
How Can We Help?
5.22.05.22.0
Highlights of this release
![]() Data Quality
Data Quality
The new Data Quality interface provides a central location for all cleaning operations for all content types within Pure. The first content type to be available in the new interface is External Organization. External Organization data can now be cleaned more efficiently and easily with functionalities to merge, set hierarchy and mark as distinct all available in one place. The interface is only available to users with permissions to access the current deduplication functionality on the External Organization content type overview.
 Funding Database
Funding Database
In this release, we have expanded functionality around Awards and Projects in Pure and added these content types for self-import of data to Pure. The expanded functionality makes it possible for Administrators to synchronize Awards and Projects related to their institution directly into Pure, and for Personal Users to search for and import Awards and Projects from specific funders. New configurations have been added to manage the flow of award/project data into Pure, such as creating a whitelist of funders that will be searchable or synchronized, features to manage de-duplication and updates, and the automated assignment of content sub-types and classifications.
The Funding Database has also been added as an import source, giving Pure users access to over one million awarded grants and projects from more than 700 funders worldwide. This integration makes it possible to automatically synchronize awarded grants and projects from 277 funding agencies (from 87 funders). Additionally, it is possible to manually search for and import awarded grants and projectsfrom 700+ funders.
This recent development is in line with our ongoing work in Pure to bring together the different parts of the research cycle, facilitating the discovery, import and linking of different content types.
 Citation formats in Reporting
Citation formats in Reporting
It is now possible to use citation formats for Research Outputs in the new Reporting module. You can now select from the various citation formats that Pure supports for Research Output, and view the list of Research Outputs in your chosen format, for instance APA or Vancouver. The formats can also be used when exporting to either Excel or CSV.
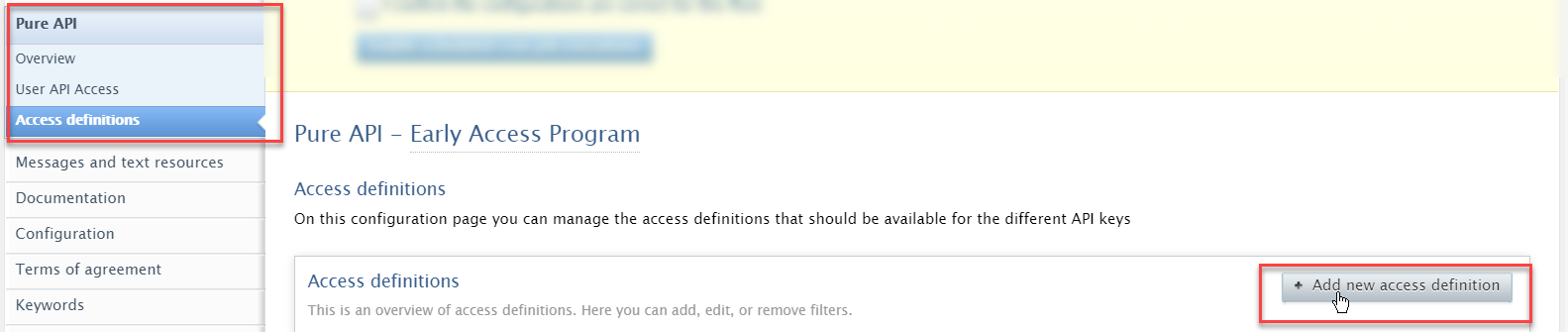
 Content and field filtering available in Pure API
Content and field filtering available in Pure API
Pure API now allows to configure access definitions to give greater control of what content is available to what API key, and what metadata is exposed for the different API types. You now also have control of whether an API key grants write permissions or only read permissions, providing much greater control of what data is made available to whom.
Watch the 5.22 New & Noteworthy seminar
PARTICULAR ITEMS TO NOTE WITH THIS RELEASE
Upgrade to 5.20.3 / 5.21.0 required prior to upgrade to 5.22.0
- In order to install the 5.22.0 release, you must first upgrade to either 5.20.3 or 5.21.0.
- The upgrade to 5.22.0 will fail if either 5.20.3 or 5.21.0 was not already installed.
- We have had to introduce this requirement to ensure the cleanup of deprecated modules is complete.
We are pleased to announce that version 5.22.0 (4.41.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 4 Oct 2021
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 6 Oct 2021 (APAC + Europe) and 7 Oct 2021 (North/South America).
- Production environments (including hosted Pure Portal) will be updated 20 Oct 2021 (APAC + Europe) and 21 Oct 2021 (North/South America).
Advance Notice
For the next major release, we will migrate the Pure code base to Java 11. This means that on-premise customers should plan for installation of Java 11 and Tomcat 9 when deploying the 5.23 release in February 2022.
Download the Release Notes
last updated 4 Oct 2021
1. Web accessibility
We continue to work towards being fully WCAG 2.1 AA compliant by ensuring accessible design in new features. In addition to this, we implemented the following improvements to existing features:
1.1. Pure Portal accessibility updates
To date, we introduced a number of accessibility features and improvements that have made us level AA (and, in some cases, level AAA) compliant. However, like painting the proverbial Forth Bridge, ensuring optimal accessibility is a job that is continuous and never truly complete. 5.22.0 brings improvements to a number of specific accessibility areas.
The improvements introduced meet the following success criteria listed in Web Content Accessibility Guidelines (WCAG) version 2.1:
Click here for more details…
WCAG 2.1 success criterion |
Improvement in Pure Portal |
|---|---|
| 1.4.1 Use of color (A) | Previously, we indicated that text is hyperlinked only with contrasting color (blue). Links are now additionally underlined to make them stand out even more. |
| 1.4.3 Color contrast (AA) | We have increased contrast between the background and the text in input fields, such as the Portal search bar. |
| 1.4.13 Content on hover and focus (AA) | Before, some of our on-hover tooltips would disappear if you hovered your mouse over to the pop-up text. We now allow you to hover and mark the text in the pop-up. |
