
How Can We Help?
5.20.05.20.0
Highlights of this release
![]() UN Sustainable Development Goals (SDGs): Report on and showcase research that contributes to the UN SDG Goals
UN Sustainable Development Goals (SDGs): Report on and showcase research that contributes to the UN SDG Goals
Universities and knowledge institutions globally have a critical role to play in the achievement of the United Nations Sustainable Development Goals (SDGs).
Our teams have been working hard this year to develop a range of features across Pure to support you in your work towards these goals, and in promoting your efforts. The 5.20 release sees the first versions of these features made available to our clients. These includes automated content tagging, template reports and Portal showcasing features.
 Global search
Global search
The global search functionality has been updated and improved to provide clearer and more accessible results for users. Previously, search results across content types were limited to what content types were present in the top 50 results across all content types. Global search results now represent the results found across all content types.
 Self-import of datasets
Self-import of datasets
With this release we are happy to announce that we expanded functionality for datasets in Pure. We have added datasets as a new content type for self-import of data to Pure, enabling researchers and personal users to search for and import datasets from specific repositories. We have also added Data Monitor as a self-import source, covering a wide range of domain-specific and cross-domain repositories. Institutions can now select one or more data sources and personal users can find and preview datasets before importing them into Pure.
This recent development is in line with the work we are doing around Open Science, allowing researchers to find and connect the different parts (and outputs) of their research activity.
 IEEE Xplore as an import source
IEEE Xplore as an import source
We have added IEEE Xplore as a new import source to Pure. IEEE Xplore is a research database of journal articles, conference proceedings, technical standards, and related materials on Computer Science, Electrical Engineering and Electronics. It contains material published mainly by the Institute of Electrical and Electronic Engineering (IEEE).
This integration provides researchers with access to more than 5 million documents - including more than 193 peer-reviewed journals, more than 1,700 global conferences, more than 6,200 technical standards, approximately 4,000 e-books, and over 425 online courses.
Watch the 5.20 New & Noteworthy seminar
We are pleased to announce that version 5.20.0 (4.39.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 3 February 2021
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 10 February 2021 (APAC + Europe) and 11 February 2021 (North/South America).
- Production environments (including hosted Pure Portal) will be updated 24 February 2021 (APAC + Europe) and 25 February 2021 (North/South America).
Advance Notice
This is an advanced notice that we will be migrating our Jira, Confluence and Crowd systems to Amazon hosting (the hosting will be in "Europe (Ireland)" otherwise known as eu-west-1). As you know, the Jira and Confluence systems are used for communicating with customers regarding defects, enhancements, documentation, implementation status and user group meetings. Our Crowd system is used to manage the access to Jira and Confluence.
The update will not change anything about who has ability to login and what their credentials are, only the location of hosting changes from om-premise in Aalborg to hosted on AWS.
This move will likely occur in the later half of March or early April 2021. If this raises any concerns for your organization, please take up contact with Davina Erasmus (d.erasmus@elsevier.com) so that we can discuss with you and take any necessary steps as needed.
Technical recommendation
PlumX API
19 Feb 2021 - Update from Pure Product Team
The PlumX API is currently experiencing technical issues which affects how quickly metrics are retrieved from PlumX, and added to individual research outputs within your Pure. PlumX, Elsevier API and Pure are working to resolve the issue as soon as possible.
To ensure all metrics are retrieved and added to your research outputs in a timely manner, please request via Pure Support that we update the batch size in the PlumX configuration options to 50. The smaller batch size will ensure that the API does not return any errors.
Detailed instructions and more information can be found at the PlumX API client page.
Download the 5.20.0 Release Notes
last updated 2 February 2021
1. Web accessibility
We continue to work towards being fully WCAG 2.1 AA compliant by ensuring accessible design in new features.
1.1. Portals WCAG 2.1 AA accessibility
We are now tantalizingly close to full WCAG 2.1 AA compliance in the Pure Portals, and expect to achieve full compliance in minor release updates to version 5.20 (more details on this will follow soon!). For this release, we focused mainly on general font, readability and screen reader issues still outstanding.
Click here for more details...
Highlights of the accessibility improvements made in this release include:
- Reflow: Reflow means allowing those who use zoom features or low-resolution devices to access the same information and features available in the default setup. We now support a resolution as low as 320px (width) and a zoom of 400%. Content can be presented without the loss of information or functionality.
- Portal font is now optimized for the Russian language.
- The collaboration map data is now also available in text format (through a popup).
- The related content graph now comes with a hidden table with graph data visible only to screen readers.
- We have made general improvements to a number of ARIA attributes.
- We have made general parsing (html validation) improvements.
2. Privacy and personal data
The protection of privacy and personal data is extremely important to Pure. Based on guidance provided by GDPR (and similar frameworks), we continually add improvements to how Pure handles sensitive data, and we continually provide tools for users to manage their own and others' data in Pure.
This release brings improvements to the Portal cookie consent (see section in these release notes).
3. UN Sustainable Development Goals (SDGs)
3.1. SDG keywords tagging
To help research institutions demonstrate the ways in which they support the Sustainable Development Goals (SDGs) through collaboration with other countries, the promotion of best practices and the publication of data, we have added the ability to attach SDG-specific keywords to content. These keywords can be added either automatically through a specific job, or added manually by individual users.
These keywords can then be used for reporting, tracking and showcasing purposes - thereby helping institutions monitor and promote their progress and achievements. The SDG search strings have been developed with expert involvement; more information on each search string can be found in the dataset Identifying research supporting the United Nations Sustainable Development Goals. A complete overview of the SDGs can be found at the official UN SDG website.
Click here to expand...
Adding SDG keywords via a job
Keywords are added (and removed) via a cron job that can be scheduled and configured. See below for details of the job configuration and for a number of typical usage scenarios.
What content types will receive SDG keywords, and what fields are considered by the job?
Currently, the job will only add SDG keywords to the Research output and Person content types. For Research outputs, the job will only consider the title, abstract and keywords. For Persons, it will consider only the profile information and keywords.
Note: Content will need to be indexed before running the job.
SDG keyword job
To enable the job and configure how the keywords are added and/or removed, go to Administrator > Cron job scheduling > Management Of Keywords Reflecting Sustainable Development Goals (SDGs)
The schedule of the job can be set in the same way as other cron jobs:
- Click Change schedule.
- Set the preferred interval.
- Click Update to confirm the schedule.
Configuring the job
Fields |
Screenshot |
|---|---|
|
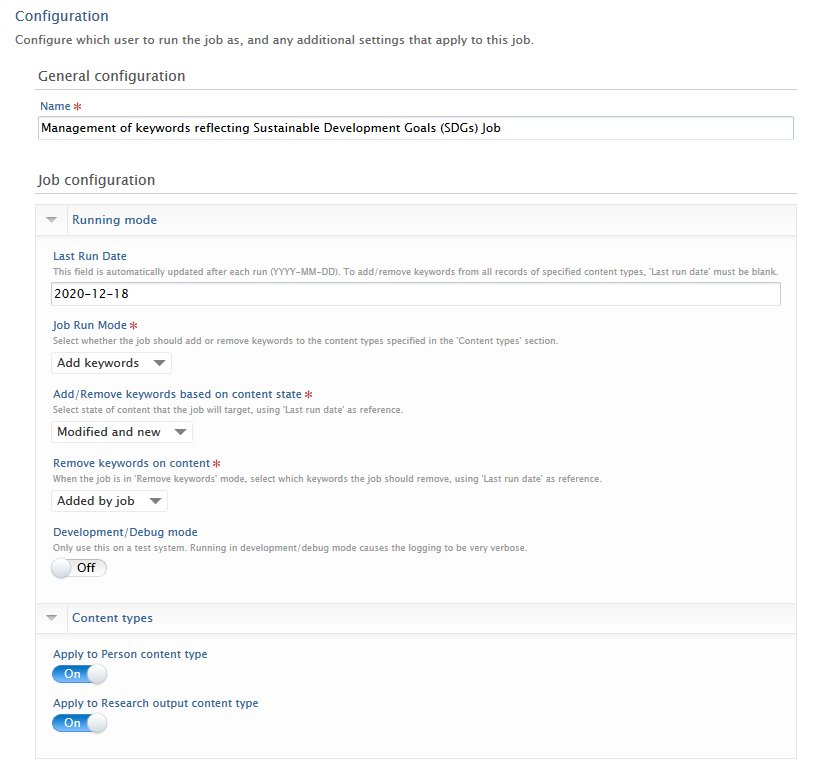
Running mode section Last Run Date This field is blank when the job is first run, and is then updated after each subsequent run. Job Run Mode You can specify whether you want the job to add or remove SDG keywords from content. Add/Remove content based on content state You can specify whether the tags should be added to content that is:
Remove keywords on content If you wish to remove SDSG keywords from content, you can specify whether to remove:
Development/Debug mode This setting allows to enable verbose logging. Content types section Administrators will need to actively enable each content type the job can add keywords to. All content types are disabled by default. |
|
|
Saving all changes If any changes are made to the schedule or configuration please remember to click 'Update' and 'Save' |
Common scenarios and configuration settings
Below are common scenarios and configuration settings for adding or removing SDG keywords. All of the scenarios require the job to be first enabled and scheduled.
| Scenario | Steps |
| Please remember to index your content before running the job | |
| Adding keywords | |
| This is the first run of the job, and I would like to add SDG keywords to all my Person and Research output records. |
|
| This is the second (third, etc.) run of the job, and I would like to add SDG keywords to all my Person records, but not my Research output records. |
|
| This is the second (third, etc.) run of the job, and I would like to add SDG keywords only to modified and new Person records since a specific date, but not to my Research output records. |
|
| Removing keywords | |
| I would like to remove all SDG keywords from all Person and Research output content records. |
|
| I would like to remove only SDG keywords added by the job, from only Research output content records, and only on new content since a specific date. |
|
| I would like to remove only user added SDG keywords from all Person and Research output content records. |
This scenario requires running the job twice, in the following sequence:
Removing all keywords:
Adding keywords:
|
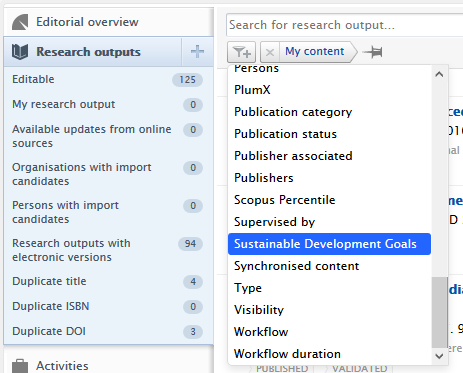
Filtering keywords on content types
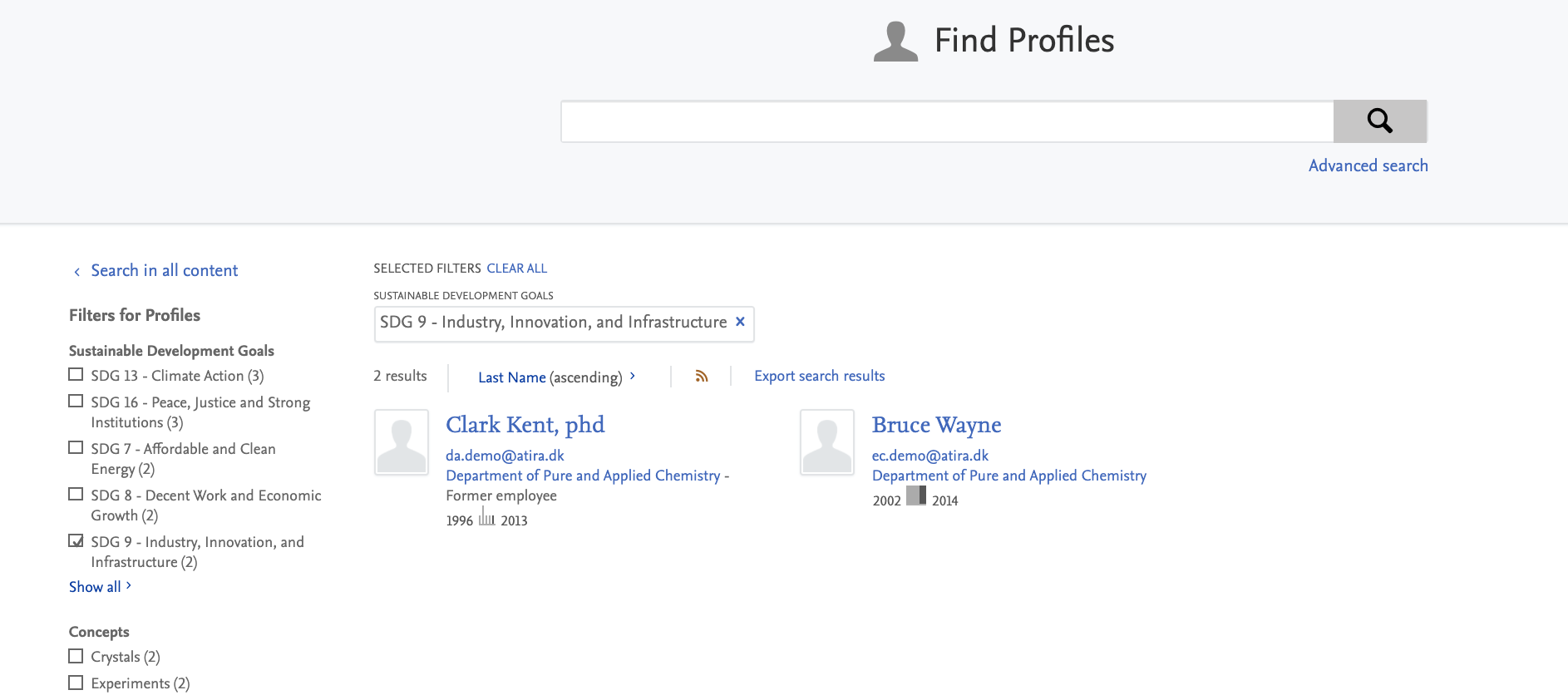
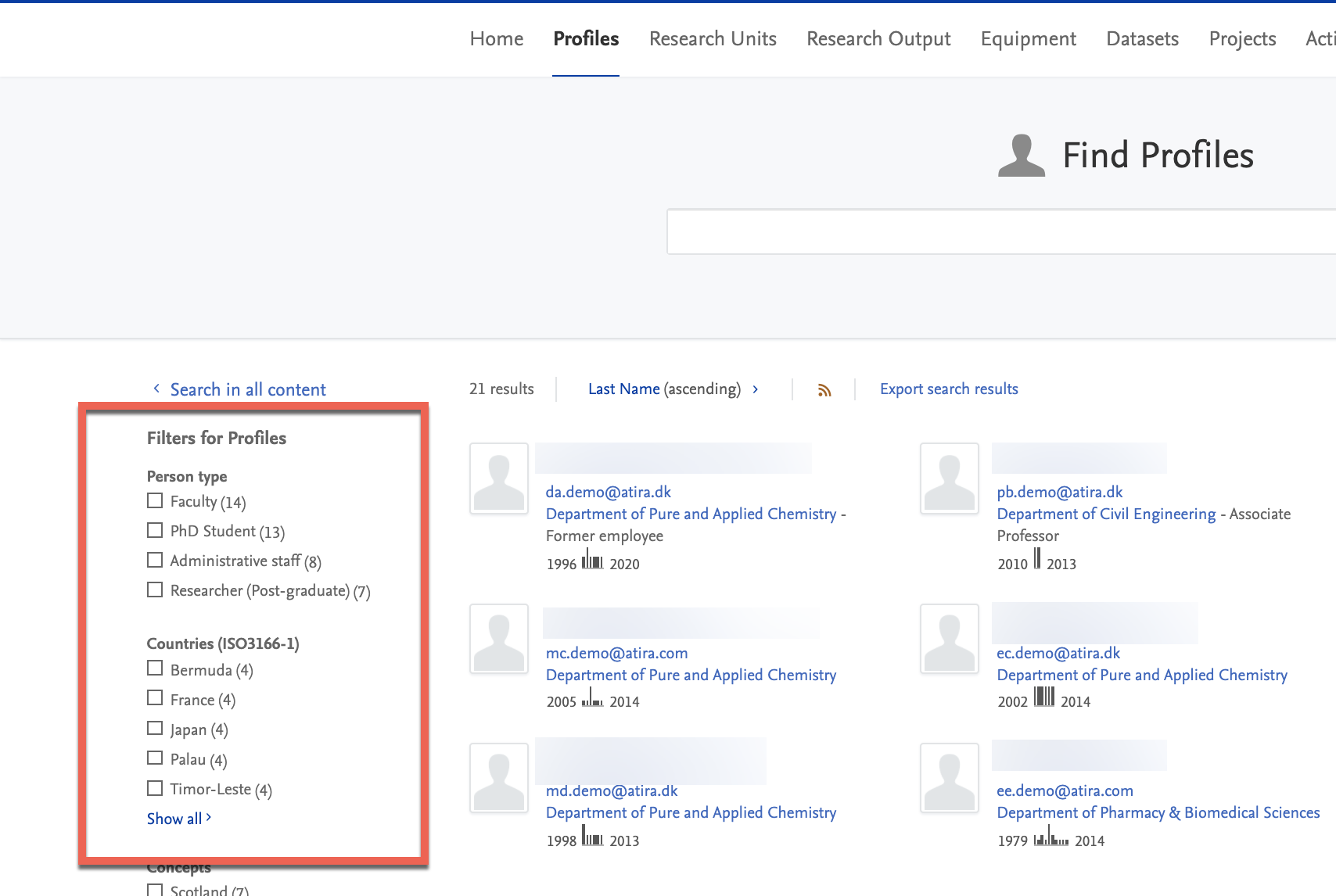
Content with SDG keywords can be filtered by using the Sustainable Development Goals filter for the Research output and Person content types.
Important notes on the addition/removal of SDG keywords
- The SDG classification scheme containing the keywords is called Sustainable Development Goals.
- The keyword group behaviour can be modified by administrators to allow users to add the keywords manually, or not at all.
- The SDG queries are defined within Pure, and are not currently available for editing. Please, contact Support if you have specific query update requests.
- There is no weighting or ranking of keywords on content. These are binary definitions, based on whether they do or do not match the search queries.
- SDG 17 - Partnerships for the goals, is not related to any specific content but to the collaboration on other SDG-related work. For this reason, SDG 17 is not automatically added to any content but is available for users to manually add to content they feel satisfies the criteria as set forth by the UN.
- If a user removes a keyword that was added by the job - it will be added again if the job runs again and the configuration in Running mode section - where Add/Remove keywords based on content state is set to Modified and new
3.2. SDG reporting
We have added two standard reports to the Reporting module:
- Number of Research Output per SDG
- SDG overview
Both reports provide an overview of your institution's output related to the Sustainable Development Goals.
Click here for more details...
