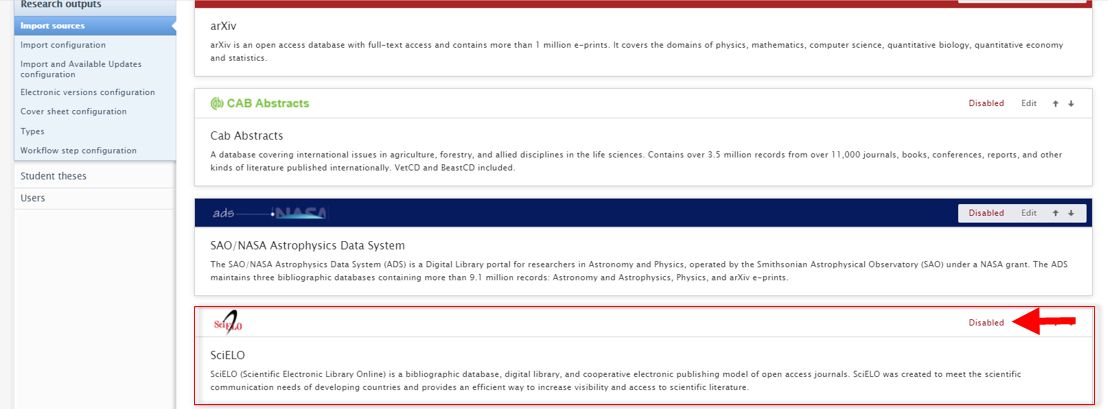 |
| To search and import content, go to ‘Add content’ and in Research Output > Import from online sources select ‘SCIELO’. | 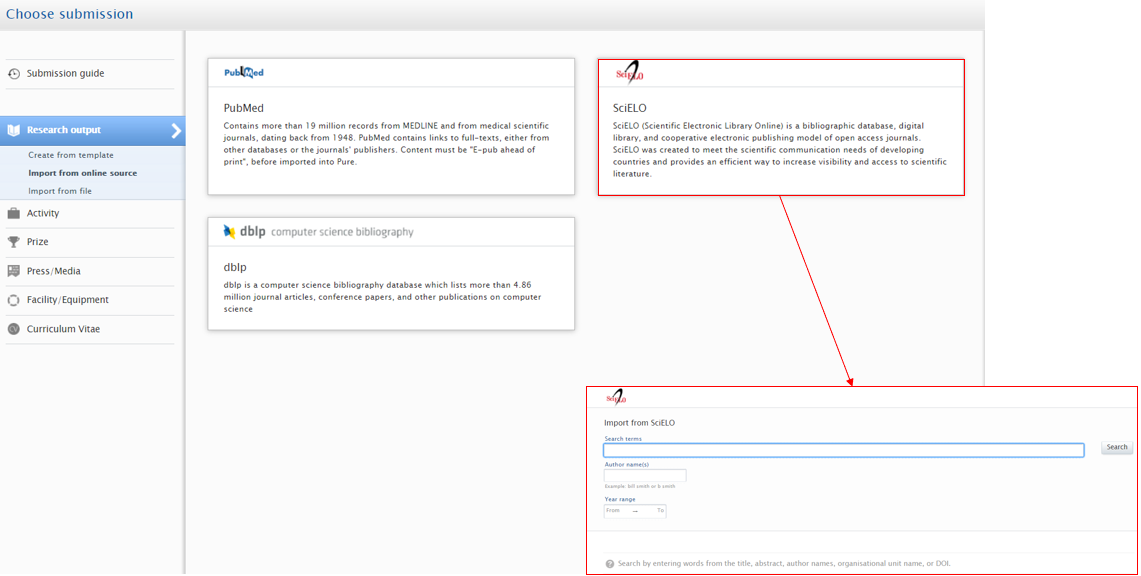 |
5.4. Jisc Publications Router Integration
In this release we have added integration to the Jisc Publication Router. The Jisc Publications Router provides a way for Pure customers to receive notifications from publishers whenever a publication with their affiliation has been added or updated. By bypassing indexing services such as Scopus or WoS, the Jisc router speeds up the import of relevant content into Pure.
In addition to reducing your Institution's administrative effort and maximising discovery and distribution of content, The Jisc Publications Router helps institutions comply cost-effectively with the Open Access policies of research funding bodies, currently valuable to UK customers considering the upcoming REF.
Access to the Jisc Publications Router is currently limited to UK customers. Before using the router integration in Pure, your institution will need to have an account set up and an agreement in place with Jisc – details available at https://pubrouter.jisc.ac.uk/about/start-up-guide-for-institutions/
Click here for more details...
Setup instructions
Instructions |
Screenshot |
|---|---|
| To enable the integration with Jisc Publications Router, in Administrator > Research Output > Import Sources set the 'Jisc Publications Router integration' to ON. | 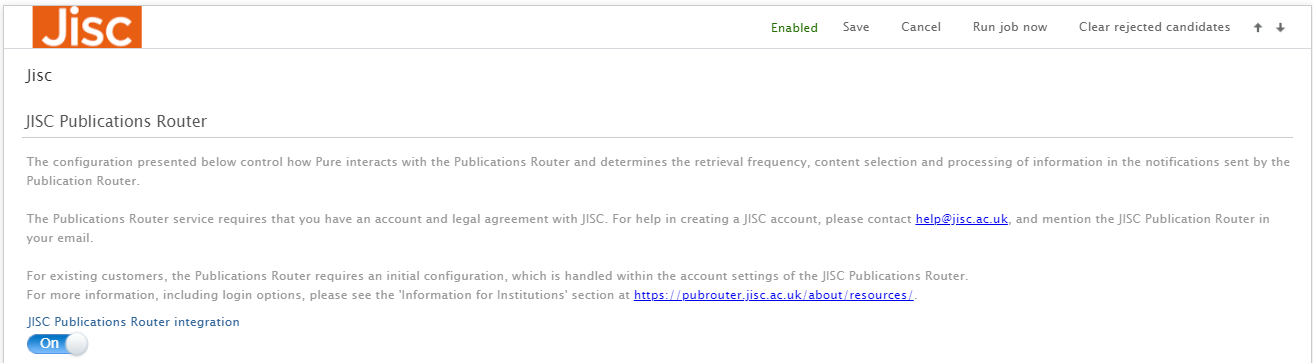 |
| In the 'Configuration' tab insert Account ID and API Key: | 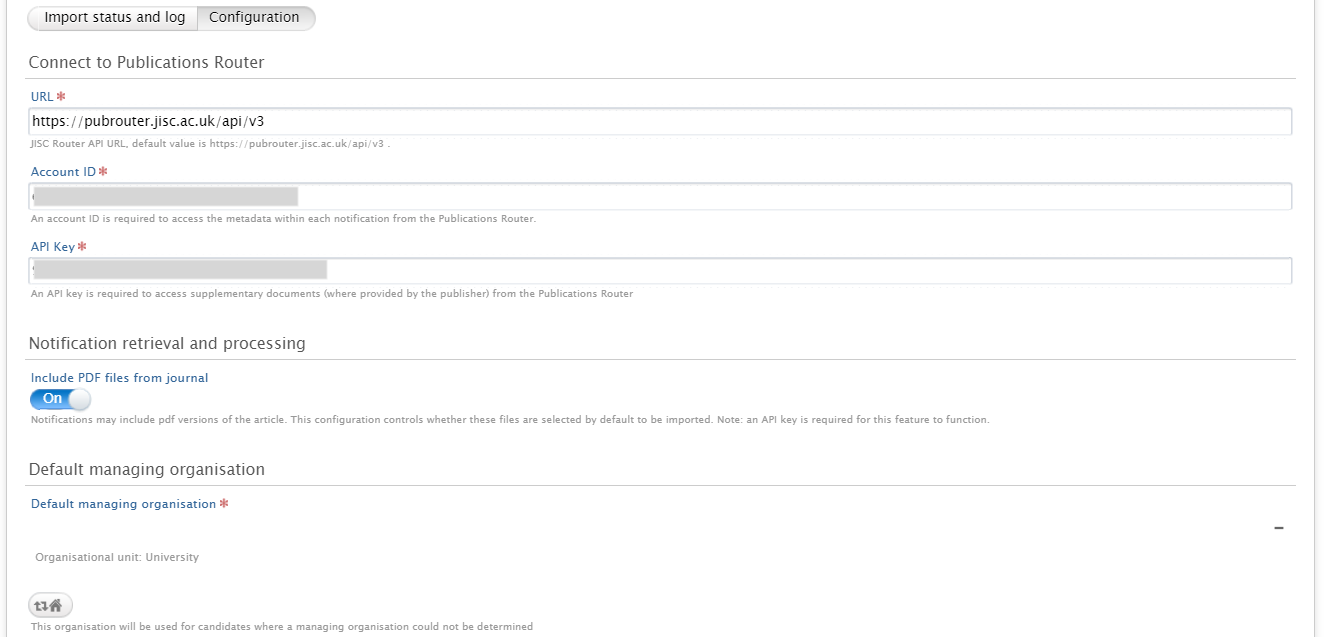 |
|
By default 'Notification retrieval and processing' is turned ON, meaning that if a pdf version of a record is found this will automatically be imported. It is possible to toggle this option OFF; in this case when a new import canddate is found it will still be possible to select the attached pdf file, when available. Once the integration has been setup, the job will run in the background and find import candidates. This job is configured to run once per day, between 06:00 and 08:00 (the exact time is randomized as to stop all Pure instances to begin querying the Jisc API at the same time). The job can also be triggered manually by selecting 'Run Job now' |
 |
Import and Update Candidates
Once the integration has been enabled, import candidates can be found in Research Output > Organizations with import candidates. Records will be shown for the default managing organization.
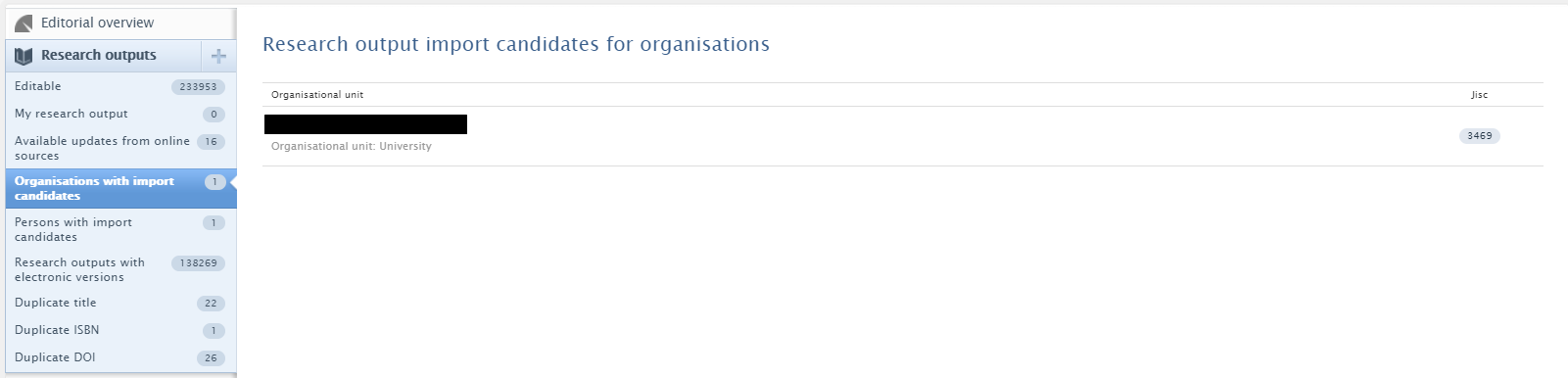
Update candidates are created if a match is made on either DOI or PubMed ID. It is then possible to import or reject candidates. Once candidates have been rejected, they will not be shown when the synchronization runs again.
Rejected candidates can be cleared by clicking "Clear rejected candidates" on the Jisc Router job configuration.
5.5. Elsevier Funding Database
In this release, the NIH grant feed for the synchronization of and Institution's awards and projects has been replaced by the Elsevier Funding Database (previously known as FROS Awards Service). In addition to awards and projects funded by the NIH, the Elsevier Funding Database comprises a number of different funders, and the service will be expanded in future releases of PURE to include data from additional funders such as the Federal Reporter and the NSF.
The jobs related to the Elsevier Funding Database can be found in Administrator > Jobs > Cron job scheduling, under 'Award Synchronization' and 'Project Synchronization (New)'.
Click here for more details...