| 3.4.2 Focus order (A) | Tab order is now more logical: we have removed areas where focus would automatically be moved to certain elements on the page upon clicking a button. This would happen on a canvas graph (e.g. Projects per year). We also removed tab indexes on elements that shouldn't have them. |
| 2.4.7 Focus visible (AA) | The focus (press TAB) was sometimes difficult to find depending on the background color. This has been changed so that the focus ring is a lot more visible. |
| 1.3.1 Information and relationships (A) | Use of headings to appropriately structure content: we had a navigation landmark in the footer which was not indented and could cause a bit of confusion among screen reader users. This has been improved. |
| 4.1.2 Name, role, value (A) | UI components communicate their state programmatically: we have added aria-expanded attribute to organisation hierarchy buttons and removed a radiogroup on our advanced search page. We also added labels to our collaboration map pop-up. |
2. Privacy and personal data
The protection of privacy and personal data is extremely important to Pure. Based on guidance provided by GDPR (and similar frameworks), we continually add improvements to how Pure handles sensitive data, and we continually provide tools for users to manage their own and others' data in Pure. This release does not introduce any new updates related to privacy and personal data.
3. Pure Core: Administration
3.1. Data Quality: new and improved External Organization cleaning interface
The new Data Quality interface will provide a central location for all cleaning operations for all content types within Pure. The first content type to be available in the new interface is External Organization. External Organization data can now be cleaned more efficiently and easily with options to merge, set hierarchy, and mark as distinct, all available in one place. The interface is only available to users with permissions to access the current deduplication functionality on the External Organization content type overview. More content types will be available in the Data Quality interface with each subsequent release.
The new interface builds on Pure's 5Cs of data quality (Complete, Correct, Connected, Current and Compliant) and focuses on cleaning and supplementing data. Within the External Organizations interface, users can deduplicate, set hierarchies and set organizations distinct from specific, or all, organizations.
Note: To display results in the interface, External Organization data in Pure will need to be indexed on upgrade to 5.22.0, and the new Duplicate External Organization Discovery job will need to be configured, enabled, and run. Note: The job has been renamed in 5.23.0 to a more generic Duplicate Content Discovery, to accommodate the inclusion of more content types in the future.
Interface overview
Accessing the interface
| The new interface is available to all users who have access to the current duplicate handling functionality. It is accessible via the Data Quality tab. |  |
The interface is composed of three primary sections:
- Group list
- Entity list
- Results preview
Information |
Screenshot |
|---|---|
|
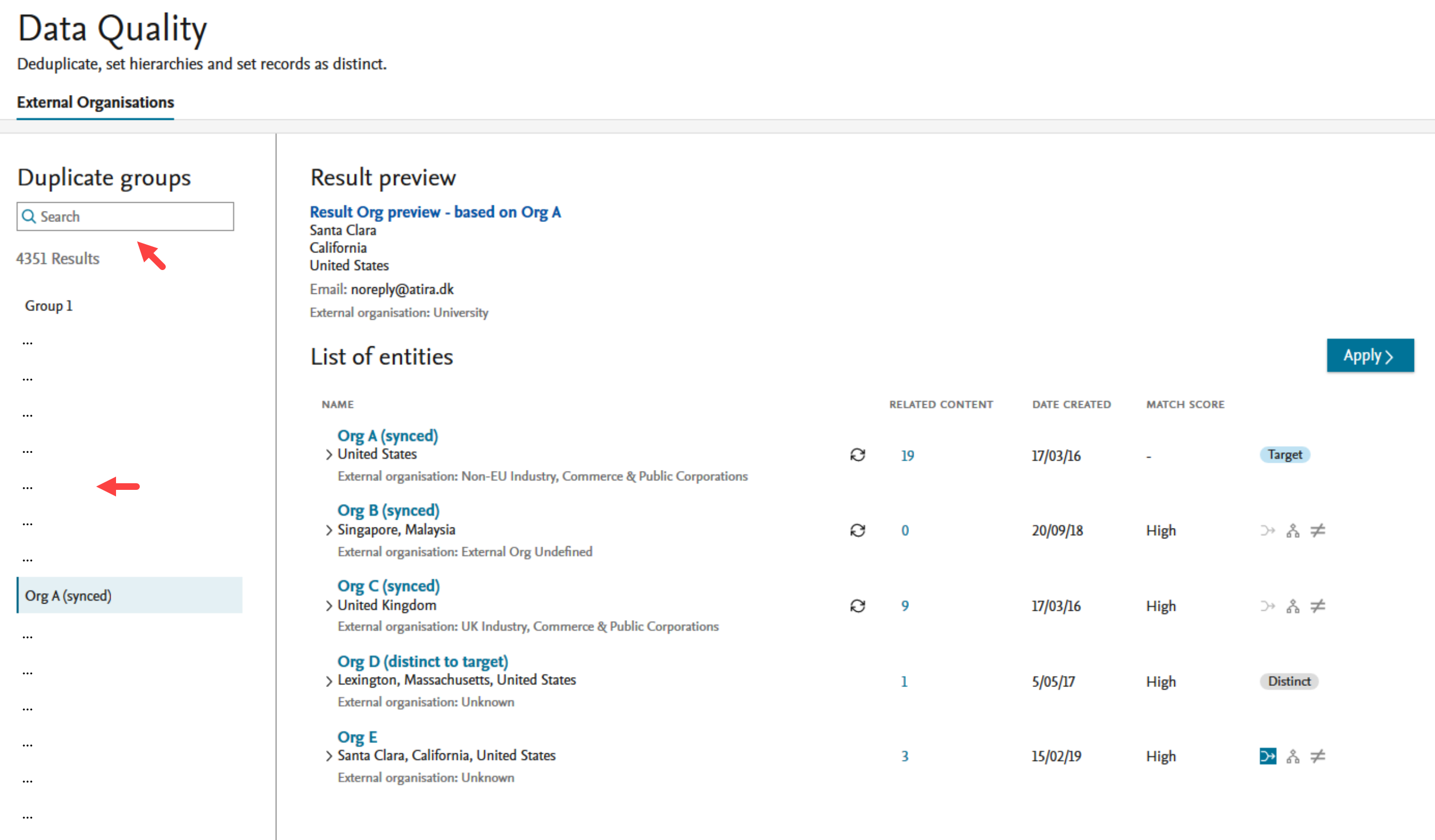
Group list The section on the left, Duplicate groups, lists groups of organizations. Organizations with high degrees of similarity between names, alternative names or IDs, are clustered together. Users can search for specific organization within these groups, and groups are ordered alphabetically. |
 |
|
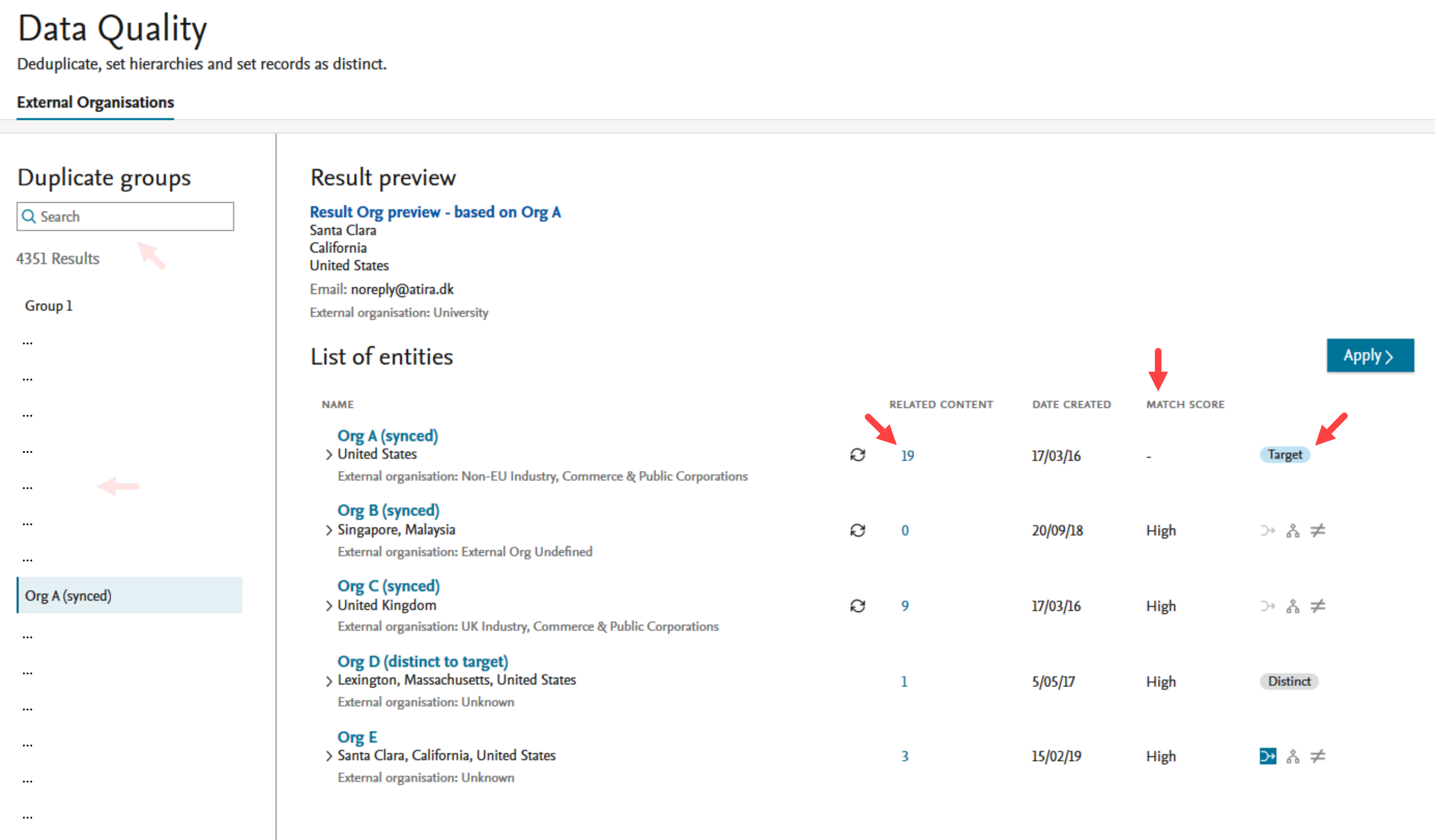
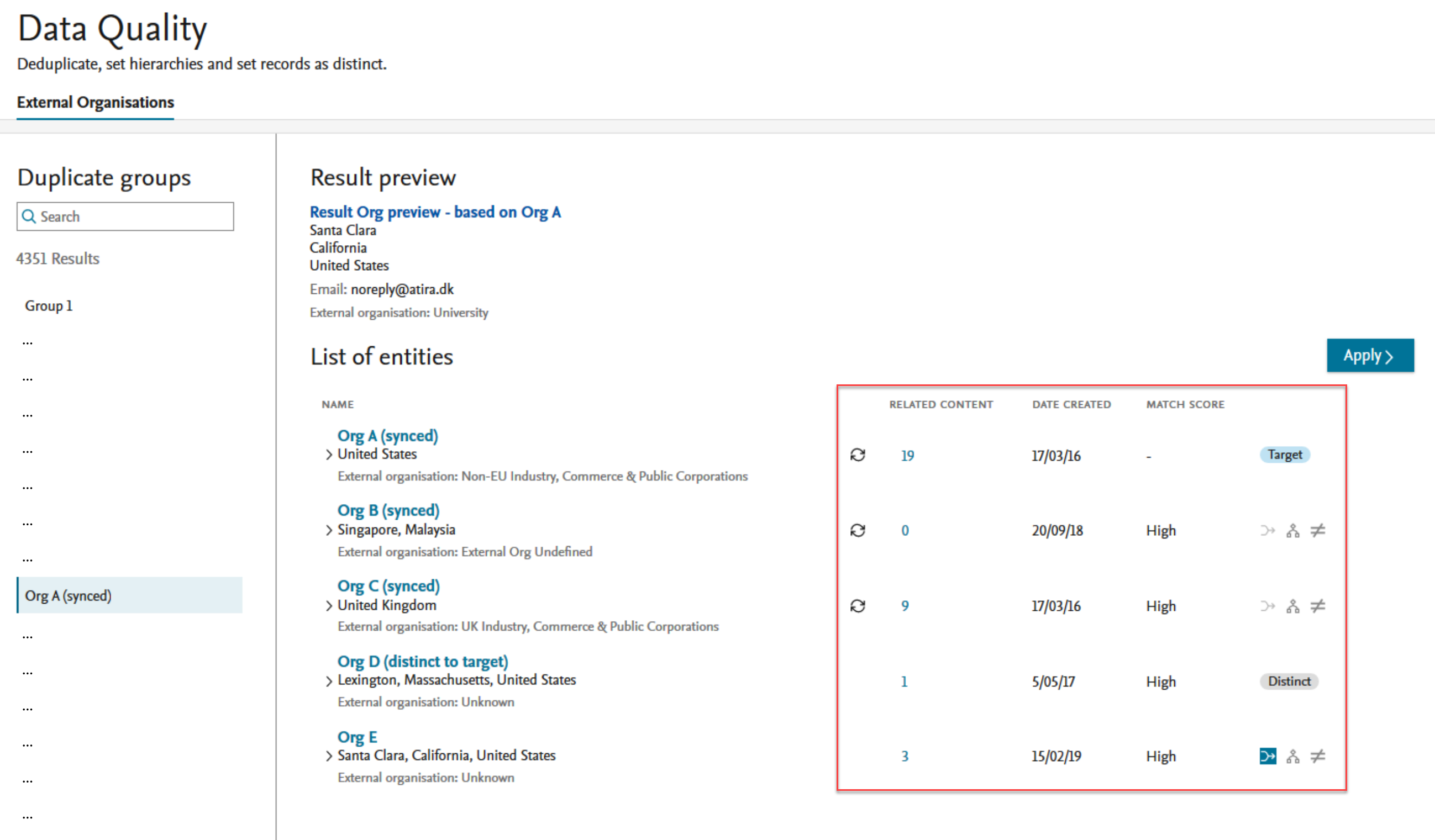
Entity list By clicking on a group, the organizations in that group are shown in the List of entities in the right hand section. The list of entities provides the names, an overview of any related content (available for preview by clicking the hyperlinked number), the date the entity was created and a match score showing the degree of similarity to the target, identified by the target badge. The last column on each entity contains the actions available. |
 |
|
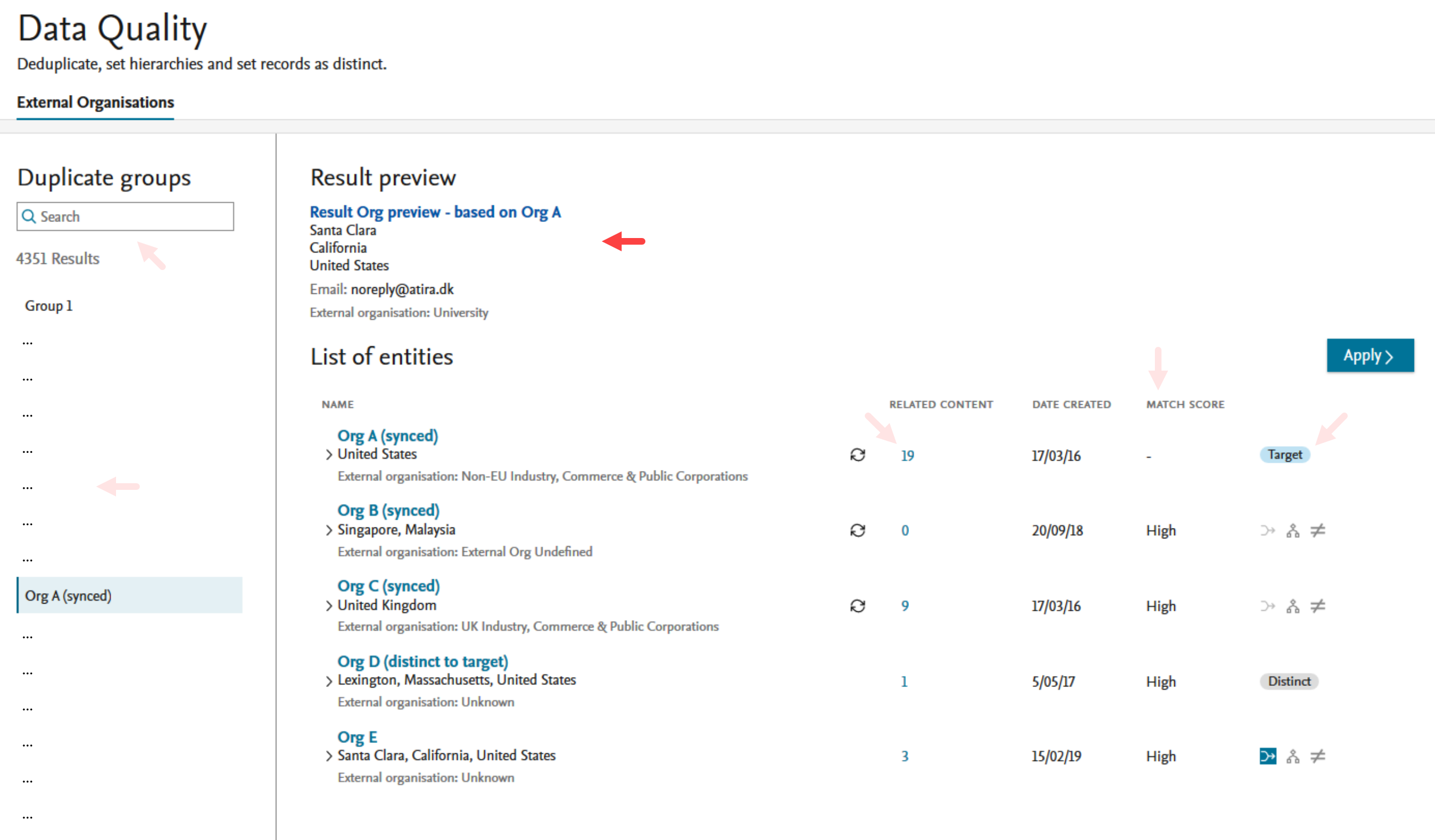
Result preview A Result preview of any actions on the target and source organizations will be displayed in the top section. |
 |
Basic controls within a group: setting a target organization
Information |
Screenshot |
|---|---|
|
A target organization is selected automatically based on:
The Result preview combines metadata fields of the target and merge options providing an on-the-fly view of what the merge result name and metadata would be. |
|
| The similarity between the target and the other organizations in the list is shown in the column Match Score. Users can change target by clicking the extended menu (…) that appears on hover over each organization and selecting Set as target. The match scores of all other organizations in the list will update accordingly and the new target organization will be moved to the top of the list. |
|
Basic controls within a group: merging organizations
Information |
Screenshot |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
The Merge icon has three states:
|
|
||||||||||
|
