
How Can We Help?
5.23.05.23.0
Highlights of this release
![]() Scheduled sharing of reports
Scheduled sharing of reports
Pure now supports scheduled sharing of snapshots of data stories with named users. Pure will automatically create a data story snapshot at the time specified by the user. The recipients (named users) will get a notification that a snapshot has been shared with them, and the link in the notification will bring them to the newly designed overview of data snapshots available to them. There, users can preview the shared data story and access and compare older versions of the same data snapshot.
 SFX integration
SFX integration
The SFX link resolver and collection management service is now available for use on the portal. It is now possible to set up an integration with SFX so that an SFX link to the full text will be added to all publications with the status of 'E-pub ahead of print' or 'Published'. SFX provides a direct route to electronic full-text records through an OpenURL. The SFX link also provides further resource discovery with access to journals and much more.
 User and Research output endpoints now available in Pure API
User and Research output endpoints now available in Pure API
The Pure API now supports the management of Users and Research outputs. CRUD operations on each of the content types are now available, with specific use cases targeted in this release. These endpoints were released in 5.22.2, with full mention of use cases and options provided in this release.
Watch the 5.23 New & Noteworthy seminar
Fingerprint Engine URL update for customers on Pure 5.22.3 and older – ACTION NEEDED
The Fingerprint Engine has recently been moved to a new location. By the end of February 2022, the old location will no longer be supported.
If you have an automatic Pure version update procedure enabled, you do not need to do anything: the latest version (5.23.0) will use the new URL of the service.
If you are using Pure versions 5.22.3 and older and are unable to upgrade to a newer version of Pure before the end of February 2022, please contact Pure Support Team on Jira or by e-mail pure-support@elsevier.com to enable the new URL on your running Pure instance.
- Customers running Pure version 5.21.0 through to 5.22.3: Please contact our Support Team who can help you add support for the new location without the upgrade to 5.23.0 or newer.
- Customers running Pure version older than 5.21.0: Unfortunately, these versions do not support Fingerprint Engine v.8.1 and would not be able to connect to the new location. To continue receiving updates for the Fingerprint service, please update to at least v 5.21.0 and then contact our Support Team for assistance.
Please note that by the end of February 2022, the old location will no longer be supported. If you chose not to upgrade, your existing fingerprints will remain in place but you will not be able to receive any new/updated fingerprints after 1st of March 2022. Pure strongly recommends upgrading your system to v. 5.21.0 or newer to continue benefitting from the Fingerprint functionality.
We are pleased to announce that version 5.23.0 (4.42.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 7 February 2022
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 9 February 2022 (APAC + Europe) and 10 February 2022 (North/South America).
- Production environments (including hosted Pure Portal) will be updated 23 February 2022 (APAC + Europe) and 24 February 2022 (North/South America).
Advance Notice
The Pure API will soon introduce breaking changes. If you have integrations using the API, it is highly recommended to read details here
Advance Notice
The Fingerprint Engine will go through a major content update in 5.24.0. Read details here
Download the 5.23.0 Release Notes
last updated 7 February 2022
1. Pure Core: Administration
1.1. External organization editor update: alternative names
Information |
Screenshot |
|---|---|
Alternative names for external organizations can now be easily viewed and removed. A conveniently placed 'Delete' button is now available for each alternative name, and users can hover over any name to easily view the full name. |
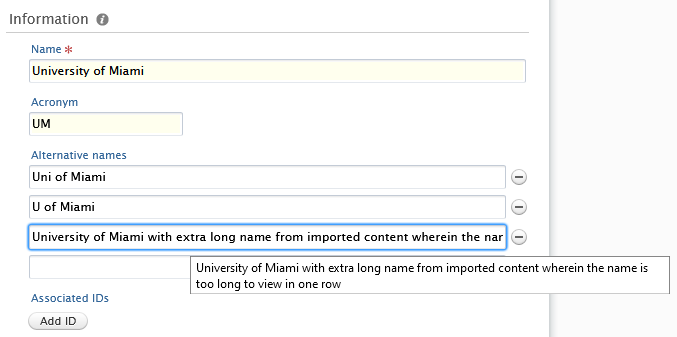 |
1.2. Data Quality: further enhancements
This release brings extensive updates to the design and functionality of the Data Quality interface. The major updates and improvements include filtering groups by organization type, as well as source IDs and matching rationale now provided for each entity. You can find detailed instructions on how to use the Data Quality interface in the 5.22.0 release notes.
Job renamed
The cron job that creates duplicate groups listed in the Data Quality interface, Duplicate External Organization Discovery, has been renamed to Duplicate Content Discovery to allowthe inclusion of more content types in the future.
Job scheduling and processing has also been made more efficient and the job can be run once every minute rather than once per day.
1.2.1. Filter groups by organization type
You can now narrow down the list of duplicate groups by applying the external organization type filter.
Click here for more details...
To both select and deselect the filter, click on the funnel next to the search bar above the group list. Select (or deselect) desired type(s) to view only the groups that contain external organizations of those type(s).
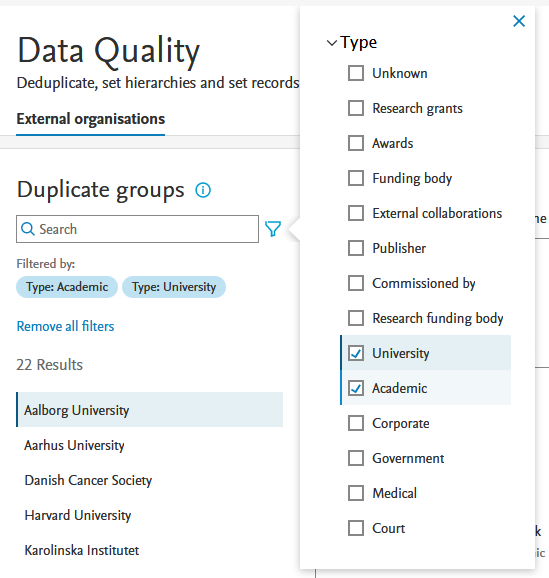
1.2.2. Synchronized source ID available on hover
Synchronization source name and IDs are now shown when hovering over the sync symbol in the entity list.

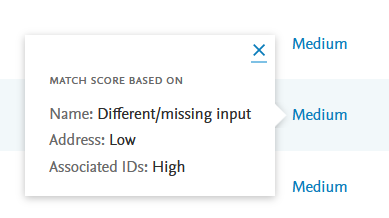
1.2.3. Match score rationale provided for candidate entities
The candidate-to-target match score rationale has been updated to provide more context to the match score. Details are provided for the name (including alternative names), address and and associated IDs. Users can click on the match score to view the per field rationale.
1.3. Password reset available on login screen
This functionality was introduced in a minor release (5.22.2).
Clients who use the login screen as an alternative or supplement to single sign-on, can now allow users to reset their password if they have forgotten it. Previously, only a logged-in user could request a password reset for another user from within Pure. The same option can now be made available to unauthenticated users on the login screen.