To update, the following steps need to be performed on each job's configuration pages
For 'Award Synchronization' job
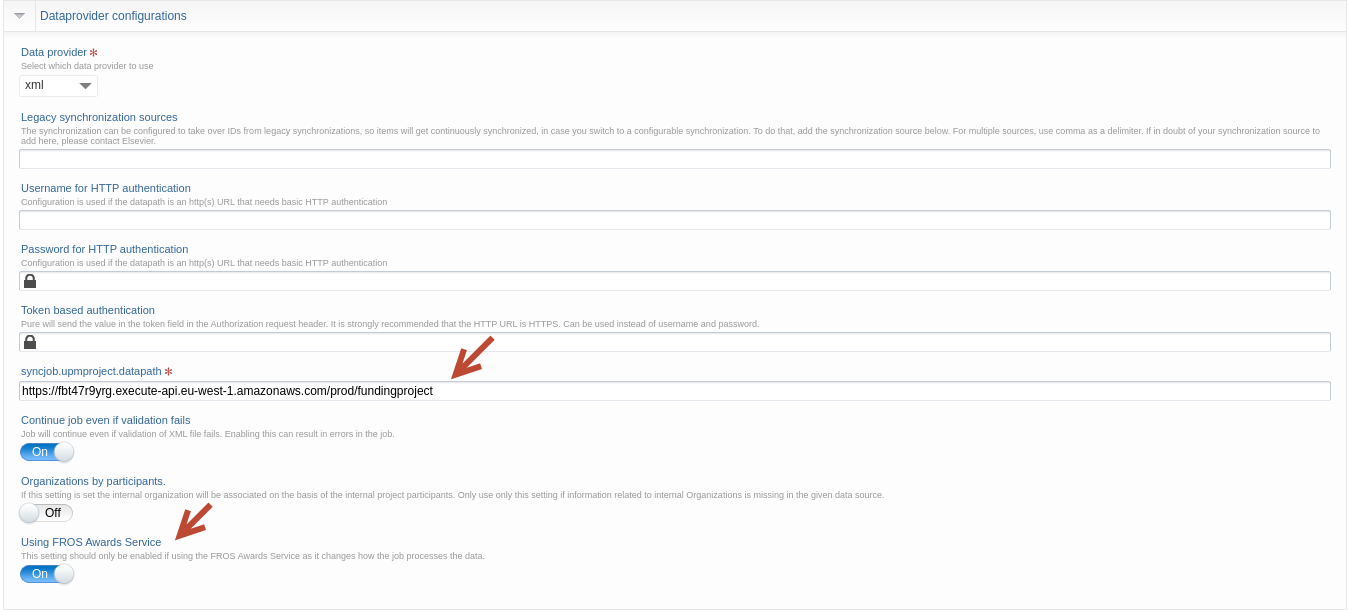
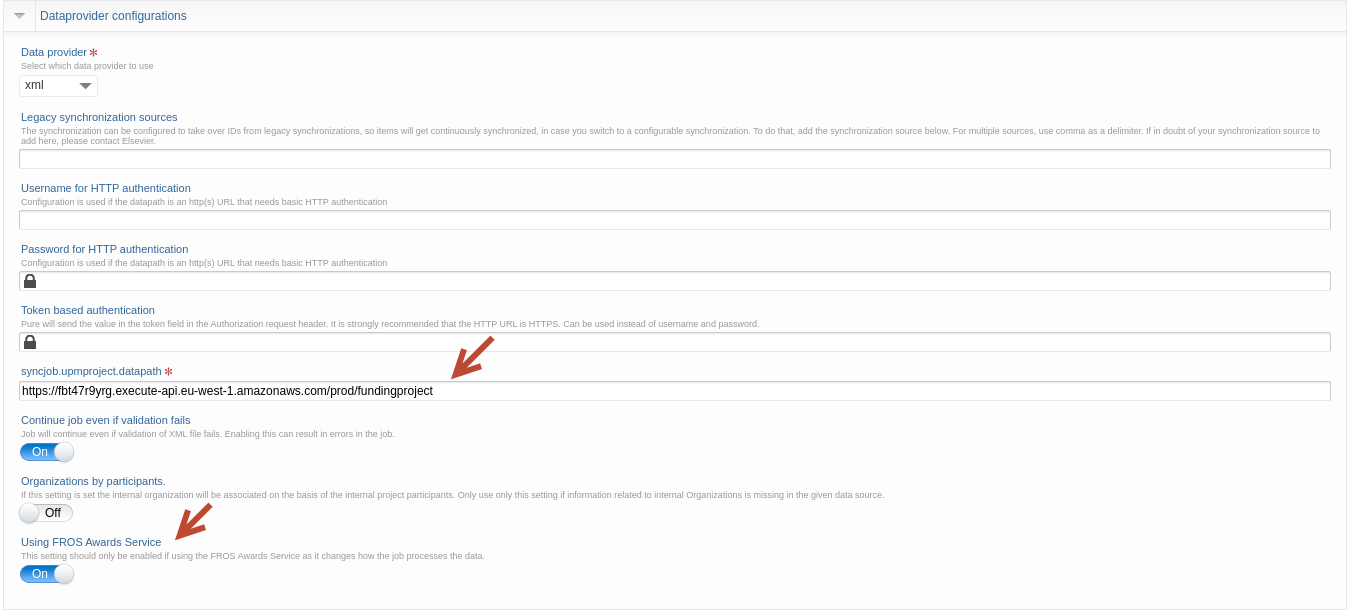
Go to Dataprovider configurations, update:
- The url to: https://fbt47r9yrg.execute-api.eu-west-1.amazonaws.com/prod/fundingaward
- Make sure to toggle on: ‘Using FROS Awards Service’
To allow the job to continue running when pre-existing awards are found, under Synchronization configuration update, toggle on 'Continue even if duplicate ids exist':
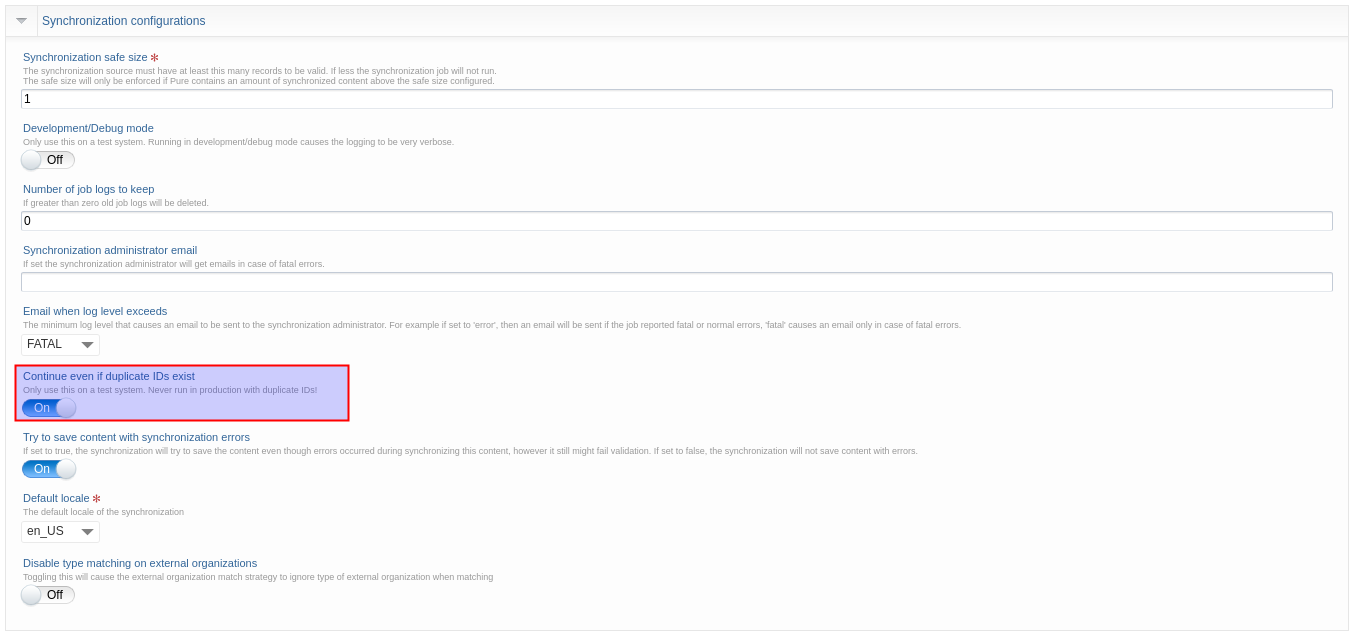
For 'Project Synchronization (New)' job
Under Dataprovider configurations, update:
- The url to: https://fbt47r9yrg.execute-api.eu-west-1.amazonaws.com/prod/fundingproject
- Make sure to toggle on: Using FROS Awards Service
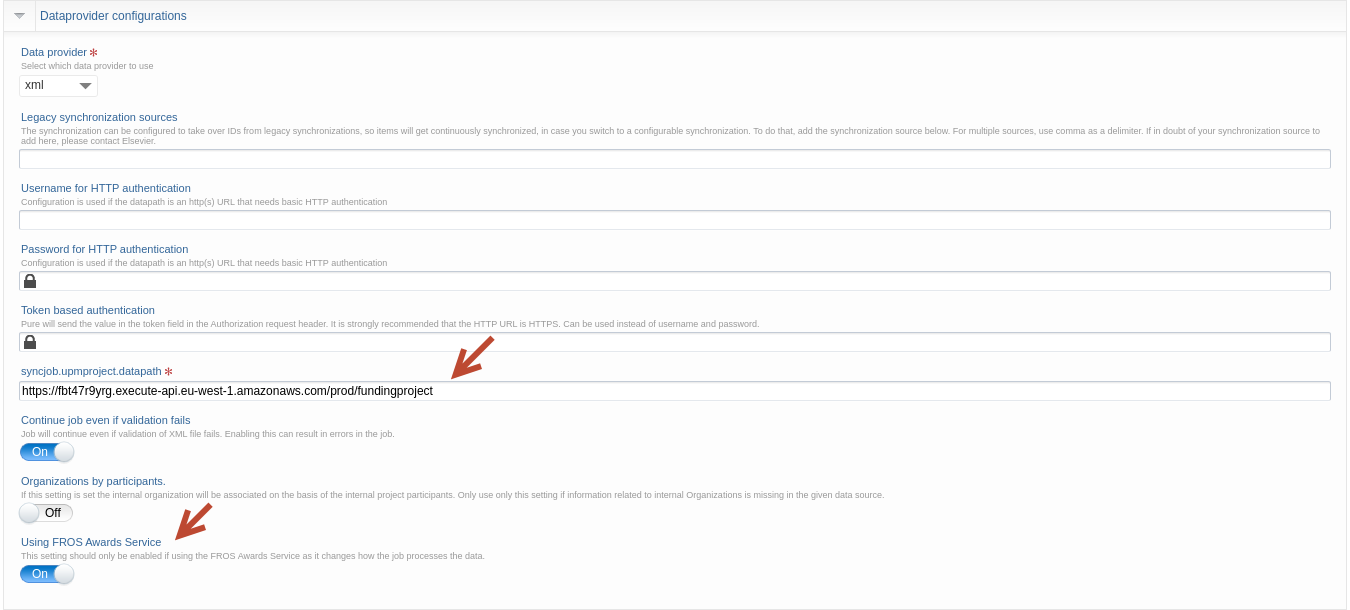
Under Synchronization configuration update, toggle on: 'Continue even if duplicate ids exists':
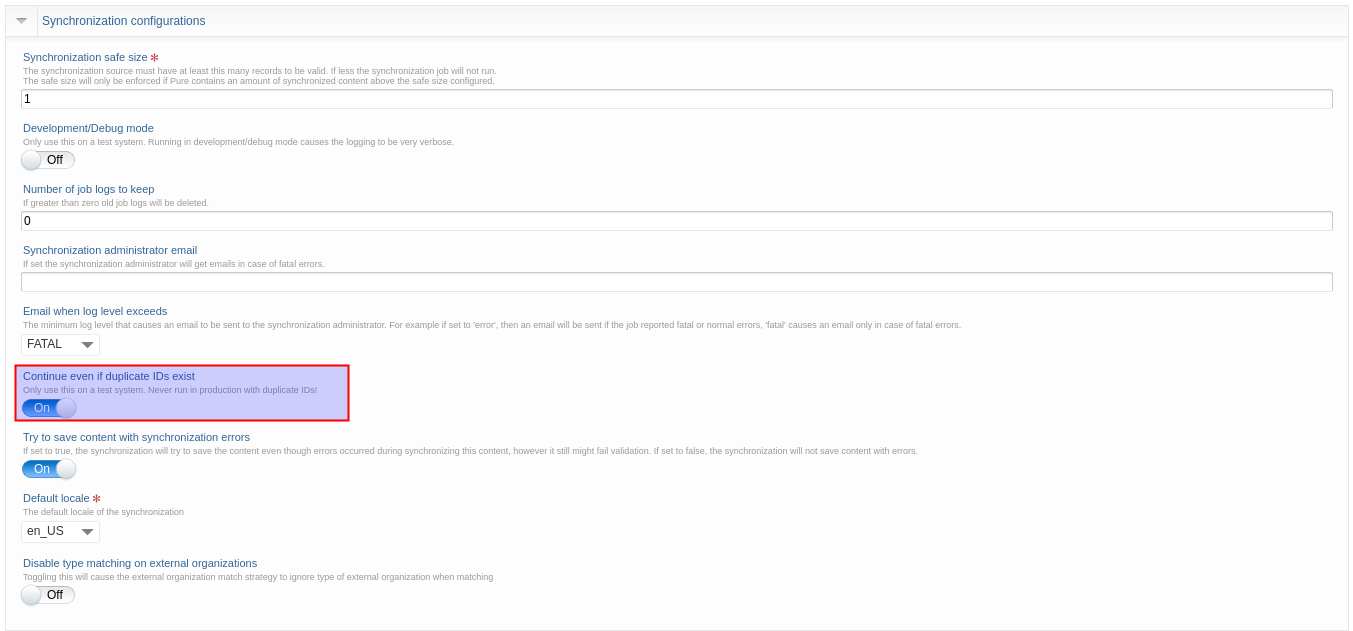
5.6. CAFE feed integration
In this release we have completed the integration with CAFE, a cloud-based process which provides notifications when content has been added to, updated, or deleted from ScienceDirect and/or Scopus.