Organizations with a high degree of similarity to the target will be automatically selected as merge options. Organizations that cannot be merged into the target (such as Synced organizations - indicated with a sync badge) will have their merge icons disabled. |
|
||||||||||
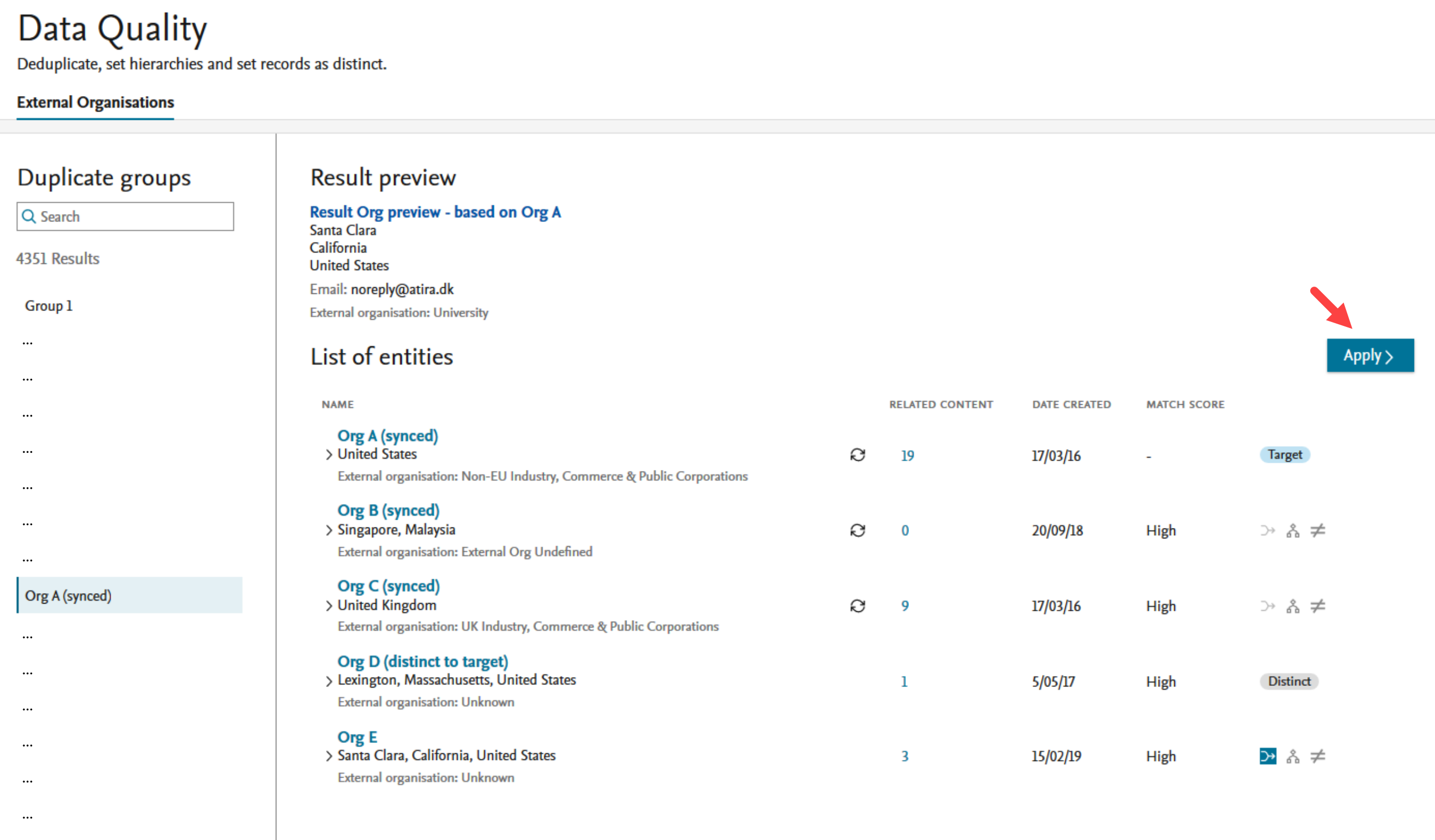
To merge:
|
|
||||||||||
| A short confirmation screen is shown with a list of organizations and the desired actions to be taken in relation to the target. |
|
||||||||||
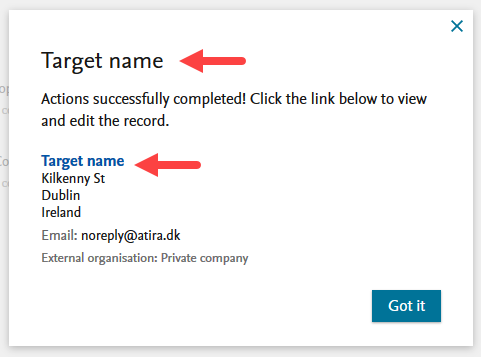
| After clicking Confirm, the progress of the merge is shown and, once completed, the user is presented with a confirmation screen and the option to open the newly updated target organization. |
|



Setting hierarchies of organizations in the list
|
The Set as child icon has three states:
As with the merge process, users can select (and modify) the target. The Set as child icon needs to be selected for each organization to be set as child to the target. Once the target and child options have been selected, users are guided through the confirmation and summary screens. |
|



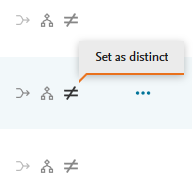
Setting organizations as distinct from target and all others in the list
|
Distinct from target As with the merge and hierarchy processes, users can select (and modify) the target. The Set as distinct icon needs to be selected for each organization to be set as distinct to the target. Once a target and distinct options have been selected, users are guided through the confirmation and summary screens. |
|
|||||||||
|
It is important to note that the organization(s) set as distinct are only set as distinct to the target. If there are only two organizations in the group, and one is set as distinct to the other, once the action is confirmed, the group will be removed. If there are more than two organizations in the list, the user will be returned to the group and any organizations set as distinct to the target will have a Distinct badge. |
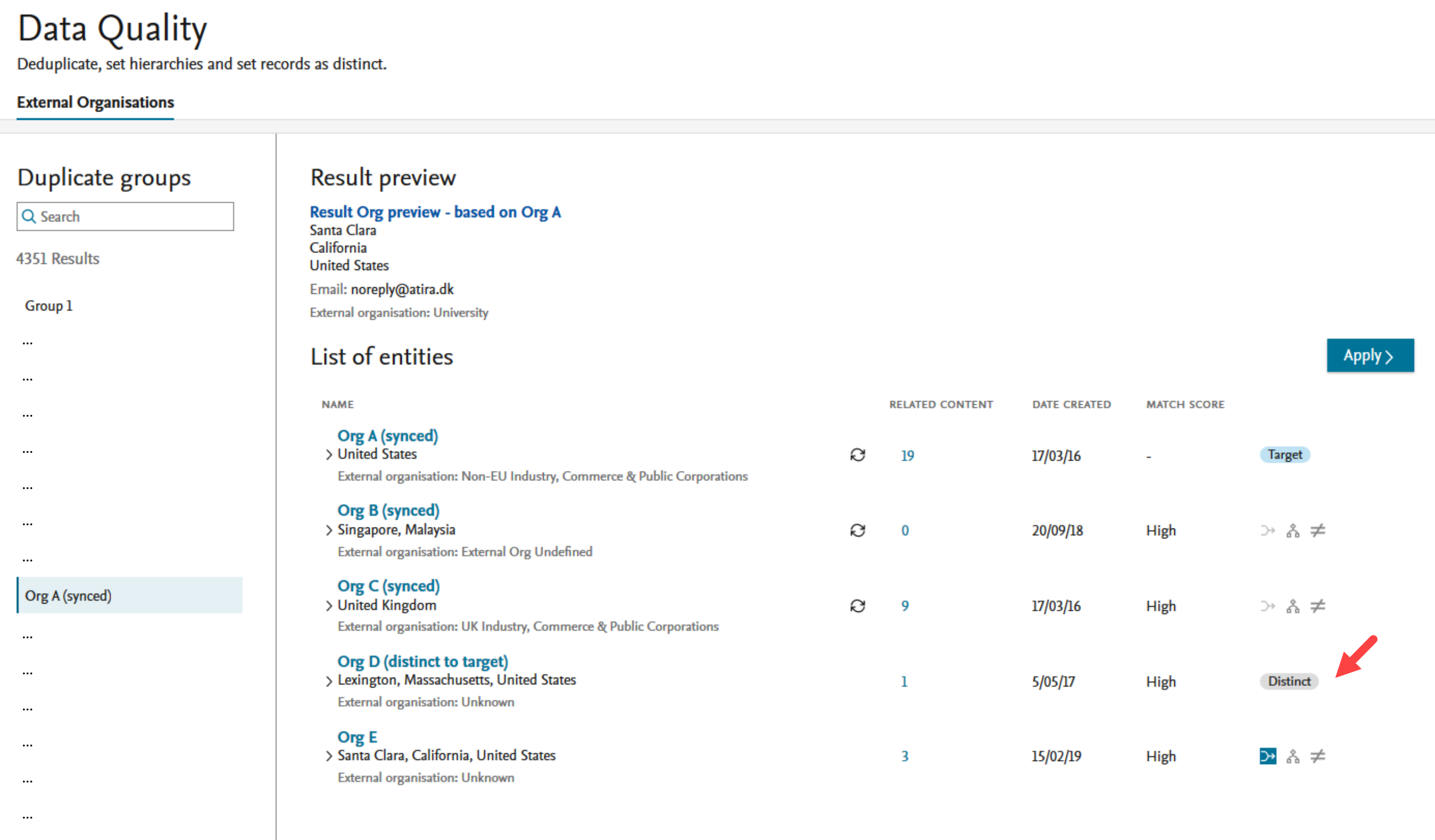 |
|||||||||
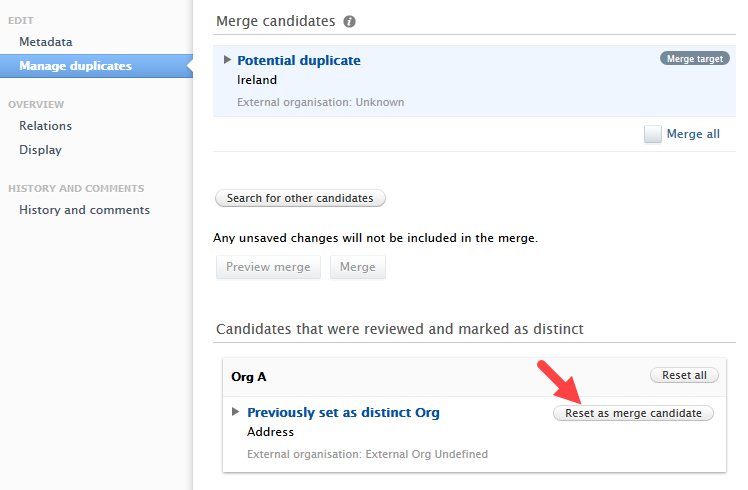
| Organizations that were previously set as distinct to the target will also have no option to merge - unless they are reset as merge candidates in the organization editor. |  |
|||||||||
|
Distinct from all A user may wish to set an organization as distinct from all others in the list. They can do so by using the Mark distinct from all option in the extended menu. This will immediately remove that organization from the group listing and will not have a confirmation screen. |
 |

Closing or completing a group
A group will be removed from the list when all the organizations in that group have either been merged, set as distinct from all possible targets, or set as distinct to all. Multiple targets can exist in a group, so multiple iterations of cleaning, hierarchy setting, and setting as distinct are possible.
Special cases
Synced or SciVal organizations
When an organization is synced or from the SciVal External Organization list, other entities cannot be merged into it. The merge icon is disabled and a warning is shown when users click the icon. These organizations can however be set as children or marked as distinct.
Job configuration
What does the job do?
The job cycles through every External Organization looking for any matching External Organizations. If it finds matching Organizations (based on either name, alternative names or source IDs) over a specific threshold, it adds them to a group. Once all possible match options are exhausted, the group is finalized and is shown in the Data Quality interface.
Limit
Due to the high degree of complexity in finding and grouping potential duplicates, the version of the job in 5.22.0 will consider a maximum of 50,000 external organisations. This limit is set in place to avoid performance issues in Pure.
Job configuration
The groups of entities are created by the Duplicate External Organization Discovery job which can be found in Administrator > Jobs > Cron Job Scheduling.
The job needs to be enabled, and have run, before any results will show in the Data Quality interface. The job can be enabled to run at your preferred schedule.
For the first run of the job we suggest enabling verbose logging mode (Edit configuration > Enable running in development/debug mode).
Job scheduling
The groups in the Data Quality interface will be updated, possibly with new entities, after every run of the job.
We suggest scheduling the job depending on how frequently you or your users want to use the Data Quality interface.
For:
- light, daily cleaning, we suggest running the job daily outside of office hours.
- deep cleaning, we suggest running the job once every couple of days or a week*. This way any particularly large groups will have the same list of entities between cleaning sessions (and job runs).
*For particularly intense cleaning sessions, we suggest pre-soaking the job before your usual cleaning cycle.
Update: in 5.23.0 the job has been made more efficient and can be run once a minute. This only applies if you are on 5.23.0 or higher. See the 5.23.0 release notes section for more details.
Inspecting the job log
The job log provides and overview of each match attempt between Organizations.