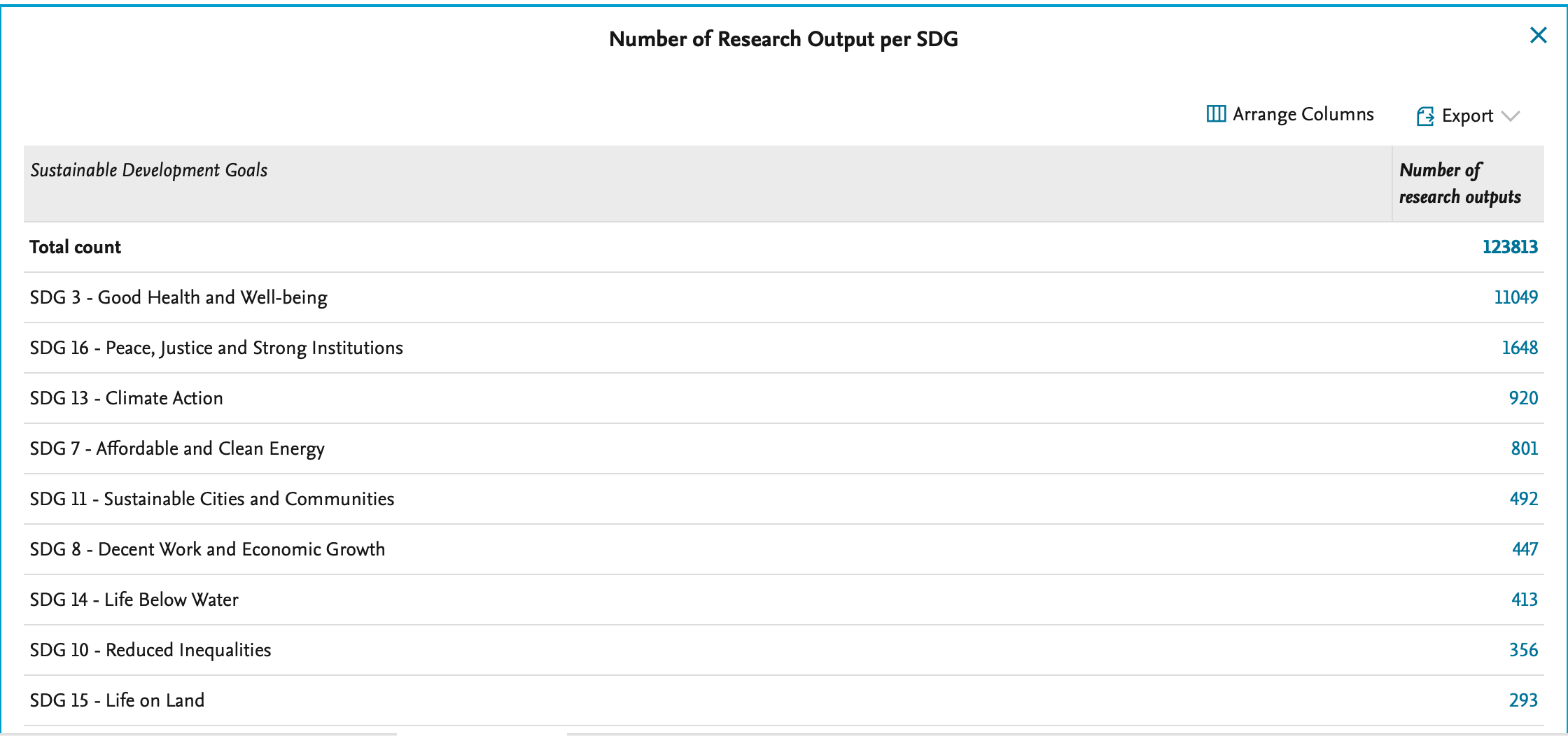
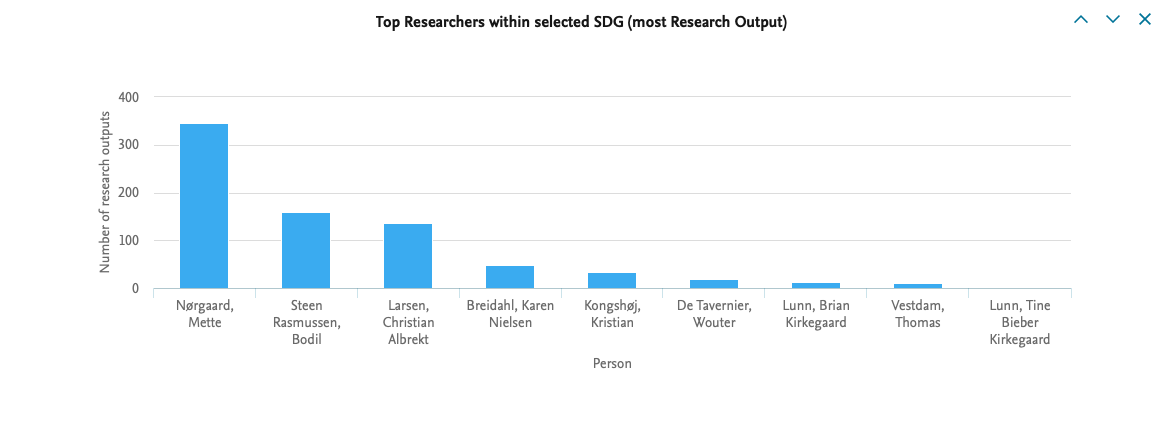
Number of Research Output per SDG gives an insight into how many research outputs have been published within each of the Sustainable Development Goals.
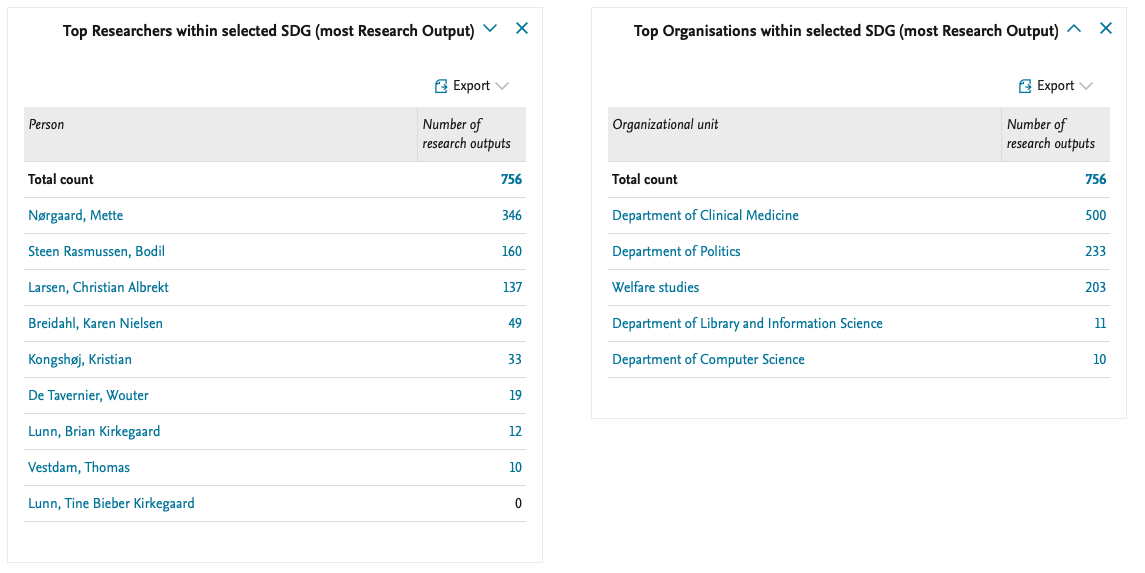
SDG overview gives an overview of which researcher or organisation has published most within the individual Sustainable Development Goals. The data story also allows you to zoom in on individual SDGs.

 |
 |
3.3. SDG Pure Portal homepage showcasing
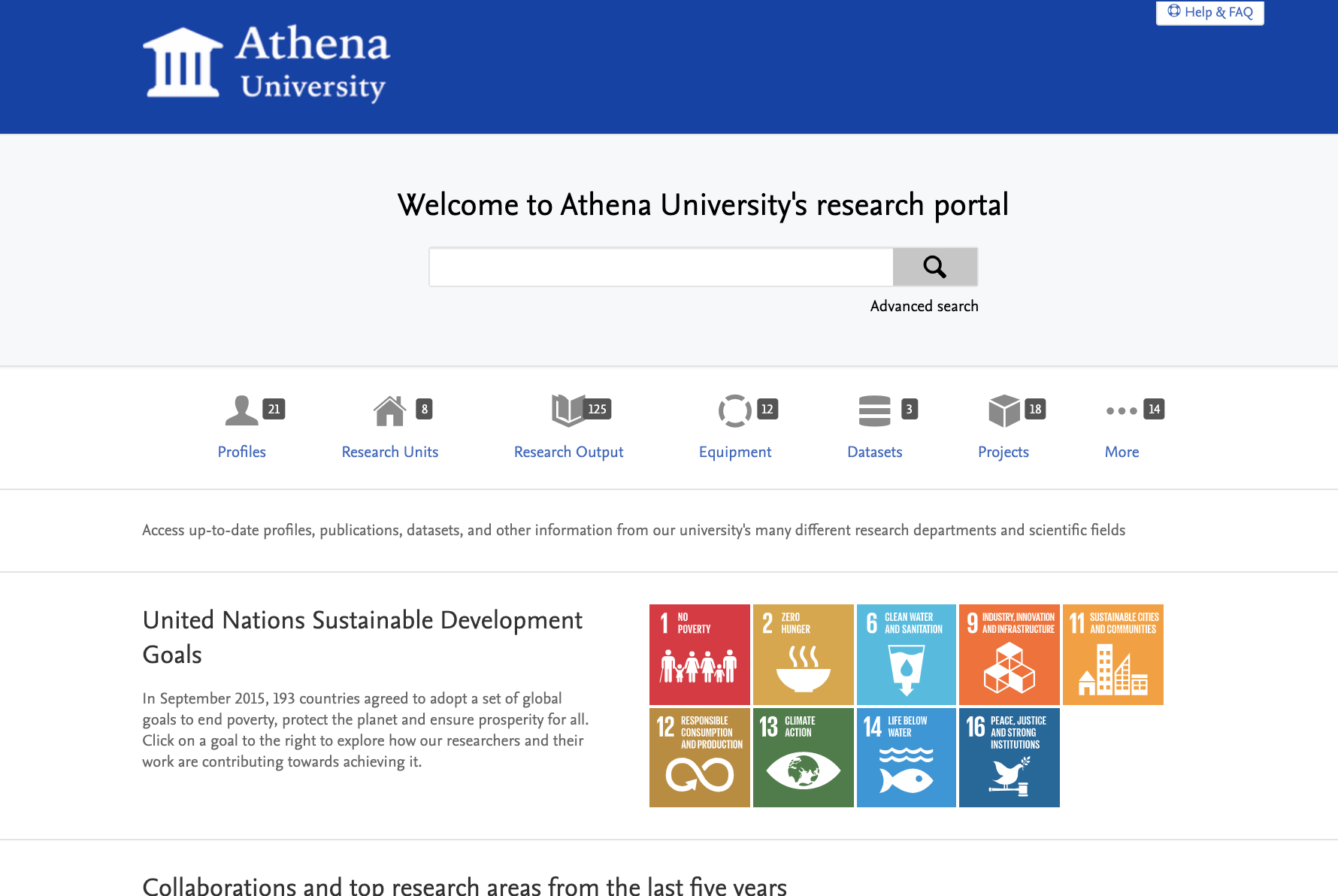
Once you have tagged your content with SDGs, you can use them to showcase and demonstrate your impact on your Pure Portal. The SDG homepage showcase can create dynamic, eye-catching links to all your SDG content directly from the homepage.
The title and description message text are fully editable so you can share your own sustainable development mission with your users. The logos to the right of the message are dynamically generated based on the content you have tagged as related to each SDG. Clicking on the logo of a particular SDG directs the user to an overview of related content for each tagged content type (currently Research outputs and Persons).
Click here for more details...
The homepage SDG showcase
The Sustainable Development Goals call for a bold showcase of an institution's work. The design is adaptive and will only show links to content that have SDG tags.
Administrators can enable the SDG showcase via the following steps:
- Adjust keyword settings to make the keyword group visible on the Portal.
- Edit the keyword group settings at Administrator > Keywords > Sustainable Development Goals.
- In the Keyword configuration editor, go to the Limit access to keyword group on content section at the very bottom, and enableboth the Show on portal and OAI and Show as filter on Portal configurations.
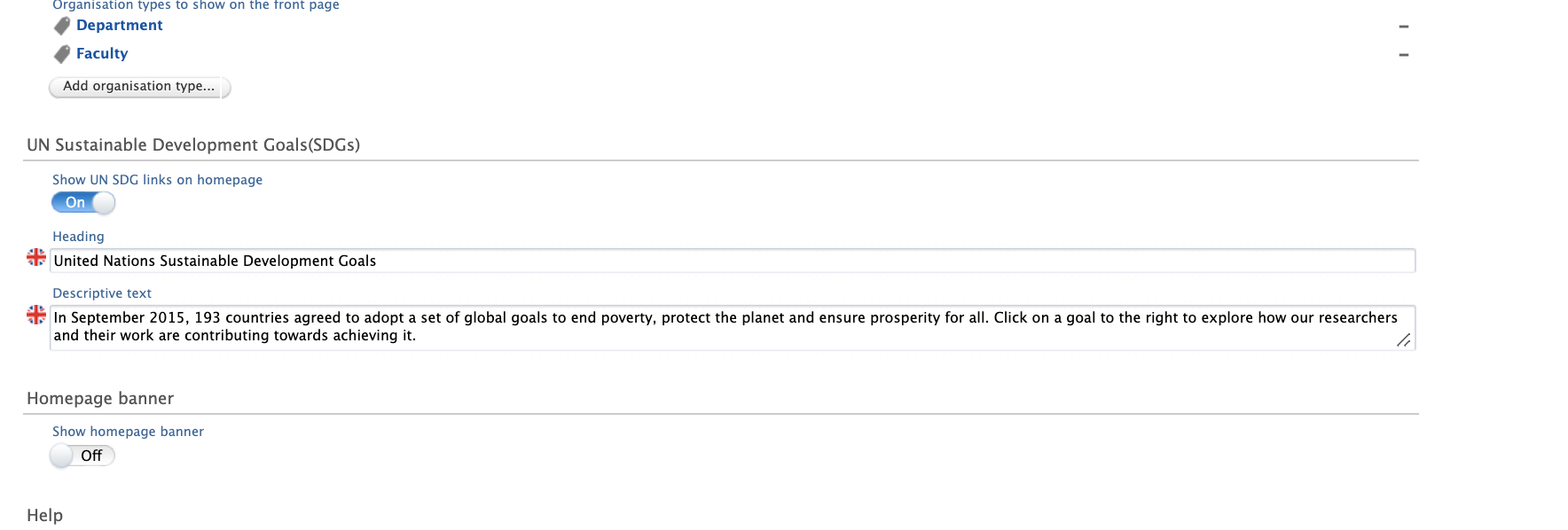
- Adjust Portal settings at Pure Portal > Styling & Layout > UN Sustainable Development Goals (SDGs).
- Toggle Show UN SDG links on homepage to start showcasing your SDG-related impact on the Portal.
Editing the title and description
We have prepopulated this feature with a heading and description. This message can be replaced by going to Pure Portal > Styling & Layout > UN Sustainable Development Goals (SDGs). When the feature is enabled (toggle on), administrators will see editable Heading and Description fields for all Portal languages.
Navigating the links
When on the Portal homepage, users can hover over an SDG logo to see its full name. Clicking on it will show an overview of the content in the Portal tagged as relevant to that goal:

Select one of the content types to navigate to a pre-filtered search overview page for that content type, which is relevant to the selected SDG:
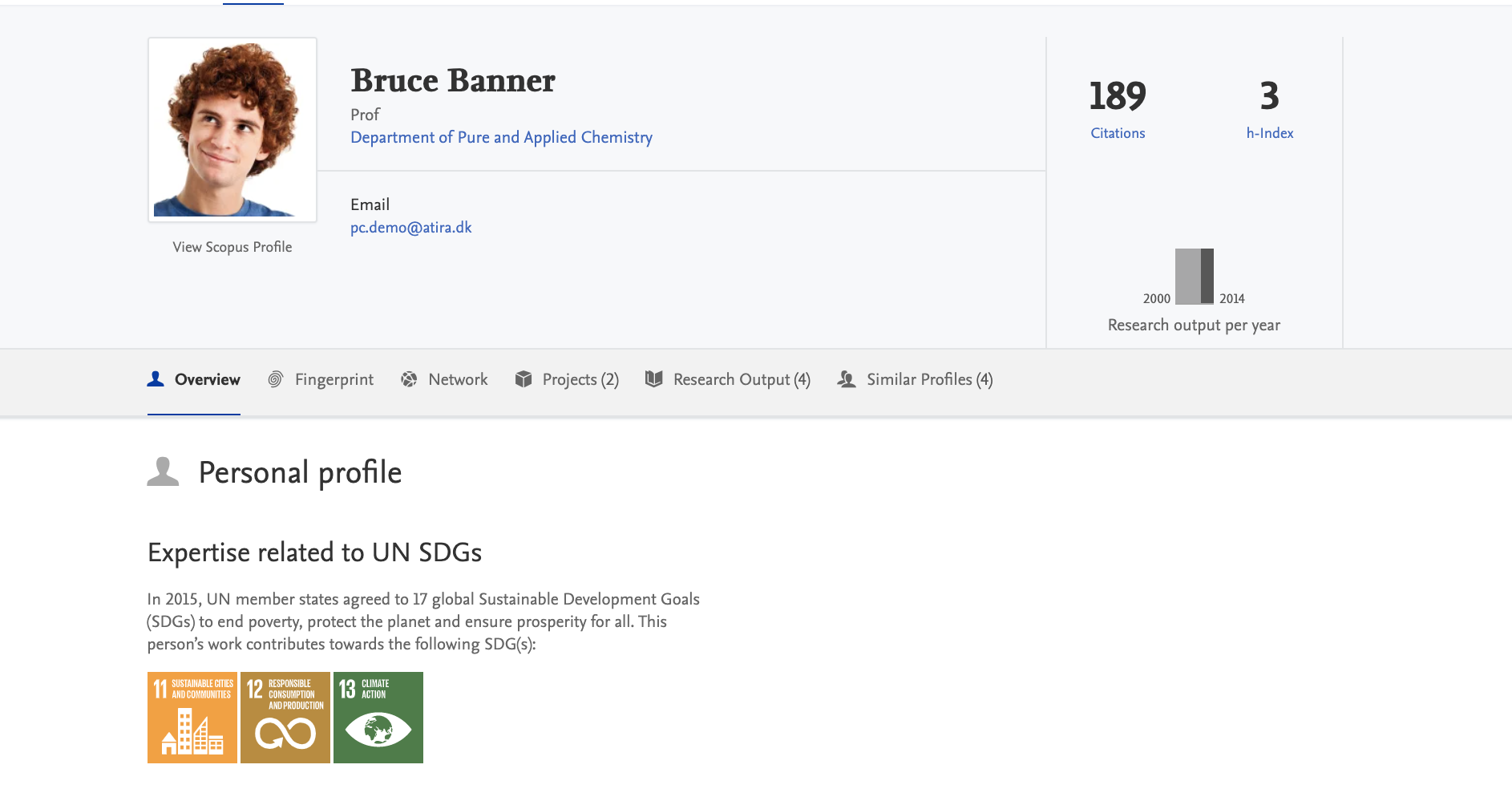
3.4. SDG badges on Persons and Research Outputs in Pure Portal
We are in the process of adding prominent SDG 'badges' to content pages, and starting with this release, we have added them to Persons and Research Outputs. Based on customer feedback, we will add these to more content types in the future.