Through the CAFE feed it is possible to import a number of journal-level metrics, such as:
- Number of publications
- Citations
- Citescore
The CAFE feed can be found in Administrator > Jobs > Cron job scheduling, under 'Scopus: Update/Create journals and metrics'.
5.7. PRS/QABO Publication Import Job - Improvements
We are pleased to announce that in release 5.18 we have included improvements to the PRS/QABO publication import job. While this job previously only matched internal persons that were profiled, this has now been changed to match non-profiled internal persons on Scopus IDs. As a result this will stop
- the creation of external persons where the person was actually internal
- the creation of external person records for internal persons that were profiled
There are still a few edge cases where a duplicate person might get created if the person is formerly profiled. The duplicate will in most cases be deleted by Master Data clean up job, which is a part of the QABO/PRS sequence of jobs.
We will continue to work on this job in the next releases to further improve matching on persons and to make this overall service more robust. For more information and updates on the QABO , see PRS/QABO related issues.
6. Unified Project Model and Award Management
6.1. Non-Latin characters in classification URIs
Pure now supports the addition of non-Latin characters when creating project, award or application types. Configurable types must first be enabled via Administrator > Unified Project Model > Enable configurable types then Enable.
To add/modify types, users should navigate to Administrator > Applications > Types.
7. Pure Portal
7.1. Portal Homepage - Showcase your unique identity - New option to add 'Hero image'
With our ongoing redesign of the Pure Portal, we aim to increase the visual impact of key landing pages while also allowing for a stronger integration of your insitutional brand.
In this release we are happy to announce the first major feature of this redesign, our bold new 'hero image' that will be displayed on the front and center of the homepage of your Portal. With this, you can now ensure your Portal stands out from the crowd while showcasing what makes your institution special:
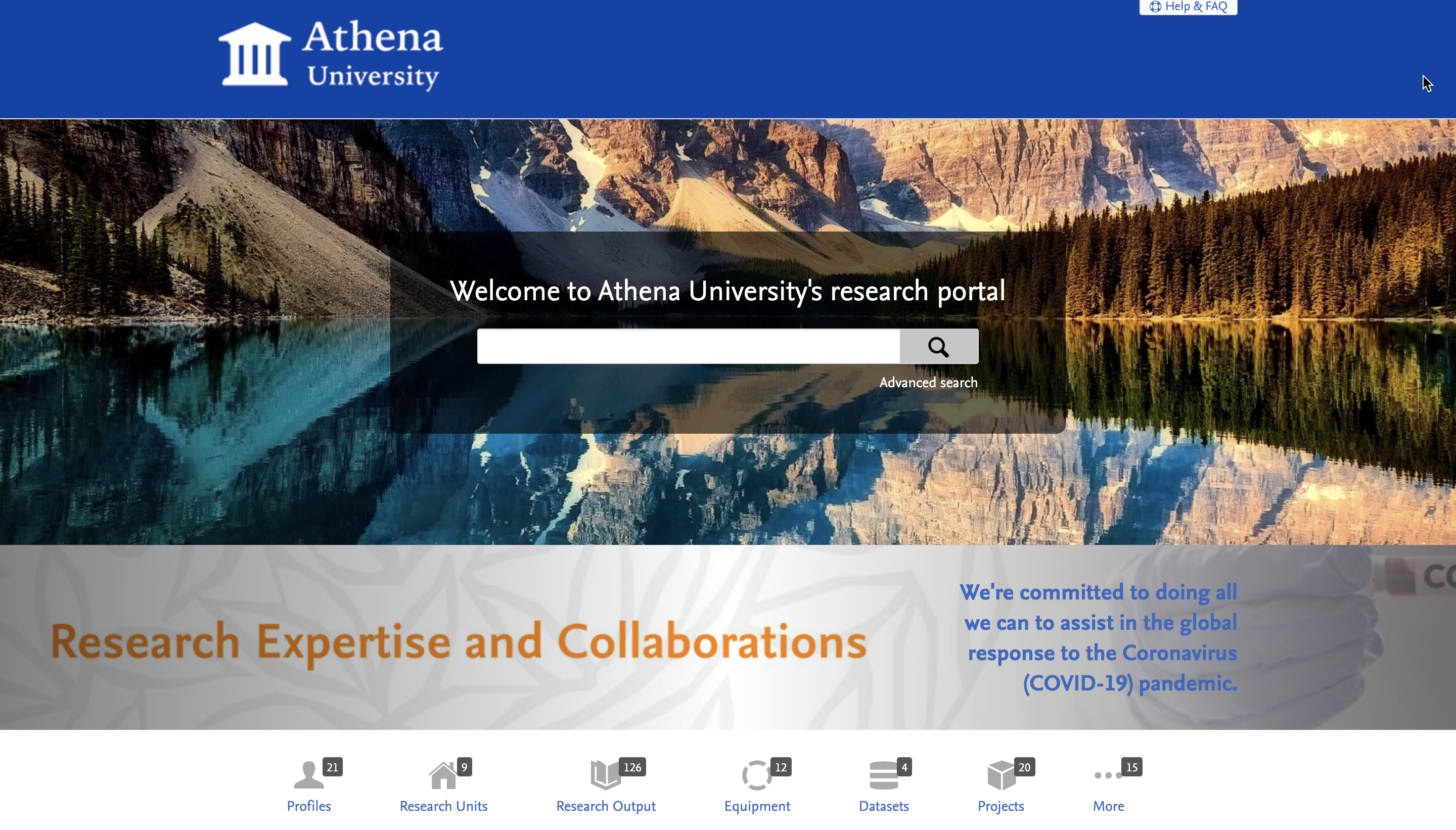
This is not only key to the new look of the homepage, but also lays the foundations for an improved visual display throughout the Portal and how we will be introducing more space for images and other multimedia elements such as video.
Click here for more details...
Adding your hero image is simple. Go to Pure Portal > Administrator > Styling and layout and scroll down to the bottom of the page to Homepage 'hero image'':
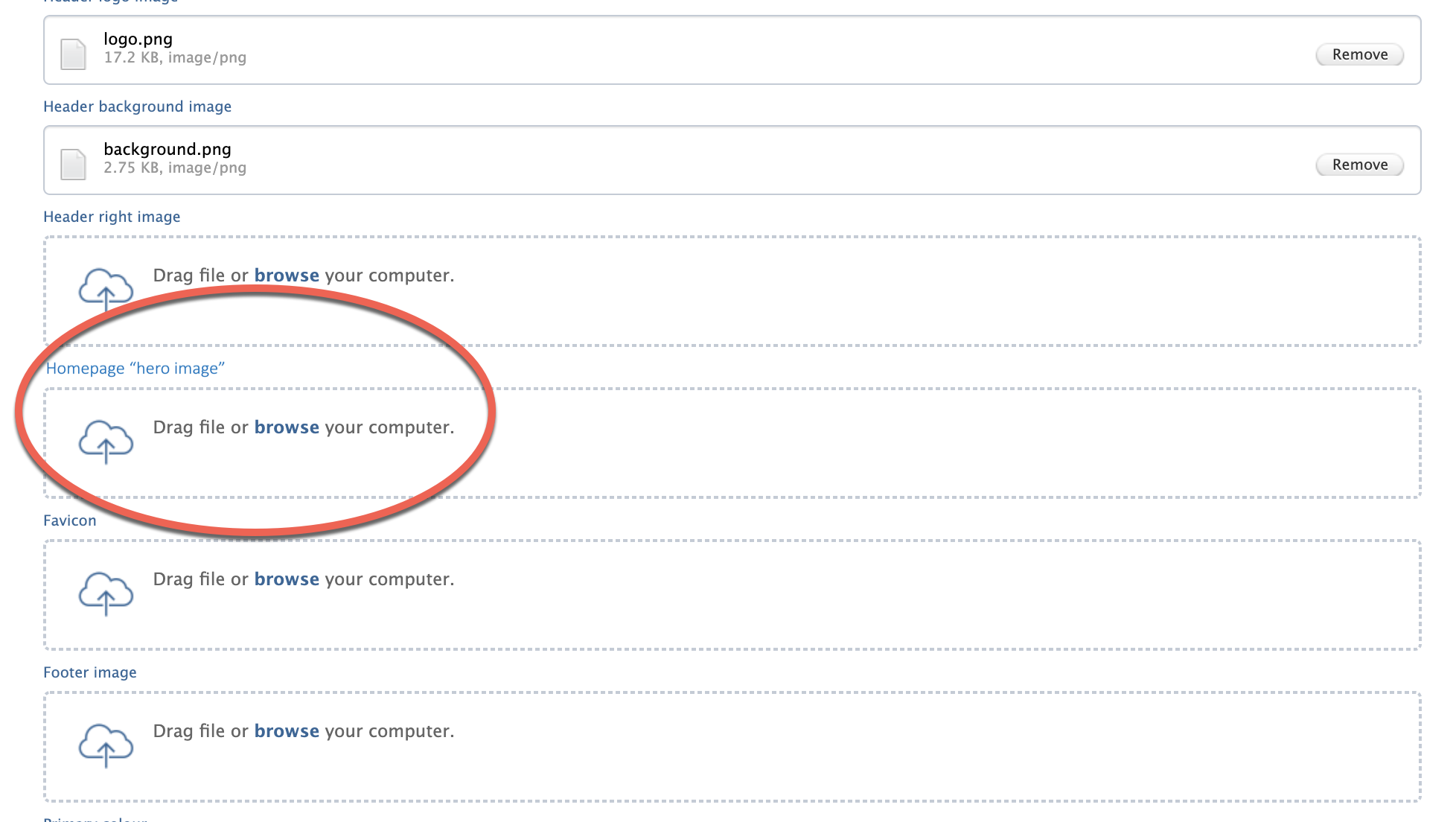
Upload an image of your choice by either dragging and dropping or selecting a file from your computer (.jpg or .png formats are supported). Since the hero image has a fixed height of 470 pixels, we advise sizes of somewhere around 470 pixels (height) by 1920pxl (width). Also please do bear in mind that too large a file size could add noticably to the page load time.
Once the file is successfully uploaded, click "Save" at the bottom of the page. The change should be pushed through to your Portal within a few seconds. It might require a couple of attempts to line up your image perfectly, so be sure to check how it is displayed on your Portal. If necessary, adjust the cropping on your original image and re-upload it until it is just right.
7.2. Homepage search field changes
In order to get the most from the new 'hero image' homepage design, we made some changes to the search field on the homepage. These simplify the existing design, making searching more intuitive and less complex for new users.
Click here for more details...
The most evident change concerns the search box, which is now layered on top of the new 'hero image' a semi-transparent box. This new layout allows for the image to show through while the search box still remains the most prominent object on the page, drawing the user's eye towards it as the primary call to action.

The dropdown menu for selecting which content type to search has also been removed, further streamlining the new homepage design. An analysis of user behaviour showed that this drop-down menu was rarely used, indicating that most users prefer to start from a broad search that can then be narrowed down to specific topics. In addition to being in line with best practice across the web, this change is consistent with our new filter design, which makes narrowing down results much simpler.
The 'Welcome text' for now remains the same as before, i.e. 'Welcome to [PortalName]'. We are, however working on getting a further improvement out soon to make this a free text string, where you can add the message you want to display.