The last entry in the job log after each run provides:
- summaries of how many groups were identified
- what is the largest number of entities in a group, and
- how many groups were added or removed from the last job run.
The job importantly also provides an estimate of how many unique External Organizations are in your Pure, based on the number of groups created and the number of entities were no matches could be found.
Tip: How to quickly and efficiently process organizations in a group.
Depending on your institution’s needs and whether you make extensive use of hierarchies within External Organizations, our general advice is to:
- Make use of the preselected target and high match entities in a group. A quick scan of the names and any available metadata of preselected high match options may be enough to confirm if the choices are indeed correct. Individual Organization editors can always be opened by clicking the name, and a scan of any related content for identical contributor names can be achieved by clicking on the related content count in the list of entities.
- For groups with more than 10 Organizations, we again suggest focusing on the target and any preselected options. Once those have been processed, you will be directed back to the group and a new target and high similarity options will have been selected.
- Alternatively, switching targets and evaluating the newly preselected options will give you an overview of any sub-groups present. This overview will better inform your choices for Organizations to be merged or set as children.
- Process merges first as this quickly reduces the number of entities in the list.
- Following this, setting the hierarchy will also reduce the list quickly.
- Process the distinct Organizations last. Undoing a distinct operation is possible, but will require you to manually remove the distinct tag on the Organization editor (Organization editor > Manage duplicates tab)
3.2. Deduplication available on more content types
Duplicate title and identifier functionalities have been expanded to more content types. These improvements come as part of our growing set of features dedicated to improving data quality.
The deduplication overviews can be found under each content type in either the Editor or Master data tabs.
Click here for more details...
The content types now supported are listed below. For each content type, deduplication is based on title or identifier similarity. Exceptions are noted.
- Activities
- Applications
- Awards (year of award also considered)
- Courses
- Datasets
- Equipment
- Press/Media
- Prizes
3.3. Personal User Overview(PUX) now standard for all customers
The new Personal User Overview (PUX) is now the standard person profile for all customers. The new Personal User Overview was introduced in 5.14.0 and is a significant improvement to how Personal Users access, work, explore and add content within Pure.
The new overview is tightly integrated with the personal user’s Pure and PlumX data at the Research Output, Project and researcher level. This includes coverage of content added by the user and institution, and PlumX mentions, usage, captures, social media and citation data for each Research Output where available. The new Overview is aimed at encouraging productive and meaningful engagement between the Personal User and their content in Pure.
For more information and help with preparation for the personal user overview:
- consult the 5.14.0 release notes
- make use of the detailed user guide - written from the perspective of an Administrator for their Personal Users
4. Pure Core: Pure Web Service and Pure API
Pure Web Service is the read-only service available to all clients. See Administrator > Web services for more details.
Pure API is the read-and-write service currently under development and available to clients through the Early Access Program. See Administrator > Pure API for more details.
4.1. Pure Web Service: filtering Student Projects via type URIs
It is now possible to search for content of a specific type, or exclude content from search results based on its type.
Example: The query below will return Student projects of the type 'Master Thesis'.
<?xml version="1.0"?> <studentProjectsQuery> <typeUris> <typeUri>/dk/atira/pure/studentproject/studentprojecttypes/studentproject/masterthesis</typeUri> </typeUris> </studentProjectsQuery>
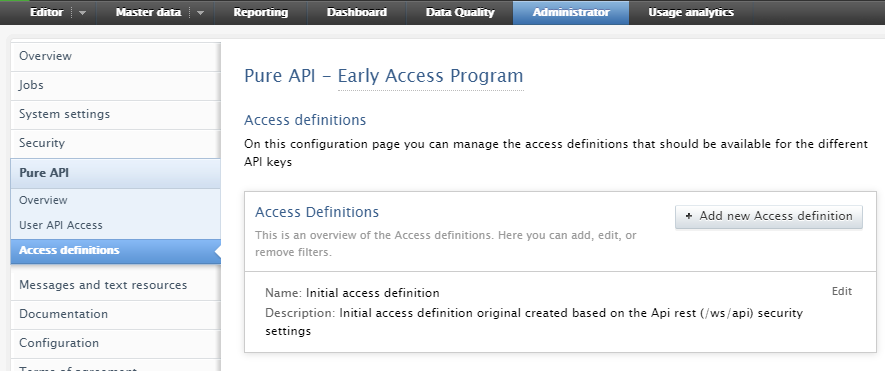
4.2. Pure API: access definitions for content and field filtering
Pure API - Access definitions for content and field filtering
Learning about the Pure API?
Please visit the Getting started: Pure API user guide for an overview and recommended starting steps.
It is possible to pair API keys with configurable access definitions to specify:
- What content is available to what API key.
- What metadata is exposed for the different API types.
- Whether an API key grants read and write permissions, or only read permissions.
This provides you with much greater control of what data is made available to whom.
For example, it is now possible to:
- Set up an API key which grants access to all confidential content (as long as that content is available through Pure API), embargoed documents, and all fields on Persons.
- Set up another API key which can only read a few fields on Persons and only has access to public data.
Note: All existing API keys will be migrated and given access definitions that match their old behavior, but can be updated afterwards to the desired access definition.
Information |
Screenshot |
|---|---|
|
Overview Setting available to user role: Administrator Each API keys is now linked to an access definition:
|
|
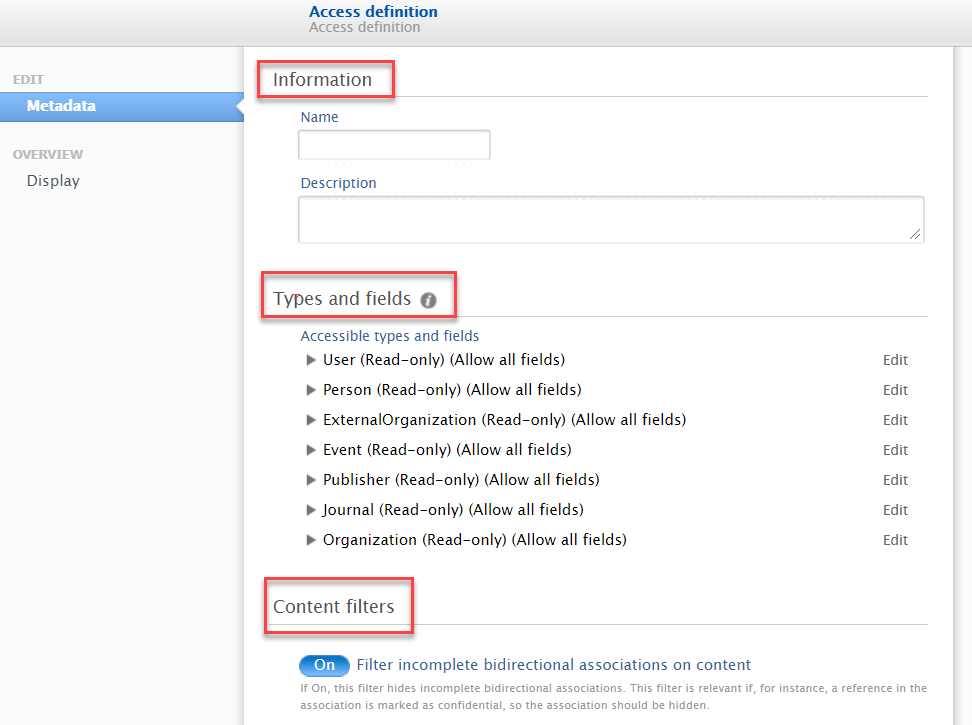
Access definition editor When creating an access definition, you can specify a number of details in the Access definition editor.
Add name and description of your access definition.
The Types and fields section includes all the supported types in the Pure API.
Filters in this section are the same as those available in Administrator > Security > Ws > Authentication requirements and content filtering. |
|
|
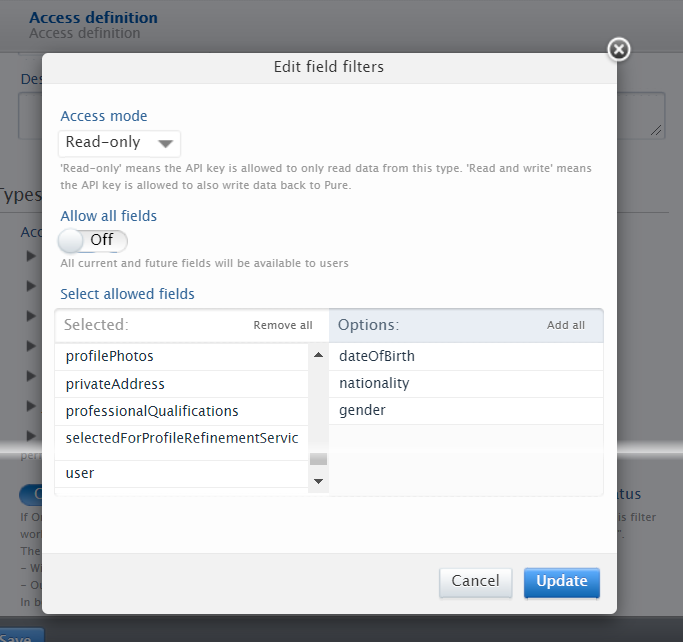
Access definition: customizing accessible types and fields Access definition editor > Types and fields lets you edit each available type to:
This means that you have flexibility to, for example, allow read-only access to some types, and read and write access to others. Note: The names of the fields in the editor correspond to the field names in the JSON response from the API. |
|
|
Adding an access definition to a new API key
|
|
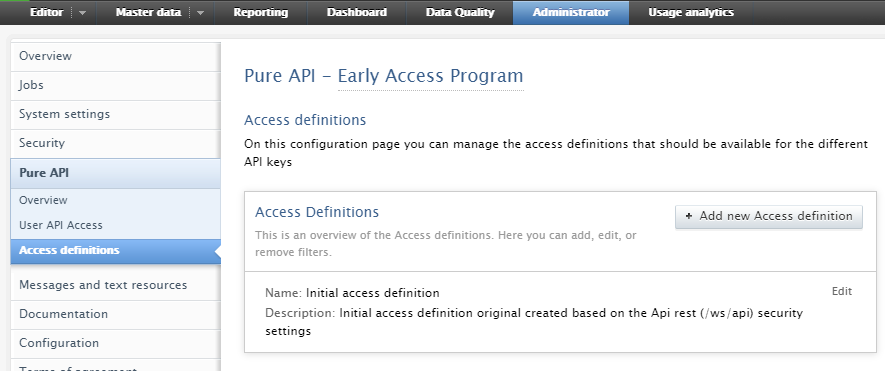
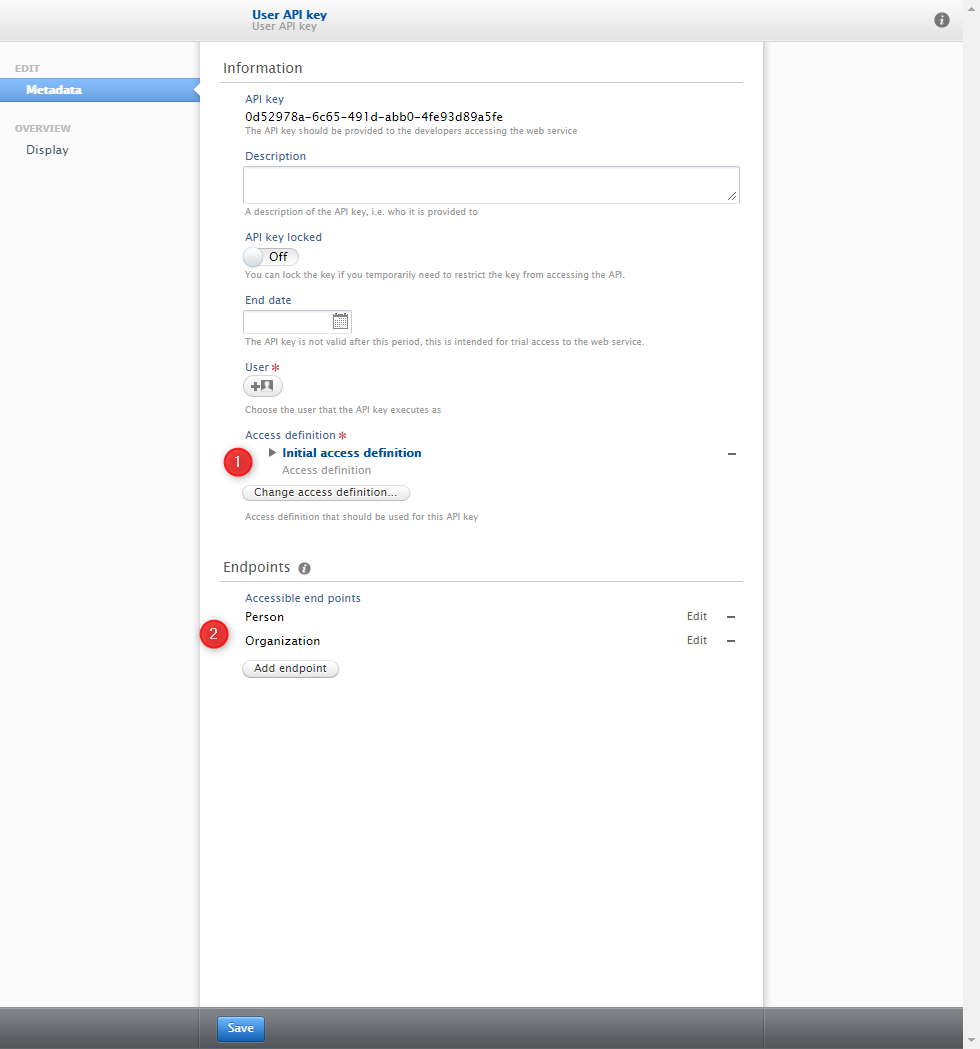
Existing API keys: initial access definition
Upon upgrade to 5.22.0, an initial access definition will be created and associated with all existing API keys.