Note: If you are using a single sign-on system to authenticate your users against your Pure instance, it is not recommended to enable this feature, as it does not support externally authenticated users.
Click here for more details…
Information |
Screenshot |
||
|---|---|---|---|
Enabling password policy To enable this feature, you first need to enable password policy for your Pure instance in Administrator > Security > Password policy. We recommend setting up a policy in line with your security standards. See 5.10.0 Password Policy & Password Reset to find out more about the password policy feature. |
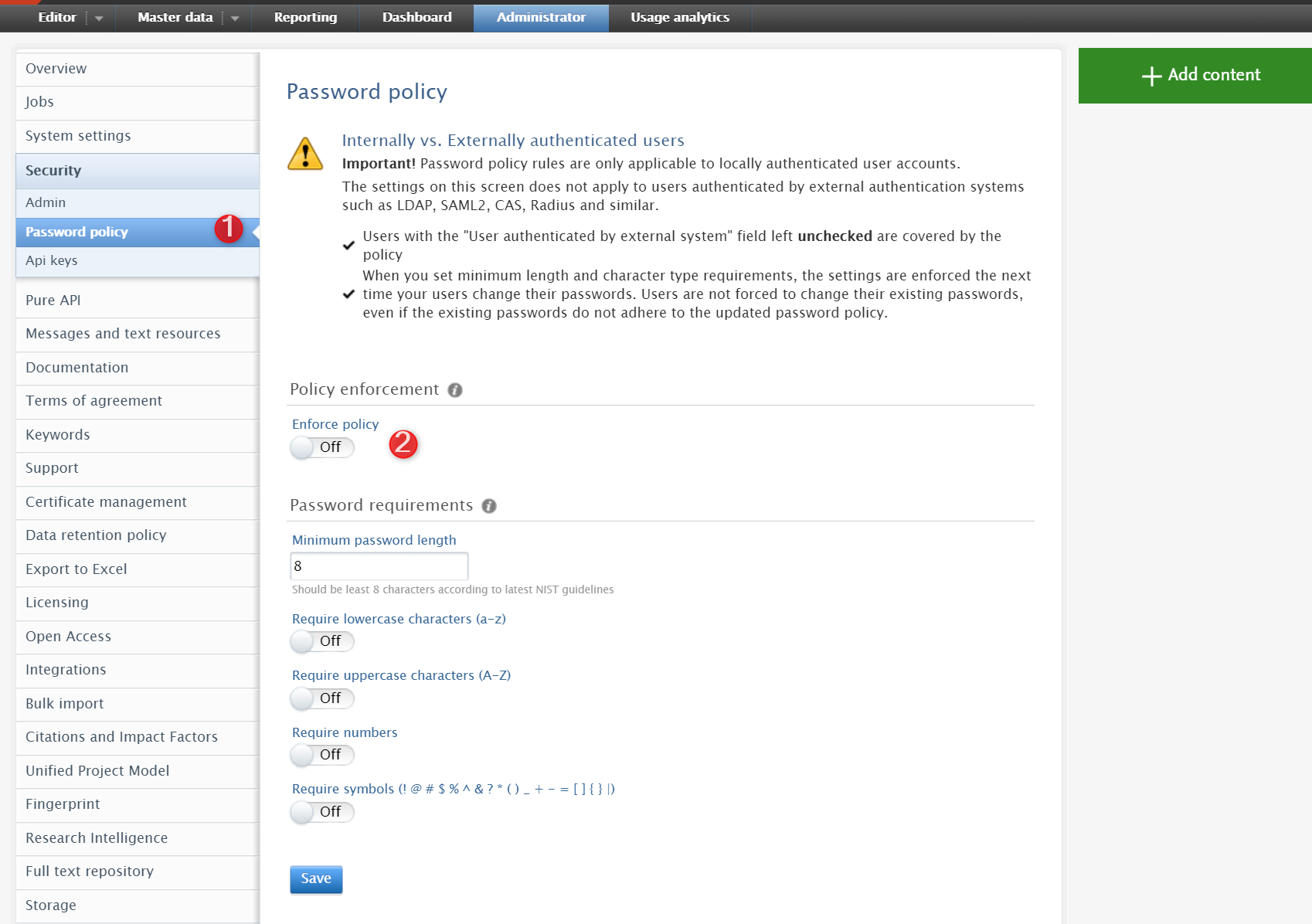 |
||
|
Enabling password reset ('Forgot password?') Once the password policy is enabled, you will see the option to enable the 'Forgot password' feature at the bottom of the 'Policy enforcement' section. Enable the feature and save your settings. |
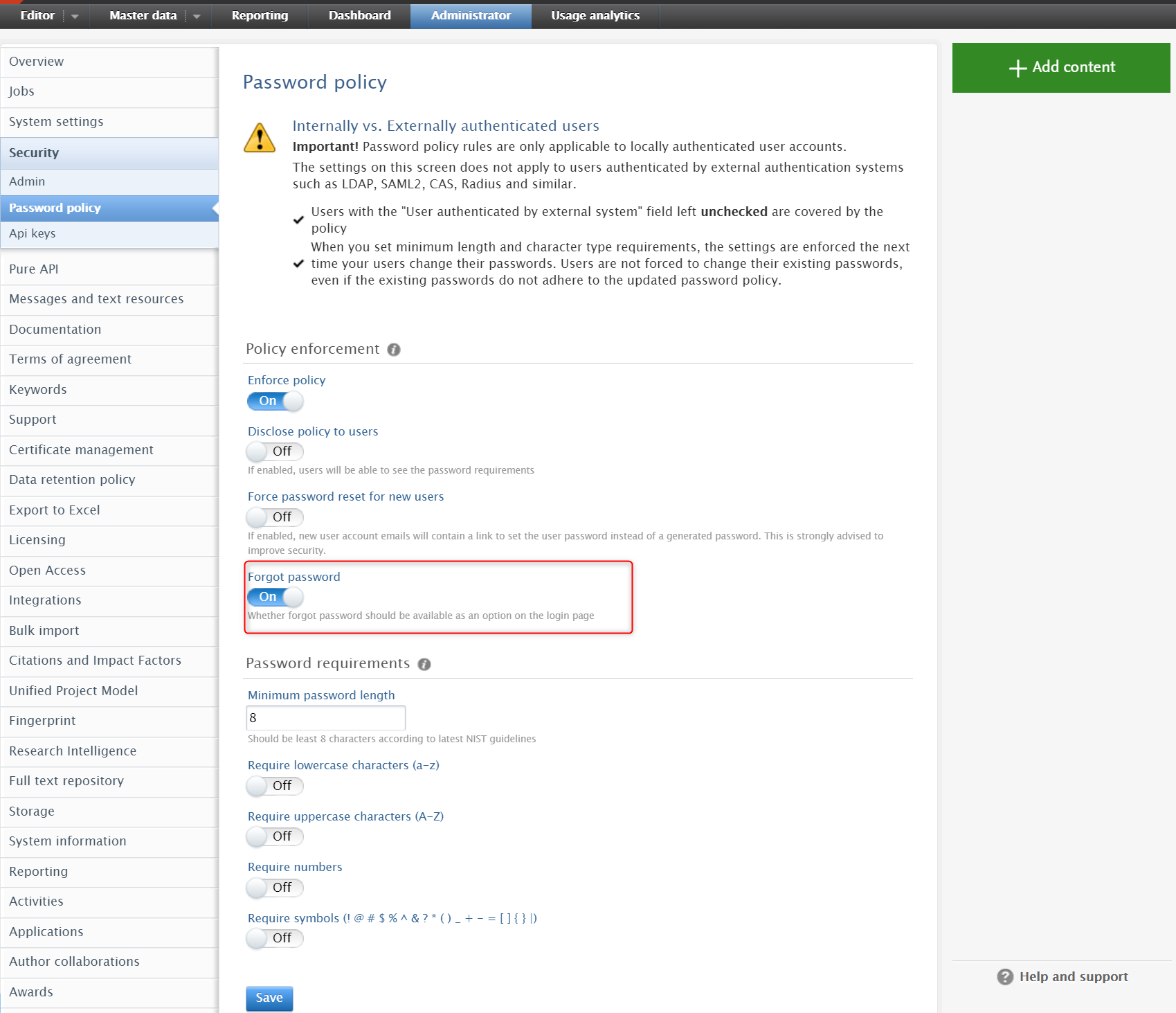 |
||
|
Accessing the feature When the feature is enabled, the users logging into Pure via the login screen can see a Forgot Password? hyperlink. |
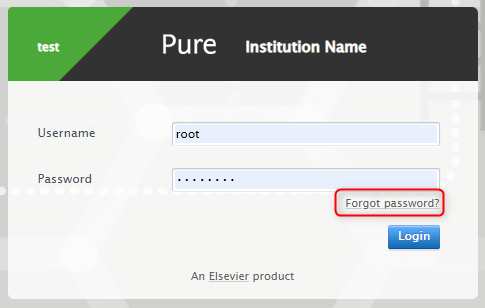 |
||
|
How it works When the user selects the option, they are taken to the next screen, where they are asked to enter either their username or email. They then receive an email with further instructions. This email and following flow is the same as the original feature described in 5.10.0 Password Policy & Password Reset. |
|
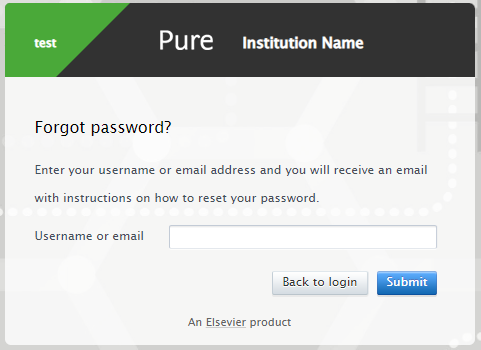
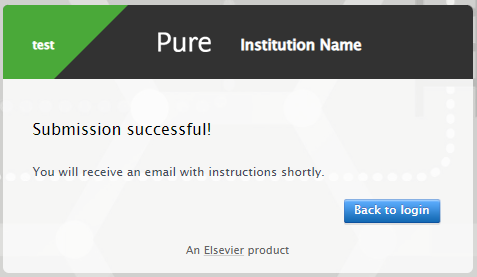
1.4. Automatic deduplication
As part of the 5.22.0 release, we implemented deduplication as a feature on many more content types (see 5.22.0 release notes section: Deduplication available on more content types).
Following a period of customer testing, we are now pleased to also make this extended deduplication feature available as scheduled cron jobs per content type.
This feature was originally defined to support the needs of our Pure Community Customers and is a powerful means to:
- process and merge content without a need for manual intervention and
- resolve duplicate issues in bulk.
The automatic deduplication process is applied based on a set of rules that identify and validate candidates prior to deduplication and merging. The rules are listed on the Automated Deduplication Job page.
Due to the potential high impact of running auto-deduplication jobs, we have made them available to customers on request only. Please contact Pure Support for further information.
2. Pure Core: Pure Web Service and Pure API
Pure Web Service is the read-only service available to all clients. See Administrator > Web services for more details.
Pure API is the read-and-write service currently under development and available to clients through the Early Access Program. See Administrator > Pure API for more details.
2.1. Pure API: Upcoming breaking changes
During our reviews of the current status of the Pure API, we have identified some areas we would like to improve. This will result in breaking changes in the API, so be sure to update your integrations when available.
- The contributors field on research output will support three types instead of just one. This is to make it clear for the API user what fields are available/required, based on what type of contributor they are adding, i.e. internal person, external person, or an author collaboration.
- Organizations are sometimes spelled with an 's', both in the field and in the documentation. We will update this to be consistently spelled with a 'z'. This is to be compliant with Elsevier API standards.
We expect to introduce these changes in one of the upcoming minor releases or 5.24.0, and will provide a detailed explanation of the concrete changes in the relevant release notes.
2.2. Pure API: User endpoint now available
This functionality was introduced in a minor release (5.22.2).
Pure API now supports the management of Users. CRUD operations on the User content type are now available.
Use cases catered for in the current release:
- Synchronize externally managed user data with Pure so that end-users can use existing single sign-on infrastructure to sign in to Pure. In this case, users are externally authenticated.
- Synchronize externally managed user data with Pure so that end-users can sign in to Pure without requiring single sign-on infrastructure. In this case, users are authenticated by Pure.
Note: It is possible to combine the User and Person endpoints to grant Persons the personal user role.
Assigned roles cannot be managed yet, but we are planning to make that possible in the upcoming release (5.24.0).
A password reset feature ('Forgot password?') was also added in this release. For further details, refer to Password reset available on login screen and Pure API: Reset user password via API.
You can get more information the API (supported fields and more) by upgrading Pure and accessing the Swagger UI available at:
https://{your Pure hostname}/ws/api/api-docs/index.html |
Shortly, you will also be able to experiment with the user endpoint using the Pure API sandbox.
2.3. Pure API: Reset user password via API
To expand on the use cases supported by the API, it is now possible to reset password for users through the API.
Note: The underlying functionality and limitations are the same as described in Forgot password available on login screen.
Click here for more details...
The feature is available as a POST action using the following endpoint:
https://{your Pure hostname}/ws/api/users/{uuid}/actions/reset-passwordThe selected user will receive an email with a link to update the password. The link will be valid for 24 hours.
After 24 hours, a new email must be sent with a new reset password token, either through the API or using the 'Forgot password' option on the login screen.
It is possible to specify a different expiry period using the query parameter tokenExpiryHours.
2.4. Pure API: Research output endpoints now available
This functionality was introduced in a minor release (5.22.2).
Pure API now supports the management of Research outputs. CRUD operations on the Research output content type are now available.
All metadata fields on Research outputs have been introduced, except for relations to other editorial content types.