Last but not least, we have changed the way in which a user can access the 'Advanced search' and 'Copy/paste text- find expertise' functionalities, which could previously be accessed by clicking the gear icon on the right of the search box:

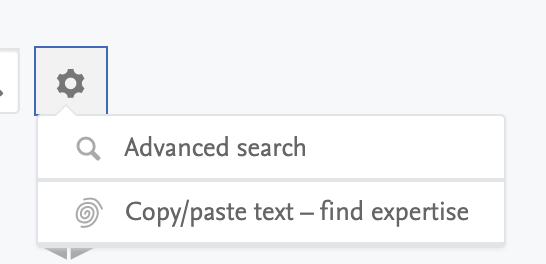
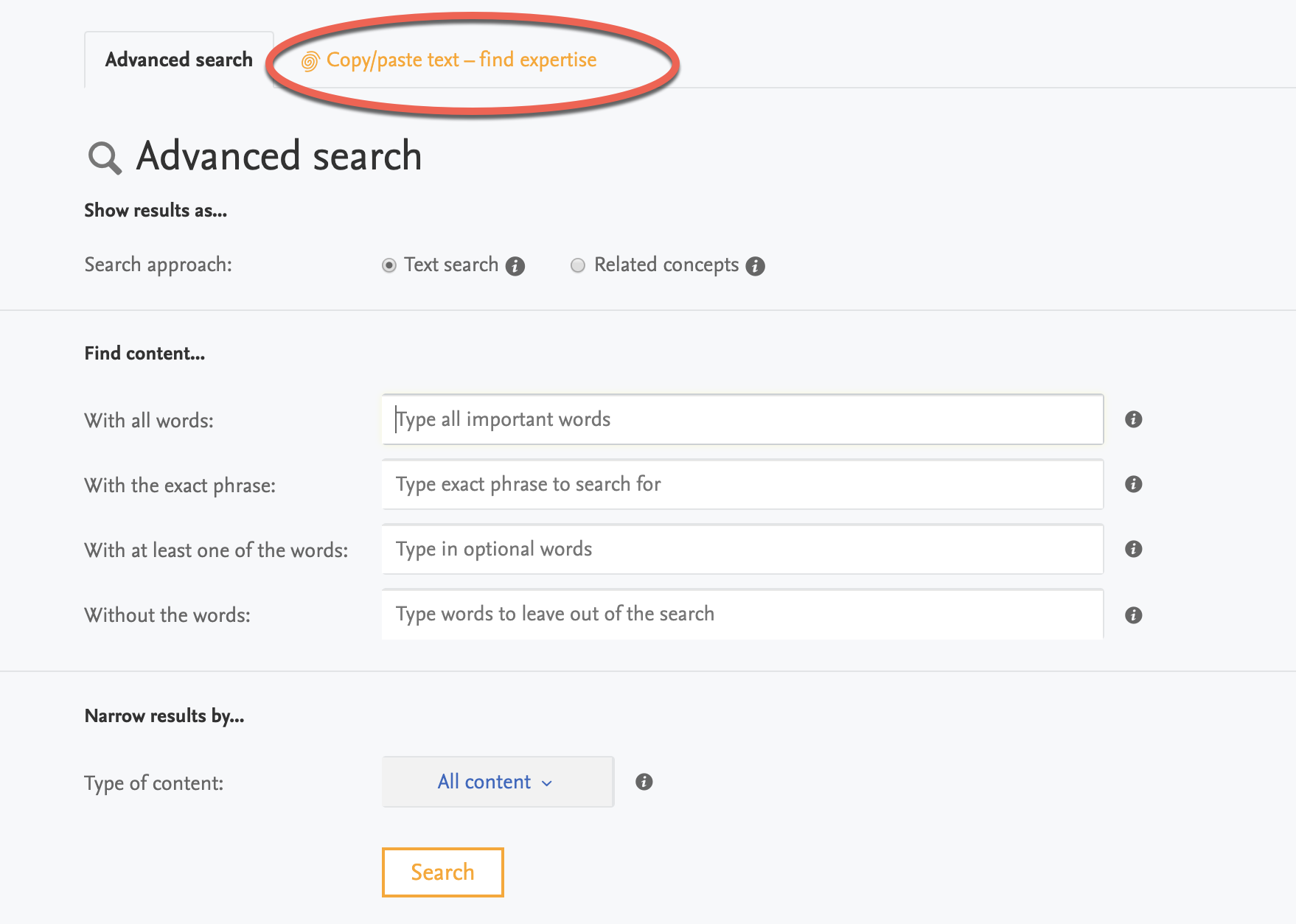
The gear icon has now been substituted by a simple link labelled "Advanced search", which directs the user to the to the "advanced search", and "copy/paste text- find experts" functionalities via the tab shown in the screenshot below.
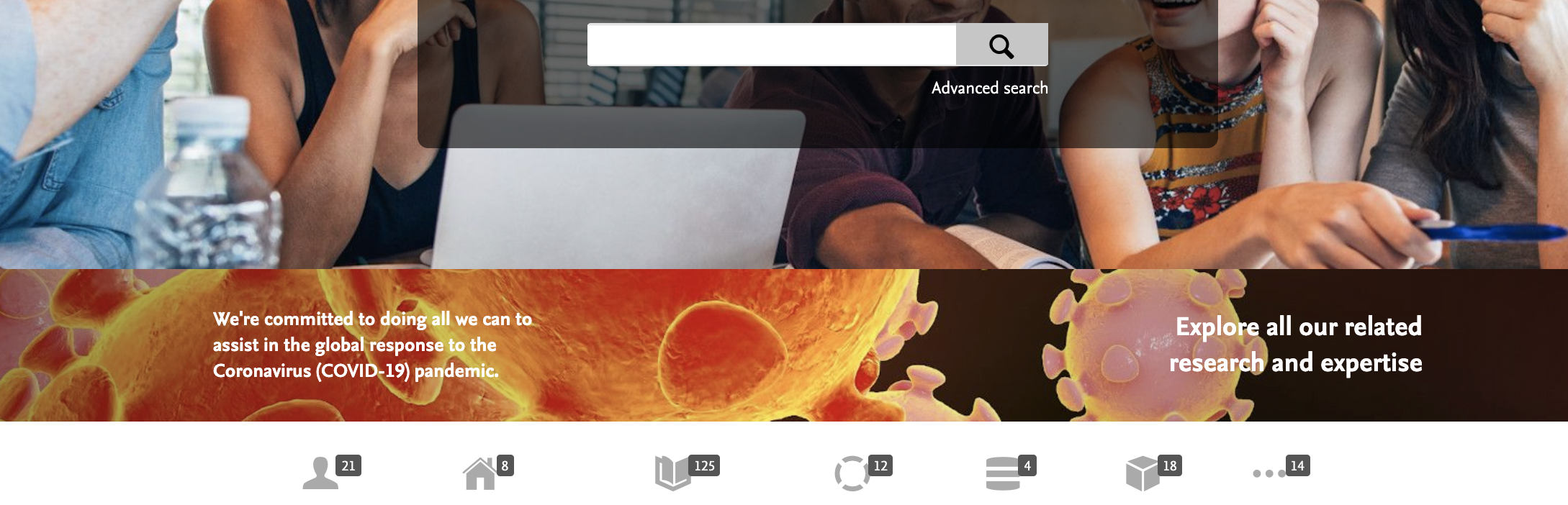
7.3. Homepage "Hot topic" banner
In the 5.17.3 minor Pure release, we delivered our brand new homepage banner feature. We designed this with highlighting coronavirus-related material in mind, but it can be used to highlight any key content, either on your portal or elesewhere.
To find out more on how to maximize showcasing of key content via this banner, check out the Pure version 5.17.3 release notes.
We have also now in this release encoded the banner search query in a more compact form to ensure compliancy with all browsers. This resolves a reported bug that occured when search strings were too long.
7.4. Portal Search: discover more efficiently and intuitively - search filter placement improved
By redesigning our Pure Portal search filter interface we have made the search process faster and more intuitive, allowing Pure users to narrow down content and surface the most relevant results.
To achieve this, all the search filters have been moved from their previous position (below the search bar) to a column on the lefthand side of the page:
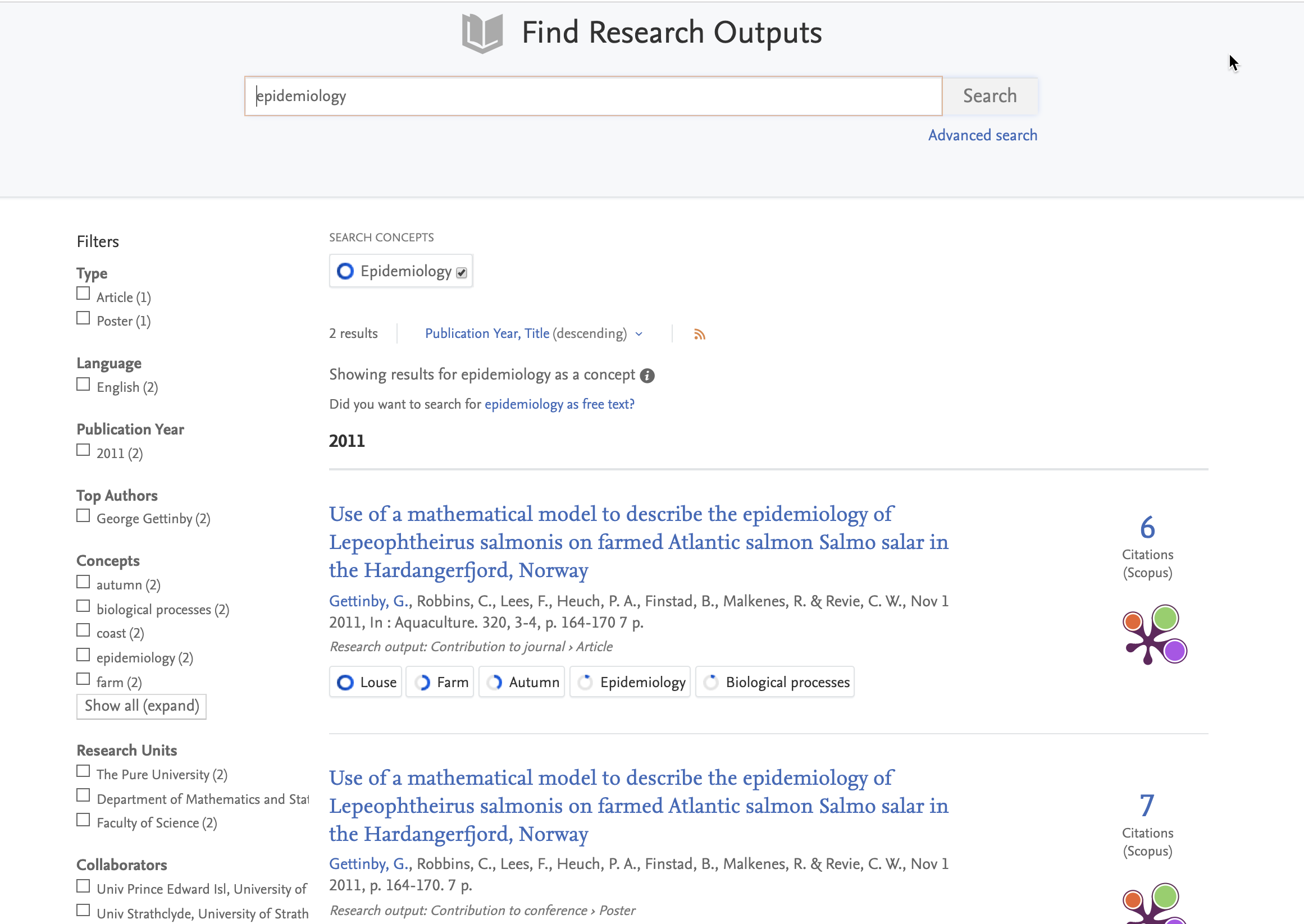
Click here for more details...
Based on feedback from analytics data and user interviews (and experimenting with several designs) we have modified our filter interface in line with the model adopted by popular shopping platforms. Testing confirmed that our new filter interface makes it easier for first time users to understand and use, solving the common issue of locating the filter functionality by always making filters visible on the results page.
As before filters are grouped into categories that are displayed on the left of the screen. To apply a filter, simply check the box. It is possible to apply multiple filters at once, either from the same category or across multiple categories. Applied filters are displayed above the search results and can be deselected either by clicking the "x" on the filter at the top of the screen, or by unchecking the filter in the filter column:
Up to five filter options will be shown under each category in the filter column. Additional filters are hidden, and can be accessed by clicking on the "Show all" link below. Clicking on this link will display the full list of filter options for a given category in an expanded box laid over the page. Simply select the filters you wish to apply and then click the "Close" button on the top right-hand corner of the box:
These changes represent a first step in modernising the search experience. We have focused here solely on improving the interface. The underlying filter mechanics remain as yet unchanged from the previous iteration. We will be continuously working to improve both our filtering mechanism and interface and would very much appreciate any feedback you could provide to us on this initial new offering, as this will help inform our further development.