The settings of the initial access definition will follow what you had setup for the REST service before the upgrade.
4.3. Pure API: Person and External Person endpoints now available
Pure API now supports the management of Person and External Person in addition to Journal, Publisher, Event, Internal Organization and External Organization.
With the new filtering options mentioned in Pure API: access definitions for content and field filtering, it is possible to control exactly what fields you expose to an API key, which is especially important for the new Person API type.
Click here for more details…
Pure API is an evolution of the existing REST service to support a backwards-compatible read and write REST JSON endpoint for using and managing research information data in Pure.
In order to achieve these objectives, we have made several changes to how the endpoints are structured and to the format of the managed entities in Pure API.
- The endpoints for an entity are structured so that it is clear where you can expect REST or RPC semantics. This should make it easy for developers to interact with the API with a minimal upfront time investment.
- The entity format is optimized in regard to JSON data modelling best practices and with an expectation of the model evolving in a backwards-compatible manner in the future.
- The API specification is defined and published as an OpenAPI 3 specification enabling service users to quickly generate a client while at the same time providing developers with useful documentation on the API and its semantics.
- The entity API includes several helper operations that return the allowed values for the different parts of the entity model where this is relevant - this should make it easy for developers to submit valid changes to the write portions of the API.
- All modification requests are made on behalf of a specified Pure user and clearly audit logged with both user and API key details.
- As we expect the API to be able to support older clients updating against a newer version of the API, all PUT requests have JSON merge patch semantics. This ensures that older clients do not inadvertently clear new properties that they do not know about.
When the module has been successfully enabled, a Swagger UI representation of the OpenAPI 3 specification will be available at https://{your Pure hostname}/ws/api/api-docs/index.html?url=/ws/api/openapi.yaml. The latest API on the development community sandbox server can be found in this Swagger UI. A sample Java client that can be used as a starting point for developing a client can be found on the GitHub page.
Information |
Screenshot |
|---|---|
| The early access Pure API can be enabled in Administrator > Pure API. Please note that enabling or disabling the Pure API module requires a restart of Pure in order to take effect. |
|
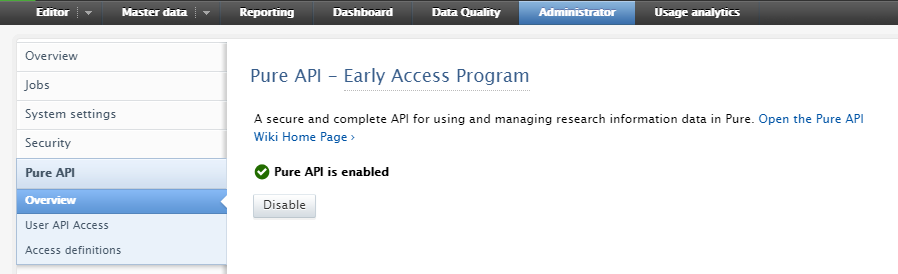
All use of the new endpoints requires an API key that is generated in Administrator > Pure API > User API Access.
In contrast to the current Web Service API keys, the new Pure API requires a user on whose behalf the system using the API key can act.
5. Integrations
5.1. Integration with Funding Database: self-import of Awards and Projects
In this release we are happy to announce that we expanded functionality for Awards and Projects in Pure, making it possible for Personal Users to search for and import Awards and Projects from specific funders.
In addition, the Elsevier Funding Database has been added as a self-import source, allowing Personal Users to search for Awards and Projects across a variety of funding bodies from different countries. They can then quickly preview and assess Awards and Projects before adding them to Pure.
Self-import of Awards
See below for instructions on how to enable, add, and search for content from the Funding Database.
Click here for more details...
Instructions |
Screenshot |
|---|---|
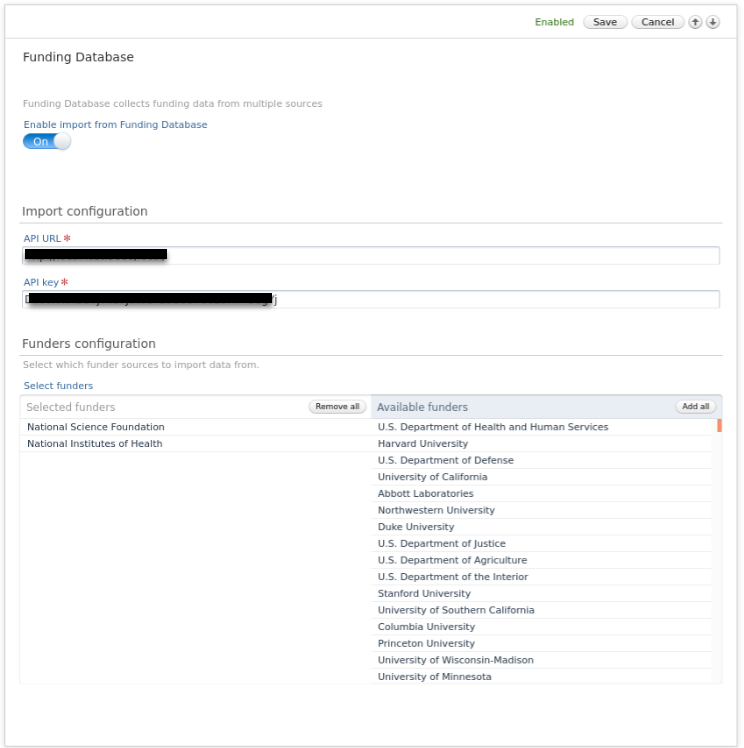
To enable the Funding Database as an import source, go to Administrator > Integrations > Funding Database. |
|
|
In the source configuration it is possible to enable the Funding Database as an import source. Available funders can then be selected under Funders configuration. Funders listed on the right will be excluded from the search. After setting the desired configuration, click Save. |
|
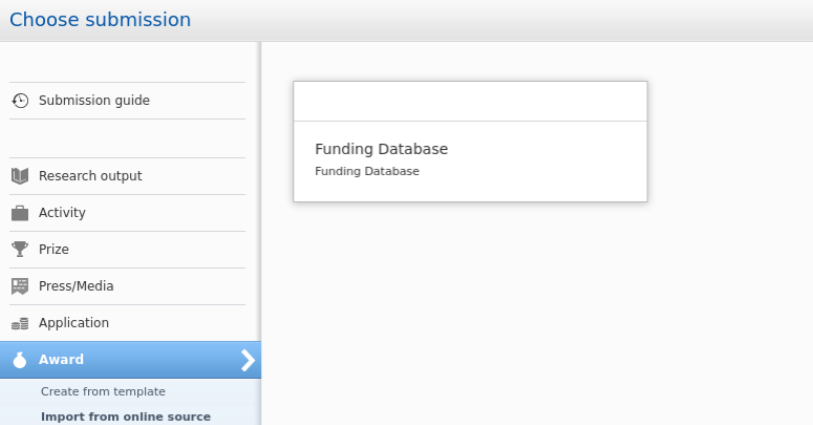
To search and import content, go to Editor > Awards > Import from online sources, and select Funding Database. |
|
|
You can now search content using Title, Author name(s), Author ID(s), Award time range, and/or Organization name(s). You can also combine the values. For instance, if you are interested in content with a certain title and awardee from a specific year, then you can fill out all of the fields and do a combined search. |
|
|
Search results are presented as import candidates and can then be previewed and imported (or removed). Awards that have previously been imported to Pure from the Funding Database are shown as duplicates. The funder from which the dataset is being imported is shown for all import candidates. |
|

Self-import of Projects
See below for instructions on how to enable, add, and search for content from the Funding Database.
Click here to expand...
Instructions |
Screenshot |
|---|---|
To enable the Funding Database as an import source, go to Administrator > Projects > Import sources. |
|
|
In the source configuration it is possible to enable the Funding Database as an import source. Available funders can then be selected under Funders configuration. Funders listed on the right will be excluded from the search. After setting the desired configuration, click Save. |
|
| To search and import content, go to Editor > Projects > Import from online sources and select Funding Database. |
|
|
You can now search content using Title, Author name(s), Author ID(s), Award time range, and/or Organization name(s). You can also combine the values. For instance, if you are interested in content with a certain title and awardee from a specific year, then you can fill out all of the fields and do a combined search. |
|
Search results are presented as import candidates and can then be previewed and imported (or removed). Projects that have previously been imported to Pure from the Funding Database are shown as duplicates. The funder from which the project is being imported is shown for all import candidates. |
|

5.2. Integration with Funding Database: improved configuration for automatic import of Awards and Projects
We are happy to announce that in release 5.22 we have expanded the configuration options for the automatic import of Awards and Projects from the Funding Database. It is now possible to either import Awards and Projects automatically, or to be presented with import candidates that can be previewed and assessed before importing them into Pure.
Details on how to enable the integration and select import options are given above.
To enable the automatic import of Awards and Projects from the Funding Database, go to Administrator > Integrations > Funding Database. In the job configuration page you will be able to set the following options:
Click here for more details...
Instructions |
Screenshot |
|---|---|
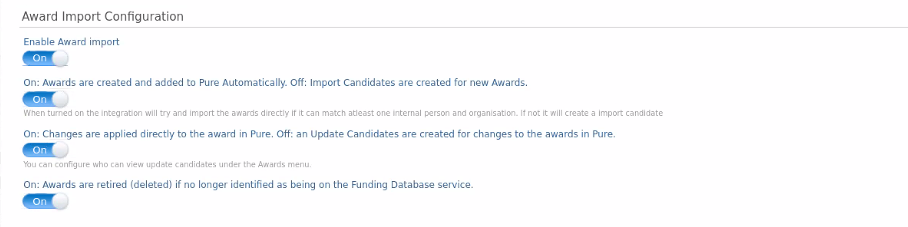
Job Configuration We have introduced a series of toggles for configuring the import of Awards and Projects. In the job configuration, settings are divided into General Settings, affecting the entire synchronization, and separate setting for the Award and the Project synchronizations. General settings: In the General Settings it is possible to set the search parameters for content indexed in the Funding Database. It is possible to search on: Scopus Author ID, Organization ID, or Organization name.