Use cases catered for in the current release:
- Research output legacy import - as an alternative to the current bulk upload functionality
- Enrichment existing Research outputs with additional metadata
- Full extraction of all Research outputs in a Pure installation, including confidential content, using Access Definitions introduced in 5.22.0
If your Research output use case is not covered by this implementation, we would like to hear from you and add it to Use cases.
Click tips and tricks...
Helper endpoints
In Pure API, each content type has a set of helper endpoints which are used to retrieve information about what possible values can be used or expected from different fields when this is not predetermined and available in the schema. These are typically values for a given classification scheme.
The Research output endpoint also contains helper endpoints due to the amount of configurable fields available on that content type. These are all the endpoints starting with allowed-.
Template control
It is possible to control what templates are enabled in a given Pure installation, which is configured under Administrator > Research Outputs > Types. To find out what templates are enabled/allowed, refer to the allowed-templates endpoint:
https://{your Pure hostname}/ws/api/research-outputs/allowed-templatesThis returns a name and a description field for all enabled templates in the given Pure installation.
The name corresponds to the typeDiscriminator field on a piece of Research output, which determines the template, and therefore also what fields are available, e.g. ContributionToJournal.
Different templates also have unique allowed endpoints to get available values for the given template:
https://{your Pure hostname}/ws/api/research-outputs/allowed-contribution-to-journal-contributor-rolesThe above endpoint returns allowed contributor roles for the template Contribution to Journal (e.g. Author, Editor, etc.).
2.5. Pure API: Disciplines (ANZSRC Module)
This functionality was introduced in a minor release (5.22.2).
We have added a new generic concept to the API called disciplines.
Disciplines is a generic concept which is available as an option on all endpoints. It can be used to retrieve additional information about different discipline schemes and content associated to these disciplines.
The API now supports the following disciplines (ANZSRC module needs to be enabled):
- Fields of Research (for)
- Socio-Economic Objectives (seo)
- Types of Activity (toa)
The intention is to add more disciplines over time and perhaps also support for managing your own disciplines.
Click here for more details…
As this is a generic functionality, all content types have discipline endpoints added. Here, we use Research output as an example.
First, retrieve which discipline schemes are available for the content type by invoking:
https://{your Pure hostname}/ws/api/research-outputs/disciplines/allowed-discipline-schemesIf the ANZSRC module is enabled, this will return:
{ "count": 2, "items": [ { "disciplineScheme": "for", "title": "Fields of Research" }, { "disciplineScheme": "seo", "title": "Socio-Economic Objectives" } ]}To find out which values are available for a given discipline scheme, invoke the endpoint /research-outputs/disciplines/{discipline-scheme}/allowed-disciplines with one of the disciplineSchemes retrieved earlier. For example:
https://{your Pure hostname}/ws/api/research-outputs/disciplines/for/allowed-disciplinesBulk-retrieve disciplines
To retrieve information about what disciplines are assigned to one or more Research outputs, invoke the endpoint /research-outputs/disciplines/{discipline-scheme}/search with the UUIDs of the Research outputs to retrieve disciplines for.
You can supply multiple UUIDs to retrieve discipline values for multiple Research outputs in one call. This is performed as a POST operation, so an example could be the following:
https://{your Pure hostname}/ws/api/research-outputs/disciplines/for/searchPOST:{ "uuids": [ "05652022-578e-4e0d-b327-f4a5152da2ce", "97085e4b-1fe4-42d7-81e3-dfe1dacf1f58" ]}You will then retrieve the discipline assignments within the discipline scheme for the provided Research outputs. You will retrieve the discipline ID and the split percentage: the discipline ID corresponds to the IDs returned by the corresponding endpoint /research-outputs/disciplines/for/allowed-disciplines.
The request is paginated and the default page size is 10, so if you supply more than 10 UUIDs, you need to increase the page size or make multiple calls.
It is possible to omit the UUIDs and just paginate through the content to retrieve all content with the associated disciplines:
https://{your Pure hostname}/ws/api/research-outputs/disciplines/for/searchPOST:{ "size": 10, "offset": 0}Continue calling the endpoint with the offset increased by the page size to retrieve all FOR disciplines for all Research outputs in your Pure instance.
Retrieve and update disciplines for a single piece of content
To get disciplines for a single piece of content the following GET endpoint has been added:
https://{your Pure hostname}/ws/api/research-outputs/{uuid}/disciplines/{discipline-scheme}The response is similar to the POST/search operation described above for bulk-retrieve.
The same endpoint has been added as a PUT operation for updating the disciplines for a piece of content. Similar to other PUT operations in the Pure API, the format is the same as the result from a GET call.
2.6. Pure API: Hierarchy on External organizations
The External organization model was updated as part of the 5.20.0 release to include information on hierarchy and organization takeover ('Taken over by'). See 5.20.0 release notes for more details.
This information is now exposed in the Pure API for External organizations and can also be updated through the API.
Click to see example output
This is an example of how the output could look like when these fields are filled out. As always, the same format is used to update the fields:
"takenOverBy": { "externalOrganizationRef": { "systemName": "ExternalOrganization", "uuid": "a76f32dc-1881-4105-af1c-79fce92855b8" }},"lifecycle": { "startDate": "2022-01-01", "endDate": "2022-01-06"},"parent": { "systemName": "ExternalOrganization", "uuid": "a76f32dc-1881-4105-af1c-79fce92855b8"}3. Integrations
3.1. Import candidate model redesign
In order to be able to provide better filtering and search for import candidates in the future, the underlying model/framework for import candidate management has been redesigned. Previously, import candidates were stored on the file system. With this release, the data has been moved to the database to provide more flexibility and better performance.
Click here for more details…
Note for self-hosted clients: Before booting 5.23.0 for the first time, you can run the following SQL script on your Pure database in order to check how much free space is needed:
select sum(f.sizelong)
from import_result ir
inner join files f on ir.file_id = f.id;
When booting 5.23.0 for the first time, a job (importCandidatesMigrationJobCallableFactory) is scheduled that will migrate your existing import candidates from the filesystem and into the database. You will not be able to see all your import candidates until the job has finished, but the job will gradually add existing import candidates for enabled import sources.
Note: Existing import candidates from Data Monitor will not be migrated but will be created again by the Data Monitor job.
Note: Existing import candidates from Bibliotek.dk and CiNii will not be migrated but will be continuously created again by the Search for Import Candidates job.
3.2. Data Monitor: upgrade to version 3
The Data Monitor integration has been upgraded from version 2 to version 3. The new version contains new information for some datasets:
- Geolocation
- Rights
- Date of data production
- Date made available
4. Unified Project Model and Award Management
4.1. Award Management: update on upcoming changes
Work continues on changes needed to support our new workflow management implementation and on underlying changes required to enable Milestone implementation on award management content types (for AMM customers only). This substantial package of changes is at an advanced stage but is still mostly 'under the hood' at this point in the development cycle. We will continue to refine these together with with our award management community in the coming months ahead of our proposed launch in version 5.24. Please feel free to contact the AMM product manager (James Toon) for further information or to provide feedback into user testing.
In addition to the underlying development described above, we continue to work on system stability and to resolve defects as they arise. Please review the Resolved Issues section of the release notes for further information.
4.2. Award Management: Milestone overview screen and filter updates
As a continuation of our work to extend and improve the use of milestones, we have made a few updates to the milestone overview screen by making a clear distinction between milestones that have been allocated a responsible user and those that are allocated based on their responsible role type alone.
|
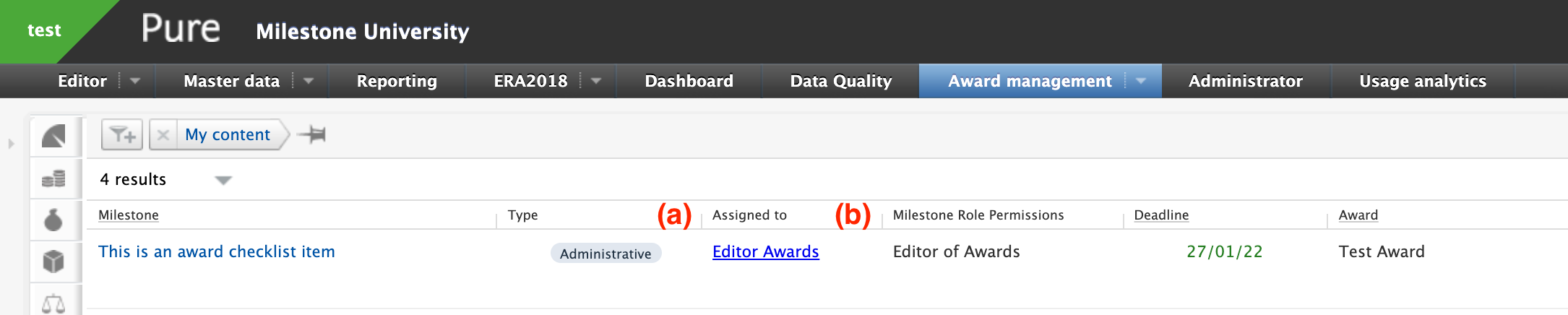 |
We have also included a further two filter options into the overview, so that it is possible to narrow down the list either based on the existence of responsible users, or by individual awards.