We have used the official SDG logos from the UN as the badge itself and users can hover over each tag to read the full name of the SDG.
 |
 |
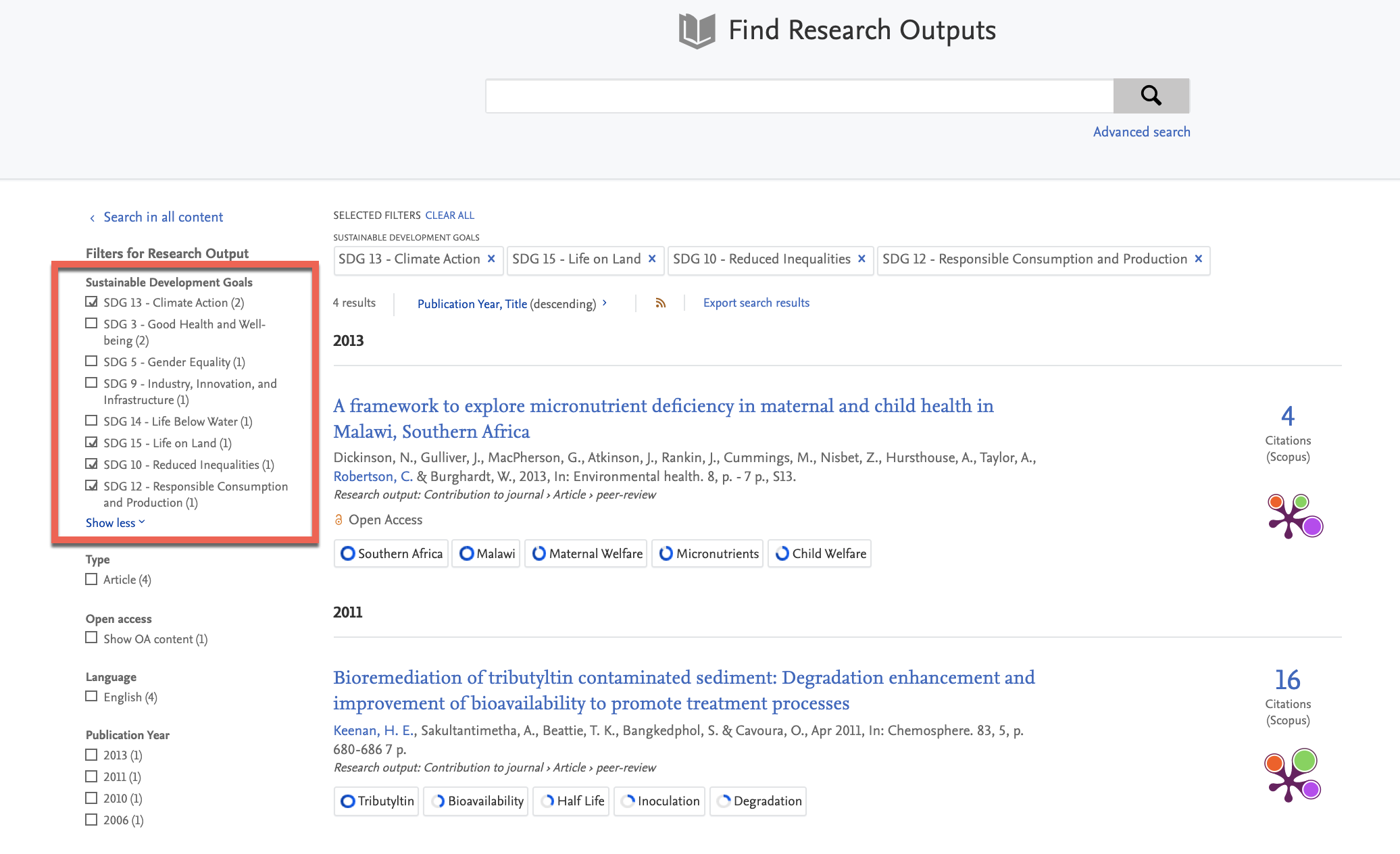
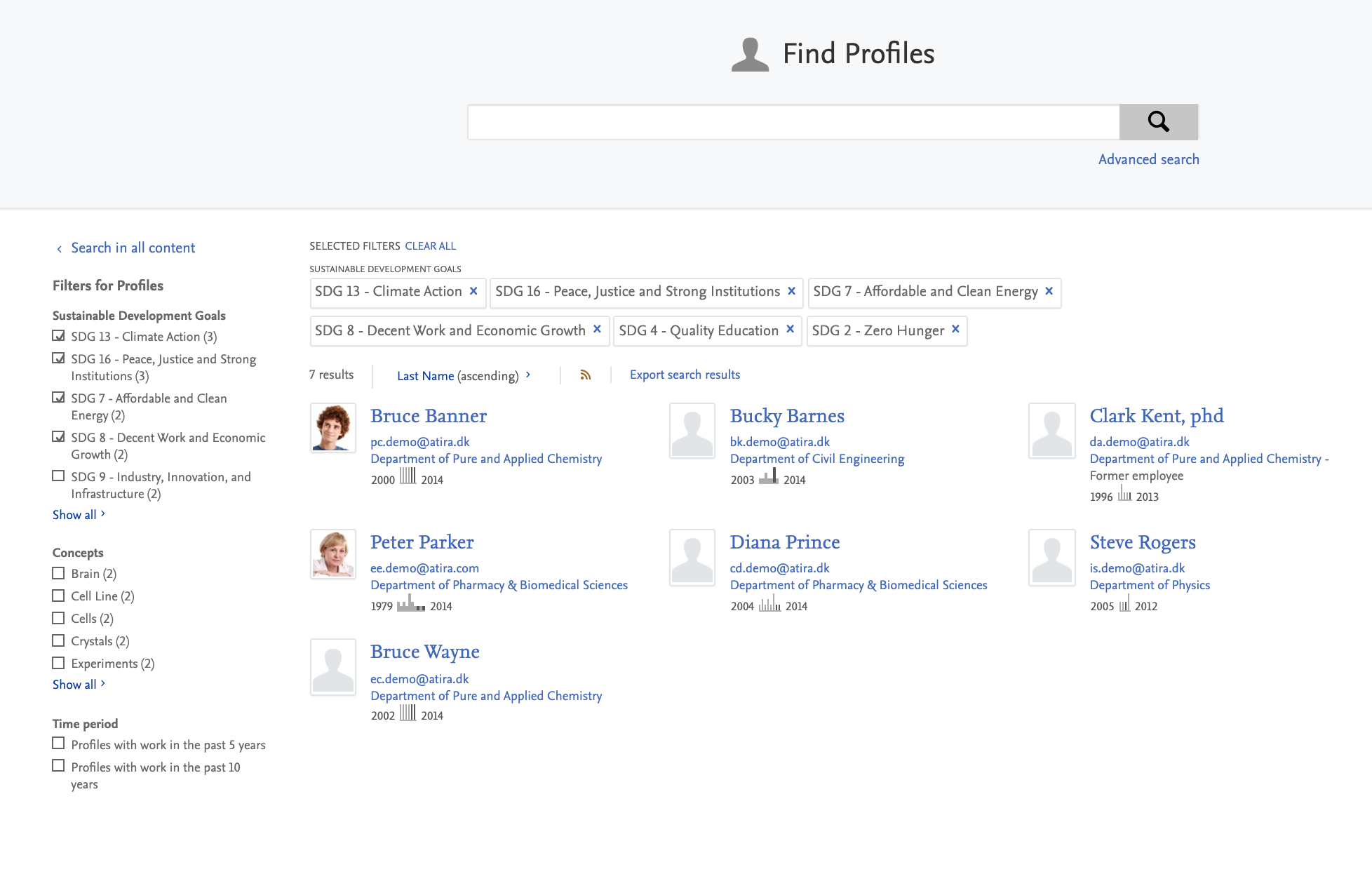
3.5. SDG Pure Portal search filters
In order to highlight your institution's SDG work to the highest degree possible, administrators can use our new custom filter feature (see Custom filters section in these release notes) to create a new custom SDG filter.
This serves to highlight SDG-related work on all search results pages, and help portal users to easily find and navigate to work related to a specific SDG that might be relevant to them.
 |
 |
4. Pure Core: Administration
4.1. Global Search
The global search functionality has been updated and improved to provide clearer and more accessible results for users. Previously, search results across content types were limited to what content types were present in the top 50 results across all content types. Global search results now represent the results found across all content types.
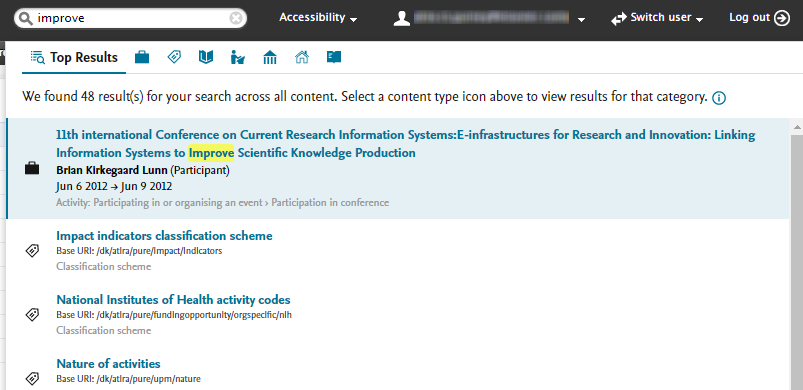
Click here for more details...
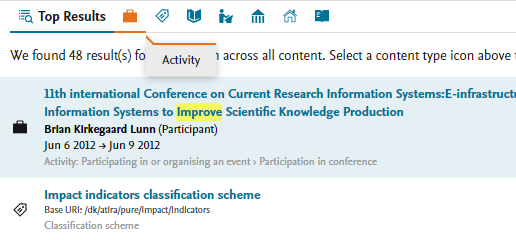
| Improvements | Screenshots |
|
On hover tool tip Users can now hover over icons to see the full name of the content type that the icon represents. |
 |
|
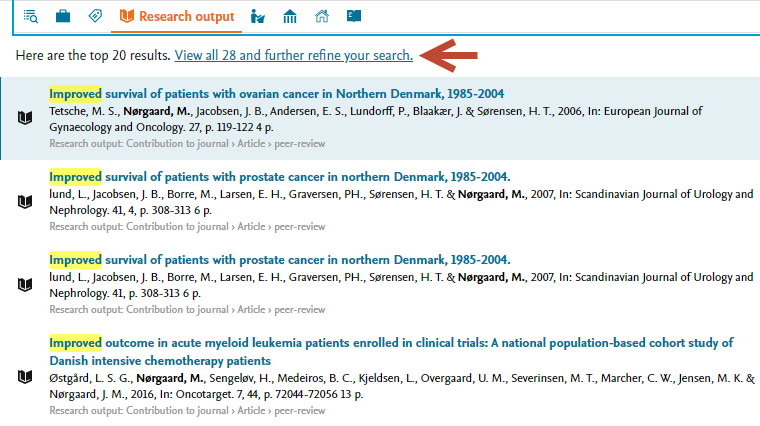
Total and per content type counts The total count of search results is displayed in the Top Results tab. Total results per content type are shown on each content type tab. |
|
Click through to content overview screen and search refining Users can now more easily click through to the content overview screens for the content type, and further refine their search using the content specific filters. As this is a global search feature, the My Content filter has been removed from the content overview. |
 |
|
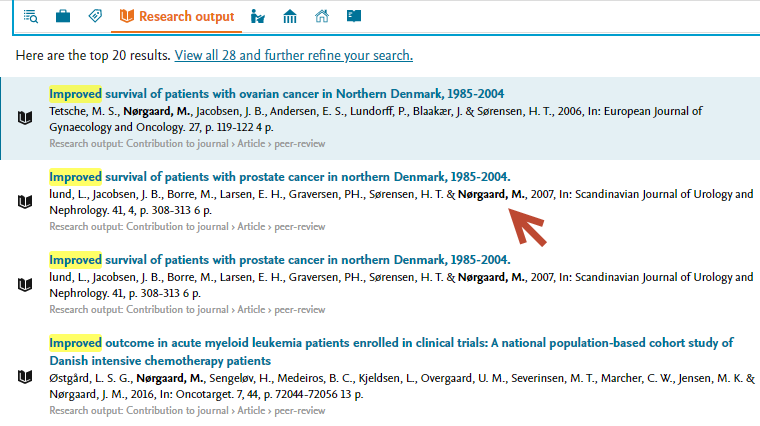
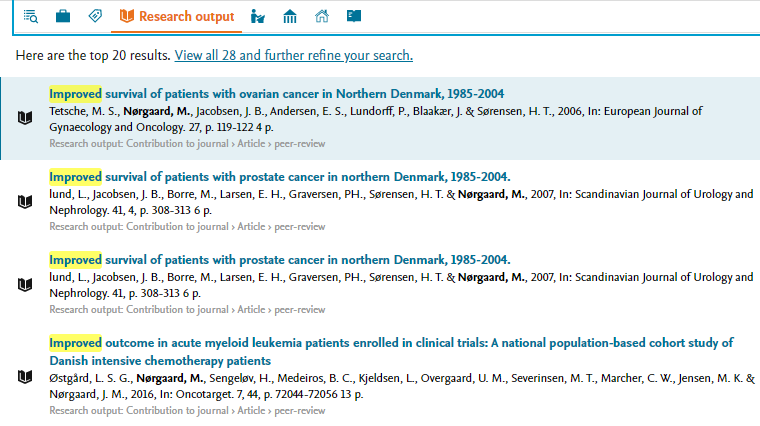
Internal contributors highlighted in bold text All internal contributors are now highlighted in bold. |
 |
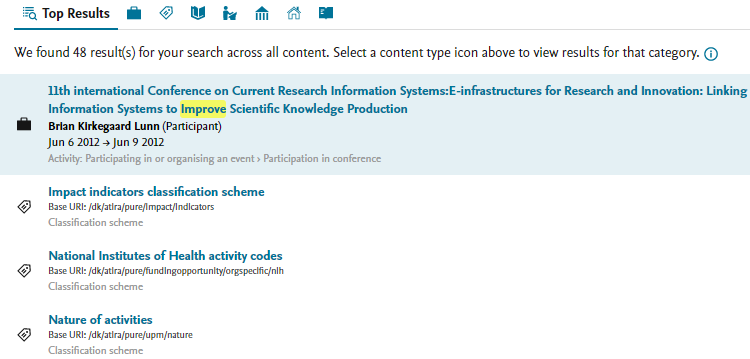
4.2. External Organisation model update
As part of our external organisation cleanup efforts, we are moving to a more unified view of how all organisations are treated in Pure. To that end, we have brought the two organisation (external and internal) models more in line with each other with the introduction of hierarchy, lifecycle and taken-over-by functionalities on the external organisation model. We will be extending the reporting capabilities to cover hierarchical and life-cycle data in subsequent releases.
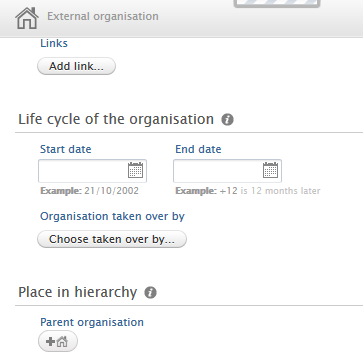
4.3. My History
The My History functionality has been improved to provide the easiest, most consistent view of content previously viewed, modified or created. The My History feature now functions as an on-hover slide up view, accessible from the bottom left corner of the main windows. The new functionality also highlights the last action performed by the user, shown as a tag on each record in the My History list.
4.4. New Personal User Overview as standard person profile
The new personal user overview (PUX) is now the standard person profile for all customers except those based in the UK. Administrators will no longer be able to allow users to switch between profile views. The new personal user overview was introduced in 5.14.0 and is a significant improvement to how personal users access, work, explore and add content within Pure. The new overview has a cleaner, simplified style, with improvements to fonts and color selection for accessibility. It continues the design changes we've already begun in Pure.
The new overview is tightly integrated with the personal user’s Pure and PlumX data at the research output, project and researcher level. This includes coverage of content added by the user and institution, and PlumX mentions, usage, captures, social media and citation data for each research output where available. The new overview is aimed at encouraging productive and meaningful engagement between the personal user and their content in Pure.
The welcome message presented to all personal users in the new Personal Overview page (PUX) can now be completely configured. Administrators can create rich text messages, including links and formatting.
PlumX API technical recommendation in effect
19 Feb 2021 - Update from Pure Product Team
The PlumX API is currently experiencing technical issues which affects how quickly metrics are retrieved from PlumX, and added to individual research outputs within your Pure. PlumX, Elsevier API and Pure are working to resolve the issue as soon as possible.
To ensure all metrics are retrieved and added to your research outputs in a timely manner, please update the batch size in the PlumX configuration options to 50. The smaller batch size will ensure that the API does not return any errors.
Detailed instructions and more information can be found at the PlumX API client page.
Click here for more details...
For more information on the personal user overview, please consult the 5.14.0 release notes, and the user guidewritten from the perspective of an administrator for their personal users that can be found in a separate wiki page. The guide is designed to supplement any training material provided to personal users. A PDF version is provided as well as image files in .png format.
Configuring the welcome message
To configure the welcome message, got to Administrator > Persons > Personal Overview configuration. Enable Add custom message in the Customize the personal overview welcome message section.
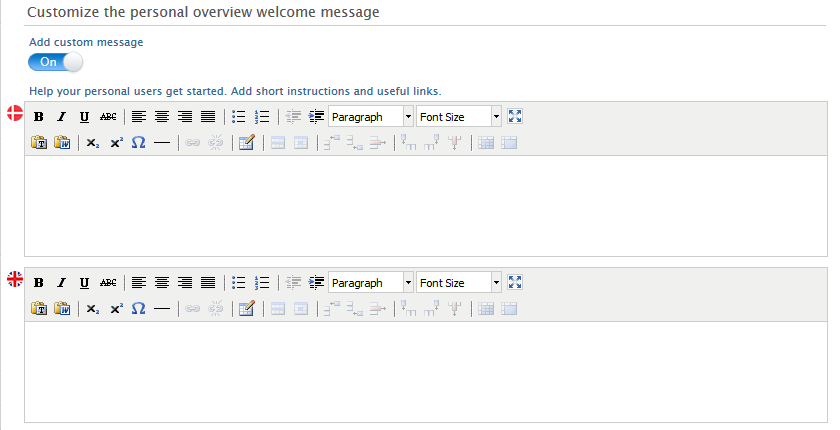
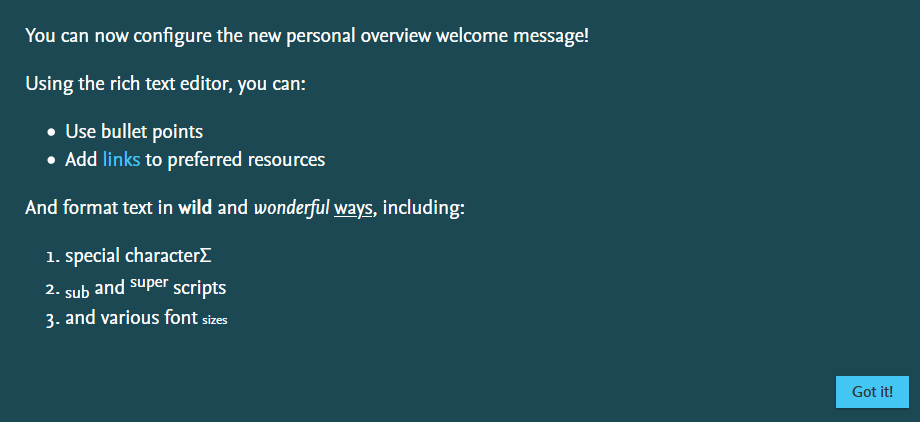
Once your message is configured, make sure to Save.
Notes
Due to post-processing of the message (links, fonts, etc. are formatted to match the overall style of Pure), we highly recommend that you keep your text in the paragraph format and not use heading formatted text.
4.5. Additional filtering options in list view
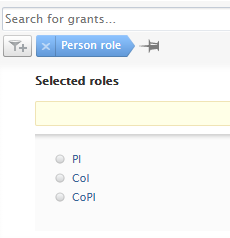
We have added several filtering options to make it easier to manage different content types. The Created by me option has been added to all content types on the My content filter. Additionally, the Person role filter has been added to Award/Grant, Application and Project content types, and filtering on financial fields on the Award/Grant and Application content types has been better aligned and improved.
Click here for more details...
Filter description |
Screenshots |
||||
|---|---|---|---|---|---|
| All content types for which My content filter is available, now also have the option to filter to content created by the currently logged in user (Created by me). This will make it easier to find content you have created and are primarily responsible to drive forward in the workflow if there are several stakeholders involved. | 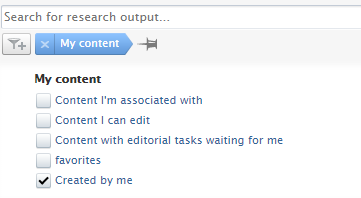 |
||||
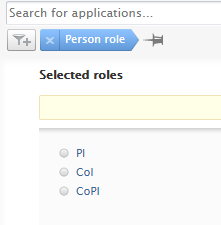
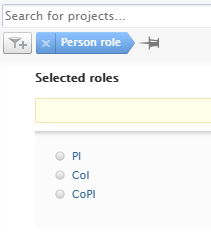
| The Person role filter has been added as an option to the Award/Grant, Application, and Project content types, making it possible to find content based on the role that the person associated with the content performs. |
|
||||
| The Financial filter has been added to the Award/Grant content type, making it possible to find all Awards/Grants which are either financial or non-financial. | 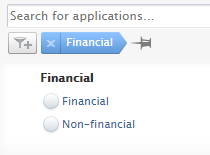 |
||||
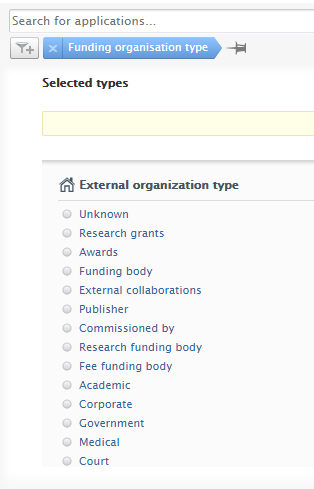
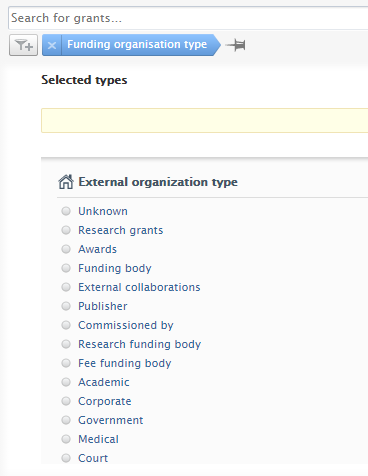
| The Funding organisation type filter: the option to find content based on the associated external organization type (funder) has been added to both Award and Application content types. |
|
4.6. Help improve our deduplication model
At Pure, we do our best to ensure high quality of your data. As part of this process, we are working on machine learning algorithms that deduplicate research outputs.
