
How Can We Help?
5.8.05.8.0
Highlights of this release
![]() Mendeley Data Integration
Mendeley Data Integration
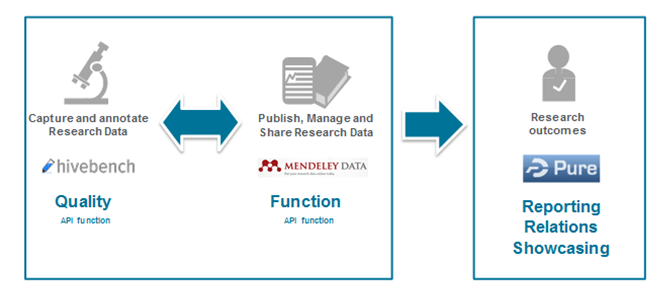
Pure now integrates with Mendeley Data, a cloud-based research data repository with specific research data management capabilities such as version management and automatic archiving. This integration enables institutions to synchronise into Pure details of Datasets entered in Mendeley Data by their researchers, keeping content in Pure up-to-date as it is edited in Mendeley Data. The integration between Pure and Mendeley Data capitalises on the individual strengths of each tool, offering a holistic solution that meets the needs of both researchers and institutions. See below for more info ...
![]() Customisable Faculty and Academic Activity Reporting
Customisable Faculty and Academic Activity Reporting
Several key enhancements to the Faculty and Academic Activity Report (FAAR) (initially introduced in 5.6) are included in this release. It is now possible to create customizable FAAR Reports that automatically harvest and exhibit Pure content, and render a summarized report of key data. Further, multiple FAAR templates can be created, enabling each individual Department or School the ability to create a template that meets their individual needs. We have also introduced a batch download feature, and automated FAAR e-mail notifications are now configurable, supporting advanced messaging to Faculty and Academics relating to expected due dates and reminders. See below for more info ...
Watch the 5.8 New & Noteworthy seminar
We are pleased to announce that version 5.8.0 (4.27.0) of Pure is now released
Always read through the details of the release before installing or upgrading to a new version of Pure
Release date: 2 February 2017
Hosted customers:
- Staging environments will be updated 8 February 2017 (APAC + Europe) and 9 February 2017 (US)
- Production environments will be updated 22 February 2017 (APAC + Europe) and 23 February 2017 (US)
Be aware of the Upgrade Notes - failing to adhere to these may result in loss of functionality
Content validation
You are generally encouraged to check all content in the re-validation workflow step prior to upgrade as changes to the underlying datamodel may not be reflected in the re-validation overview screen (see example)
Further, you are encouraged to check if all content can validate prior to an upgrade of Pure. This check is done by running the Check content and files job and resolving any data validation issues that are flagged by the job
Installation and downloading
See the Request Pure distribution file page for information about how to request a new version of Pure
Other Resources and Links
If you have problems with this release please contact Pure Support to get help
Pure hosting requirements
See the Pure Requirements page for more information about the current hosting requirements for Pure
1. Administration module
1.1. Datasets : Mendeley Data Integration
Mendeley Data is a cloud-based research data repository, with specific research data management capabilities:
- Version management, including comparison between versions
- Automatic archiving of Datasets into DANS archive (in perpetuity)
- Preview and visualise files in browser, including spreadsheets and 3D images
- Integration with Hivebench ELN for full lifecycle management
In response to our customers’ increased focus on Research Data Management and the tools required to support it, in this release we have implemented integration between Mendeley Data and Pure, enabling institutions to synchronise into Pure details of Datasets entered in Mendeley Data by their researchers, keeping content in Pure up-to-date as it is edited in Mendeley Data.
The integration between Pure and Mendeley Data capitalises on the individual strengths of each tool, offering a holistic solution that meets the needs of both researchers and institutions. Enabling the Mendeley Data integration in Pure requires the Pure Import module and a subscription to Mendeley Data Institutional Edition.
Click here for more details on Mendeley Data integration
The integration between Pure and Mendeley Data capitalises on the individual strengths of each tool, offering a holistic solution that meets the needs of both researchers and institutions.