|
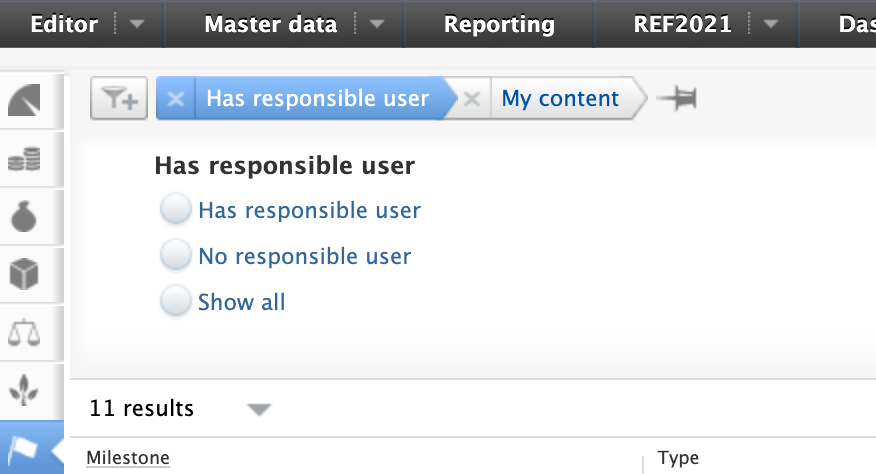 |
|
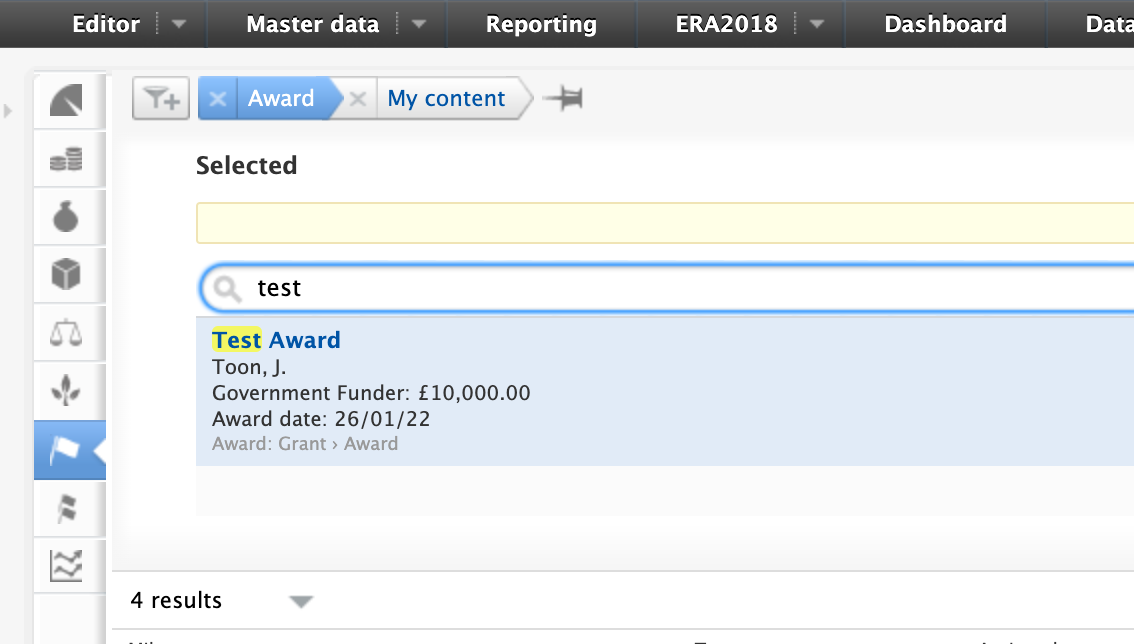 |
5. Pure Portal
5.1. SFX support added
It is now possible to set up an integration with SFX so that an SFX link to the full text will be added to all publications with the status of 'E-pub ahead of print' or 'Published'.
The SFX link resolver is a linking service and a collection management tool. It provides a direct route to electronic full-text records through an OpenURL. The SFX link also provides further resource discovery with access to journals and much more. The SFX can be launched as an Ex Libris-hosted, or a locally hosted system. Linking capabilities can be easily embedded into any OpenURL-compliant source. This could be discovery platforms, a library portal, or Google Scholar, just to name a few.
In other words, the SFX link provides the information on the electronic availability of an item. It can be used to link directly to a full-text, to find journals, and to take advantage of other library services.
Click here for more details…
Information |
Screenshot |
|---|---|
|
Enabling the SFX link resolver
Note: As mentioned in the help text, research outputs will be republished when a URL is first entered or updated. |
 |
|
Accessing the feature Users visiting the Portal will see an SFX link together with other links for the research output. This will be shown for all research outputs with the status of 'E-pub ahead of print' or 'Published'. |
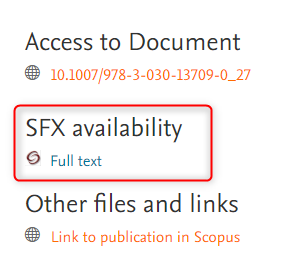 |
5.2. Export of search results available and configurable
It is now possible to allow visitors to your Portal to export a search result to a file containing a list of UUIDs. The list is formatted in such a way that it can be used as a filter in the reporting module. See this section for further details
This feature is disabled by default.
Note: We have also added the option to disable the existing export functionality, so that now both Excel and UUID list exports can be either enabled or disabled.
Click here for more details...
Information |
Screenshot |
|---|---|
|
Enabling export of UUIDs
Right now this is available for Organizations and Persons, but might be expanded to more content types later. They all follow the same configuration option. Note: "Export of search result to Excel" is enabled by default, as this is the existing feature (Export search results) introduced in 5.18.0. This feature can now be disabled. |
|
|
Accessing the feature Users visiting the portal will see an option to export the UUIDs on the search result pages for Profiles and Research units. Note: Only the first 2,000 results will be included. |
|


5.3. Fingerprint Engine – important fingerprint concept update in June 2022