In order to improve the accuracy of our algorithms, we need more training data that is tagged with relevant information. You can now choose to help us improve the research output deduplication mechanism by granting us access to a subset of your research output data. The data we will be accessing is the information about the research outputs that have been merged or deemed as distinct, where we will receive metadata from the following fields:
- title
- subtitle
- name of authors
- type
- DOI
- publication category
- keywords
- publication year
This data will be used exclusively by Pure to train a machine learning model to recognize duplicate research outputs. Please note that the data provided will only be used to train the model, so will remain anonymous and will not be associated to an institution. This data will temporarily be stored to allow for sufficient training of the model, but will be permanently deleted once the training model is finalized and released.
If you want to help us, please create a support ticket, and we can extract this data from your running Pure once it is upgraded to 5.20.0
5. Pure Core: Web Services
5.1. Updated ResearchOutput swagger definitions
The WSResearchOutput swagger definition has had several fields updated in order to now more correctly match with the data model across xml and json.
These following fields have been updated:
- printISBNs changed to isbns
- electronicISBNs changed to electronicIsbns
- caseNotes changed to courtCases
- links changed to additionalLinks
- articleProcessingChargesCurrency changed to articleProcessingChargeCurrency
- openAccessEmbargoMonths is changed to embargoMonths
- openAccessEmbargoDate is changed to embargoEndDate
Click here for more details...
See the following example:
"openAccessEmbargoMonths": {"type": "integer","format": "int32","xml": {"name": "embargoMonths"}},"openAccessEmbargoDate": {"type": "string","format": "date-time","xml": {"name": "embargoEndDate"}} |
Is changed to:
"embargoMonths": {"type": "integer","format": "int32"},"embargoEndDate": {"type": "string","format": "date-time"} |
5.2. Pure API schema breaking changes
Some inconsistencies in the schema of the new Pure API have been aligned.
Breaking changes:
- OrganizationOrExternalOrganizationRef.externalOrganisationRef renamed to externalOrganizationRef. This is to align the spelling of organization.
- The systemName/discriminator of OrganizationRef has been renamed from 'Organisation' to 'Organization'. This is to align the spelling of organization.
- The systemName/discriminator of ExternalOrganizationRef has been renamed from 'ExternalOrganisation' to 'ExternalOrganization'. This is to align the spelling of organization.
- "previousUuids" on all Content, "uuids" on all Queries and "uuid" on all ContentRefs now have format="uuid". Previously, some cases of an uuid had the type String instead of uuid.
5.3. Highlighted content for Persons (Pure API)
Content selected as Highlighted content for persons is now exposed through the new Pure API. The new API also allows to update which content is highlighted for a person. As the Person synchronization does not support highlighted content, this serves as an alternative for those customers who want to manage highlighted content outside of Pure. However, the new API is not yet complete so a mixture of the current and new API is needed to retrieve the full details of highlighted content.
Notice: The endpoints are only available to the API keys which have access to the Person content type.
Click here for more details...
To those using this feature, we recommend enabling the 'Web service' setting in Administrator > Web services > Highlighted Content. This will allow personal users to curate their highlighted content in the person editor. When this setting is disabled, only Pure Portal-related content will be visible, and if no Portal is configured, the highlighted content menu item will not be available in the person editor.
The following content types can be highlighted through the web service:
- Research outputs
- Activities
- Applications
- Awards
As with other endpoints, the output of the GET operation can be used as input to the PUT operation. Here is an example output response
{"researchOutputs": [{"systemName": "ResearchOutput","uuid": "af71dc5e-eb65-4bc0-91db-6f25eba09cb6"},{"systemName": "ResearchOutput","uuid": "92c43776-f5ee-40a0-8c8b-0fe662432ca6"}],"activities": [{"systemName": "Activity","uuid": "1a0b2d07-6128-4efe-a3cb-08e59006a260"}]} |
This PUT operation uses the same patch semantics as other PUT operations.
If you only PUT a json object with "researchOutputs" specified, then only the highlighted research outputs will be updated.
If you want to clear a list, just submit an empty list, for example:
{"researchOutputs": [{"systemName": "ResearchOutput","uuid": "af71dc5e-eb65-4bc0-91db-6f25eba09cb6"}],"activities": []} |
If the above example was used to update the highlights of the same person in the "Example of response" then it would remove the activity and the second research output, where the following would only remove the second research output, but not alter the activity:
{"researchOutputs": [{"systemName": "ResearchOutput","uuid": "af71dc5e-eb65-4bc0-91db-6f25eba09cb6"}]} |
5.4. Merging External organisations (Pure API)
Two new endpoints have been added, making it possible to manage merging and deduplication of External organizations in Pure through the Pure API.
- Preview-deduplication: shows a preview of how Pure would handle deduplication of 2 or more External organizations.
- Merge: merges 2 or more External organizations together and updates all related content to point to the merged External organization.
Click here for more details...
Preview-deduplication
This endpoint is used to determine whether Pure would consider two or more External organizations to be duplicates and how the merged result would look like. Note: This operation does not perform any database changes, and the external organizations do not have to be in the Pure database.
The input is a list of External organization objects, and the output is the deduplicated lists of External organizations:
- if they are all considered duplicates by Pure, one external organization is returned;
- If they are all considered distinct, then the same number of external organizations will be returned.
The External organizations considered to be duplicates will be merged together. Note: The list of External organizations provided is considered a prioritized list, so the first duplicate organization will be the new target object, and fields from the other duplicate external organizations will be added to this one if any data fields are missing.
Merge
This endpoint merges two or more External organizations together and updates all related content so that it points to the merged External organization. This operation is irreversible, as there is no operation to un-merge the content.
The input is a list of uuids of External organizations you want to merge. Note: All of the External organizations must exists in Pure database, and all of the External organizations will be merged into the first instance of that organization on the list.
{"items": [{"uuid": "60a3a63e-9a17-4940-b43f-ac160d9ab134","systemName": "ExternalOrganization"},{"uuid": "53e58906-7035-485a-92ac-6f9ae404e398","systemName": "ExternalOrganization"}]} |
As a result of the operation, the merged External organization will be returned as a full json object. If the preview-deduplication endpoint was called with the full json object of all the External organizations merged, it could be used to see how the merged objects would look like (if they were deemed duplicates by Pure).
When merging, all unique information from the records is saved:
- fields that are empty on the target are added if found on the merged record(s)
- data in the multi-value fields is merged
- identical values are merged into one on the target
- non-identical values from both records are kept on the target
As a result of the merge, all dependent content on the External organizations will be updated to point to the new target External organization, see section 5.5 for further details on that endpoint.
5.5. Dependents (Pure API)
A dependents endpoint has been added for the following content types: External Organization, Organization, Journal, Publisher in the new Pure API.
This endpoint is used to find all content which is dependent on the provided content. These dependents will be updated if the merge operation is invoked as described in previous section.
Click here for more details...
To access a dependents endpoint, you need to use an API key which has access to the content type which you want to get dependents of. For example, to be able to call access /external-organizations/{uuid}/dependents you need to use an API key which has External organizations enabled.
An example of a response could look like this:
{"items": [
{"systemName": "ResearchOutput",
"uuid": "979ed98b-07cf-45d5-b342-68a42a174a69"
},{"systemName": "ExternalPerson",
"uuid": "88e99cdb-ef00-4850-93b3-3ad972308846"
},{"systemName": "ExternalPerson",
"uuid": "68efb12f-ae14-41ba-8569-bd508c73cd51"
}]} |
Each dependent record will then be listed with systemName and uuid. It is possible to retrieve the dependents through the new API (if supported); otherwise, the current API will return them.
However, if any of the dependent content is not visible to the user or the API, then this will not be exposed. This means that the returned items can be empty even though dependents exist (for example, if the backend content is not exposed through the API).
6. Integrations
6.1. New Import Source: medRxiv
medRxiv (https://www.medrxiv.org/) is a (Open) preprint service for the Medical, Clinical and related Health Sciences.
The integration with medRxiv provides researchers and institution with content in Medicine and Health Sciences, especially relevant at this time to stay up-to-date with the newest COVID-related studies and results.
Click here for more details...
Instructions on how to enable, add, and search for content from medRxiv are shown below.
Instructions |
Screenshot |
|---|---|
| To enable medRxiv as an import source, go to Administrator > Research Output > Import Sources. | 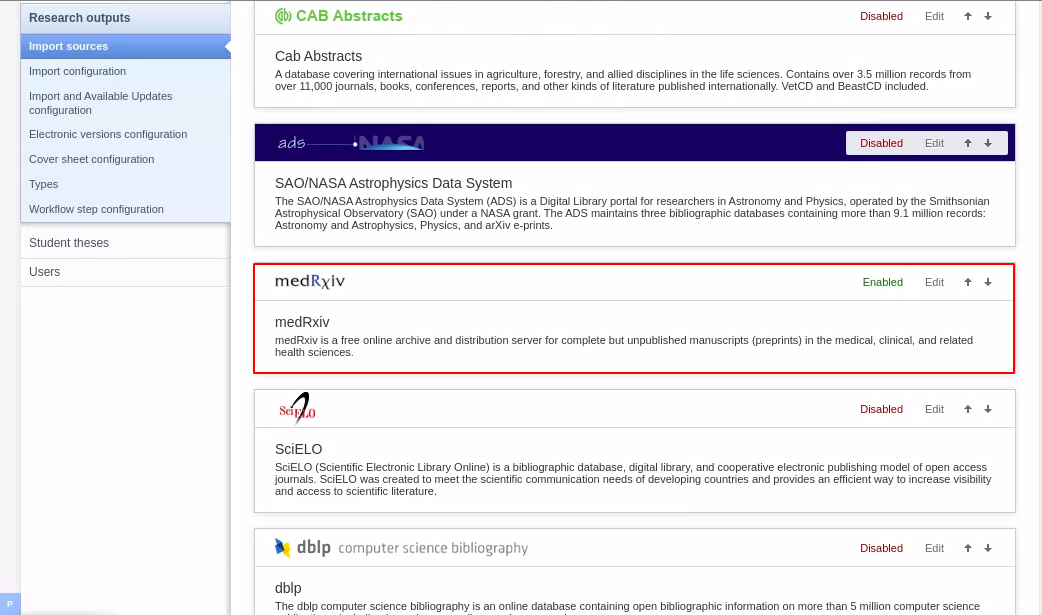 |
| To search for and import content, go to Editor > Research Output > Import from online sources and select medRxiv. | 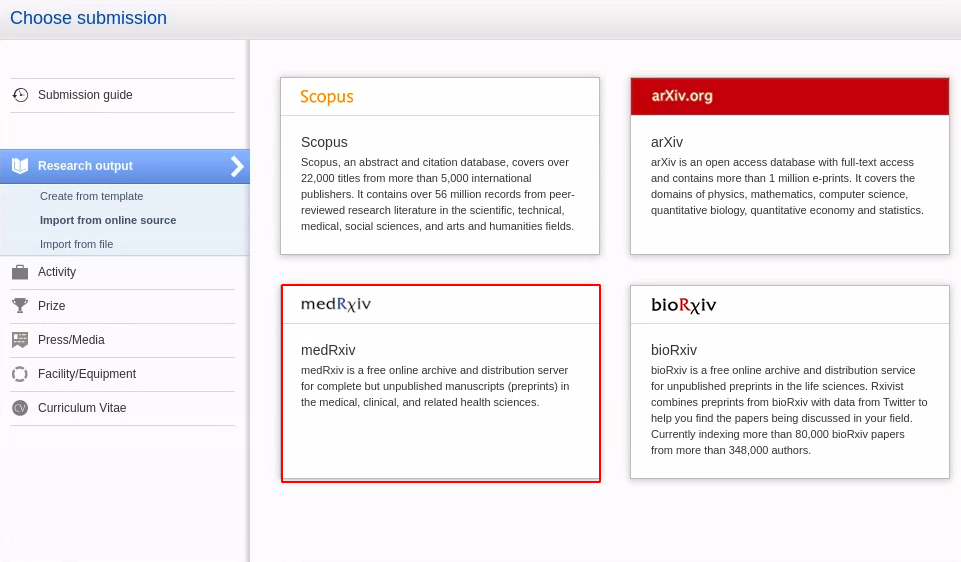 |
|
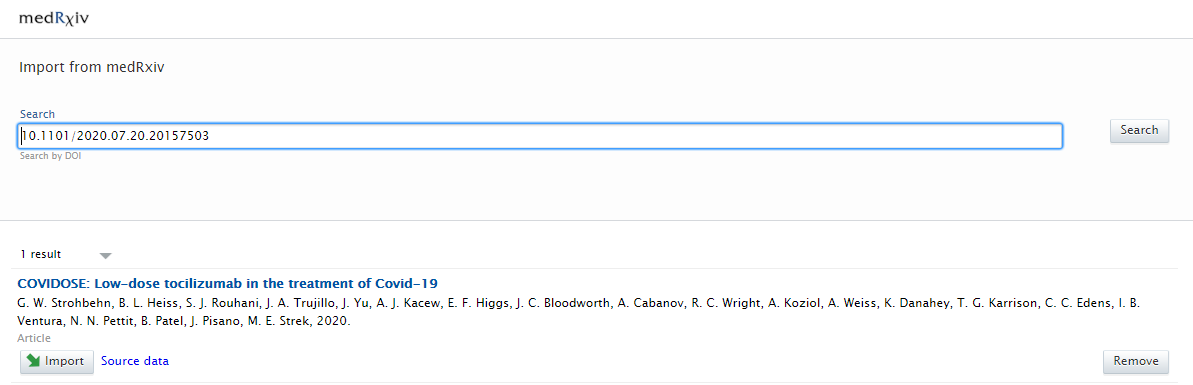
There is one option when searching for content:
Search results are presented as import candidates and can then be previewed and imported (or removed). Records that already exist in Pure are shown as duplicates. |
 |
6.2. New Import Source: IEEE Xplore
IEEE Xplore (https://www.ieee.org/) is a research database for discovery and access to journal articles, conference proceedings, technical standards, and related materials on Computer Science, Electrical Engineering and Electronics. It contains materials published mainly by the Institute of Electrical and Electronic Engineering (IEEE).
This integration provides researchers with access to more than five million documents - including more than 193 peer-reviewed journals, more than 1,700 global conferences, more than 6,200 technical standards, approximately 4,000 e-books, and over 425 online courses.
Click here for more details...
Instructions on how to enable, add and search for content from IEEE Xplore are shown below.