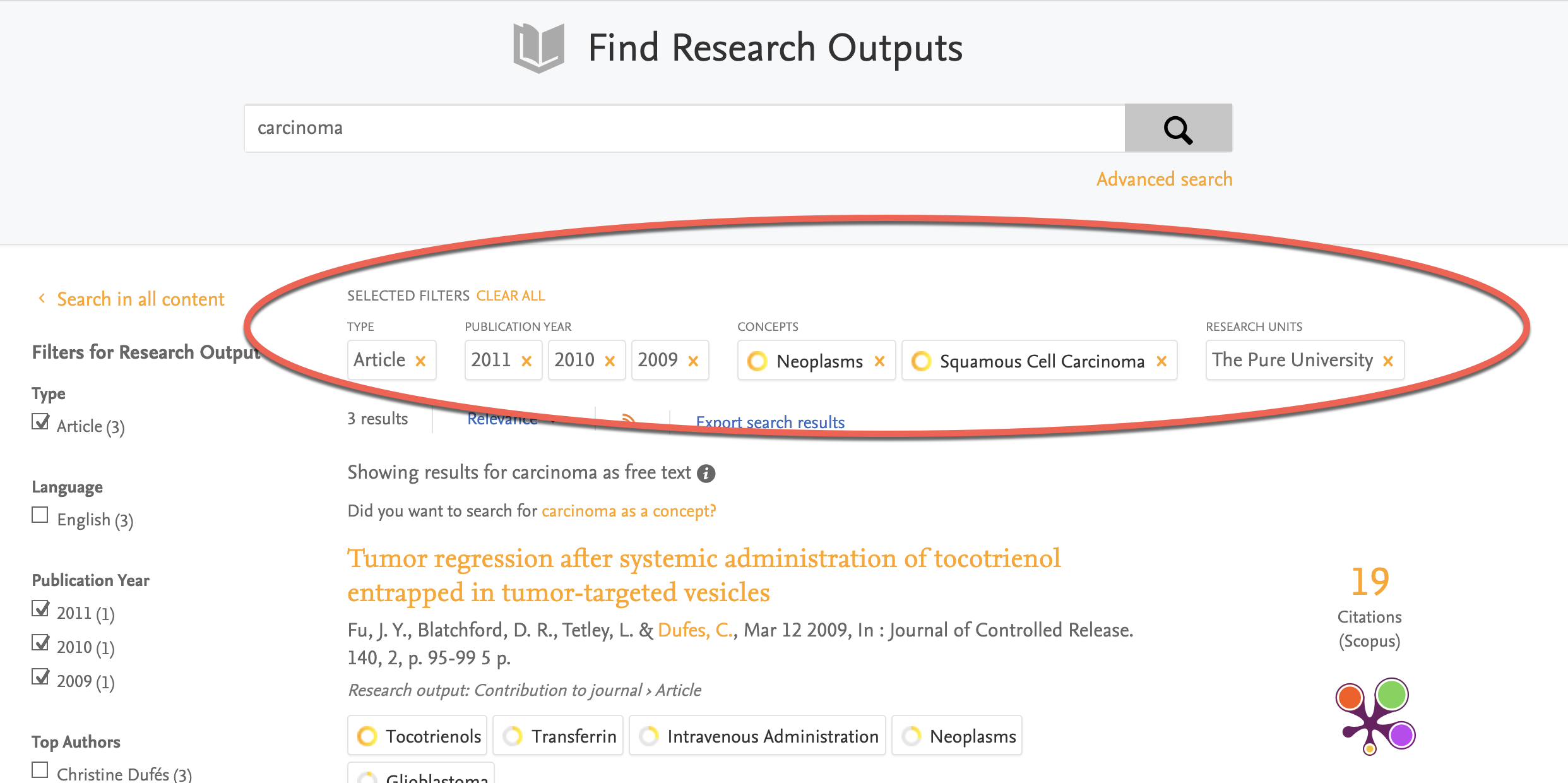
7.5. Export search results
Adding the ability to export search results from the Portal has been a highly requested feature for some time. With the 5.18.0 release, we are making this a reality, meaning you can now more easily share your search findings with others.
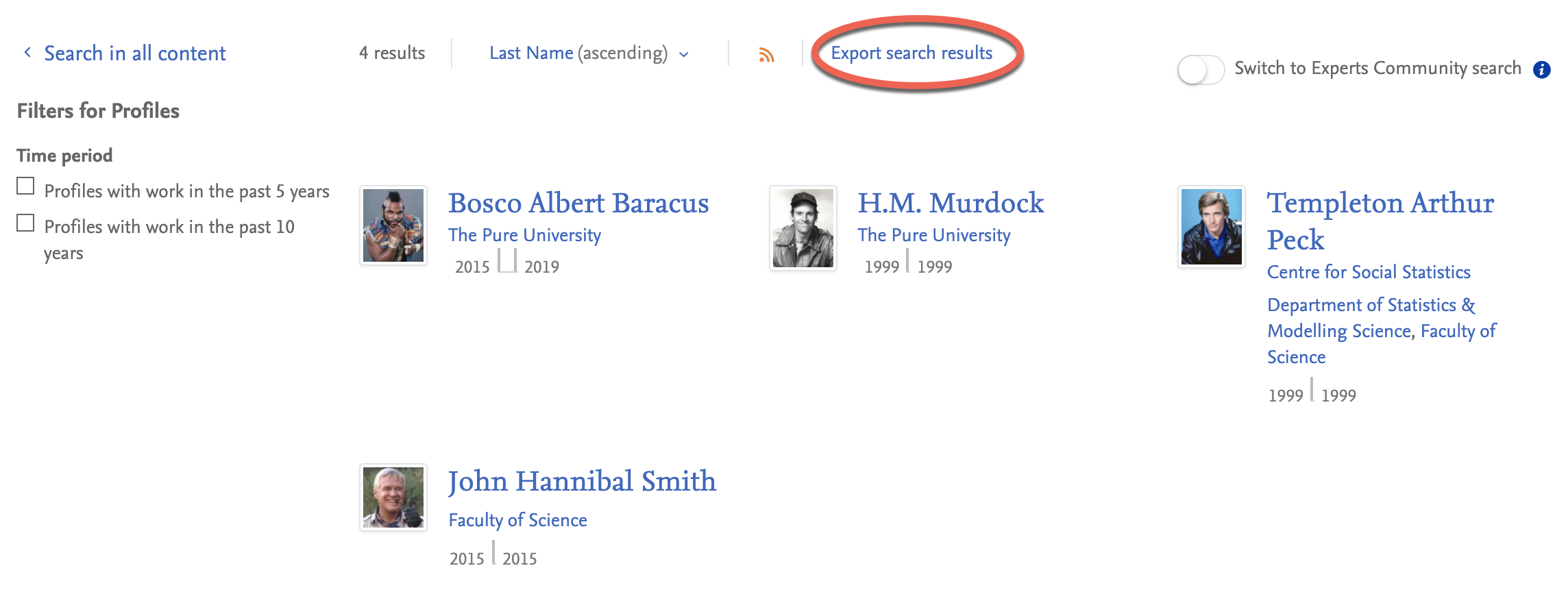
Click here for more details...
Saving your search results might be useful for several purposes, either for your own use later or to make it easier for you to share the search content with a colleague or other collaborator. With our new export functionality we hope to make this a little easier. Once you have made your search just click the link at the top of your page to download the results, which are provided as an Excel spreadsheet (.xlsx).
It is possible to download results for any content type, but please note two important limitations here:
- Results can only be exported from one content type at a time. This means that if you are searching across "All content", you need to separately select each relevant content type and click on the link on the next page to download.
- Only the results currently shown on screen will be exported. This means if you want to export results across mutiple pages of results, you will need to click to each page and export the results from that page separately.
For most content types, the content will be exported as shown below:
Column A: The result number, based on the sort order defined on the results page.
Column B: The content name/title. For instance, for a Research Output this is the output title, while for an Organisation or Research Unit it is the organsiation/unit name.
Column C: The Portal URL of the page for that piece of content.
For exports of Persons/Researchers in the Portal we have a little added more granularity, including also their Organisation/Research Unit affiliation and contact email address, if available:
The filename is in the following format: export-{ContentType}-DateExported.xls
The search string is added as the tab name in the file. Please note, this is not always possible for longer or more complex search strings.
Note also that, while we are open to feedback and suggestions on limited expansion of the data points available for export from the Portal, in general this functionality is intentionally kept as simple as possible. It is mainly intended either for quick, simple reports by admins, or for use for persons either without access to or experience in using the Pure "back-end" program.
For more complex searches, and to create more detailed reports, we still highly recommend you use the Reporting Module in Pure, which is specifically designed for this purpose.
7.6. Related content layout improvements - Research Outputs and Datasets
In the last major release (5.17.0), we updated the layout of the Pure Portal pages for equipment and project pages to display links to the content related to those pages in a more structured way. In this release, the same changes have been rolled out to the Research Output and Dataset content types:
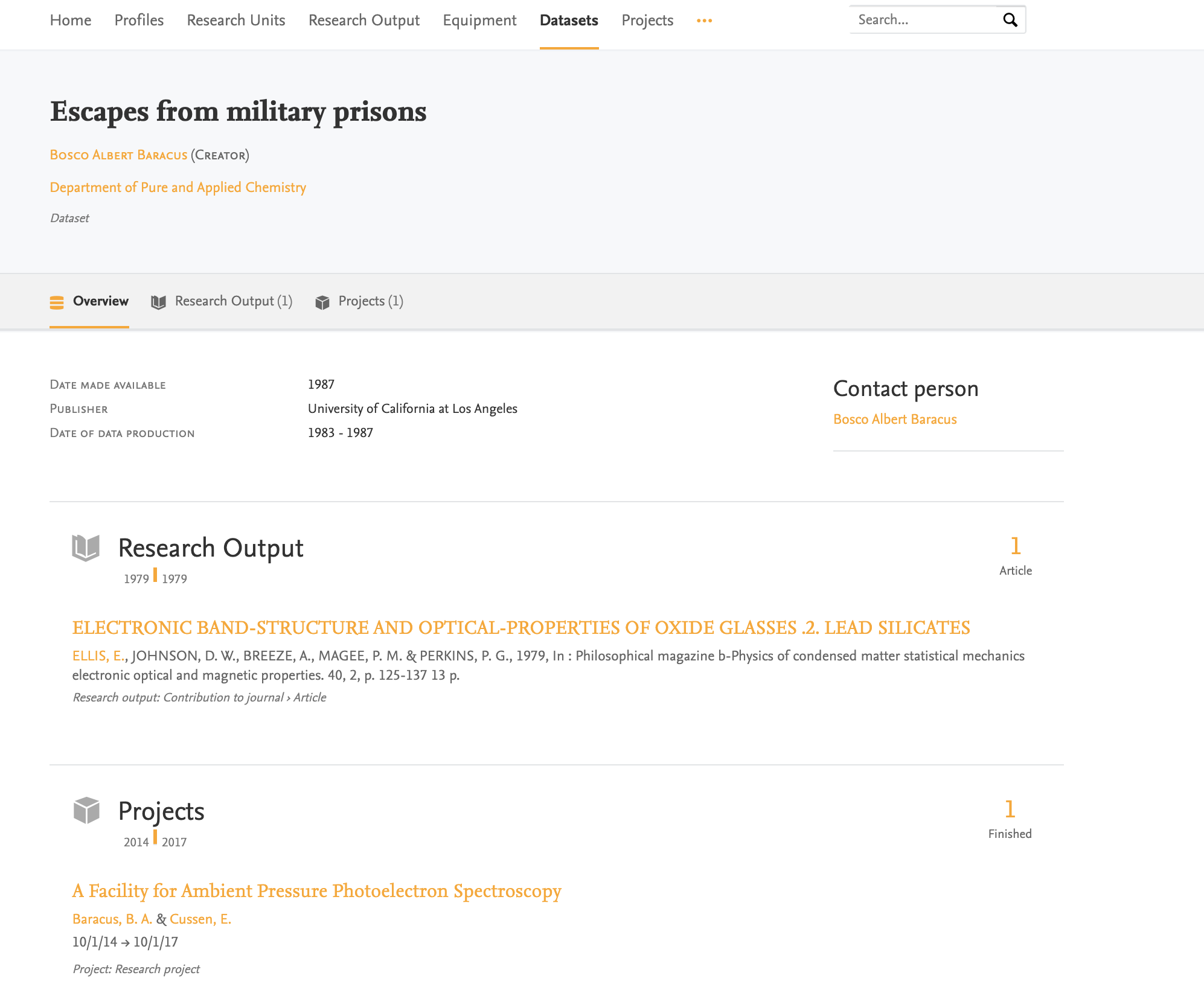
7.7. Supervised work tab
A new tab has been added to the Pure Portal profile pages, in order to separately display the work that a person has supervised from their own work.
Click here for more details...