Pure and Elsevier teams continue to work on enhancing the Fingerprint engine. From June 2022, the technology behind the fingerprint is changing, making the terms used clearer and the fingerprint itself more compact and easy to use. As a result of this, we expect the existing fingerprints to change noticeably and would like to make sure that our customers are comfortable with this change.
In view of the above, we are calling on customers currently using the Fingerprint functionality to participate in the new fingerprint testing. Customers who wish to take part will be able to view the updated fingerprint for their research outputs, persons and organisations and compare it to the current one. Your feedback will be instrumental in ensuring the necessary level of quality of the updated service.
Please contact Irina Bischof (i.bischof@elsevier.com) if you would like to participate in the testing or have any questions about the forthcoming changes.
6. Reporting
6.1. Scheduled sharing of data story snapshots
Language availability
Currently, snapshot scheduling is fully available in English only. This means that clients using Pure in languages other than English will see text related to this feature in English also when switched to another interface language. We apologize for this temporary inconvenience and are working on providing full availability of features in all supported languages.
New term
A data story snapshot is a copy of a data story as it was in a given moment in time (when snapshot was taken). Data story snapshots are saved in Pure, and can be shared with other users.
This release brings one of the most sought-after additions to the reporting module: scheduled sharing of data stories.
You can now set up a schedule for sharing snapshots of data stories with named users. Pure will automatically create a data story snapshot at the time specified by you. The recipients (named users) will get a notification that a snapshot has been shared with them, and the link in the notification will bring them to the newly designed overview of data snapshots available to them. There, users can preview the shared data story and access older versions of the same data snapshot, which makes comparison between the snapshots really easy. They can also print/export data story snapshots to a PDF if this is required.
The snapshots are stored in Pure and you will be able to see who they are shared with, how often they are viewed, and by whom. This usage statistics can be useful when maintaining your shared workspaces. You will also be able to stop sharing specific versions of the data story, or all versions (if needed). Snapshot scheduling provides a lot of flexibility to configure the frequency, user access, and much more.