|
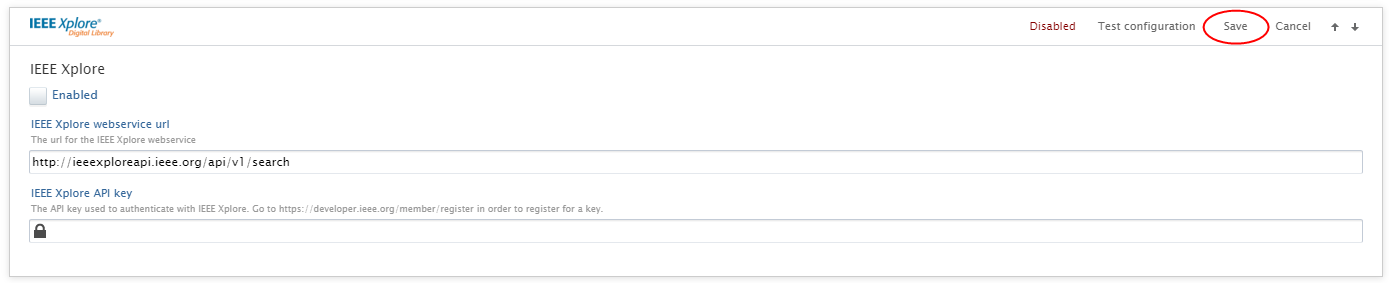
An API key is required for authentication with IEEE Xplore. To register for an API key go to https://developer.ieee.org/member/register. After inserting the API key, enable the source and click Save. |
 |
| Search results are presented as import candidates and can then be previewed and imported (or removed). Records that already exist in Pure are shown as duplicates. | 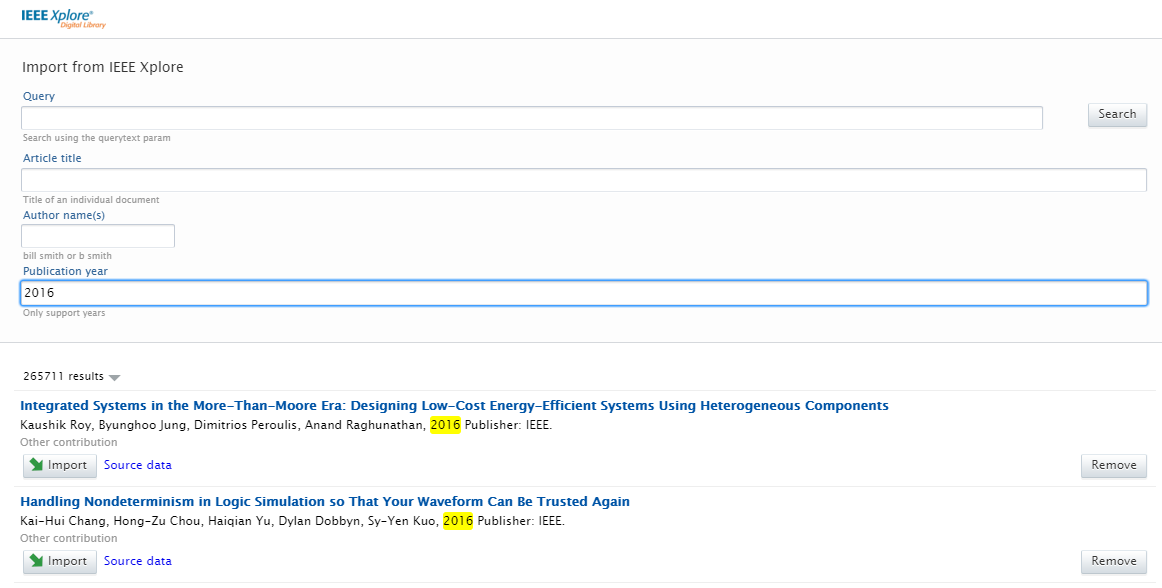 |
| To enable IEEE Xplore as an import source, go to Administrator > Research Output > Import Sources | 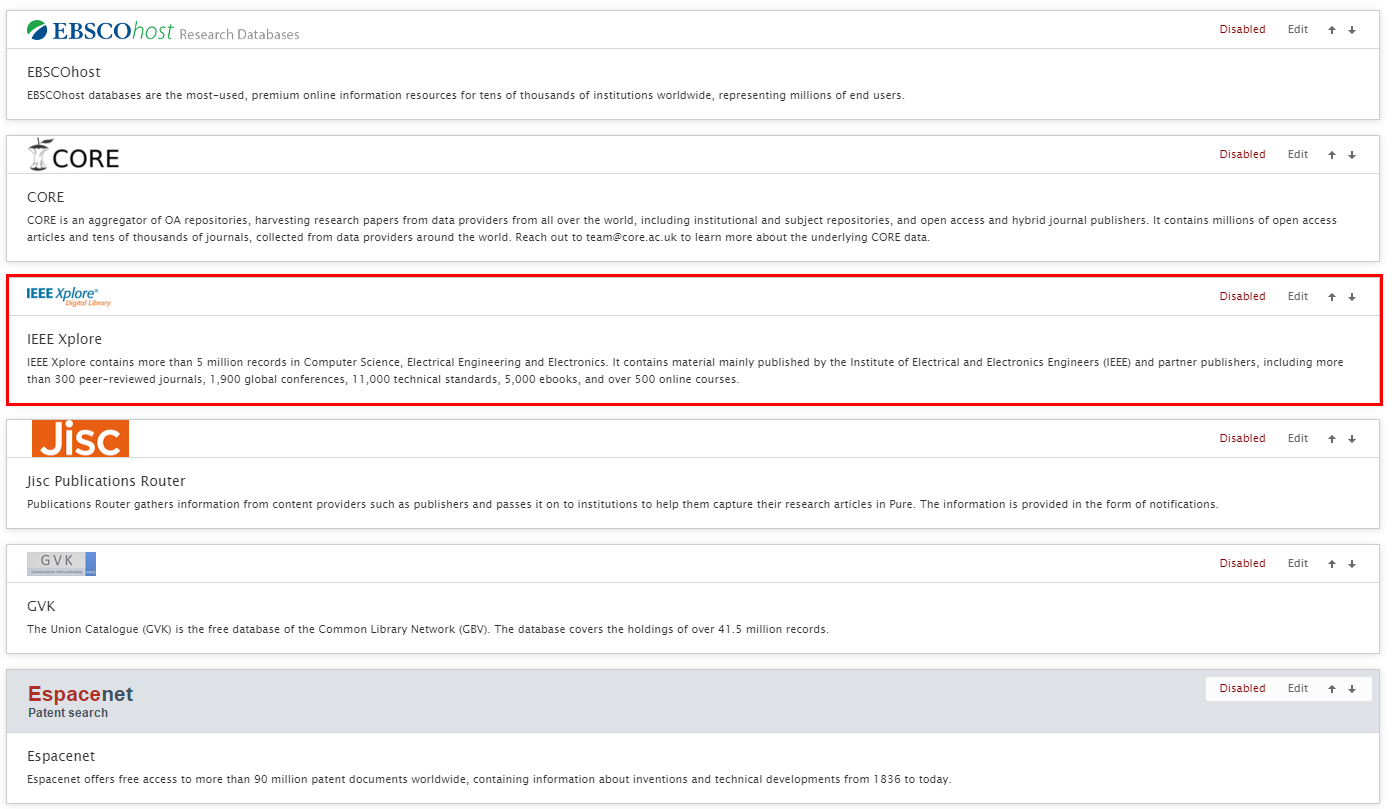 |
| To search and import content, go to Editor > Research Output > Import from online source and select IEEE Xplore. | 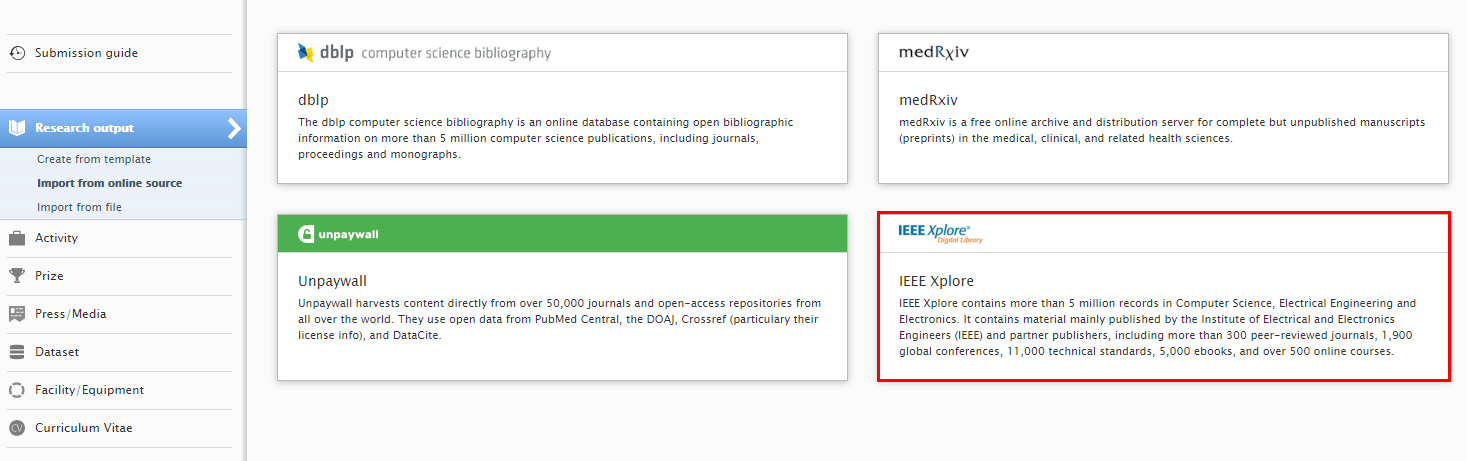 |
|
You can now search content using query text, article title, author names, or publication year. You can also combine the values. For instance, if you are interested in content with a certain title and author from a specific year, then you can fill out all of the fields and do a combined search. The query field is a text field where you can type out your search criteria and it will try to match everything. For example, if you want to search for a title containing 'humanity' by author named John Doe that was published in 2005, then your query would be "humanity John Doe 2005". |
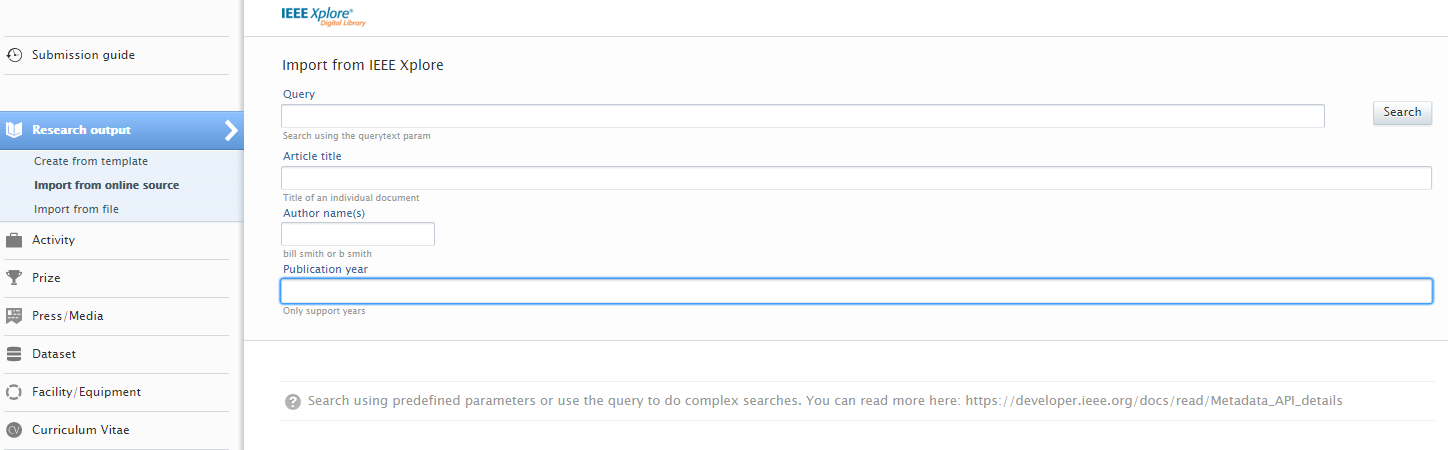 |
6.3. Self-import for datasets
In this release we are happy to announce that we expanded functionality for datasets in Pure, making it possible for researchers and personal users to search for and import datasets from specific repositories.
In addition, Mendeley Data Monitor has been added as a self-import source, allowing scientists and researchers to search for datasets across a variety of domain-specific and cross-domain institutional repositories and other data sources. Researchers can quickly preview and assess datasets before accessing them in the destination repository.
Click here for more details...
Instructions on how to enable, add and search for content from Mendeley Data Monitor are shown below.
Instructions |
Screenshot |
|---|---|
| To enable Data Monitor as an import source, go to Administrator > Datasets > Import Sources. | 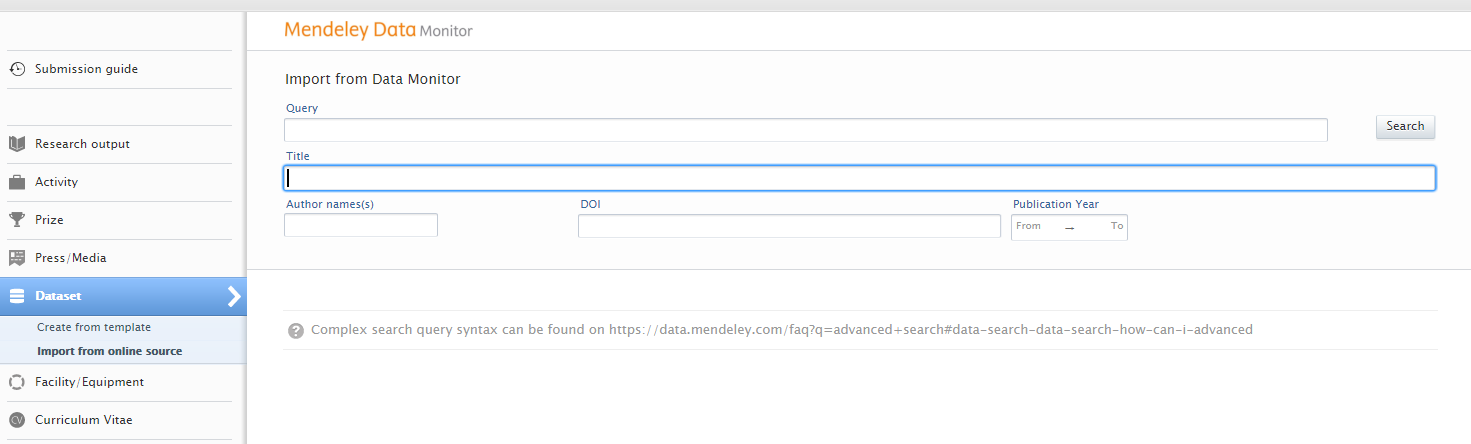 |
|
In the source configuration it is possible to insert the API key and a URL. It is possible to enable Mendeley Data Monitor as an import source with or without an API key. Available data sources can then be selected under Data Source Providers. Sources listed on the right will be excluded from the search. After setting the desired configuration, click Save. |
 |
| To search and import content, go to Editor > Dataset > Import from online sources and select Mendeley Data Monitor. | 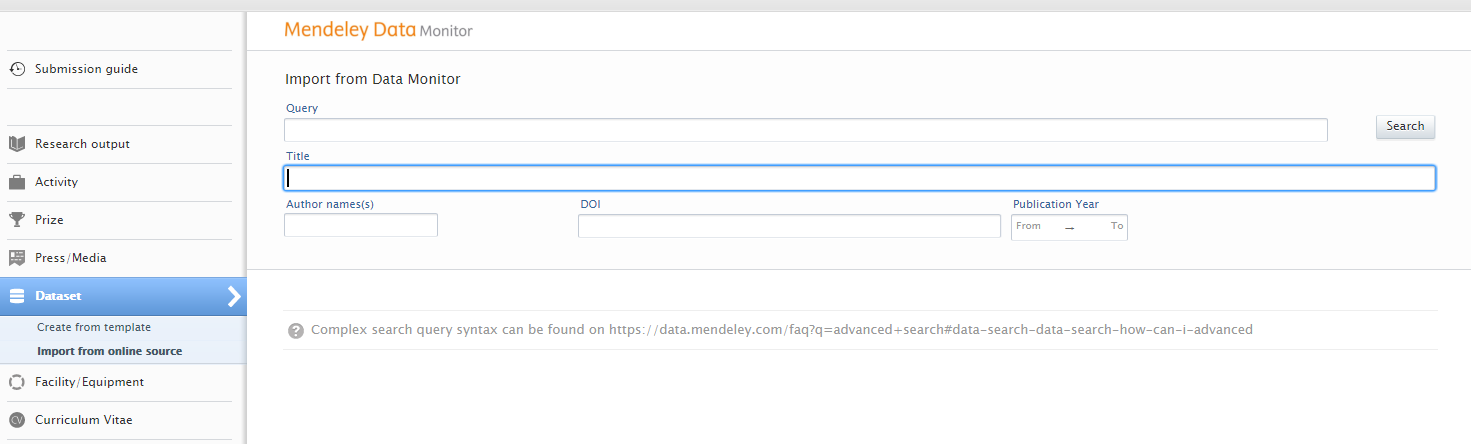 |
|
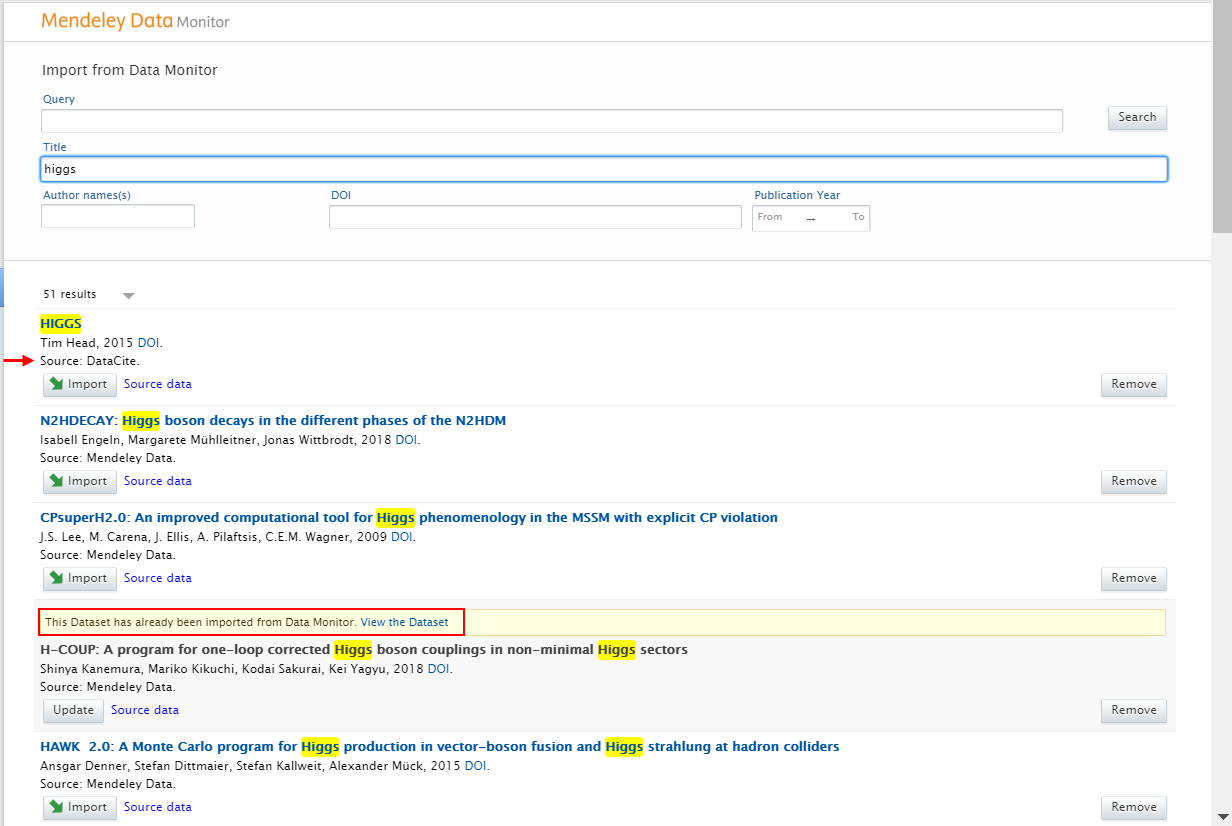
You can now search content using query text, title, author name(s), DOI, and/or publication year. You can also combine the values. For instance, if you are interested in content with a certain title and author from a specific year, then you can fill out all of the fields and do a combined search. The query field is a text field where you can type out your search criteria. You can find possible search queries here: https://data.mendeley.com/faq?q=advanced+search#data-search-data-search-how-can-i-advanced |
 |
|
Search results are presented as import candidates and can then be previewed and imported (or removed). Datasets that have previously been imported to Pure are shown as duplicates. The data source from which the dataset is being imported is shown for all import candidates. |
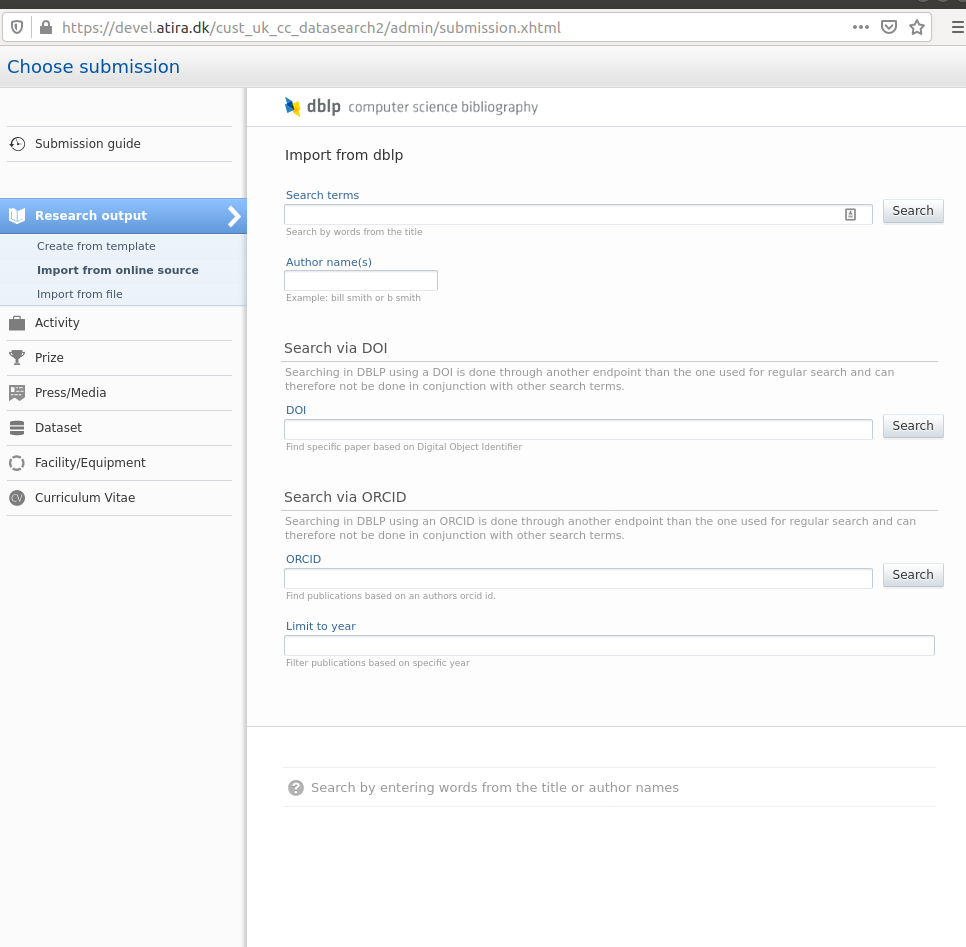 |
6.4. Enhancements to the DBLP integration
In this release, we have improved our integration with DBLP by expanding the search options and by adding DBLP as an import source for automatic updates.
Click here for more details...
It is now possible to search for content using DOI, or ORCID ID and publication year.