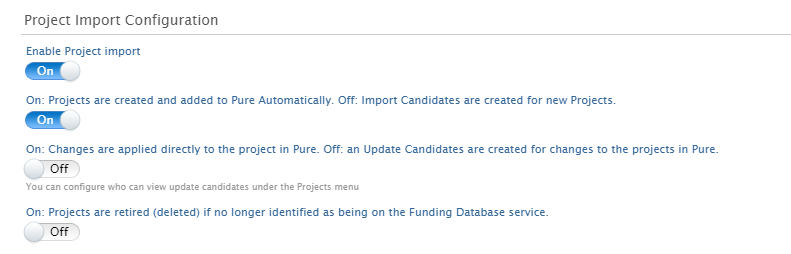
Award and Project Import Configuration: In the Award Import Configuration, it is possible to set conditions for the import ofAwards to Pure. This section includes four options:
The same options are available in the Project Import Configuration. |
|
|
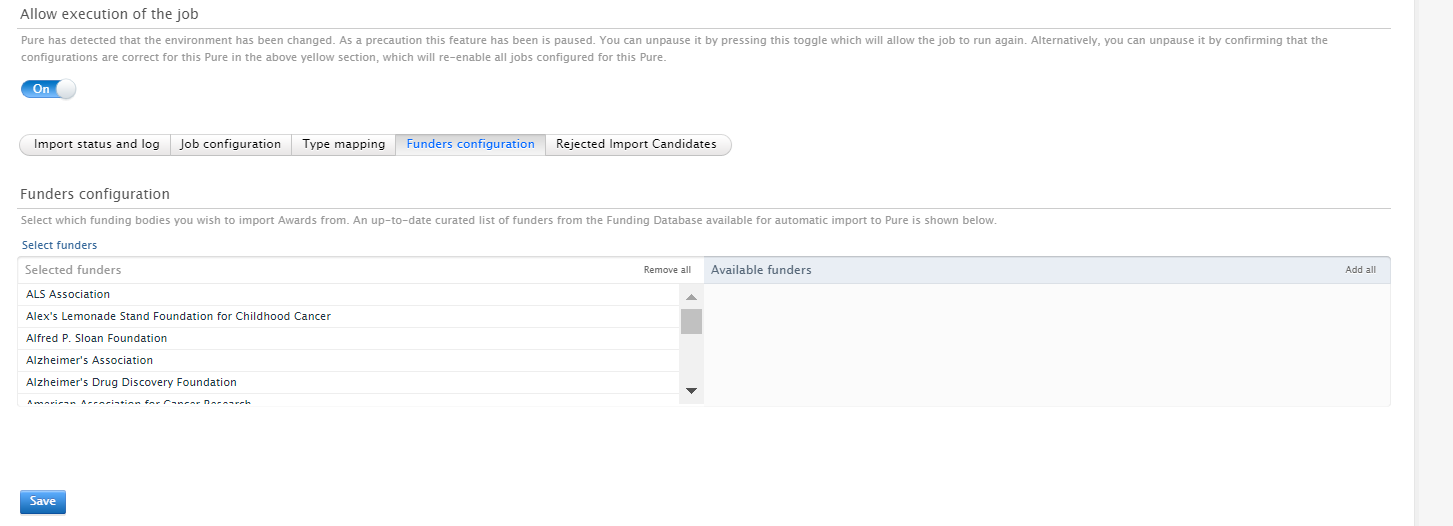
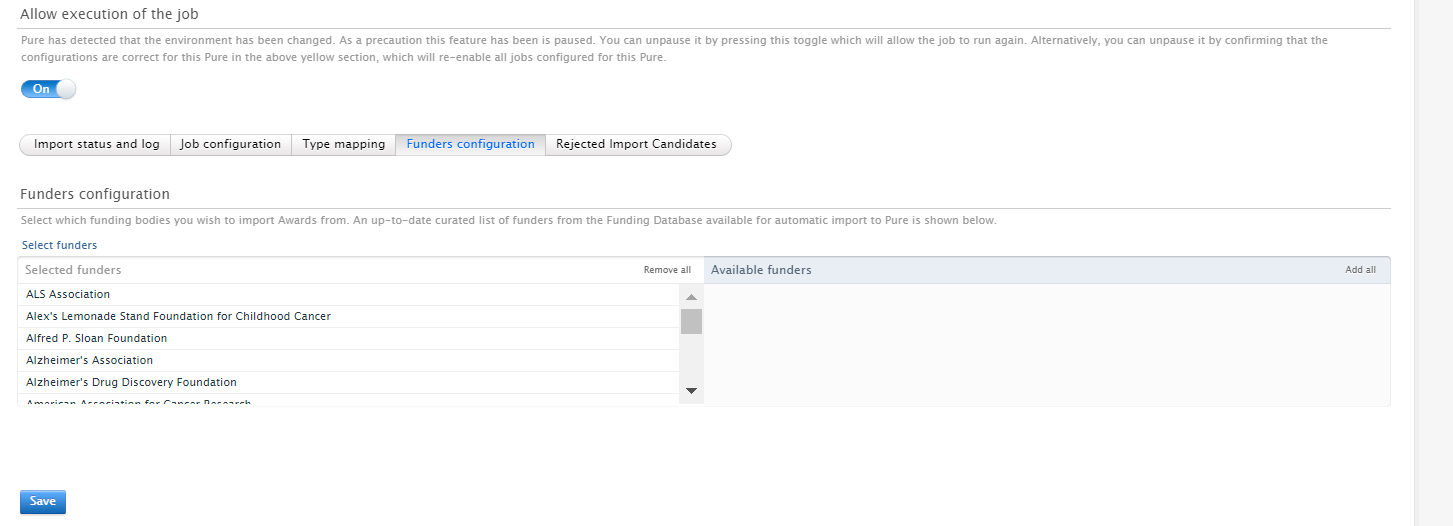
Funder Configuration Here, Administrators can select which funders to include in the import job. |
|
|
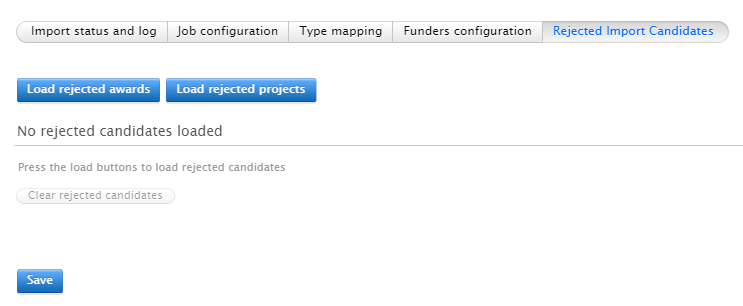
Rejected Import Candidates Import candidates that have previously been rejected are listed in this tab. Rejected candidates can be un-rejected and will be picked up by the job when it next runs. |
|
|
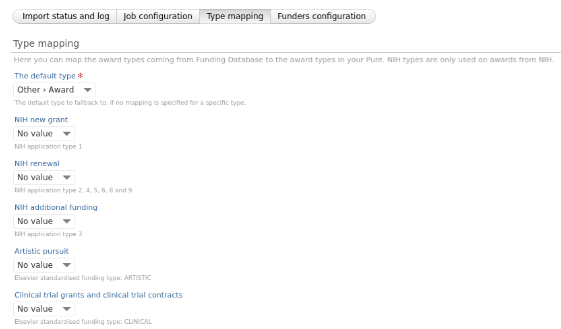
Type Mapping This tab lets Administrators specify the mapping for Awards imported from the Funding Database. The default type mapping must be selected. |
|
5.3. Awards and Projects: new funders added from the Funding Database
Until this release, the integration with Funding Database supported the import of Awards and Projects from:
- NIH (https://www.nih.gov/)
- the National Science Foundation (NHS: https://www.nsf.org/)
- the Russian Foundation for Science (RFS: https://rscf.ru/en/)
In this release, we have expanded support to all 689 funders currently indexed by the Funding Database.
However, to facilitate the automatic import of content from the Funding Database we have curated a smaller list of 87 funders. This is to limit the number of Awards and Projects that are not automatically imported because of missing metadata (and therefore insufficient matching). All records imported from funders on our curated list include either Scopus Author IDs or Organization IDs and can therefore be matched in Pure.
When selecting the self-import configuration, it is possible to import data from the full set of 689 funders. When found, content is presented as import candidates and it is possible to edit the metadata of the Award or Project.
When importing content through the Award and Project synchronization job the list is limited to 87 funders.
5.4. Awards and Projects: improved organization matching
We have improved the integration matching mechanism so that we can now determine the managing organization more precisely. Until now, only the root organization was extracted from the source data, leading to the import of ‘incorrect’ Awards and Projects that have been assigned a wrong managing organization (i.e. the awardee was part of the root organization at the time they received the Award but is now a former person).
In release 5.22 we have improved the quality of the captured data. When content is imported from the Funding Database, Persons and Organizations are matched to internal Persons and Organizations. If an internal Person or Organization is matched, then that Organization is set as managing organization. If no Person or Organization is matched, a default managing organization will be assigned as managing organization.
The 'Add Default Managing Organization' option in the job configuration page enables a default managing organization to be added to Awards and Projects for which no organization could be matched (to an internal Organization) from the source data. Since a managing organization is required, this will affect the number of Awards and Projects that can be imported directly.
See below for a detailed description of the improved organization matching logic.
Click here for more details...
The logic added will, first and foremost, try and match the root organization provided in the source data to an internal Organization in Pure based on organization ID. If no internal Organization can be found, we will attempt a name match.
-
If we match to an internal Organization, we will add that Organization as the managing Organization and treat the Award or Project as internal to the institution.
- This means that for any Persons on it, that we match to an internal Person in Pure, we will look at the organizations they are associated to in Pure and add to the award holder/participant. These Organizations will be added using the following logic:
- Pure will try and limit to any organizations which the Person was associated to based on the Award/Project period.
- If none can be found, it will look at any active Organizations for the Person and pick the first one.
- If none can be found, it will simply default to the first Organization on the Person.
- In some cases, the source data provides a department name. Based on the department name Pure will look through the Person's organization associations and match internal Organizations.
- If one is found, that Organization is used.
- If multiple are found, the above described rules are applied to this subset of Organizations to pick the correct one.
- If we are able to derive internal Organizations for the award holders/participants, the managing Organization will be overridden and set based on the first internal award holders/participants associated internal Organization
- This means that for any Persons on it, that we match to an internal Person in Pure, we will look at the organizations they are associated to in Pure and add to the award holder/participant. These Organizations will be added using the following logic:
-
If we are unable to match it to an internal organization we will treat the Award or Project as external to the institution.
- This means that for any Persons on it, that we match to an internal Person in Pure, we will look at the organizations they are associated to in Pure and add to the award holder/participant. These Organizations will be added using the following logic:
- Pure will try and limit to any organizations which the Person was associated to based on the Award/Project period.
- If none can be found, the Organizations from the source data will be added to the award holder/participants as an external Organizations.
- If we are able to derive internal Organizations for the award holders/participants, the managing Organization will be set based on the first internal award holders/participants associated internal Organization.
- If no internal Organization can be derived, no internal managing organization is added unless the Funding Database Integration has been configured to add the configured default organization.
- This means that for any Persons on it, that we match to an internal Person in Pure, we will look at the organizations they are associated to in Pure and add to the award holder/participant. These Organizations will be added using the following logic:
5.5. Awards and Projects: Deduplication
With the expansion of the Funding Database integration and the inclusion of over 600 funders, it is important that new Awards and Projects imported to Pure do not negatively affect the existing content. To the purpose, we have added support for the identification of potential duplicates.
Records imported through self-import will be presented as duplicates if a match is detected on classified IDs, title, and start date of an existing record.
When importing content through the synchronization job it is possible to enable a duplication check in general settings of the job configuration. When the option to 'Skip Potential Duplicates' is enabled, the job will check new content for duplicates against existing content in Pure, and automatically skip a record when a duplicate is detected. Deduplication is based on IDs, strict title-matching (90%) and on the start date of the Award or Project. When the toggle is off, potential duplicates will be imported and the Administrator can later merge the records in Pure.
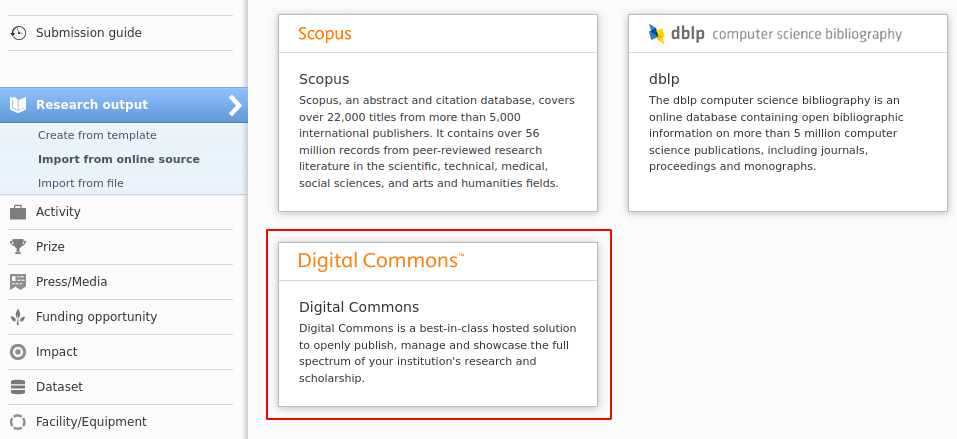
5.6. New import source: Digital Commons
Digital Commons is an institutional repository platform for journals, conference proceedings, open educational resources, and more. It is used by over 500 academic institutions, healthcare centers, public libraries, and research centers to manage and showcase their institution's research and scholarship. In this release we have added Digital Commons as an import source to Pure.
Instructions on how to enable, add and search for content from Digital Commons are shown below. In order to enable this integration a subsription to Digital Commons is required.
Click here for more details...