Click here for more details…
| In order to schedule snapshots, you need to first create a data story and save your workspace. | 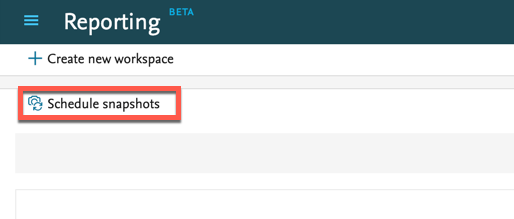 |
|
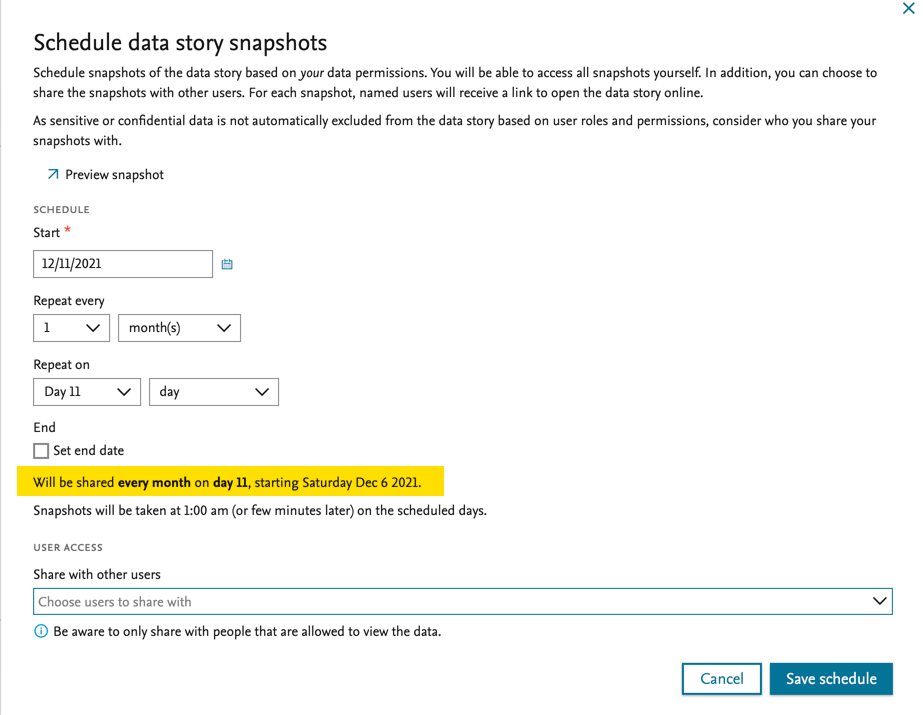
Select 'Schedule snapshot' to configure the schedule and specify which users should have access to the data snapshot. As there are many options related to the schedule, we have added an auto-generated text summary at the bottom of the screen to help you validate your schedule configuration (see screenshot). The recipients of the data story snapshot will see exactly the same content as the owner of the workspace. All snapshots will be created in the context of the user owning the workspace. |
 |
| It is possible to specify which users should have access to the data story snapshot. It is also possible to see a preview of what the users will see when they access the snapshot. | 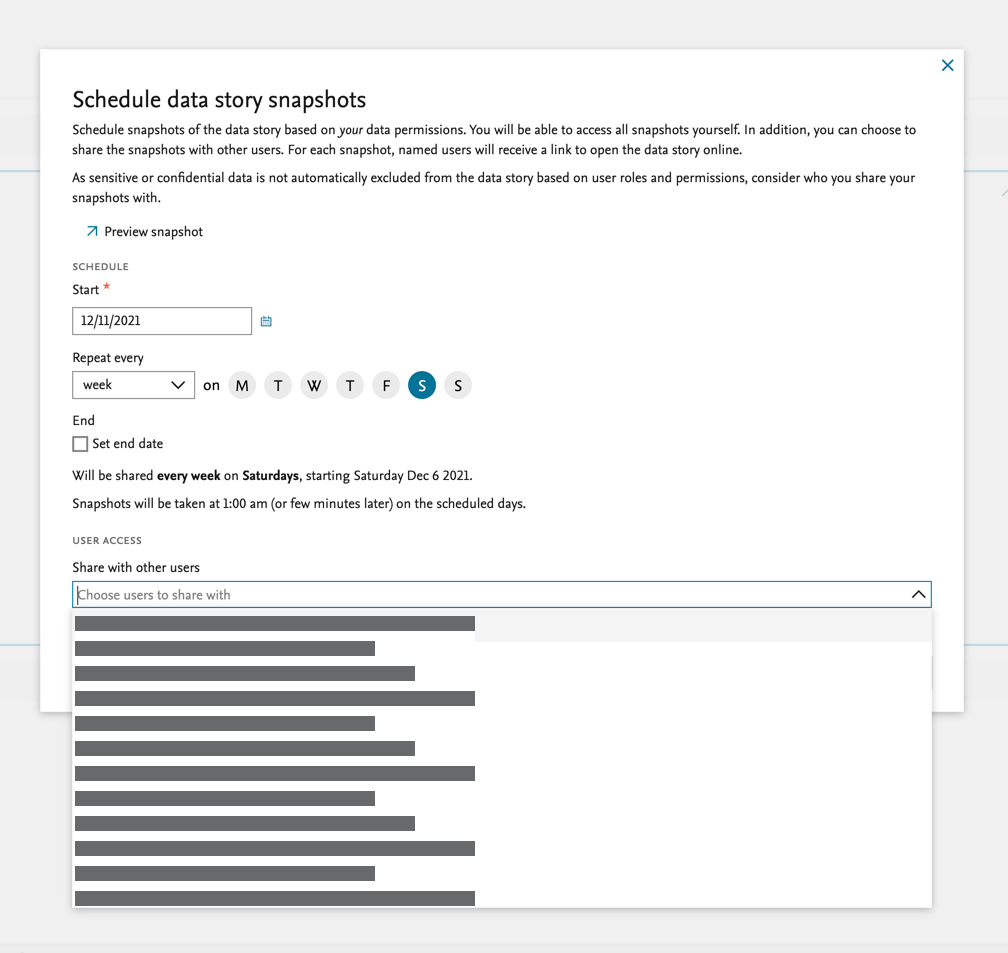 |
| If snapshots have been scheduled for a particular data story, it is indicated with a badge ('Snapshot scheduled'). It is possible to change the schedule, and to view and compare all previous snapshots on the new data story overview page. | 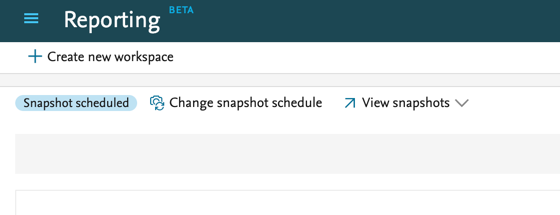 |
| The new overview page shows all scheduled workspaces with information about who they were shared with, how often they have been viewed, and by whom. This is useful feedback to consider when managing workspaces and can help decide which ones to rework or remove. | 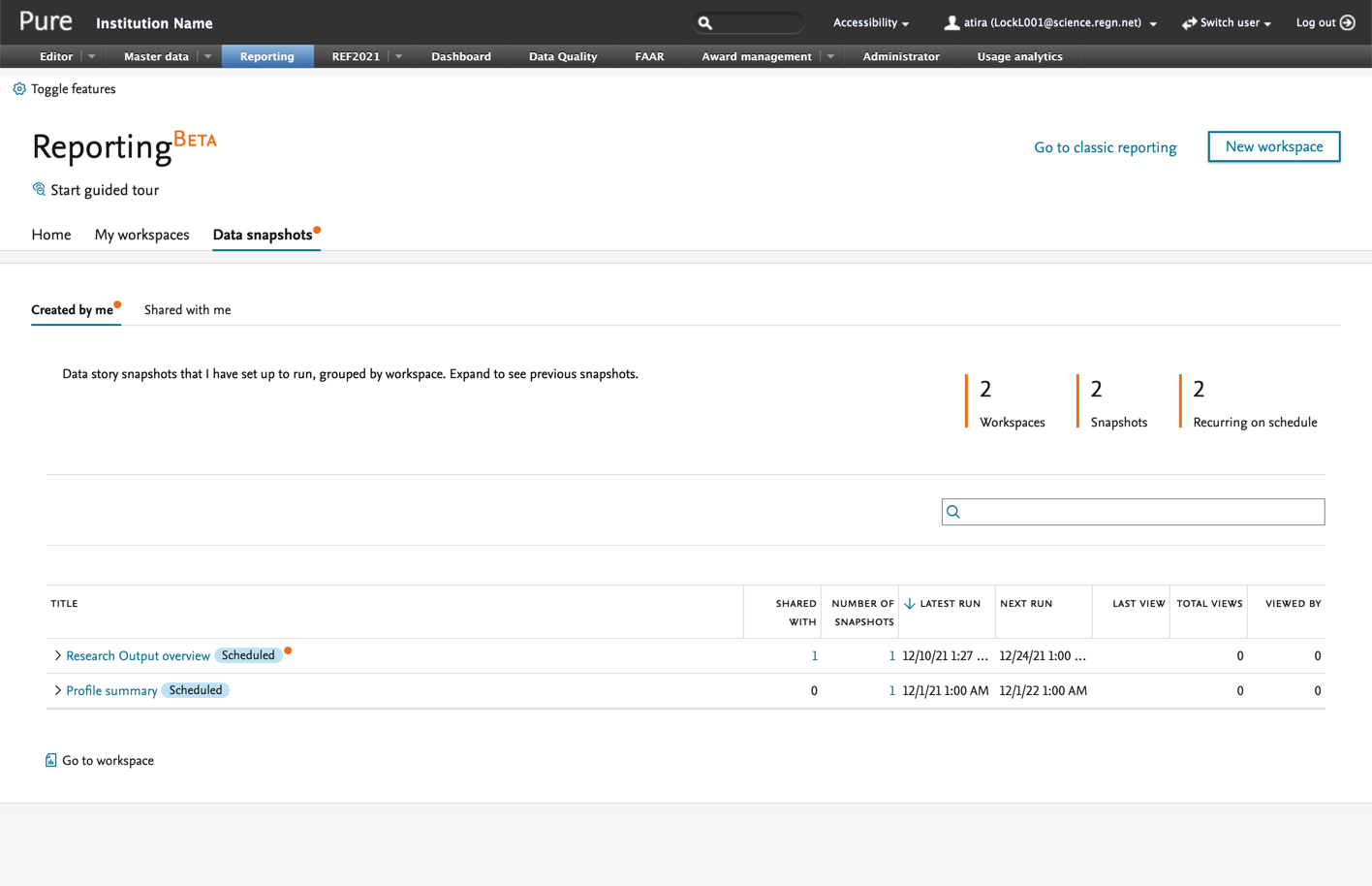 |
| Together with the data story snapshots, we have introduced a new preview mode for the data stories. You can quickly preview the data story when scheduling a snapshot share: this lets you see exactly what the recipients of the snapshots will see. When there are already multiple snapshots available for a given data story, you can pick a particular snapshot from the dropdown list to preview it. |
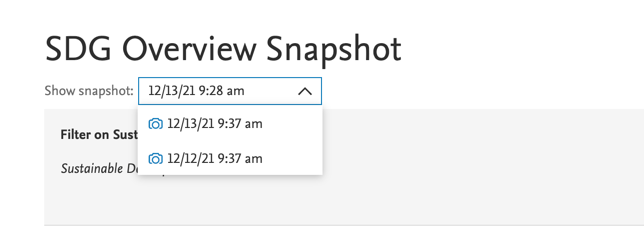 |
| Data stories are now also formatted and easy to print to PDF. You can print the data story from both the preview and the traditional data story view. | 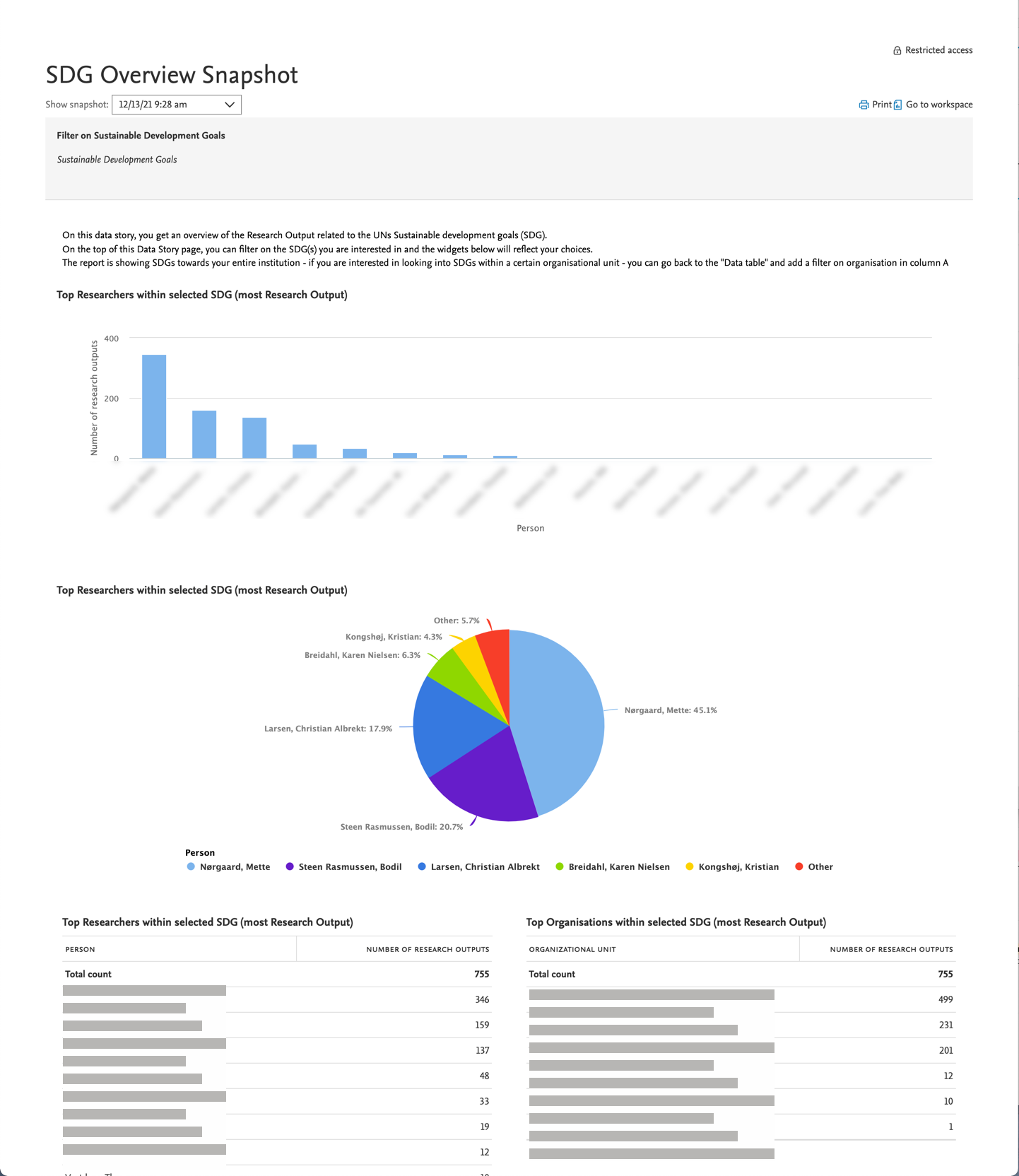 |
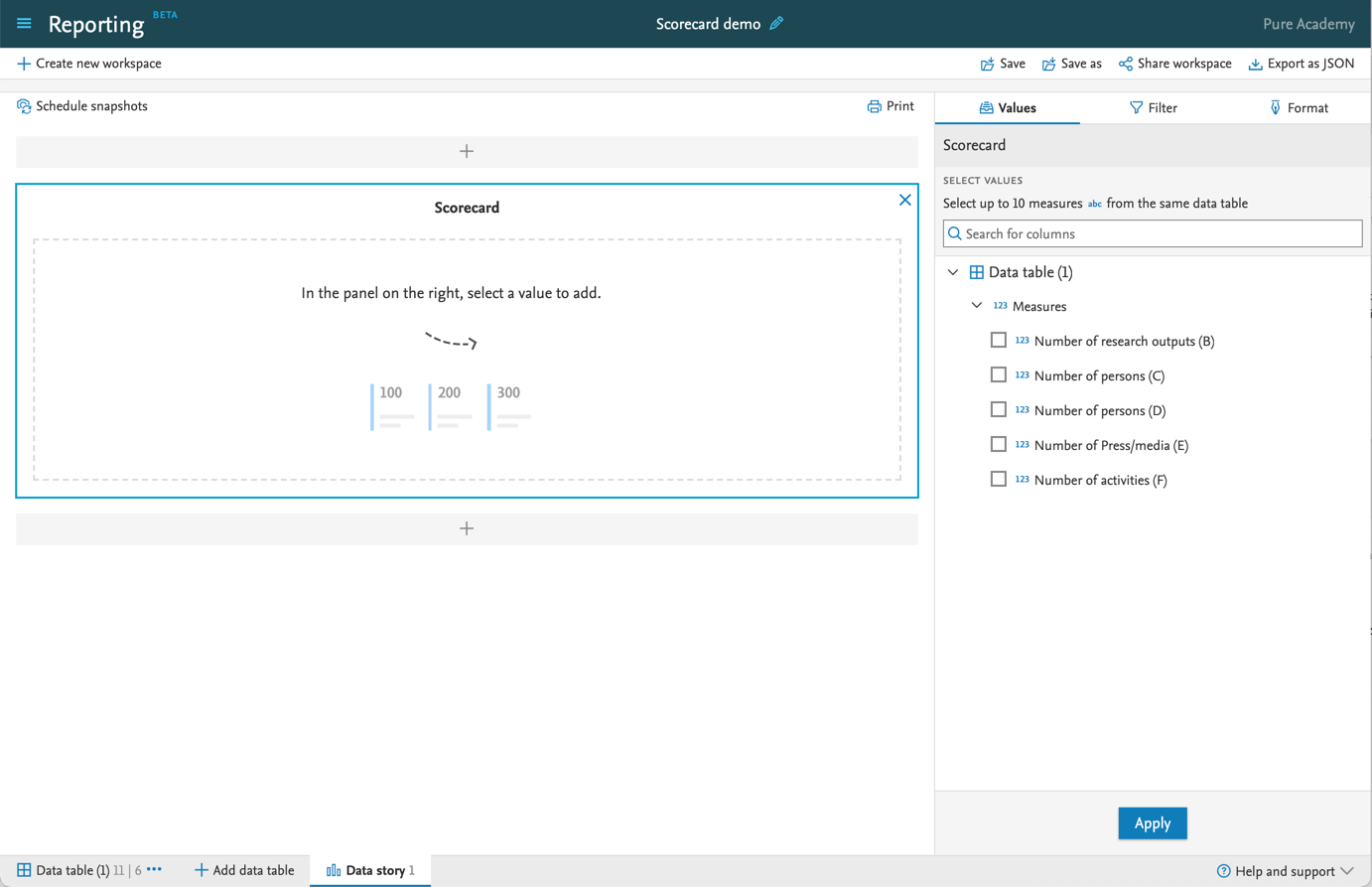
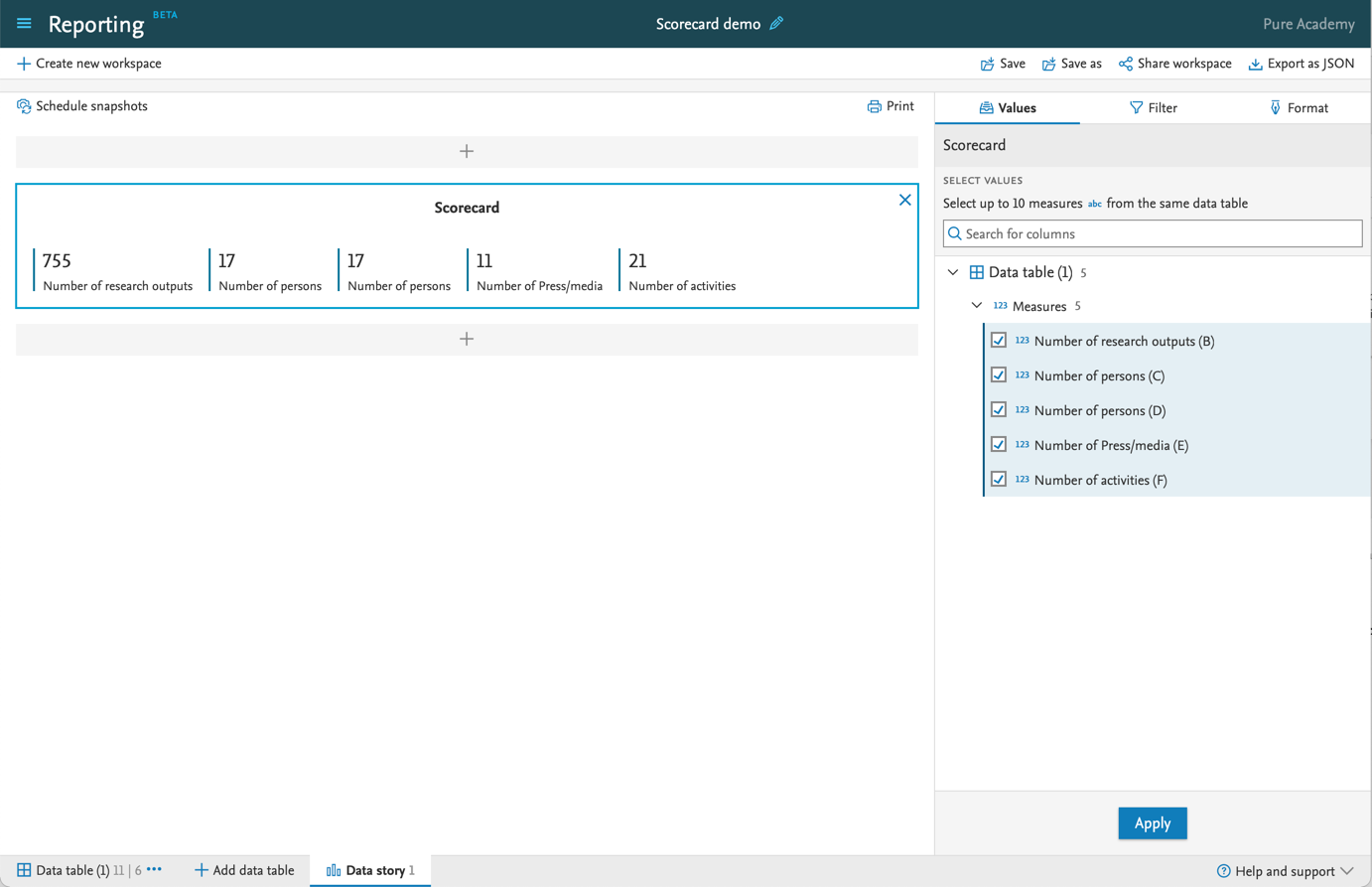
6.2. Scorecard: a new data story widget
We have introduced a new widget for the data story which we call the Scorecard. The Scorecard lets you easily draw attention to key figures in your data story. We use this widget in Pure itself, for example in the Personal user overview page. With this release, you are now able to create this widget yourself.