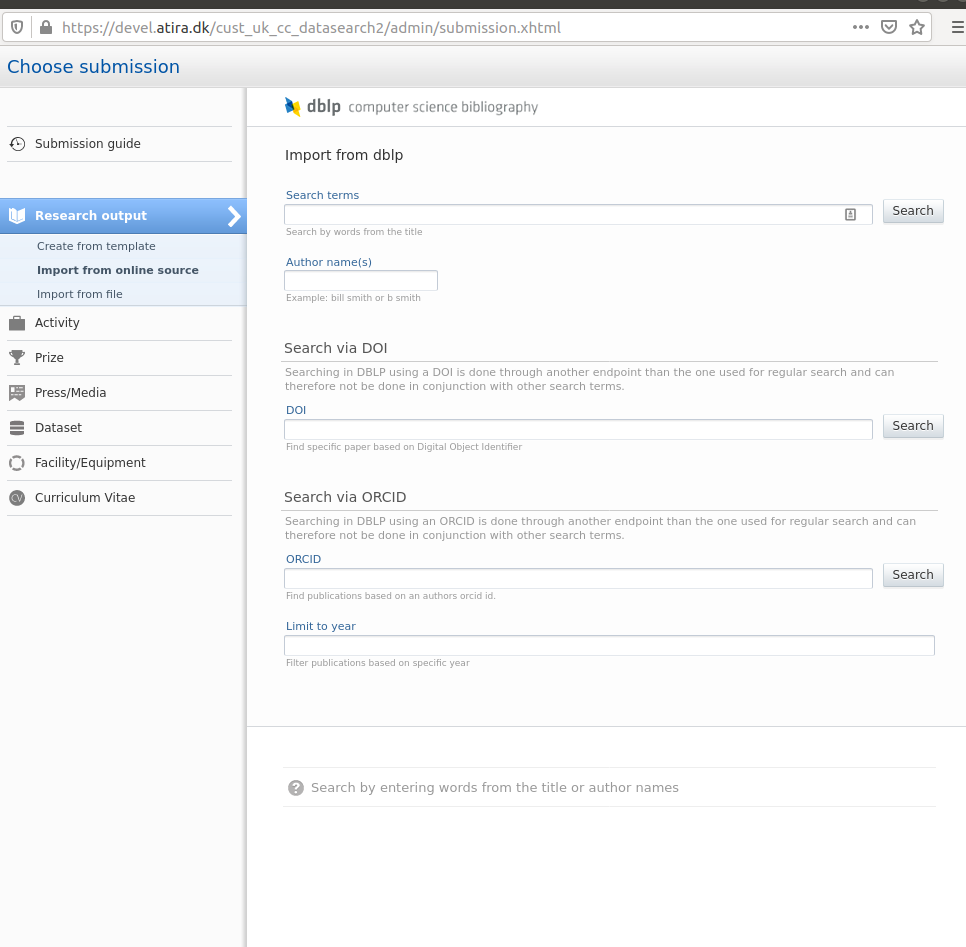
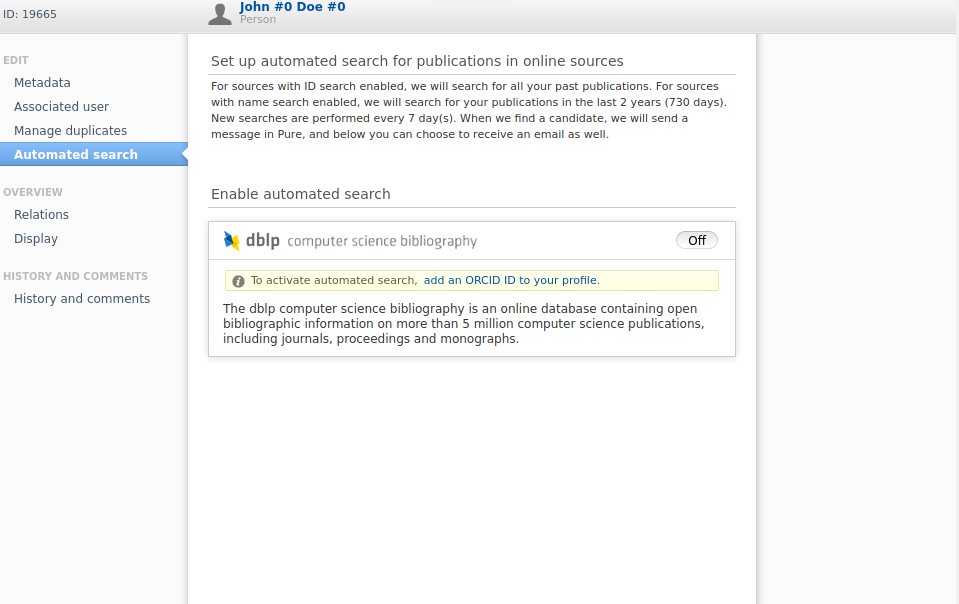
We have also added DBLP as an import source for automatic updates to existing content in Pure, via the record's DOI. It is also possible to enable the automated search on your personal profile using your ORCID ID.
It is now possible to search for content using DOI, or ORCID ID and publication year.
We have also added DBLP as an import source for automatic updates to existing content in Pure, via the record's DOI. It is also possible to enable the automated search on your personal profile using your ORCID ID.
6.5. Integration with Ciencia Vitae
We are happy to introduce the integration between Pure and CIÊNCIA VITAE for the generation of an academic CV in a standardized format. With this integration, researchers belonging to Portuguese institutions can create their CV in CIÊNCIA VITAE by exporting their data directly from Pure.
While with this release, it will be possible for researchers to export data related to their Activities and Research output, we are working on enabling additional content types (Awards, Projects) in the 5.20.1 release.
CIÊNCIA VITAE is the Portuguese national scientific curriculum management system (https://cienciavitae.pt/), and is a central element in the ecosystem of information management on scientific and technological activity as well as a tool to support the modernisation of the administrative processes supported by a CV. It aggregates in a single site the information currently dispersed in multiple platforms, in a simple, harmonised and structured way, respecting the specificities of the scientific areas and enshrining the principles of freedom and responsibility in the management and presentation of the curriculum. Developed and managed by the Foundation for Science and Technology (FCT), the CIÊNCIA VITAE platform uses import mechanisms and automatic completion of curricular data, ensuring the principle of re-use of information (introduce once, reuse multiple times), in direct association with Ciência ID. The development of the platform respects international best practices and regulations and is interoperable with several national and international systems and identifiers.
Click here for more details...
To allow the use, and creation of a CV, in CIENCIA VITAE, Administrators need to follow the instructions below.
Information |
Screenshot |
|---|---|
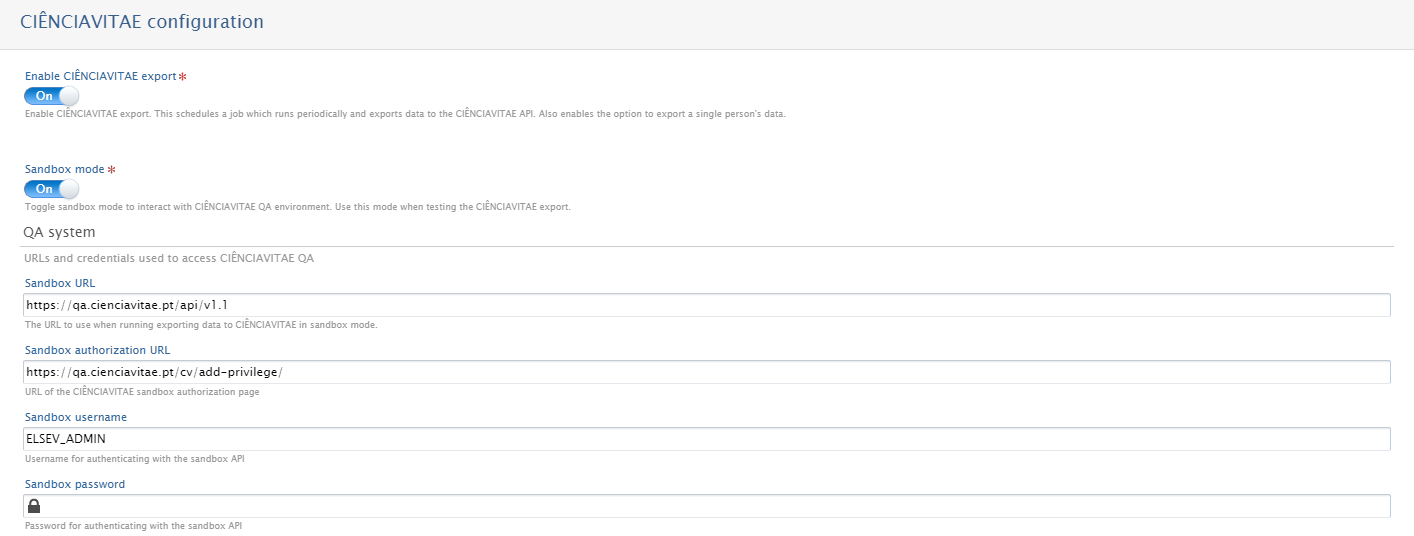
In Administrator > Curricula Vitae > CIENCIA VITAE Configuration, set up the CIENCIA VITAE configuration. Enable the export to CIENCIA VITAE, and fill in the URL, username, and API key required for authentication. |
 |
| A default mapping file is provided. If needed, it is possible to edit this file depending on your Institution's requirements. |  |
| Once the configuration has been saved, it is possible to export content to Ciencia Vitae from a personal profile. |  |
Once the data is exported it will be synchronized to CIENCIA VITAE and you will be able to create your CV there.
6.6. Clean-up Scopus IDs for research output
In this release we have introduced a new option as part of the Match Scopus IDs For Publications job in Pure. You can now check for, and add, the Scopus publication IDs of existing Research outputs in Pure. If this option is enabled, the job will scan existing records in Pure to check for and correct invalid Scopus IDs.
Click here for more details...
To enable this option in theMatch Scopus IDs For Publications job, go to Jobs > Cron Job cheduling and go to the Match Scopus IDs for Publications configuration page.
| In the job configuration select Edit configuration | 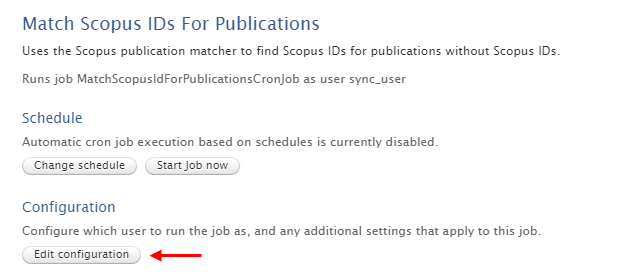 |
|
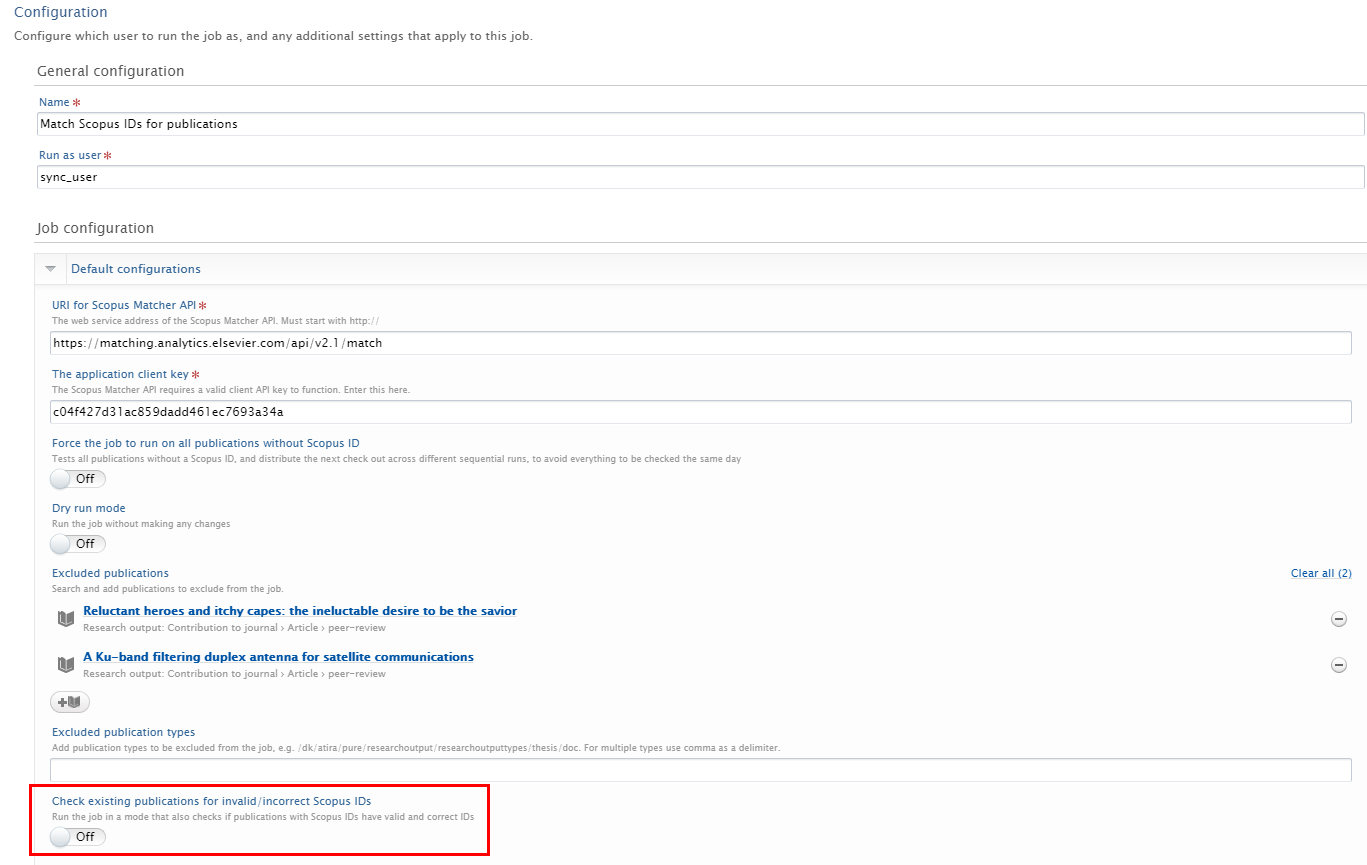
Select Default Configuration, then turn on the option to Check existing publications for invalid/incorrect Scopus IDs, and Save. This is not enabled by default. When the job is enabled, it is also possible to select publications to be excluded. |
 |
| The Matching rules configuration can be set such that matching logic only applies to specific fields, and a minimum number of matches across these fields. We suggest 2 matches with all fields enabled. Too high a number of required matches may result in valid Scopus IDs being removed. | 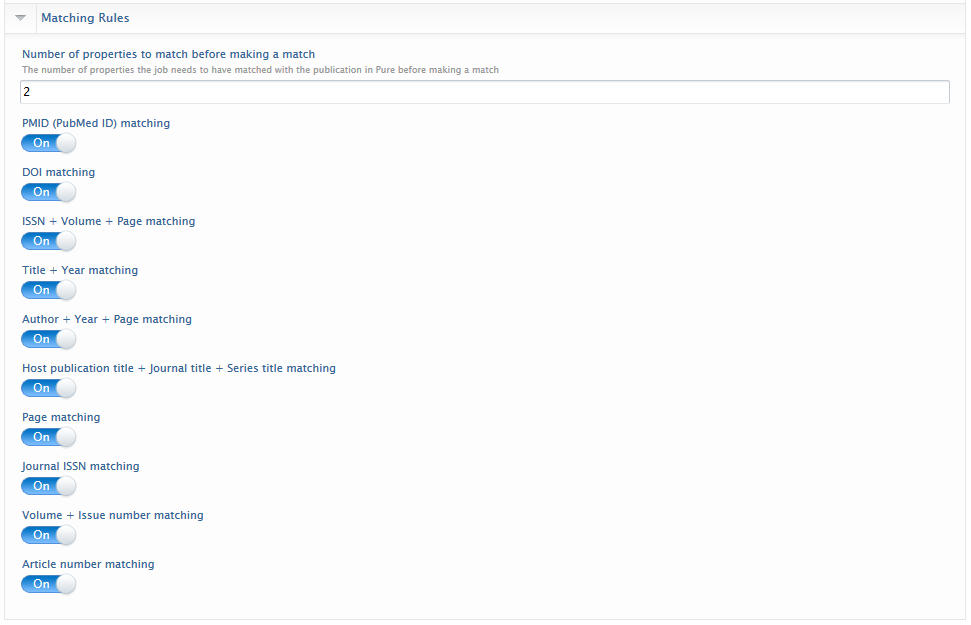 |
6.7. Import Grants awarded by the U.S. National Science Foundation (NSF) and the Russian Science Foundation (RSF)
In this release, we have enhanced our integration with Elsevier Funding Database, making it possible for institutions to import Awards from additional sources. The integration with Elsevier Funding Database was first introduced in release 5.18 of Pure. See here for its configuration details. There is no charge for this data source when used solely for your own institution's records.
This integration initially supported the import of Awards and Projects from NIH (https://www.nih.gov/). With this release, we have enabled import from two additional funders, the National Science Foundation (NHS: https://www.nsf.org/), and the Russian Foundation for Science (RFS: https://rscf.ru/en/).
| To enable the award synchronization from the Elsevier Funding Database go to Administrator > Jobs > Award Synchronization |  |
| Go to Edit Configuration, and in Data Provider enable Using FROS Awards Service | 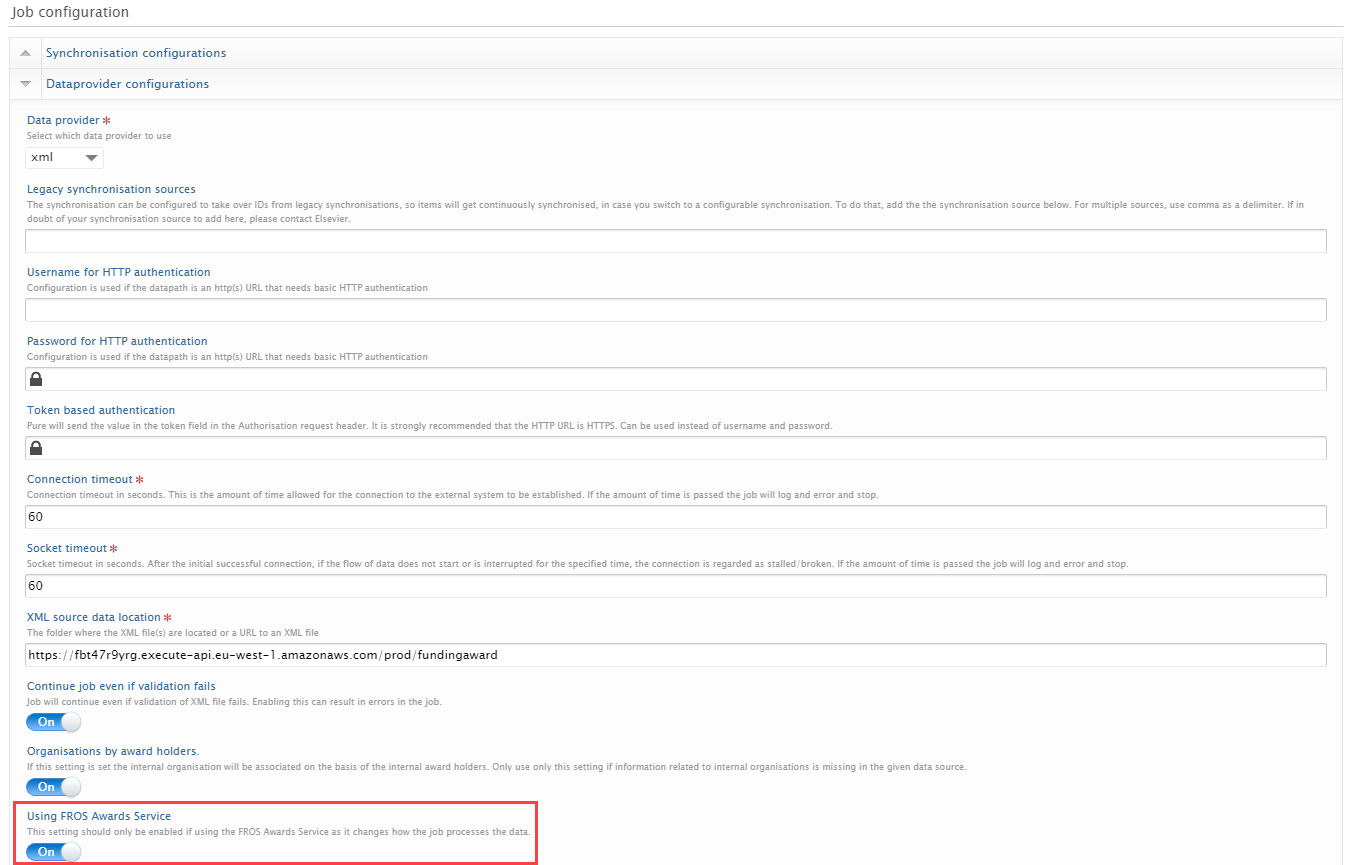 |
| It is also possible to select the funders from which you wish to import grants. Currently the NIH, NSF and RSF are supported. |
N.B. This job is set to run every 7 days by default, as data from the Elsevier Funding Database is updated once per week.