Instructions |
Screenshot |
|---|---|
| To enable Digital Commons as an import source, go to Administrator > Research Output > Import Sources | |
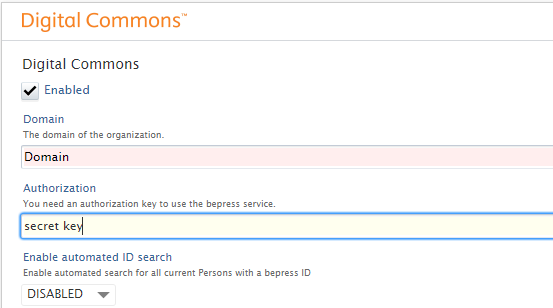
A Domain and Authorization key are required to use Digital Commons. To register please contact support@bepress.com. Once you have these details please contact pure-support@elsevier.com to setup the integration in Pure. |
After 5.22.1 |
| To search and import content, go to Editor > Research Output > Import from online source and select Digital Commons. | |
You can now search for content using article title, bepress ID, author names, or a general search on all data fields. You can also combine the values. For instance, if you are interested in content with a certain title and author, then you can fill out both fields and do a combined search. You can search for specific authors who are registered in Digital Commons by using the bepress ID. When you use the general search field, your query is checked against all data fields. This is a good option e.g. if you want to run a search for keywords that maybe both in title and abstract of a publication. |
|
| Search results are presented as import candidates and can then be previewed and imported (or removed). Records that already exist in Pure are shown as duplicates. |
|
Digital Commons supports automatic update candidates. When content is imported, an automatic job will find updates, and they will show in the research output overview (A). When you click this menu item the update can be either accepted or rejected (B). |
 |
Digital Commons supports automatic import candidates. If an author in Pure has a bepress ID (Digital Commons author ID), the system will automatically find other content from the author (A). When you click on the little green button with the number inside you get a list of import candidates (B). From there, you can either import or reject the content. |
|

5.7. OAI: MODS language in NL-DIDL
MODS XML of NL-DIDL now includes lang attributes when requested using OAI-PMH. You may observe slightly different MODS XML with different ordering of attributes and fewer namespaces as a result.
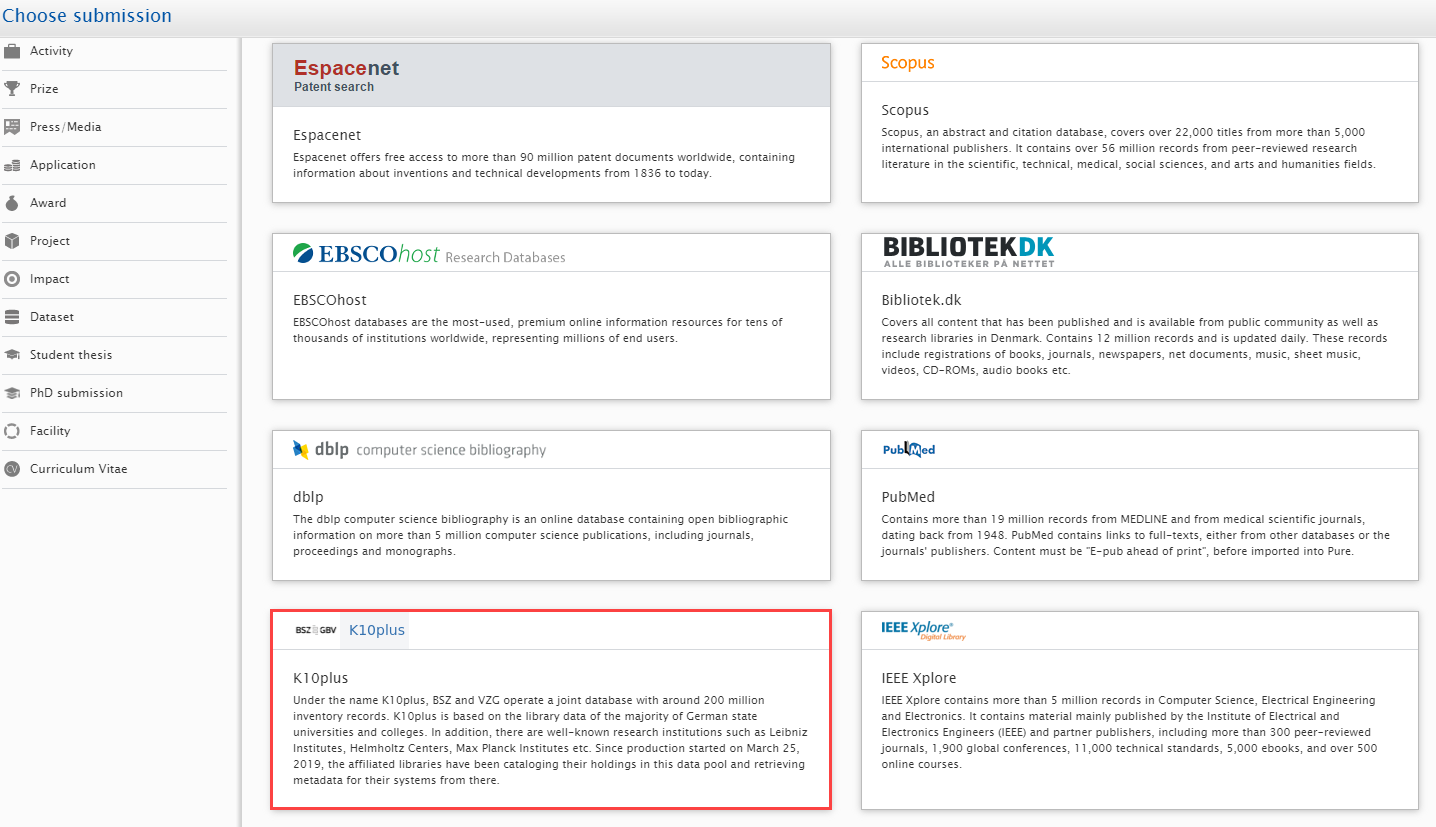
5.8. Import Source Update: GVK replaced by K10plus
In this release we have replaced our existing integration with GVK with the more comprehensive K10plus, a joint database that includes around 200 million inventory records from the majority of German state universities and colleges.
Instructions |
Screenshot |
|---|---|
| To enable K10plus as an import source, go to Administrator > Research Output > Import Sources |  |
To search and import content, go to Editor > Research Output > Import from online source and select K10plus. |
 |
6. Reporting
6.1. Citation formats in Reporting
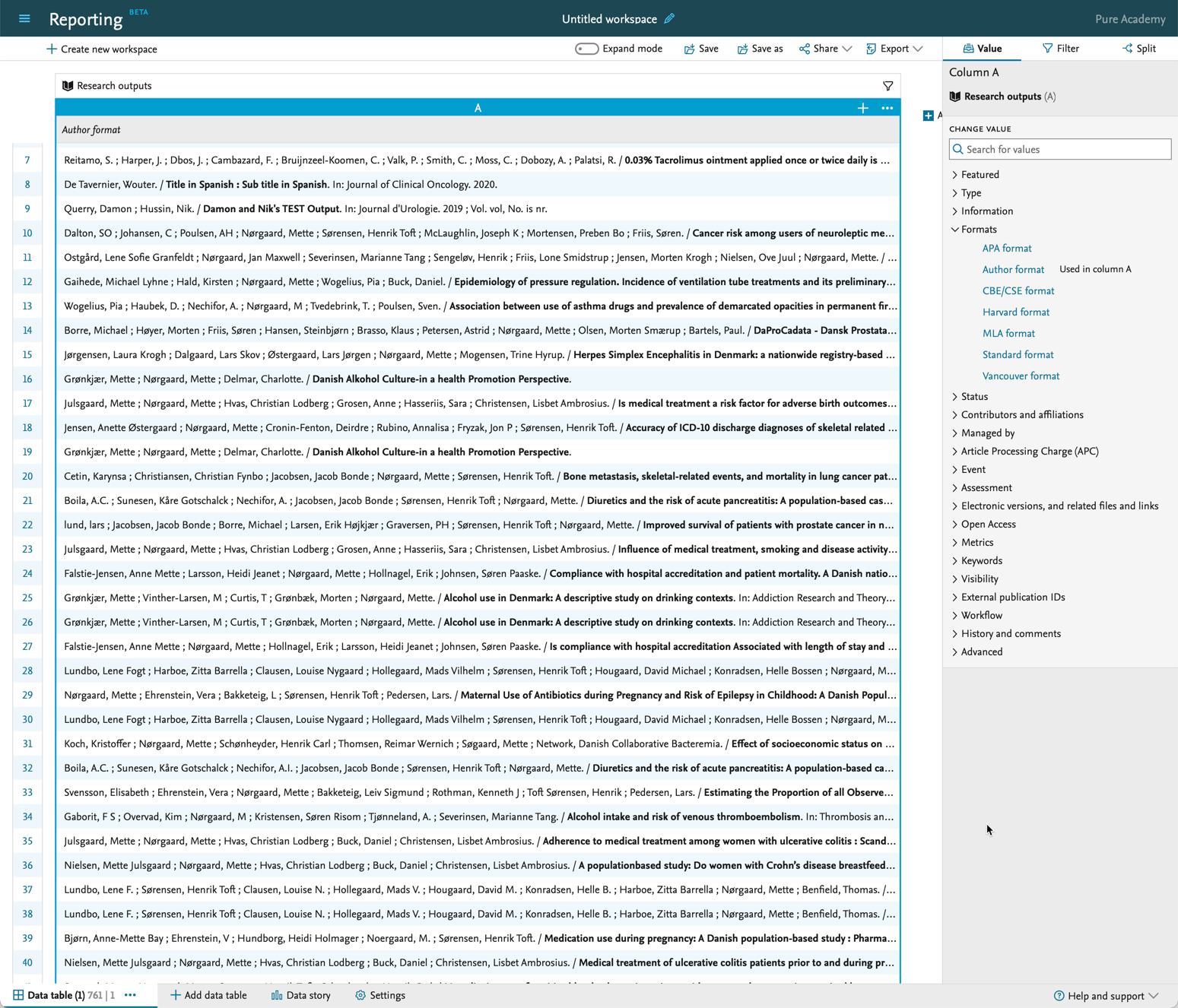
We're really happy to announce that it is now possible to use the citation formats for Research Outputs in the Reporting module as this is one of the most requested improvements counted by votes.
With this release you can now select the various citation formats that Pure supports for Research Outputs. This makes it possible to view the list of Research Outputs in a specific format, for instance APA, or Vancouver, and these values can be used in the data story to help tell the research stories. The formats can also be used when exporting to either Excel or CSV.
Click here for more details...
You can find the formats in the same place as all the other values that you add to the Reporting module.

After adding the selected format, a new column will be added to the data table with the selected citation format.
7. Unified Project Model and Award Management
7.1. Milestones improvements
We have made a number of enhancements to our Milestones functionality available to customers using the Award Management module. With this release, we have made changes to how users can choose to receive emails and notifications, and have introduced task panel options to show those Milestones that are forthcoming or that may be overdue.
Click here for more details...
Information |
Screenshot |
|---|---|
Messaging and email notifications We have introduced a number of messaging/email notification options for Milestones that can be selected from within the users profile settings. These include the ability to receive:
In addition to these changes, we have also made some adjustments to the email text sent by Pure in order to reduce the risk of potentially confidential award information being made available. Milestone emails will now inform users that they have a task pending and will invite them to view the associated milestone and award in Pure via a deep link URL contained in the email text. |
 |
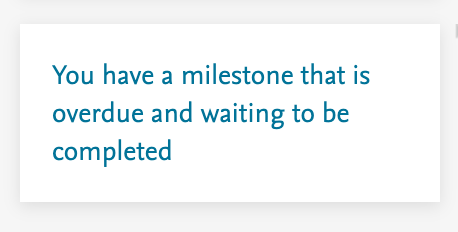
Task panel We have added the option of displaying a task panel item for users to identify any forthcoming or overdue Milestones for which they have been named as the responsible user. |
|
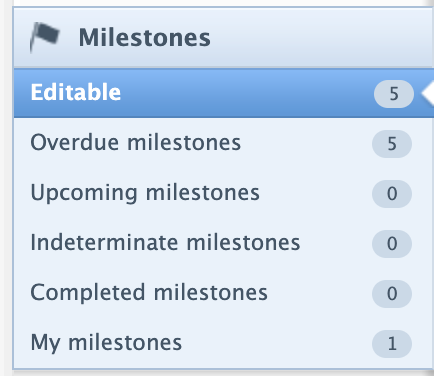
Milestone overview screen We have updated the filters available from the Milestones overview screen to make it easier for users to identify those Milestones they are have been assigned as named (responsible) user. We have also added a new filter to show the total of Milestones that can be completed based on the user permissions ('Editable'). |
|
8. Pure Portal
8.1. Organization filter available on more content types
In this release we have made a highly requested update to the Pure Portal search filters. It is now possible to find content in the portal based on which Research Unit contributed to it.