Click here for more details…
Information |
Screenshot |
|---|---|
| To use the new Scorecard widget, just select it when adding new widget to the data story. |
|
When the Scorecard is added to the data story, you can select which measures should be included. You cannot select measures from different data tables. |
|
|
After selecting the key measures, just click 'Apply'. To remove measures from the Scorecard, just deselect the measures and click 'Apply'. |
|
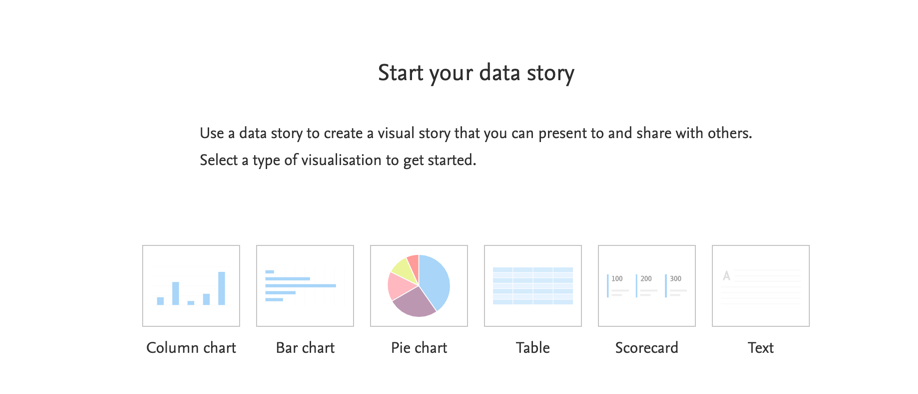
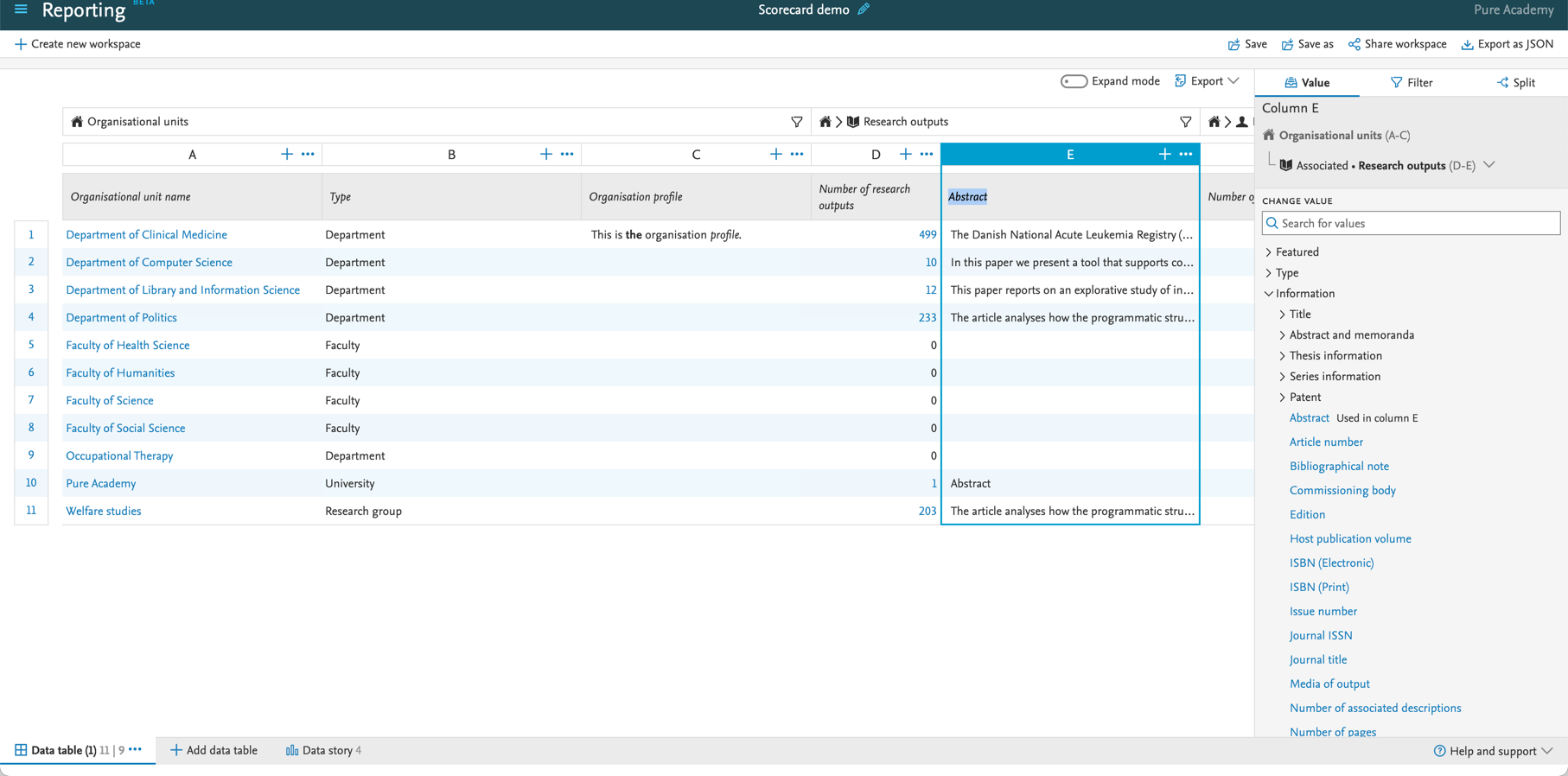
6.3. Reporting on more fields
We have been working on adding more values to the reporting module, and with this release we have added the option to use fields which can contain markup, such as 'Organization profile' and 'Abstract' on research outputs.
If the field contains markup, this will be shown in the reporting module.
Click here for more details…
Information |
Screenshots |
|---|---|
You will find the new fields when adding columns to the data table. In this example, 'Organization profile' and 'Abstract' have been added to the data table. We will show as much of the fields as we can, based on the available space on the page. Once you export to either Excel or CSV, the entire field will be exported. Any markup that might be present in these fields will now also be shown in the reporting module. This can lead to some odd-looking data tables, as we are showing all contents in one line. In the table widget we do show any new lines as well, but if there is a lot of text with embedded tables, etc., this can still look odd. |
|
6.4. New way of selecting data for widgets in the data story
It is now easier to add measures and dimensions to the data story. This new, streamlined way of selecting the values will be available throughout the reporting module, with updates to other areas planned in subsequent releases of Pure.
Click here for more details…
Information |
Screenshots |
|---|---|
| When adding values to a widget, you will now see the same controls as in the Scorecard. |
|
| After selecting the needed dimension and measure for the selected widget, just click the 'Apply' button. | 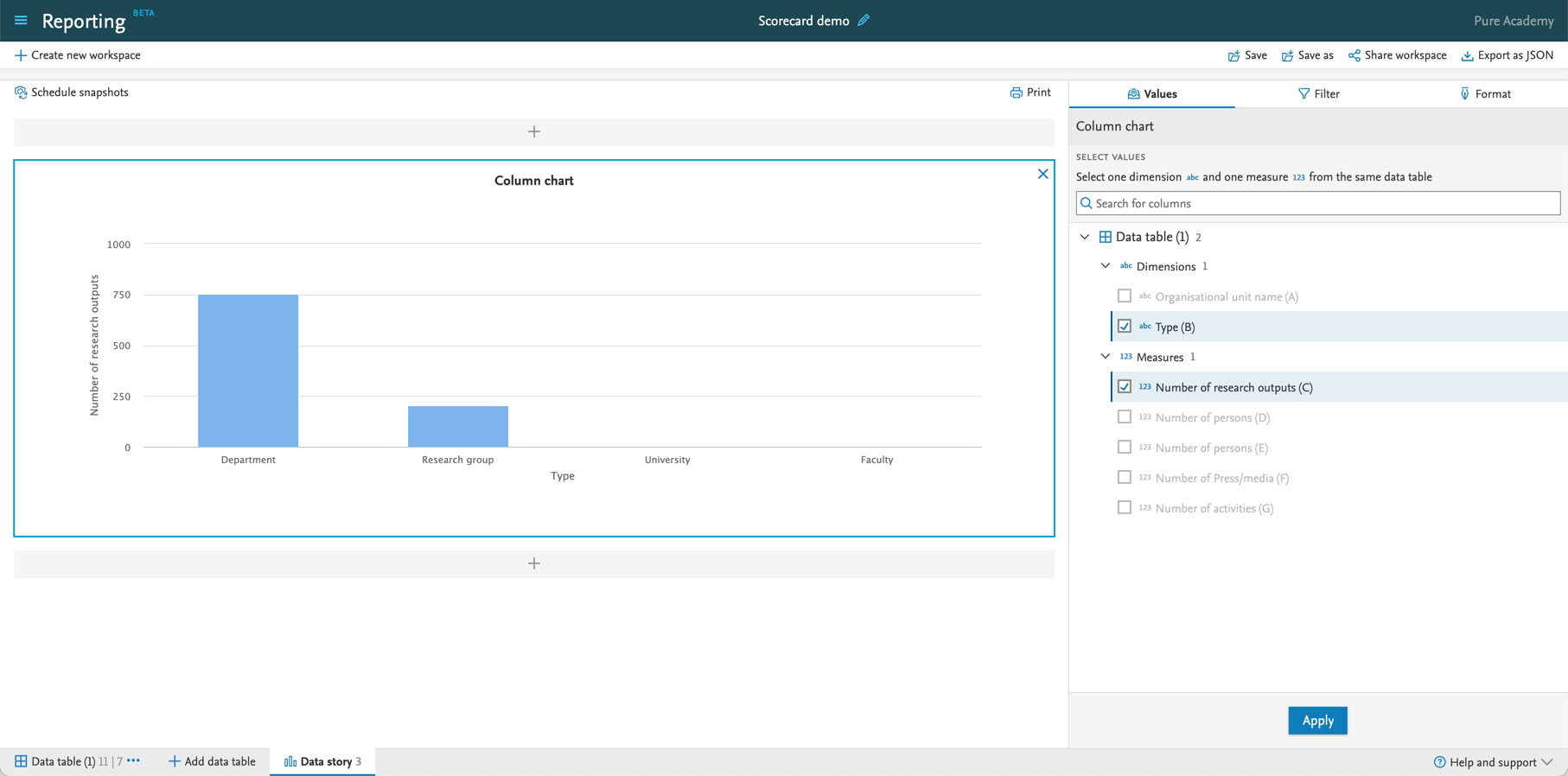 |
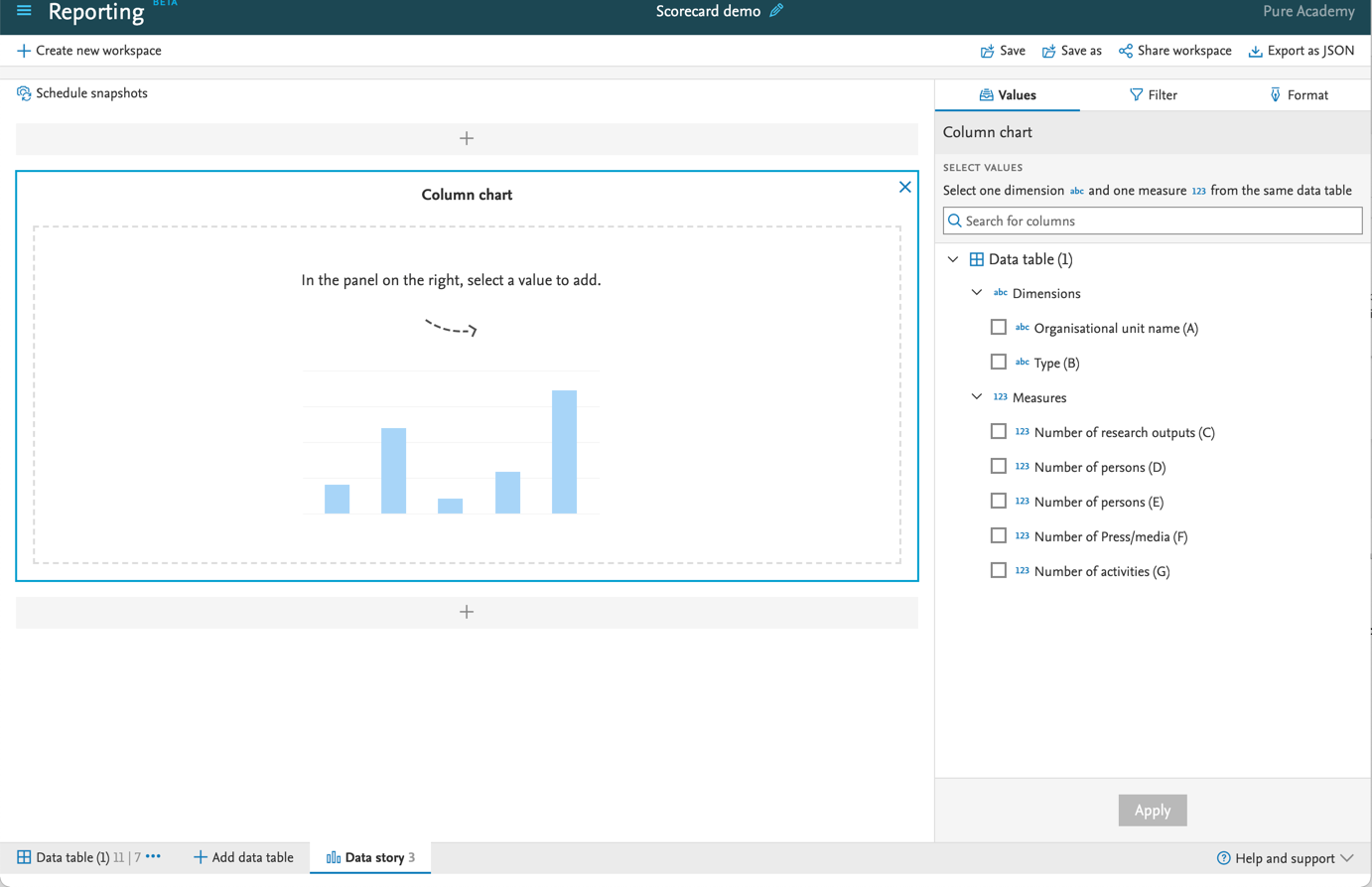
6.5. Filter content based on a list of IDs
Do you have a specific list of Pure IDs or UUIDs that you need to filter to in the reporting module? With this release you can. (See also section 5.2 Export of search results available and configurable)