This work is ongoing and we will be making it possible to import from a wider range of funders in the next releases of Pure.
6.8. Fingerprint Extraction Tool
The fingerprint extraction tool allows you to extract concepts and concept weights for persons, organizations, research output, awards, and projects.
A step-by-step guide on how this tool functions can be found in the Fingerprint section of the Pure Client space..
Please contact pure-support@elsevier.com if you are interested in running this tool.
7. Unified Project Model and Award Management
7.1. Closed status on Award/Grant
In this release, we have introduced an additional fifth step in the workflow for Awards/Grants. A final step called Closed has been added. Only Administrators of Awards/Grants and global Administrators can move content to and edit it at this workflow step. This also includes completion of Milestones.
Note: We have not introduced any new roles and the logic of existing workflow steps remains the same.
Click here for more details...
Highlights |
Screenshots |
|---|---|
Workflow is still disabled by default for Awards/Grants. If workflow has been enabled in your Award Management Module, a new workflow step called Closed will now be available. You can enable or disable workflow for Awards/Grants under Administrator → Awards/Grants → Workflow step configuration When workflow is enabled, you can find a list of roles that can move the content to, and edit it at each workflow step (see screenshot). Administrator is never mentioned as global Administrator users always have permission to move content across workflow steps. |
|
|
When the content is in Validated workflow step:
|
|
|
When the content is moved to the new final workflow step (Closed):
An Award/Grant in the Closed workflow step should no longer need modifications. |
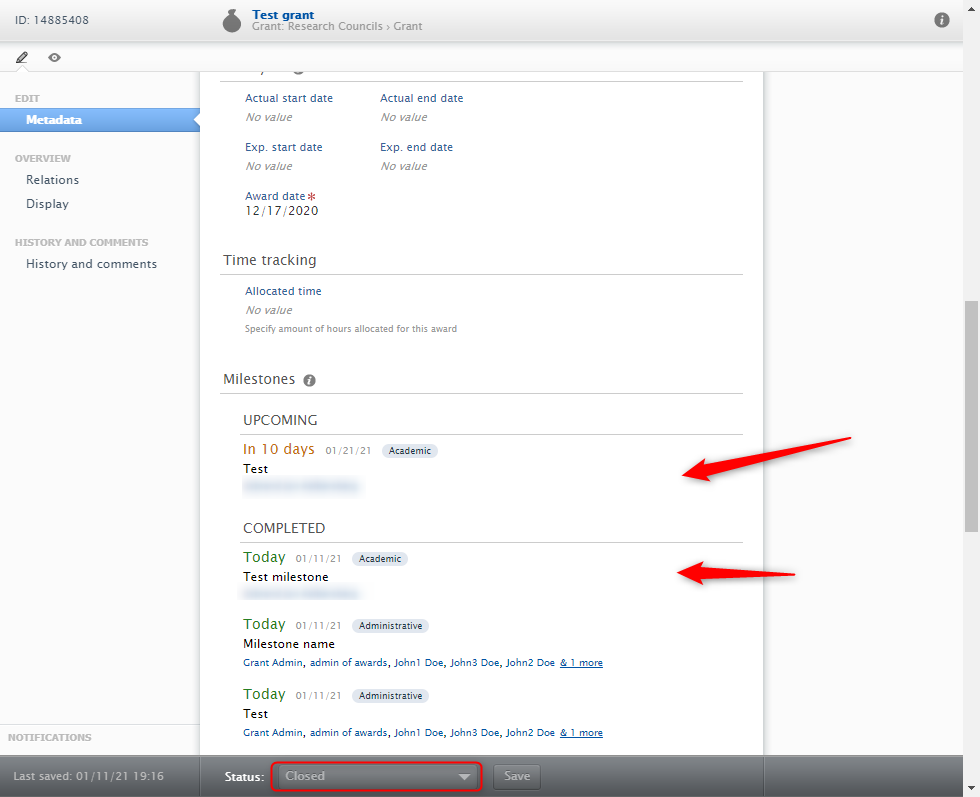 |
7.2. Multiple Applications on Awards/Grants - Successor and Predecessor enforcement
Up until now, only one Application could be related to an Award/Grant, either as its Predecessor or Successor. With this release, multiple Successor Applications are allowed for an Award/Grant, while Predecessors are still restricted to one.
This allows support for a continuous flow of Applications to Awards/Grants. Take the following example: an Application is created, and it results in an Award/Grant. Another Application follows from this Award/Grant - and can be associated with it as its Successor.
Previously, this was not possible.
To enable a two-way relationship, it is necessary to appropriately configure the Predecessor/Successor and the Successor/Predecessor settings on both Applications and Awards/Grants (see example below).
Click here for more details...
Description |
Screenshots |
|---|---|
|
To set up the Predecessor/Successor flow between the different content subtypes, first enable the functionality at Administrator > Unified Project Model > Enable configurable types. You will then be able to specify what Predecessors and Successors should be available for the Award/Grant, Application and Project subtypes (see below). |
 |
|
The following steps are an example of an Application to Award/Grant flow. 1. Initially, the Application type Proposal is set up to have a Successor relation to the Award/Grant type Grant |
|
|
2. Then, the Award/Grant type Grant is set up to allow Application types:
|
|
|
3. The Application type Additional Funding is set up so that:
Note: A similar flow should also be set up for the Application type Renewal, as it is also set up as a valid successor of Grant. We have now configured the following flow between Applications and Awards/Grants: Proposal (Application) > Grant (Award/Grant) > Additional Funding (Application) > Additional Funding (Award/Grant) Note: When a new Successor/Predecessor relation is set up, the corresponding Predecessor/Successor relationship is not automatically established but must instead be manually updated to properly reflect the intended flow. |
|
With the multiple Applications enabled in 5.20, the following scenario is also possible: 4. We can create a new Application based on an Award/Grant with a Proposal Predecessor. Previously, this option was not available when an Application was already associated with an Award as either its Predecessor or Successor. |
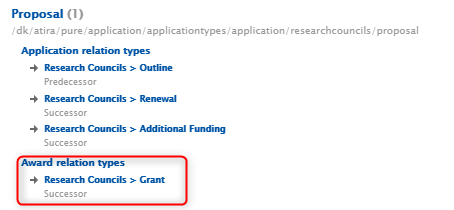 |
| 5. When creating a new Application based on an Award/Grant, you are given the option to select between Renewal and Additional Funding as these were the two configured Successor types. |  |
6. Even when a Successor Application already exists, it is still possible to add more Successor Applications. Note: While many Successors are allowed, the Predecessors are limited to one. In the example, it is impossible to add the Application called Application renewal 2 as a Predecessor, as this Application already has a Predecessor set as an Award/Grant. |
 |
Important notes
- If no Successor/Predecessor relationship has been set up for an Award/Grant type, then you can add any allowed relation to it. However, as soon as one rule has been added, the types that are allowed to be added as relations are limited in line with this rule. This is applied to the two content types forming the relation. This is to enforce a tight relationship between the Application and Award/Grant types in Pure.
- Project type relations are only enforced if a Project type relation is added. This means that all types of Projects can be linked to other content types by default. Once a relation type between a Project type and another content type is specified, it will be enforced in Pure.
- If the allowed types of relations are later altered, the existing relations will still be valid and recorded in Pure, but you will not be able to add them to new content. Instead, you will need to follow the altered logic when defining new relations.
7.3. Milestone improvements
Minor improvements have been made to:
- error messaging when creating new Milestones
- how Milestones with multiple responsible users are displayed.
As described in the section Closed status on Award/Grant of these release notes, Milestones can no longer be completed by Personal Users and Editors when the related Award/Grant is in the new workflow step Closed. At that point, they can only be completed by global Administrators and Administrators of Awards/Grants.
Click here for more details...
Description |
Screenshots |
|---|---|
When adding Milestones for which reminders (but no deadline) have been set, the following warning is shown. Note: This is the existing behaviour. |
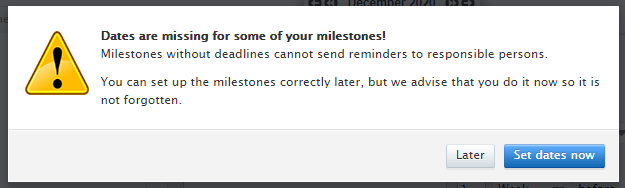 |
| The default behaviour is to have a reminder sent out one week before the deadline, so it is always advised to set up a deadline for the reminder functionality to work. | 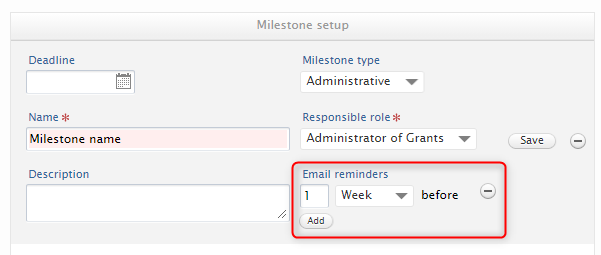 |
|
With the 5.20.0 release, the above behaviour has been updated so that you are no longer prompted to fill in the deadline when setting up a Milestone. This makes adding Milestones easier and accounts for cases when deadlines are not required/necessary. Instead, you can fill in the deadline and add an email reminder only when necessary. |
|
| The users responsible for a given Milestone are shown in the Award/Grant editor. If more than five users are responsible, only the first five will be shown, with an option to expand the list. | 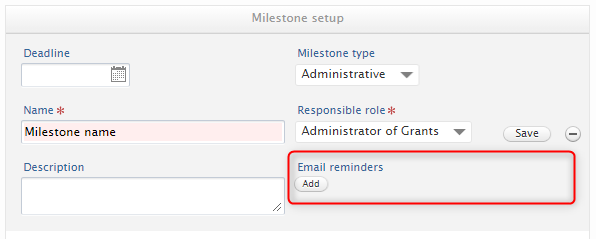 |
8. Pure Portal
8.1. Custom keyword filter groups
We are really excited about our latest big update to the filtering functionality in the Pure Portal. We are now giving you the power to create your own custom filters based on criteria of your choosing! Any structured keyword group you create in Pure can now be converted into a ready-made Portal filter, allowing you to highlight most relevant content (for example, SDGs) and further customize your users’ search experience based on your institution's specific profile.
 |
 |
 |
Click here for more details...
You can now use any structured keyword group in Pure as the basis for a custom Pure Portal filter group. This means that you can base a filter on a keyword group already existing in your Pure, or you can create an entirely new one just for this purpose. Naturally, a new keyword group would require you to tag relevant content.
To convert a keyword group to a custom Pure Portal filter group, first go to Administrator > Keywords and locate the keyword group you want to use in your Pure Portal. They are organized based on the content types to which they relate.
Note: In the case of SDG keywords, a group has been created for you on both Persons and Research Outputs with this release. It can be populated manually, or automatically via the SDG keywords job.
Edit the keyword group you want to use. This will open the keyword group editor window. The Name field will be used as the heading for your filter, so adjust this as required.
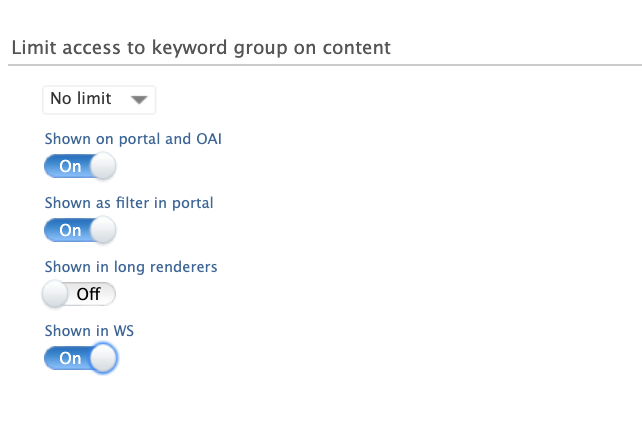
Then, go to the Limit access to keyword group on content section at the bottom of the editor, enable both Show on portal and OAI and Show as filter on portal, and Save your settings.
Once you have done this, and after the Portal takes a moment or two to update, your new filter will be available on the Portal:
While there is no difference in how they look, custom filters will always display above all generic filters on the Portal. They use the same behaviour as most other filters. If a user selects multiple options within one custom keyword filter, then 'OR' logic is applied. If you add multiple custom filter groups, 'AND' logic is applied between the terms of each of the separate filter groups.
Note: Only structured keyword groups can be converted to Portal filters. Free text keyword groups can be shown on the Portal but not added as filter.
8.2. Displaying Other files attachment type on Pure Portal Research output pages
When adding a file to a Research output in Pure, you have 3 options: Electronic version, Other links and Other files. In earlier versions of Pure, only the first two types were displayed on the Portal. With 5.20, files categorised as Other files can now also be displayed on the Pure Portal.
Click here for more details...
Background to Research output attachment types in Pure and the Pure Portal
We have two basic types of attachments that can be added for Research outputs in Pure.
The first type is an Electronic version. This type is designed for adding full-text of the publication. The electronic version can be added in 3 ways:
- adding the file itself
- adding a DOI (which will point to the full-text)
- adding a link (which will point to the full text).
In all the above cases, the link to the Research output can be shown in the Portal.
The second type is divided into two sub-types: Additional links and Additional files. Here, you can add a link or a file that has something to do with the article. This could be, for instance, a link to the conference where you presented the paper, or it could be a file that contains the interview you based you article on, or it could be a file that has information on something relevant for you publication - but not the actual full-text of the article.
While the additional links have always displayed, we have not always displayed the additional files on Portals. Now, it is possible for your institution to decide whether to display the additional files on Pure Portal.
Global configuration to display Research output files and links on the Portal
We have added new global configurations for file and link display on the Portal. Other link will be enabled by default while other files will not be enabled by default. This is done to have the exact same behaviour as we had before this update. Visibility settings for restricted or embargoed documents can also still be overridden for specific documents (see next section):
Enabling the display of Other files on the Pure Portal
The process of adding Other files to Research outputs in Pure remains the same: if you open or create a Research output in the Pure Editor, you can add the file along with its name (this will then be the display name shown on the Portal), and any embargo or license details. This is also the same as for the two other types of file/link attachments. Embargoed files will only be accessible after the end of embargo period.
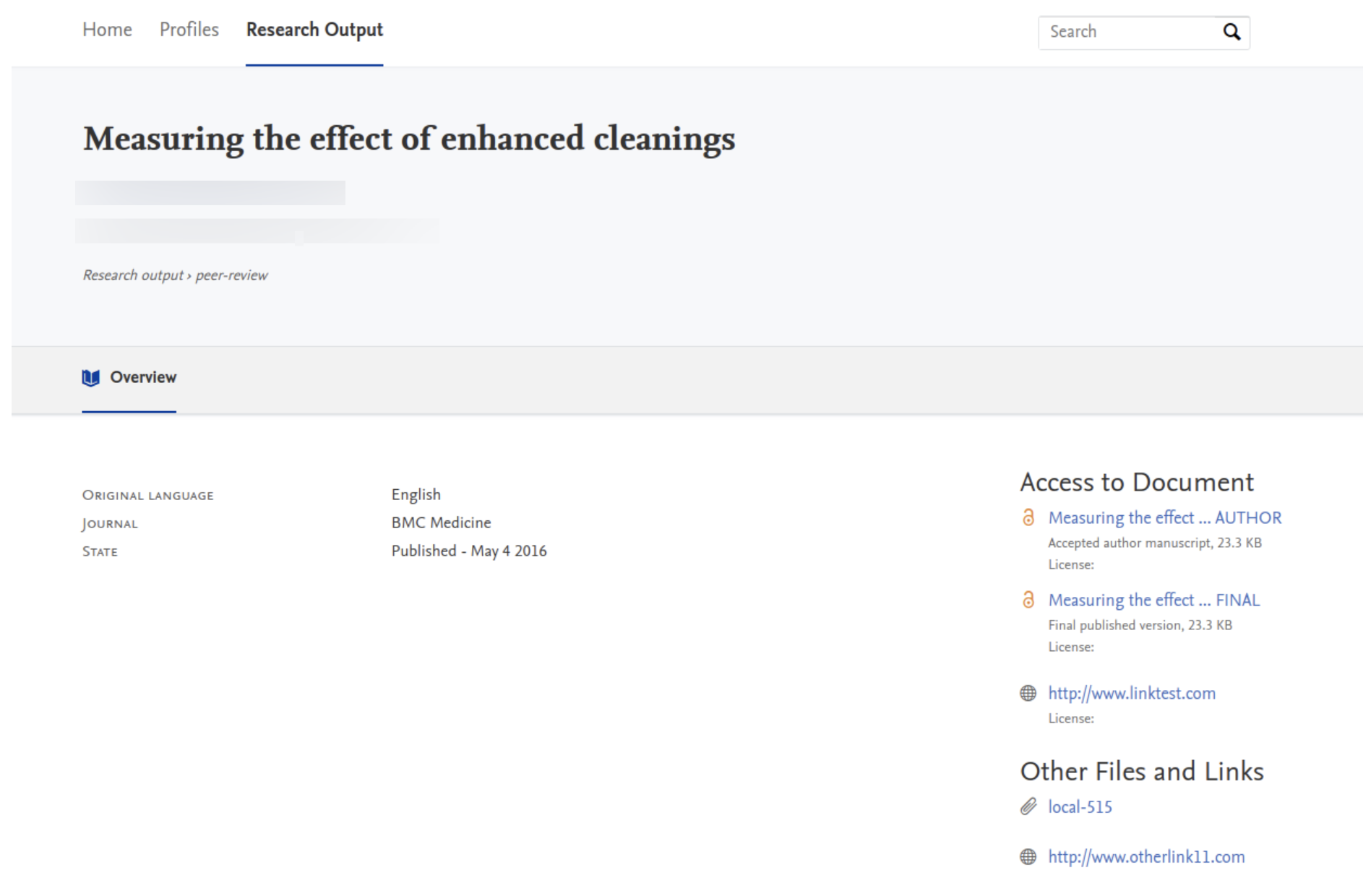
Pure Portal display
We have taken this opportunity to reorganize the display of files and links on the right-hand side of the Pure Portal Research output page. There are now two clear sections: one for access to electronic versions of the document, and one for other associated files and links:
8.3. Similar profiles improvements
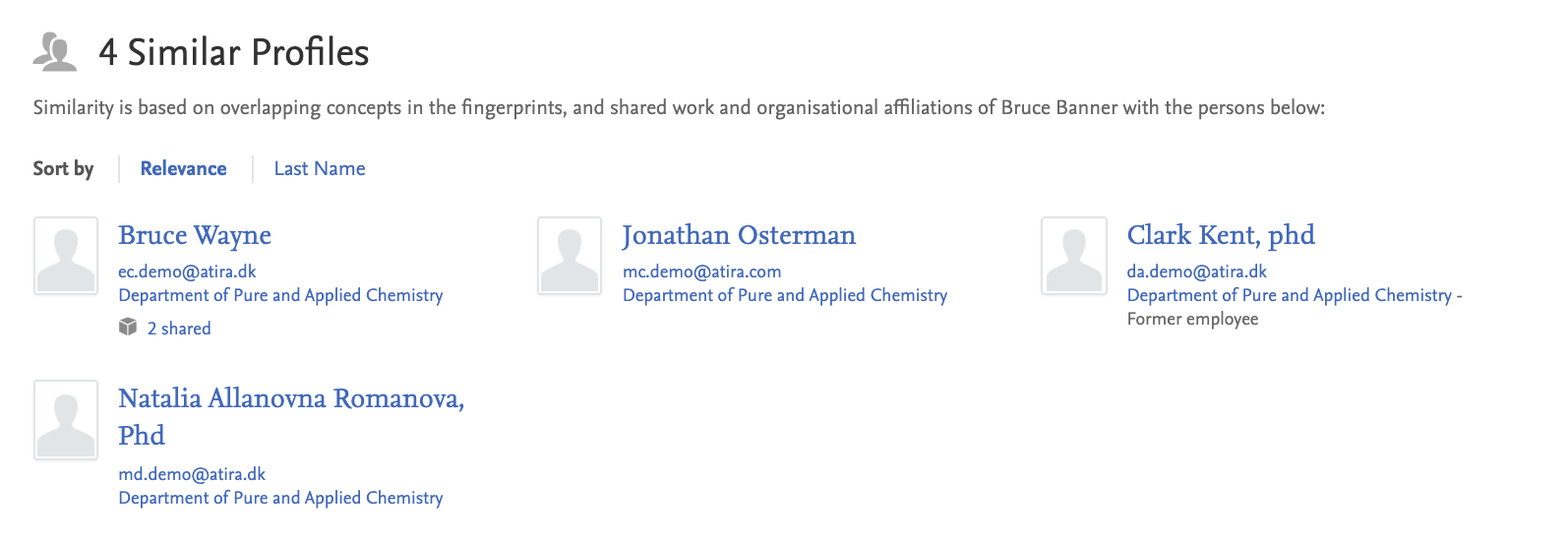
The Pure Portal is a great way for visitors worldwide to find experts in a given field. Once you have made your search and found an expert matching your criteria, you can explore the profiles of other experts who match your search in the Similar profiles tab on Profile pages.