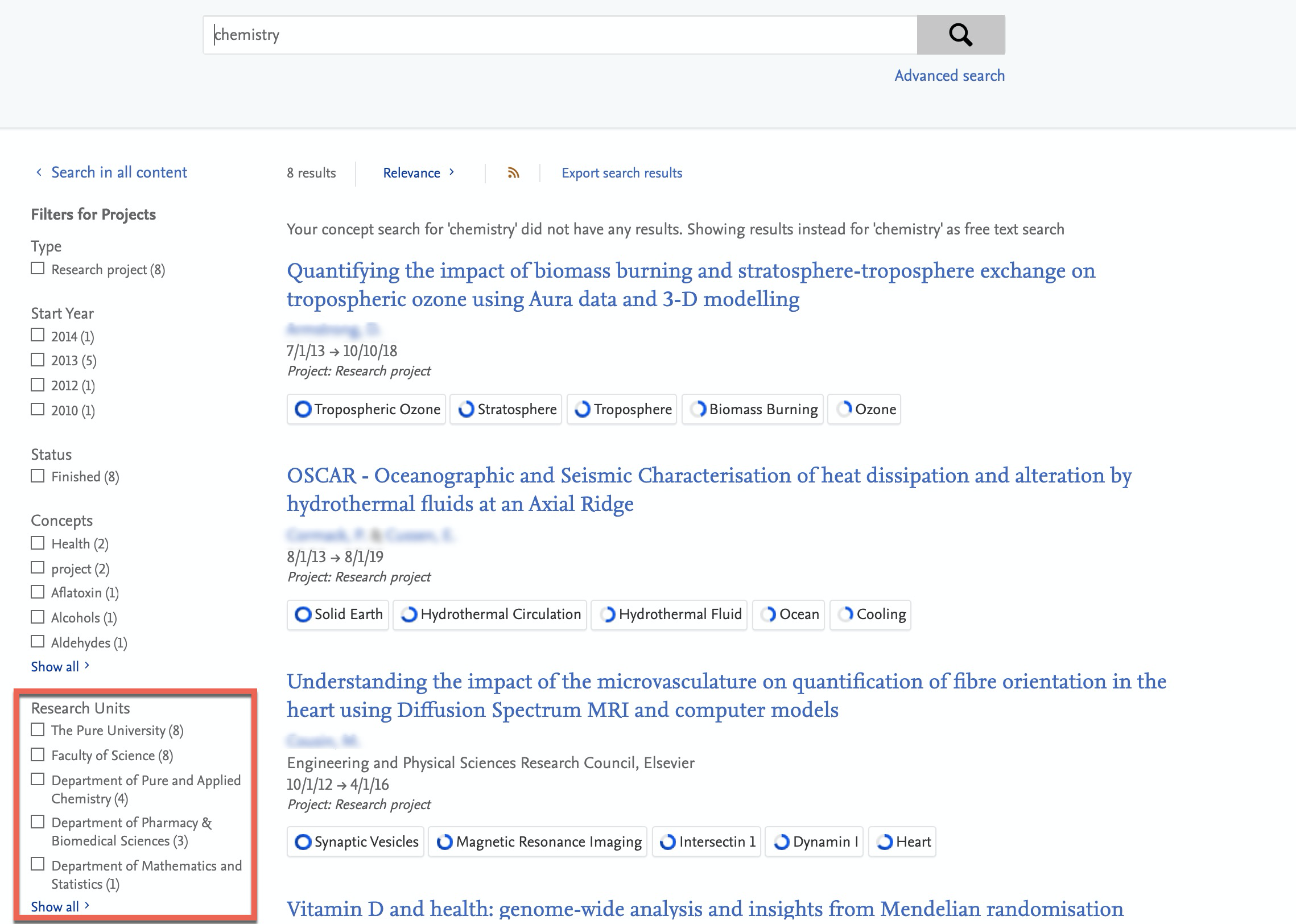
The Research Unit filter was previously only available on Research Outputs. It is now available on all the following content types:
- Persons
- Projects
- Activities
- Facilities/Equipment
- Datasets
- Prizes
- Press Media
- Student Projects
- Student Theses
8.2. Limit your Portal to only show specific Organization types and/or only parts of the hierarchy
It is now possible to have greater control of what data you are exposing on your Portal. We have added two new configuration options to help you manage this. You can now:
- Only include data associated to parts of your hierarchy.
- Only show Organizations of a certain type.
Both of these options can only be configured by Elsevier Support, so please reach out directly to our Support Team.
Click here for more details...
Below are some examples of how these options can influence your content on the Portal. Note that the screenshots show the Administrator tab and not Portal, but that is to clearly illustrate the types.
Instructions |
Screenshot |
|---|---|
|
As an example, here is a simple organization hierarchy. In the example, hierarchy, you might not want to highlight the 'Partners' part on your Portal. Previously, you only had the option to set the visibility of this Organizational Unit to 'Backend', or mark the unit as 'Former'. Neither option was ideal, as visibility settings affect what is exposed in the API, and marking a unit as 'Former' means introducing inaccurate data. |
|
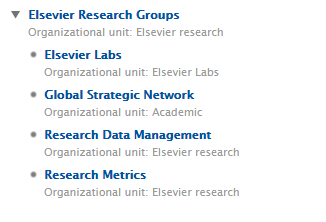
1. Only include data associated to parts of your hierarchy. Now it is possible to create a hierarchy filter to limit what is shown on the Portal without affecting any other functionalities in Pure. In the example, a filter was created to only include Organizational Units that are part of the Elsevier Research Groups. As a result, only content associated to an Organizational Unit within Elsevier Research Group will now be available on the Portal. Note: This filter can be applied to all content types associated to organizations. For example, if a Research Output was only associated to the 'Partners' Organizational Unit, it would not be exposed either. |
|
2. Only show Organizations of a certain type. You can also limit your hierarchy to certain Organization types. In this example, you may want to only include Elsevier Research and Academic as allowed Organization types. Note: This filter can only be applied to Organizations. For example, if a Research Output was only associated to Elsevier Labs (so an Organization type excluded from the filter), it would still be shown on the Portal but without any reference to the Organizational Unit (Elsevier Labs). |
|


8.3. Web of Science (WoS) citations can now be showcased in the Portal
Due to an updated agreement with Clarivate, we are now allowed to showcase Web of Science (WoS) citations in the Pure Portal.
Note: If you have multiple citations providers enabled, we will still only show citations from one provider on a specific piece of Research Output.
Click here for more details…
Information |
Screenshot |
|---|---|
|
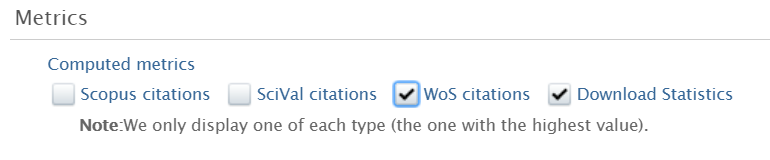
Setting available to user role: Administrator When configuring what metrics to show on Research Outputs, you can now also select 'WoS citations'. It is possible to enable all the citation providers, but only the provider with the highest citation count will be shown for a given Research Output. Note: This will republish all outputs to the portal, so it might take some time to be visible on all outputs. It is recommended to select the same same metrics providers for persons, where WoS is also available as citation and h-index as part of this update. |
|
|
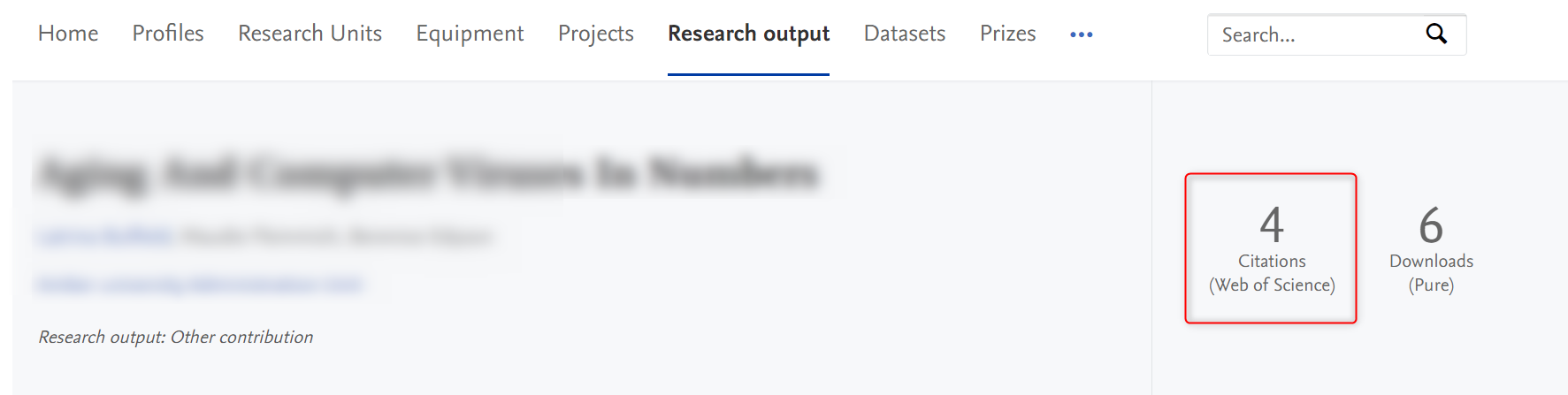
Visibility: Anonymous visitor to the Portal If WoS citations are enabled, they will be shown in the Portal where we normally show citations. |
|
9. Country-specific features
9.1. AU: ERA
9.1.1. Wide preview of FoR, and SEO % in Reporting
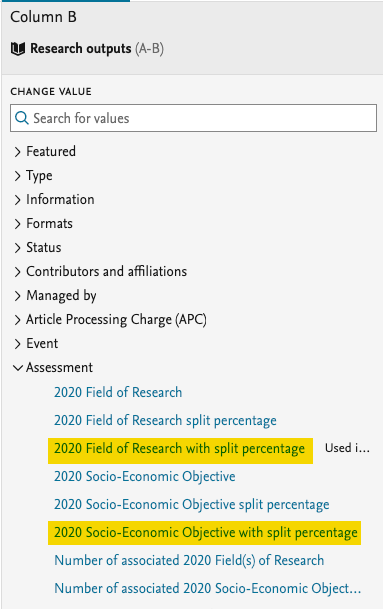
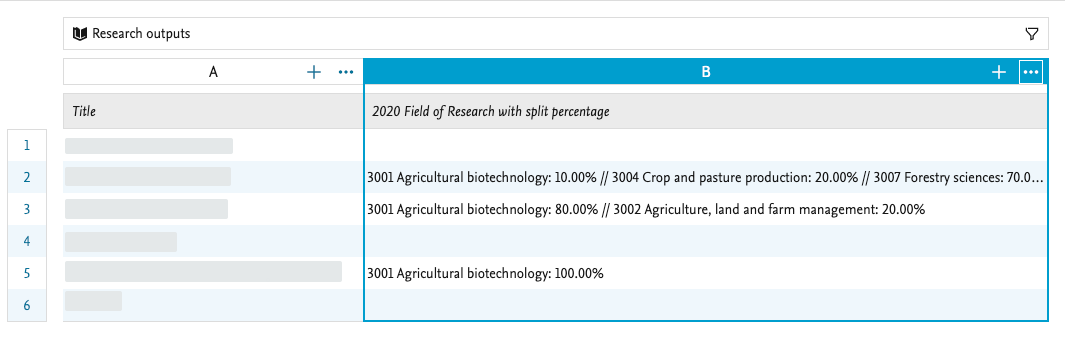
It is now possible to use the FoR and SEO in a wide preview mode in the Reporting module. We have added new values called: 2020 Field of Research with split percentage and 2020 Socio-Economic Objective with split percentage. It is possible to view the columns with these values in wide preview to see the pairs of FoR codes and split percentages so that you can create a report of the FoR codes, and their corresponding split percentages.
Click here for more details...
 |
 |
9.1.2. Job for correcting Field of Research associations on records
Prior to 5.21.0, it was possible to add more than three 2020 Fields of Research to records. In 5.21.0, the limit was set to three, but this may have potentially left some records in an invalid state (these records cannot then be saved). We have now introduced a job that fixes such records. When booting 5.22.0 (or 5.21.4), the job will run automatically and clean the content to make sure that there are no longer any records in invalid state.
Click here for more details...
If there are more than three FoR codes on any piece of content, the job will remove all but the first three FoR codes. The resulting split % will be 33.33 for the remaining three codes on the content. We log any changes to content in the job log, so that you can always double-check the changes and make necessary adjustments. The log will contain information about the ID of the changed content, as well as what the discipline assignment was before then change with split percentages, and then what the content looks like after the change.
The job log can be found in Administrator > Jobs > Job log (find and expand 'anzsrcCleanupForsLoggingJobCallableFactory').
Published at March 25, 2025