Click here for more details…
Information |
Screenshot |
|
|---|---|---|
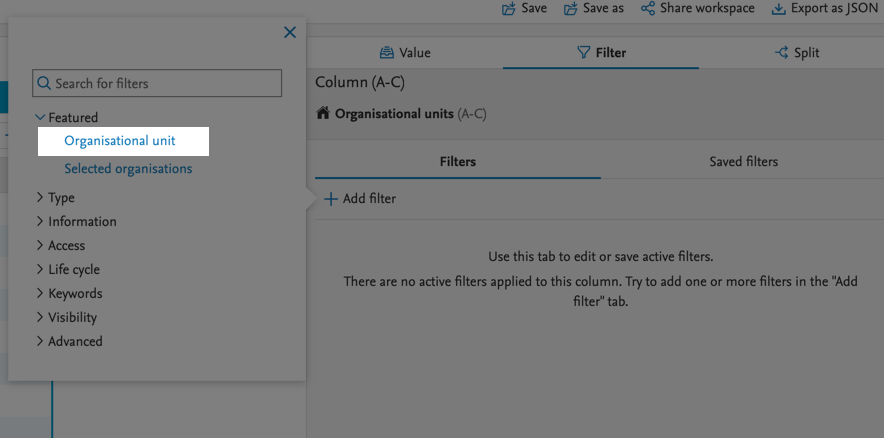
| To filter values based on a list of IDs, you just need to paste the list of IDs in the search bar available for that filter (here, Organizational unit). Note: The list can only be used in filters where you can search for content. |
|
|
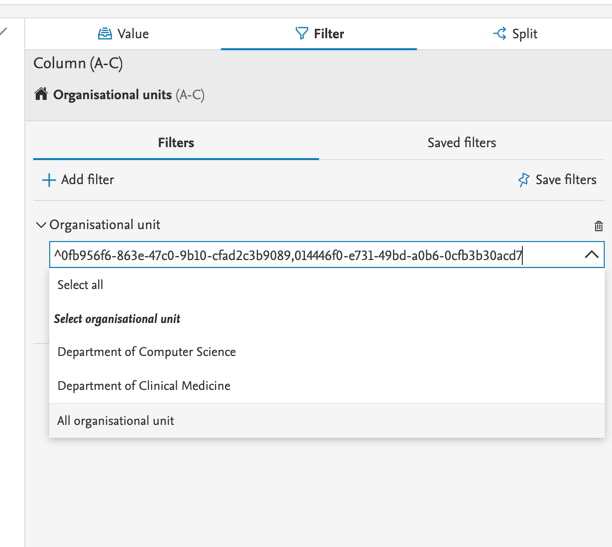
To use the list, it must follow this format: ^ID1,ID2. Example
After adding the string in the search box, you will see the IDs that Pure was able to find, and you can then select some, or all of them. Pure only support 2,000 IDs in one string. |
|
7. Country-specific features
7.1. AU: ERA
7.1.1. ERA module
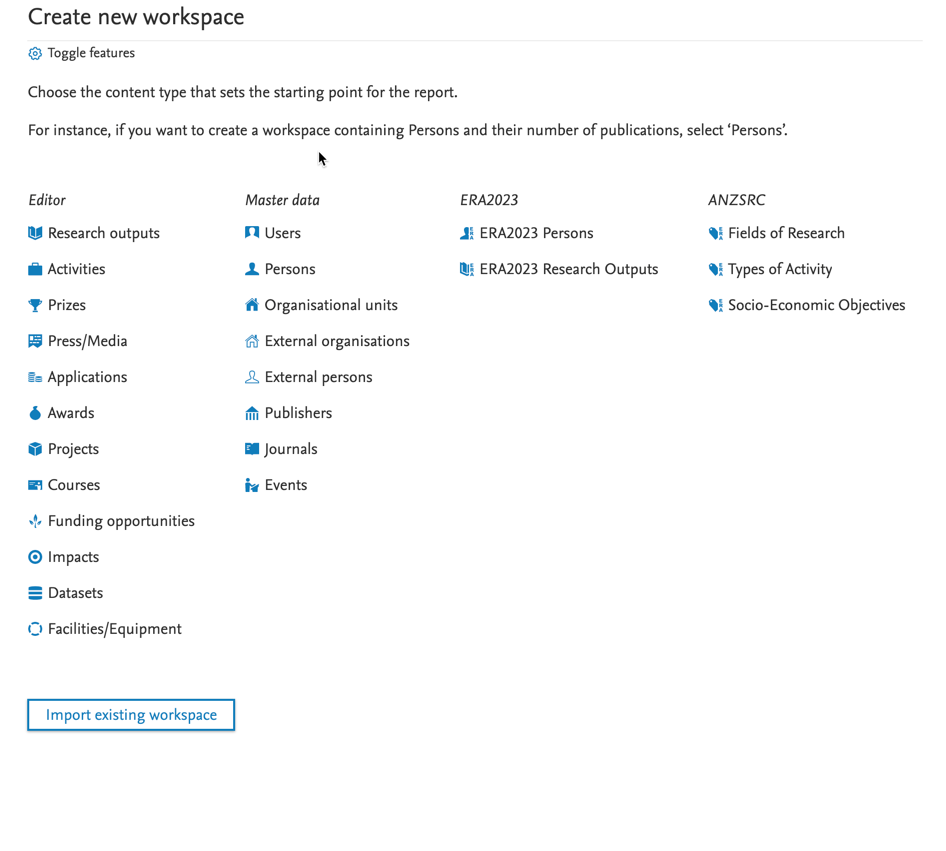
We have made the initial version of the new ERA 2023 module, which can be enabled by request. This module contains ERA Persons and ERA Outputs to which you can add only FoR codes. This will allow you to start looking at the pool of Persons and Outputs that should be considered for the ERA 2023 exercise. We have also enabled reporting on these new content types such that you can created reports to help get an overview of the pool of ERA Persons and ERA Outputs.
Click here for more details...
We will add more fields to the ERA Person and ERA Output once we know more about the upcoming ERA 2023. Also, right now we don't have any limits on the FoR codes: we will work in collaboration with the ERA working group to determine what types of limits and validations need to be implemented. Please watch the ERA2023 space, if you don't already.
7.2. DK: BFI
BFI is closing down at the latest 15/2. Therefore we're working on some changes to the BFI module in Pure, unfortunately, this didn't make it to the 5.23.0 release. We're working on a 5.23.0-1 release that we recommend for all Danish clients using the BFI module.
What will happen for the danish clients in 5.23.0-1 is the following:
- BFI jobs will be removed (Series, Publishers, Conference series, points)
- We will add a note to the BFI overview pages saying points will no longer be updated
- We have changes two setting on the BFI setting page: ‘Show BFI check on BFI information tab’ and ‘Limit search on journals and publishers on BFI authority list’
Published at December 05, 2023