In this release, we have made extensive changes to the algorithm that generates these recommendations. These changes mean we are using more data points to find matches, ensuring we are more consistently providing a useful number of high-quality matches. On our test datasets, this translated to increasing the percentage of profiles where we can show 3 or more matches from 28% to 99%.
Click here for more details...
An explanation of the improved matching logic:
- The initial basis remains the similarity of fingerprints, however in cases where this is returning few or no results, we have supplemented this with additional data based on the person's network.
Finding similar profiles is done by looking at a maximum of 5 criteria, in the following priority order:
- Using the existing fingerprint similarity algorithm.
- Shared projects, sorted from most to least.
- Shared outputs, sorted from most to least.
- Persons directly sharing organisations, sorted from highest citation count to lowest.
- We aim for a minimum of 6 and have set a maximum of 12 similar profiles for each profile.
- The algorithm works down the criteria list in order.
- If the person already has at least 6 similar profiles based off the fingerprint similarity algorithm, no further criteria are used, and these are their similar profiles, up to a maximum of 12, based off closest match.
- If the threshold of 6 is not reached, we move through the remaining criteria, in priority order.
- If at any point the minimum threshold of 6 persons is reached, we stop at this step.
Please let us know what you think of the new matching algorithm. We are already thinking of new data points we can use, and your feedback will help us prioritise further optimizations.
8.4. Cookie consent
For this release, we have completely reworked the way in which the Portal manages cookie consent for visitors to the Portal. When you first arrive on the Portal, a large banner is shown at the bottom of the page, requesting explicit consent for the Portal to store cookies to manage tracking and performance. From here visitors can accept cookie usage, or manage which types of cookies they consent to us using.
We now ensure our Portals do not place any cookies or other tracking technologies before your user has given consent. This change brings us into full compliance with both the EU's ePrivacy Directive (the “cookie law”) and the General Data Protection Regulation (GDPR).
Note: The option to decline tracking cookies, and that they must be actively opted-into, per EU law, means that your portal will likely see a drop in recorded traffic from this release onwards. This does not mean that less visitors are coming to your Portal, just that now not all of these visits will be recorded. This unfortunately cannot be helped, and is an accepted consequence of compliance with the law. This impacts all website providers the same.
Click here for more details...
The first time a user visits a Pure Portal, they are greeted with the banner shown in the screenshot above. If they chose to Accept all cookies, the banner collapses and they can continue their visit. A further cookie is used to save this preference, so the user will not see the banner again, unless they clear their cookies or use a new (or incognito) browser.
Alternatively, the user can select Cookie settings and adjust their cookie preferences. On selecting this option, they will be shown the Cookie Preference Center:
Here, they can decide which category of cookie to allow and which to disable. Note: It is not possible to disable Strictly necessary cookies.
You can also get more details on the cookies we are using per category:
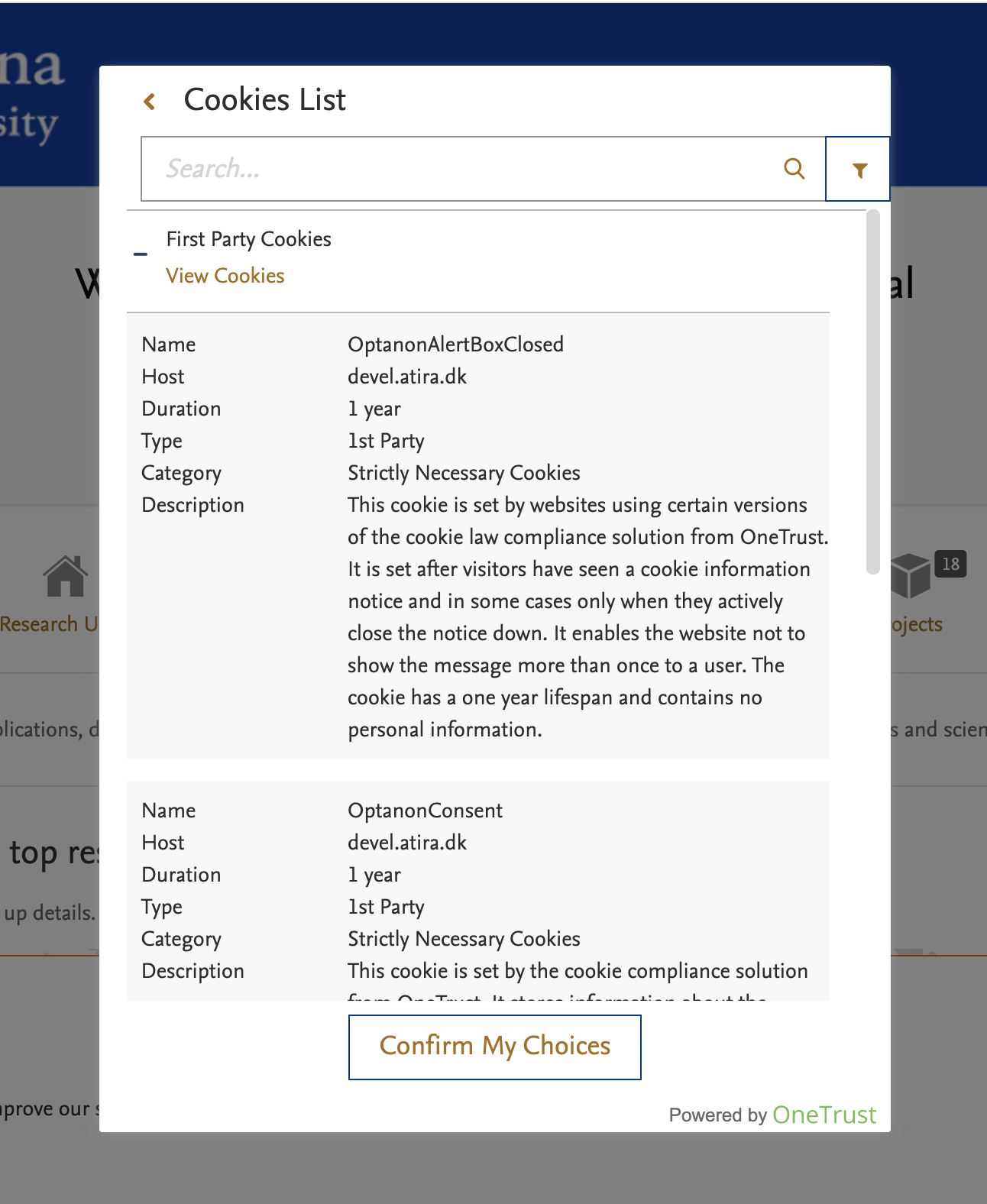
It is also possible to access the Preference Center at any time by clicking Cookie Settings in the footer of the Portal. Note: This does not clear the cookies already stored. If you wish to remove these cookies, you need to do this via your internet browser settings.
8.5. More flexible homepage Welcome text
In another seemingly small but highly in demand change, we have added more flexibility to the homepage Welcome message. Previously, the text was hard-coded to always show the message "Welcome to [Client/University Name]". Now, you can use the field to show whatever message you wish.
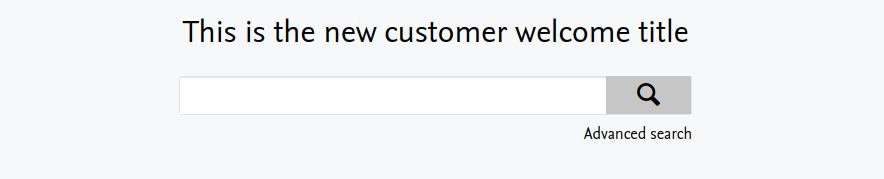
Click here for more details...
The configuration field for the homepage Welcome message can be found at Pure > Administrator > Pure Portal > Portal > Styling & layout. This new field has been pre-populated to show the full default text string that is used:

The big change is that this is now fully editable. Simply change the message to show exactly what you want displayed and save your changes. This will be used as the front page welcome title and replaces how the front page welcome title was generated before ("Welcome to [CustomerName]"):

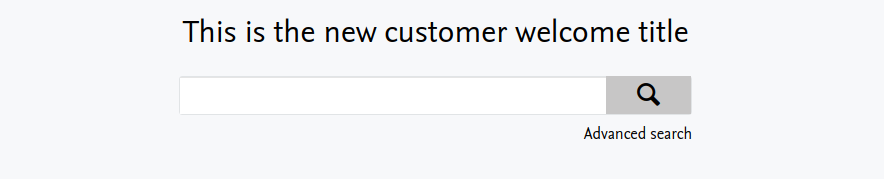
Note: When updating to the latest Pure version, the customer welcome title field will automatically be populated with "Welcome to [CustomerName]". If you have in any way modified your text resource file here, it will revert back to the original message and will need to be changed back via the steps above.
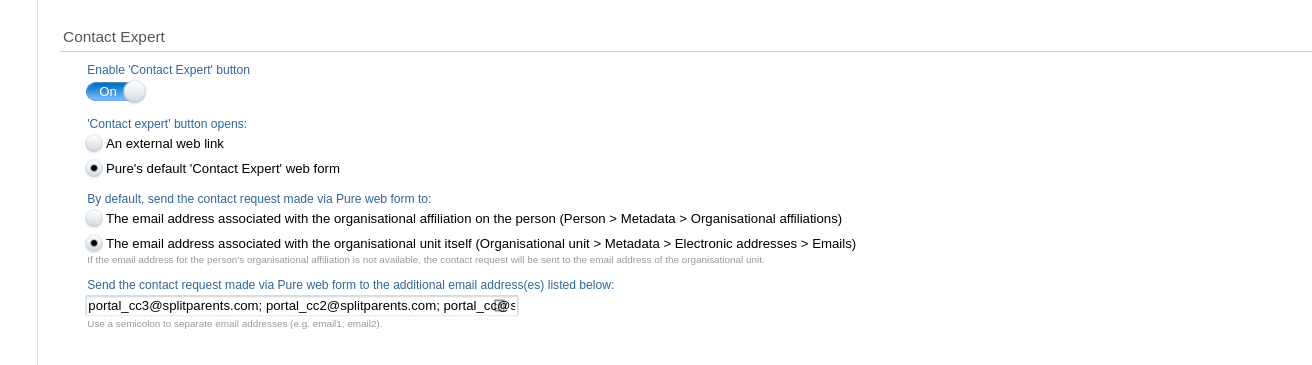
8.6. Contact Expert improvements - Additional CC's on contact requests + switch of CAPTCHA provider
We have made two small changes to our Contact Experts feature. The first is an improvement to allow you to add multiple copy addresses on incoming mails. The second is a switch of the CAPTCHA provider we use for authentication on messages as protection from spam bots.
Click here for more details...
Additional CC's on Contact Expert requests
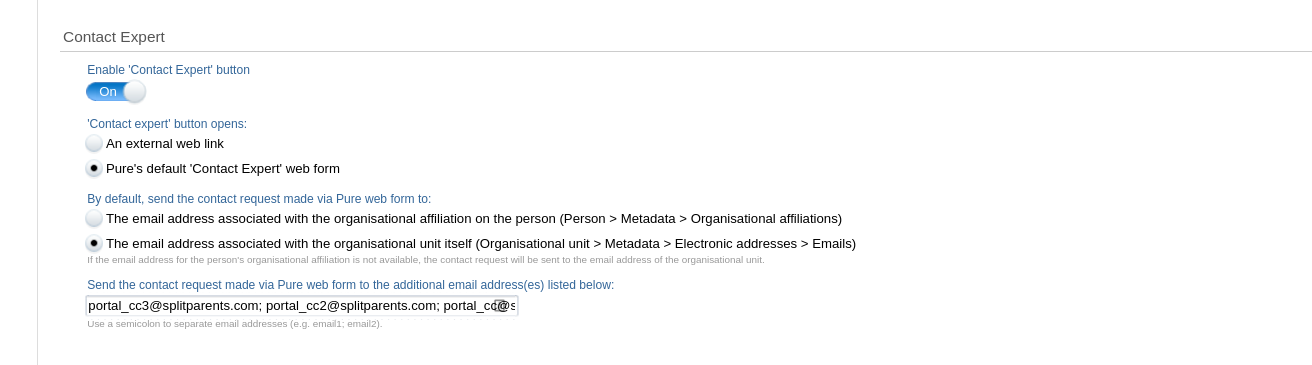
Previously, we only allowed one CC email address on incoming contact expert mails We have had a few requests from clients to increase this so that more persons can be notified and copied on the contact requests coming in so that these can be more reliably tracked and monitored.
We have taken this feedback on board, and now multiple addresses are supported.
Adding in additional CC addresses couldn’t be simpler. Just add all addresses you wish to be copied on for incoming contact emails, separating each out with a semicolon (‘;’):
Replacing reCAPTCHA with hCaptcha
We recently migrated the CAPTCHA provider we use for Contact Expert requests from Google's reCAPTCHA to a service provided by the independent hCaptcha.
A CAPTCHA is a type of challenge–response test used in computing to determine whether or not the user is human. We are excited about this change because it helps address a privacy concern inherent to relying on a Google service that we have had for some time. We also have issues in some regions, such as China, where Google's services are intermittently blocked. We evaluated a number of CAPTCHA vendors and considered an in-house solution as well. In the end, hCaptcha emerged as the best alternative to reCAPTCHA.
Further benefits of switching to hCaptcha from to reCAPTCHA include:
- hCaptcha do not sell personal data; they collect only minimum necessary personal data, they are transparent in describing the information they collect and how they use and/or disclose it
- It gives us more flexibility to customize the CAPTCHAs we show
- Campared with reCAPTCHA, their performance was as good as or better in testing
- hCaptcha has a robust solution for visually impaired and other users with accessibility challenges
9. Reporting
9.1. Reporting on Open access
With this release, we have added more values and filters on Open Access and APC . This will make it possible to create reports on Research outputs and their Open Access status, embargo date, APC information, and more.
We are currently working on providing standard reports that make use of the new values and filters. We hope to make these available with the 5.20.1 release so please an eye on the future release notes.
Click here for more details...
Accordion Body
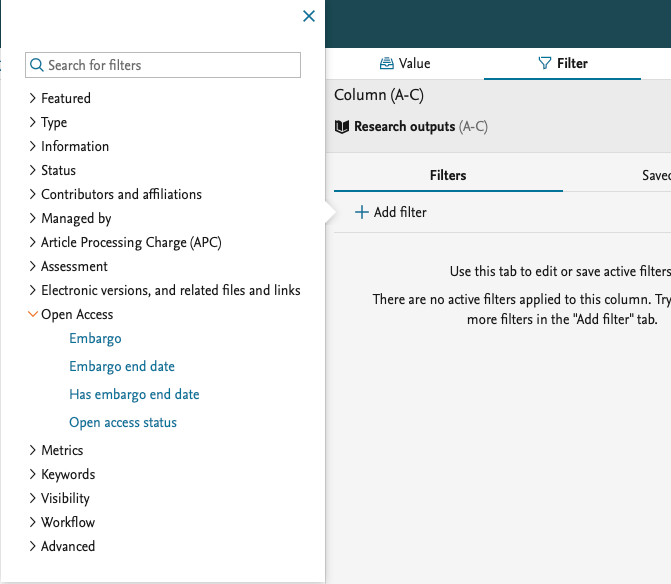
We have added more filters on Open Access. Use these to limit the content you want to include in your report.
These are filters on the open access status of the research output.
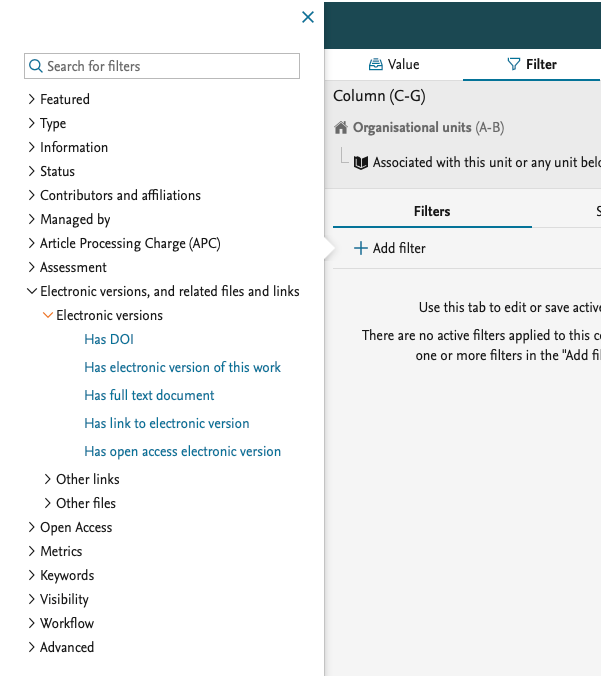
We have also added more filters on the electronic versions on the Research output, which allow you to limit the report to content that has an Open Access document added.
We have added more values that can be used to create the data you need for your report. You can now project the 'Embargo end date' and the overall 'Open Access status' of the Research output.
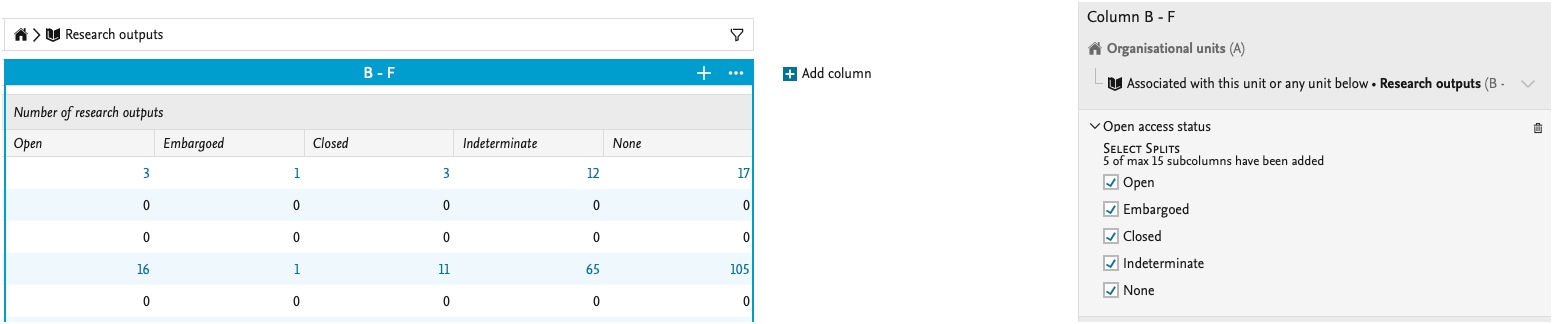
We have updated the ability to split data by Open Access status:
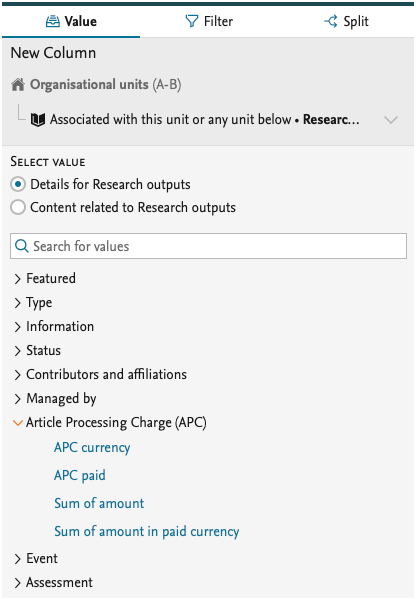
We have also added more values for the APC part of the Research output. You can now add information to the data table on the APC currency, whether the charge has been paid, and include the actual sum both in paid currency and Pure's default currency.
Published at December 04, 2023