Previously, supervised work was displayed on the supervisors profile page listed among their personal research output. This has now been separated and given its own tab on the profile page:
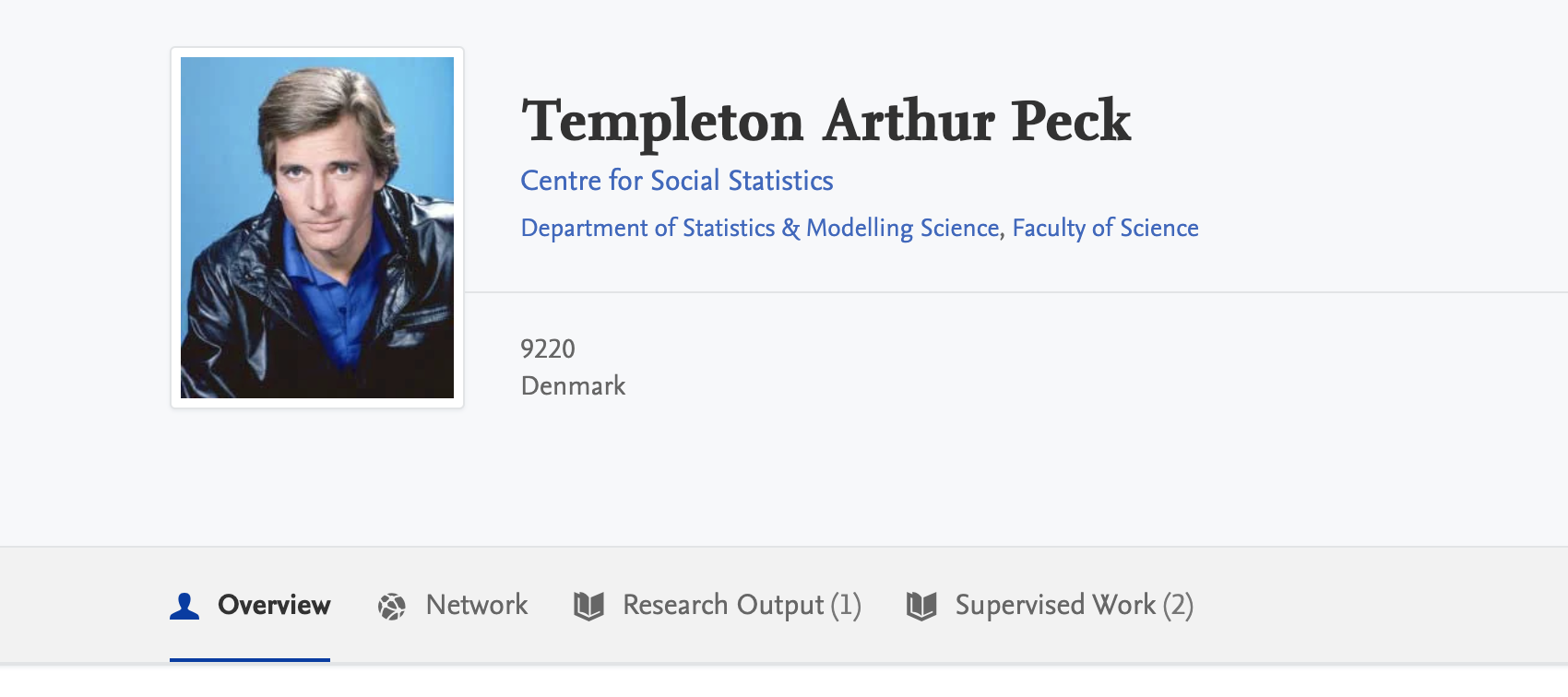
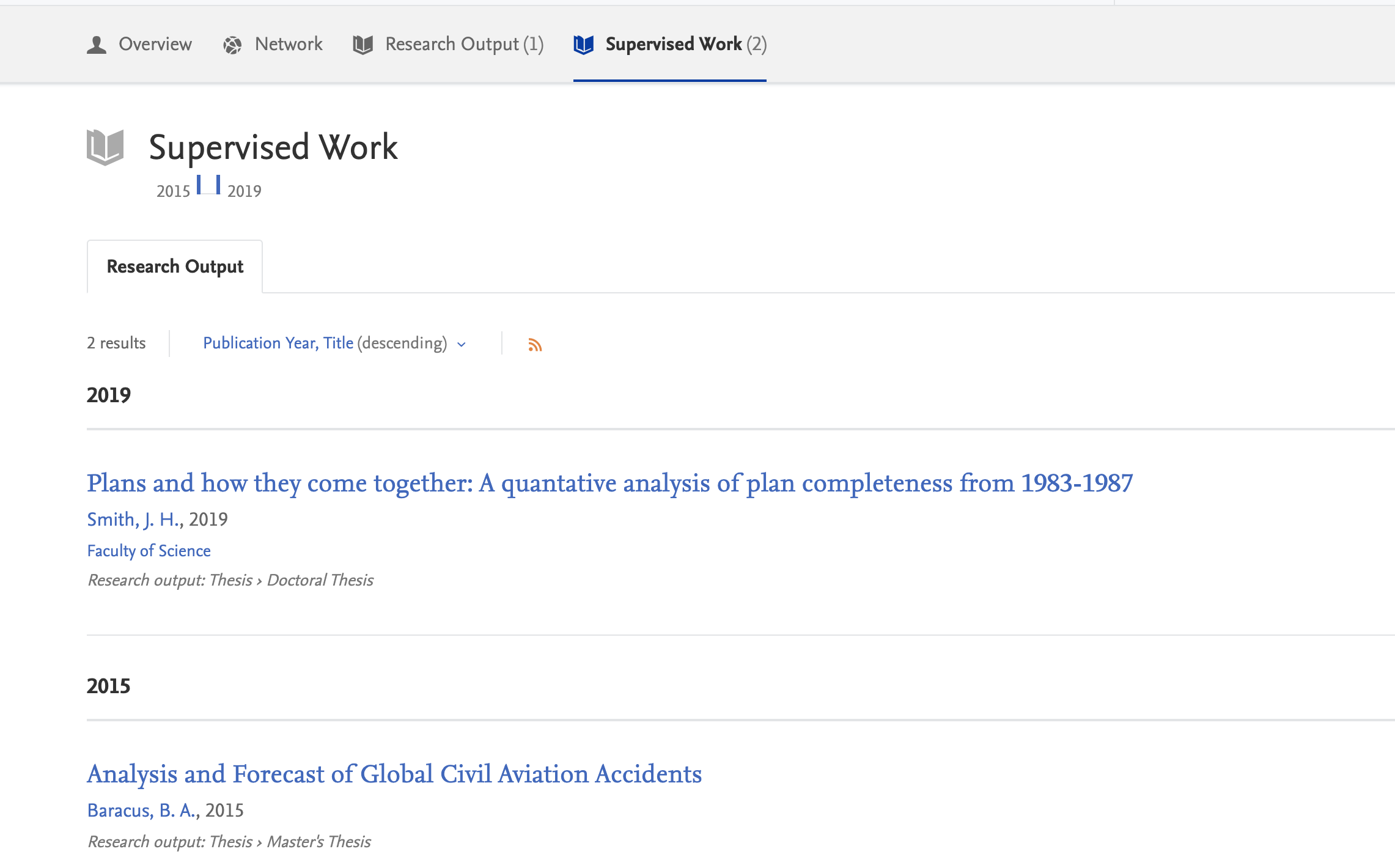
By clicking on the "Supervised Work" tab, the research outputs for which the profiled person served as supervisor are shown (in the same format as that of their individual work):
7.8. Disabling the person research output bar graph
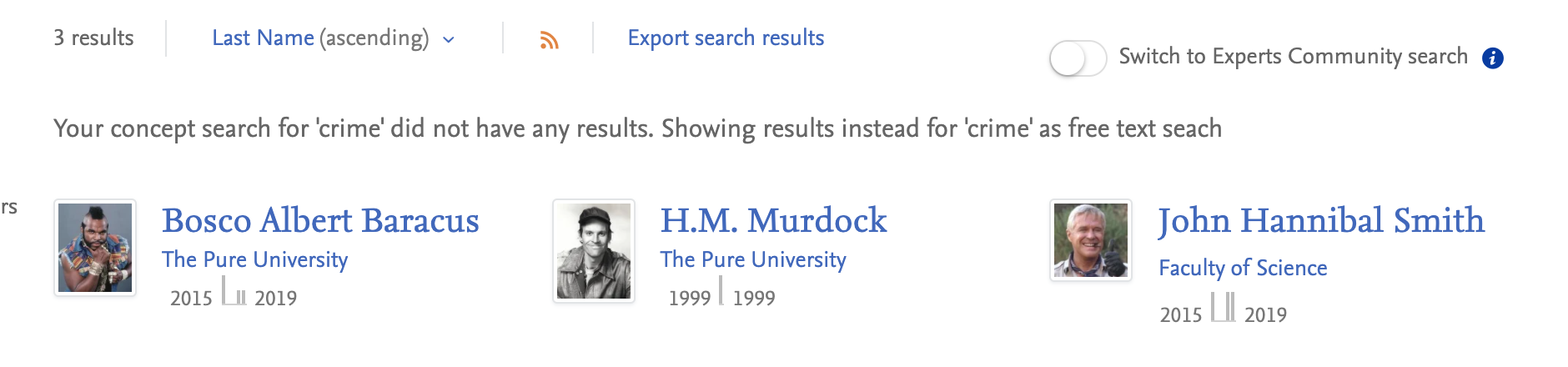
To indicate a person's research output over time, a small bar graph is shown on their profile.
While typically a quick indicator of a researcher's activity, we recognise that it in some circumstances this data can be misleading, or unflattering. We have therefore added a configuration allowing your institution to choose to hide this bar graph.
Click here for more details...
The research output bar graph can be found towards the top righthand corner of a person's profile page, as well as in search results:
In order to disable the graph, go to Pure Portal > Administrator > Configurations > Persons and toggle the option Remove research output graph to "On".
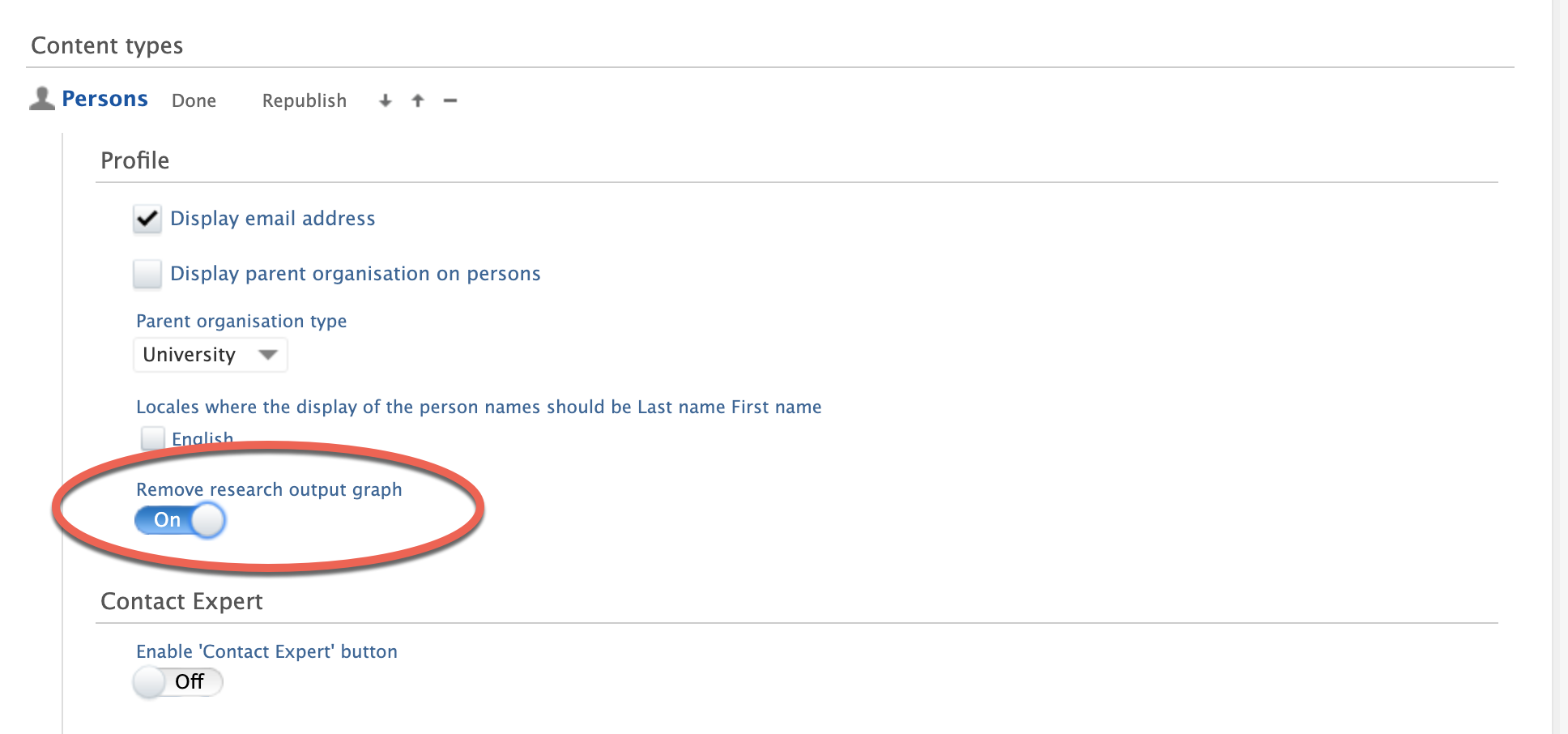
All person output bar graphs will then be entirely removed across your portal.
8. Reporting
8.1. Global reporter roles
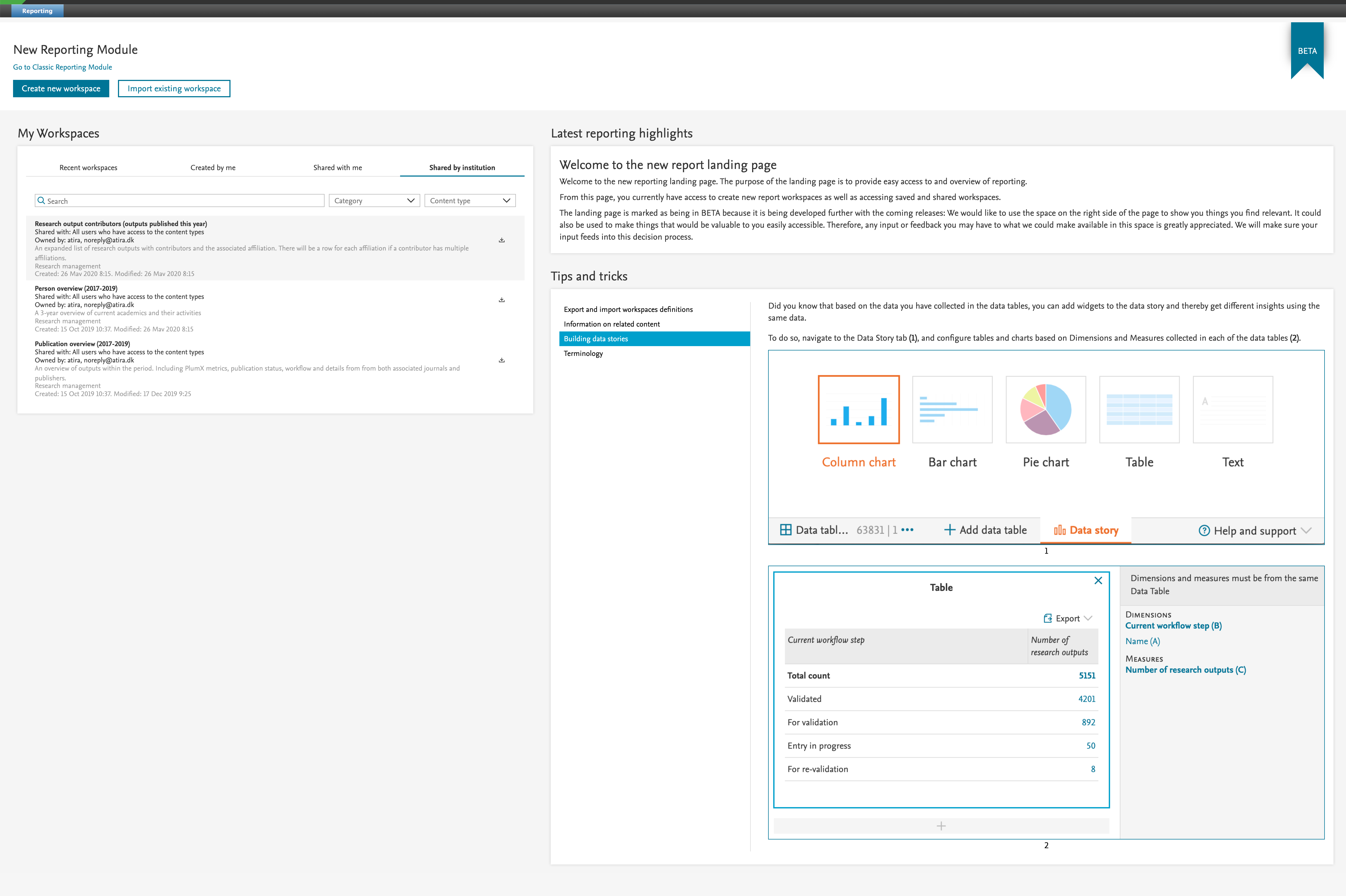
With this release, we have introduced global reporter roles for all content types. These new roles will grant access to the new reporting module, and it will be possible to report on the selected content types, e.g. Global reporter of Research Output. This means that it is now possible to open the new reporting module up for more users so they can start using the new reporting module. Combine these roles to give access to the new reporting module for more users without having to provide editorial rights to users. If the global reporter roles are the only role that a user has, then the user can only see the new reporting tab, and use the new reporting module without being able to see the rest of Pure.
 |
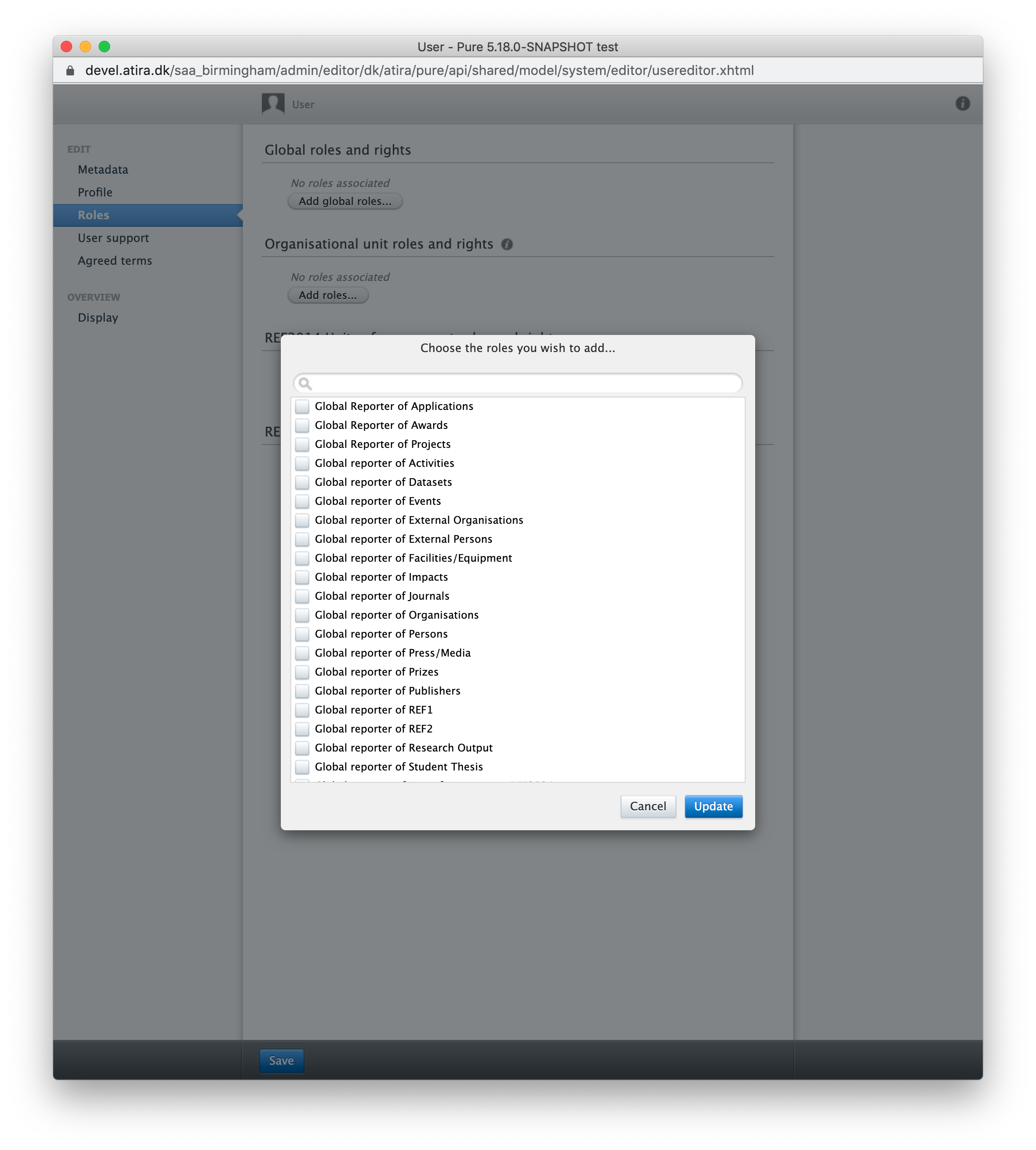 |
This is part of the ongoing development of the new reporting module and we are planning for more changes around the roles in the new reporting module to enable even more fine-tuned access and usage of the new reporting module.
8.2. Updates on Report home page - Tips and Tricks
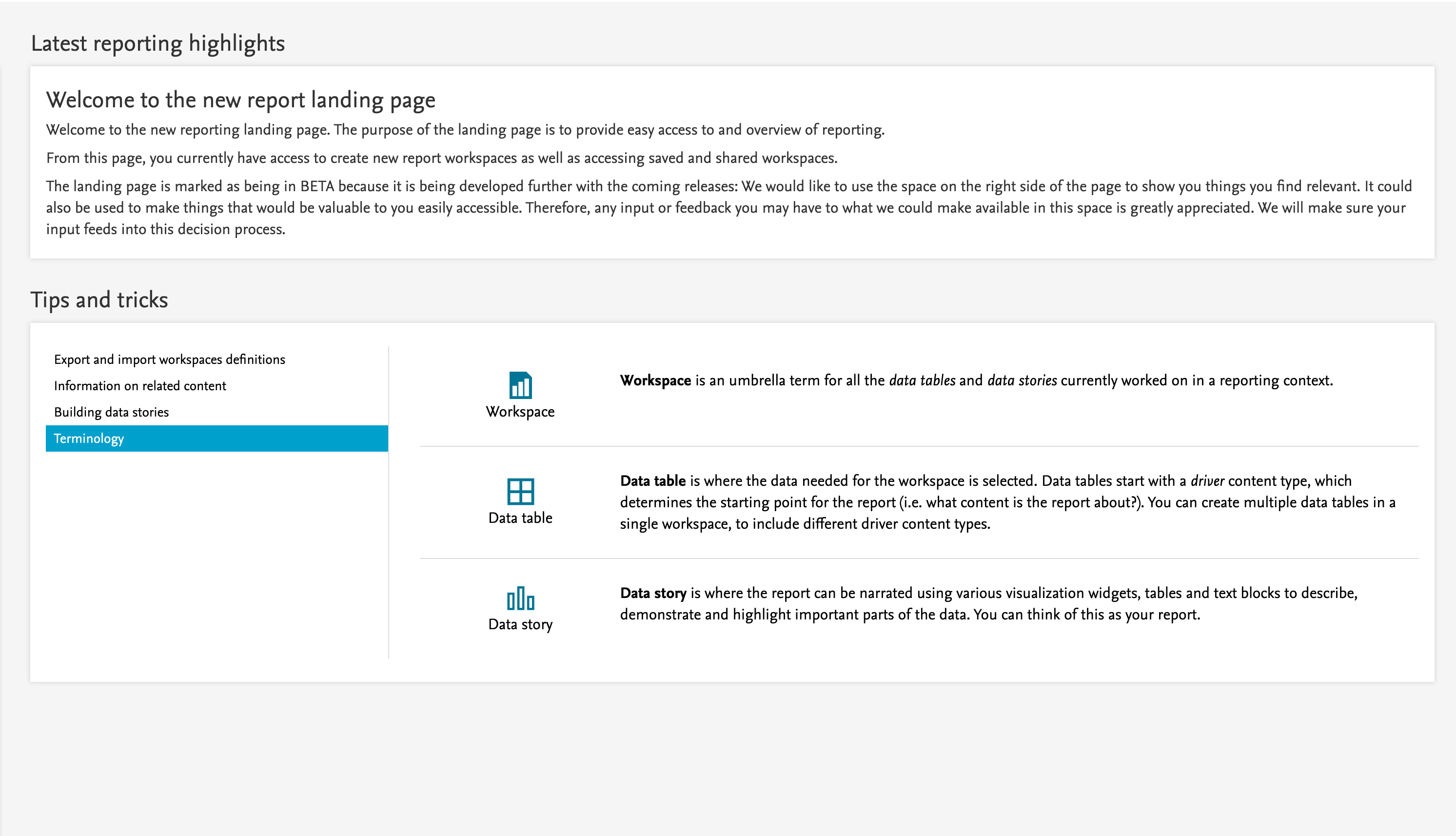
As part of ongoing interviews and feedback from users, we have introduced Tips and Tricks to the home page of the reporting module.
 |
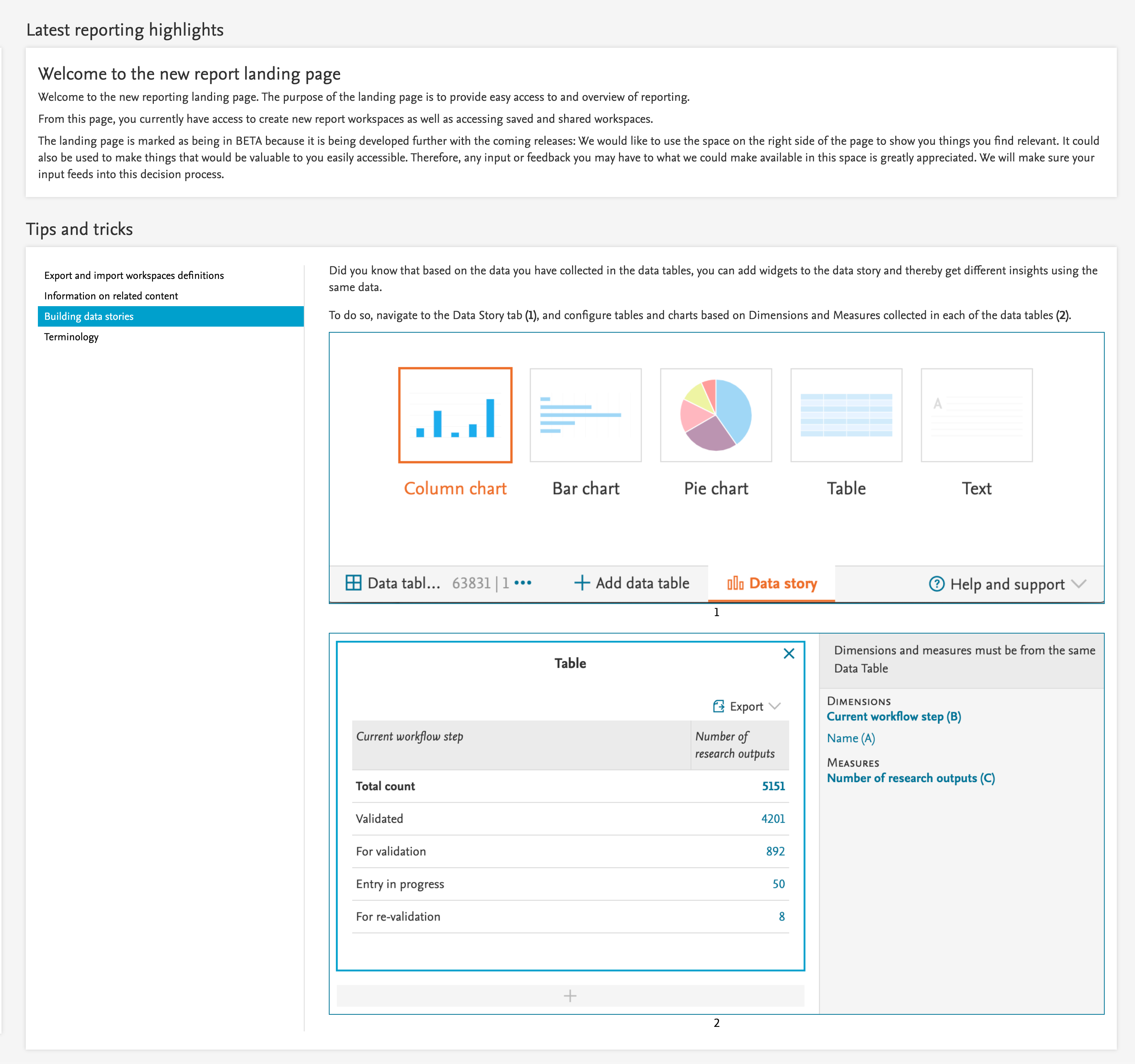 |
These Tips and Tricks will:
- Highlight various features of the new reporting module
- Help with on-boarding
- Help discover the multitude of features and possibilities in the new reporting module
- Help users in their daily tasks
The reporting home page will be updated with more Tips and Tricks with each release of Pure.
8.3. Option to remove schedule reports - classic reporting
It is now possible to disable the ability to schedule reports in the classic reporting module via Administrator > Reporting.
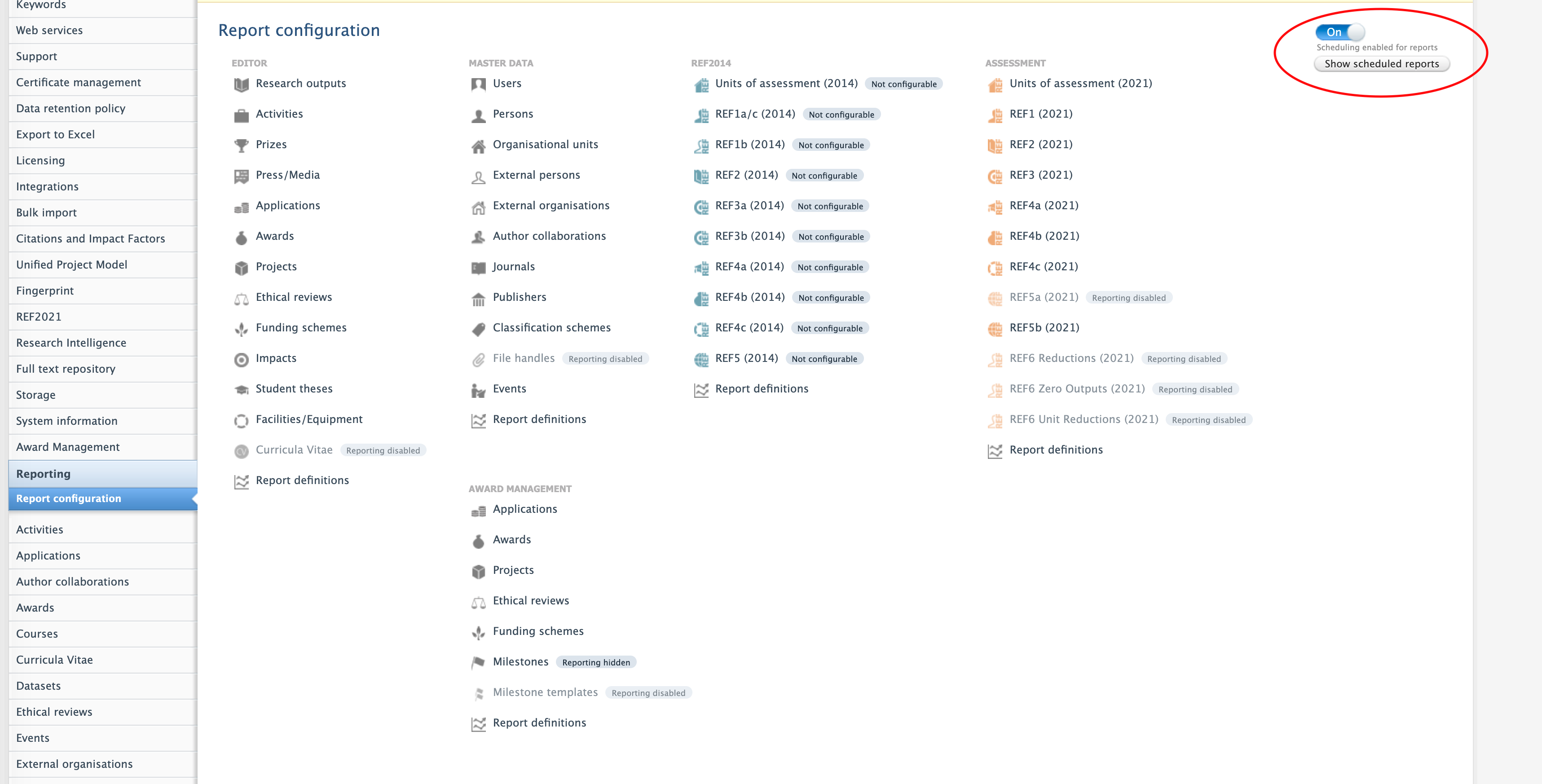
Click here for more details...
When disabled the ability to set up new scheduled reports will be removed from the classic reporting module
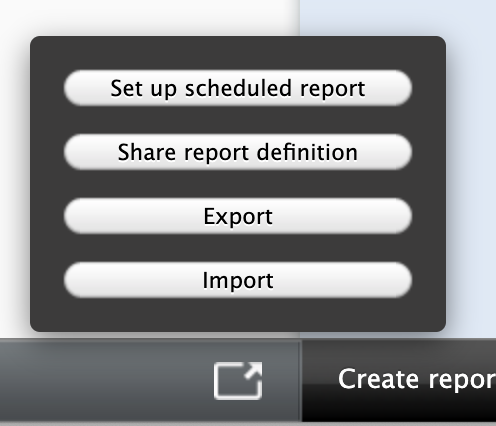 |
 |
It is possible to cancel any already scheduled reports, by clicking 'Show scheduled reports' button on the Report configuration page, see screen shot above. There is possible to cancel selected ones, or all at once.
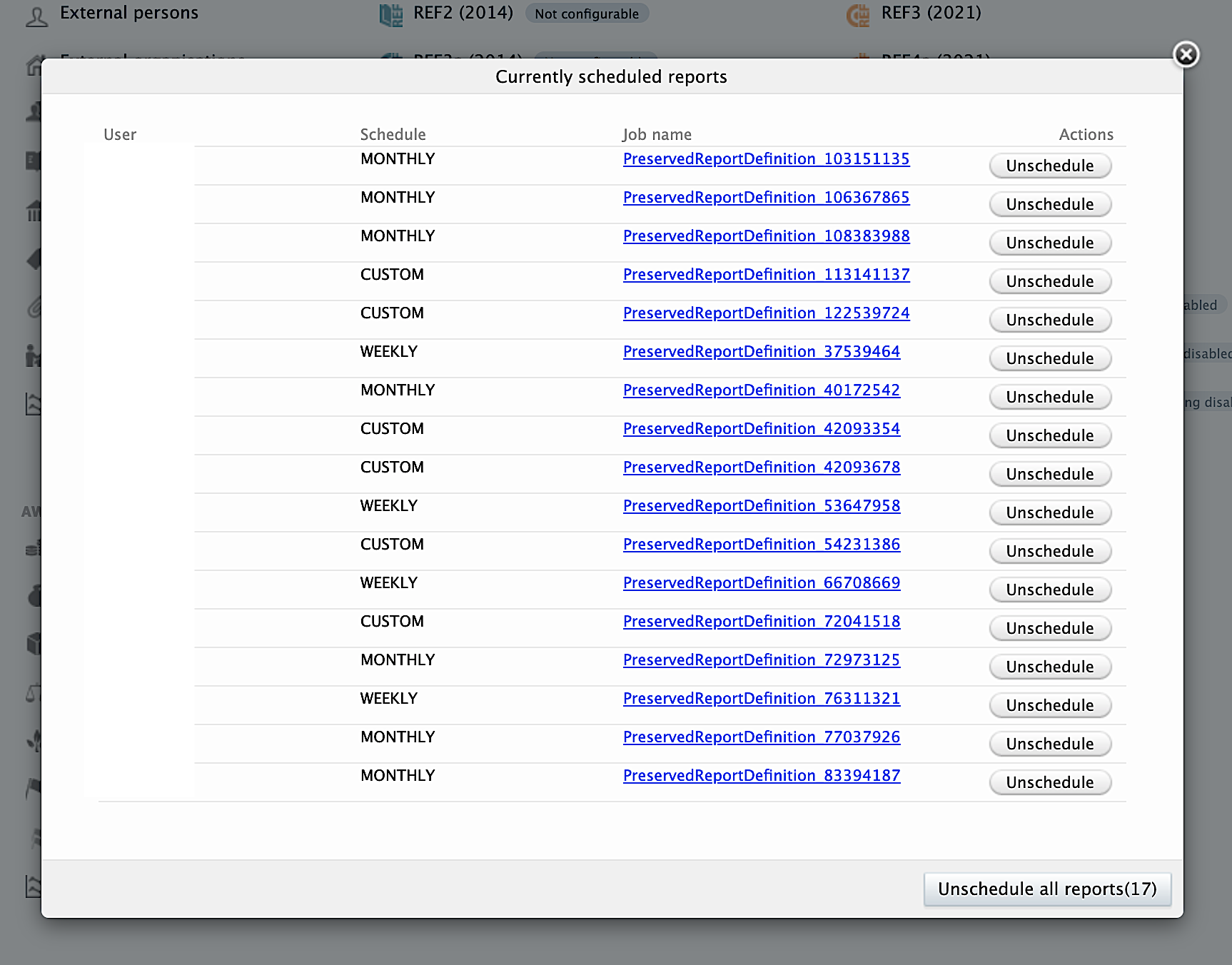
Cancelling all of the scheduled reports will remove the scheduling and it will have to be set up again on all of the reports if they are needed once more.
9. Country-specific features
9.1. UK: REF
In this release we have made a number of updates to the REF module:
9.1.1. Bulk upload of Output allocation
We have introduced the ability to bulk upload the output allocations for REF2s. Please read the REF2 - Bulk upload output allocation documentation for more information about how to prepare the Excel for bulk upload, where to upload etc.
9.1.2. REF release notes
We have created a page to keep track of all of the REF related release notes from Pure. It can be found in the REF 2021 - Release notes part of the REF documentation.
10. Additional features and notes of this release
10.1. SameSite cookie attribute
Pure now supplement session cookies with a 'SameSite' attribute to satisfy requirements set by current and soon to be released browsers when using single sign-on and other functionality that relies on non-GET HTTP methods, and to better protect end-users against attacks. Its value is set to 'None' for anonymous sessions and 'Lax' for fully authenticated sessions by default. The default value can be changed individually via Administrator > System settings > Cookies (SameSite). This includes disabling addition of the attribute entirely.
Please notice that the Pure Security Guide now strongly recommends to use HTTPS for all Pure web applications and recommends that the 'secure' attribute is set on Tomcat connectors. That is especially important when a 'SameSite' attribute is added to cookies as browsers can now or in the future require such cookies to also have the 'Secure' cookie attribute.
10.2. Sherpa Romeo API updates
Sherpa Romeo is deprecating their current 'color' service for journal OA policies and permissions. Based on current information found at http://sherpa.ac.uk/romeo/index.php, and confirmed by Jisc, the providers of Sherpa Romeo data, the following dates are confirmed:
- Launch of new service: April 14th 2020
- Decommission of current service: July 31st 2020
The updated web access can be found here: https://v2.sherpa.ac.uk/romeo/
Significant changes have been made to Sherpa Romeo, with multiple options for Open Access routes per publication state. Interviews with customers are underway to determine what is the best information to surface at the research output and the journal content level.
Service to Sherpa Romeo will continue to be available until the API shutdown, upon when Pure will switch off access to the old API to prevent system errors.
In 5.18.1 users will be shown a link to Sherpa Romeo to access the latest journal OA routes, and once customer interviews are complete, the updated information will be surfaced in full on the research output and journal editors. The transition to the new Sherpa Romeo will be complete on release of 5.19.
We highly recommend administrators and other relevant roles review the new OA access routes information.
Published at May 14, 2024