Key features of the Mendeley Data integration:
- Automatically synchronises Datasets created by your researchers in Mendeley Data
- Keeps synchronised Dataset content in Pure up-to-date as it is edited in Mendeley Data
- Only metadata is imported into Pure; files are represented as links in Pure with the golden copy retained in Mendeley Data
- Harnesses the individual strengths of Mendeley Data as a cloud-based research data repository, and Pure as an institutional tool to capture relationships between content, to showcase institutional research activity, and to monitor compliance with funder mandates and institutional policies
More information on Mendeley Data and its integration with Pure is available here
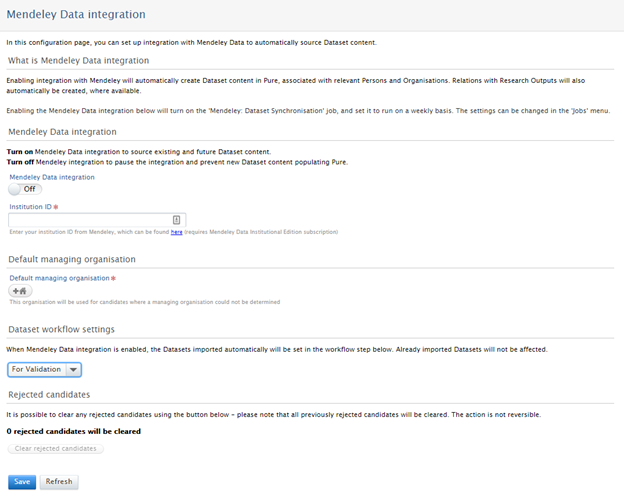
Roles affected: Administrator, Administrator and Editor of datasets, Personal user
Notes:
- Mendeley Data integration is, by default, DISABLED
- Enabling the Mendeley Data integration in Pure requires the Pure Import module and a subscription to Mendeley Data Institutional Edition
1.2. Open Access Improvements
This release includes:
- Expansion of the Journal datamodel to include whether the Journal is indexed in Directory of Open Access Journals (DOAJ)
- New Unknown value available for 'Public access to file'
- Improvements to functionality relating to previously embargoed electronic versions
Improvements to restrictions on users from deleting / replacing Electronic versions from validated records
Click here for more details…
Directory of Open Access Journals (DOAJ) | ||||
|---|---|---|---|---|
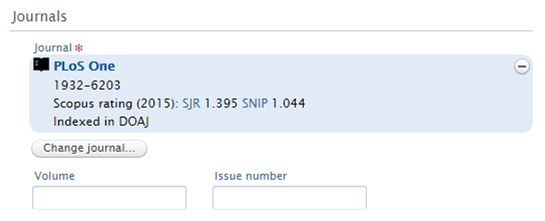
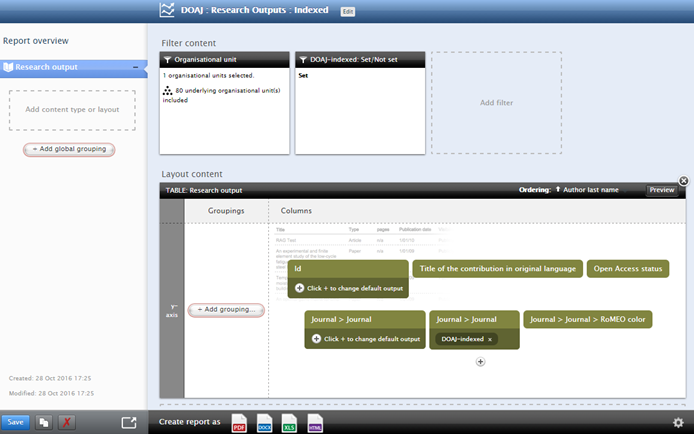
The Directory of Open Access Journals (DOAJ) "is a community-curated online directory that indexes and provides access to high quality, open access, peer-reviewed journals." We have expanded the Pure Journal datamodel to include whether the Journal is indexed in DOAJ, enabling users to identify outputs published in Journals indexed in DOAJ. This DOAJ information appears in the Journal editor, in addition to renders of the Journal (on, for example, the Research Output and Activity editors). In the Reporting module, it is possible to filter, group, and report on Journals indexed in DOAJ (both when reporting on Journals by themselves, or as a related content type).
In order to capture this information, you should enable the "DOAJ Indexing" job, which is by default set up to run on a daily basis, but it is recommended that this is changed to no more frequently than monthly. Note that the matching process is performed solely on ISSNs, and not Journal title. Note that Pure does not maintain any history of a Journal's indexing in DOAJ (as this is not supplied by the DOAJ API). Pure only records whether the Journal is indexed in DOAJ at the time of running the job. |

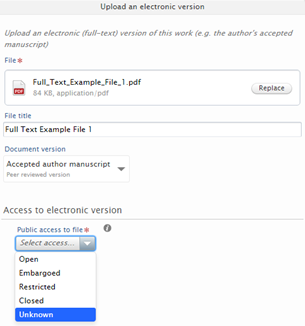
New Unknown value for 'Public access to file' | ||
|---|---|---|
In response to customer feedback, there is now the option to select Unknown 'Public access to file' (for Documents, DOIs, and Links). The Open Access : Logic for OA Flag documentation has been updated accordingly (where the 'Public access to file' is Unknown, the Open Access Status is INDETERMINATE).
Notes:
|
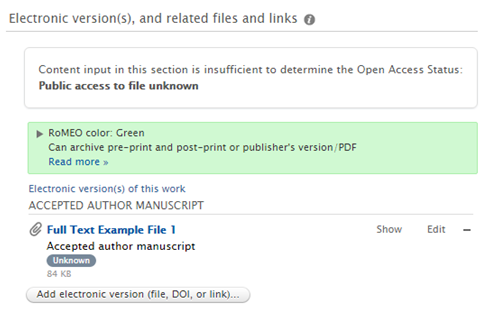
Improvements to Open Access Status functionality relating to previously embargoed electronic versions |
|---|
We have improved two elements relating to the Open Access Status of previously embargoed electronic versions:
|
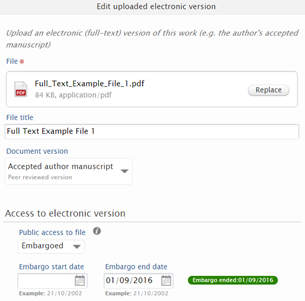
Restricting users from deleting / replacing Electronic versions from validated records |
|---|
In 5.6.2 / 4.25.2, we delivered functionality that enabled Administrators to restrict selected user types from deleting Electronic versions from validated records. This functionality has now been improved such that these restrictions have been expanded to also include replacing files in validated records.
|
2. Reporting
2.1. Faculty and Academic Activity Reporting
Further to the delivery of the first phase of Faculty and Academic Activity Reporting (FAAR) in 5.6.0, this release includes:
- further customization of the FAAR templates
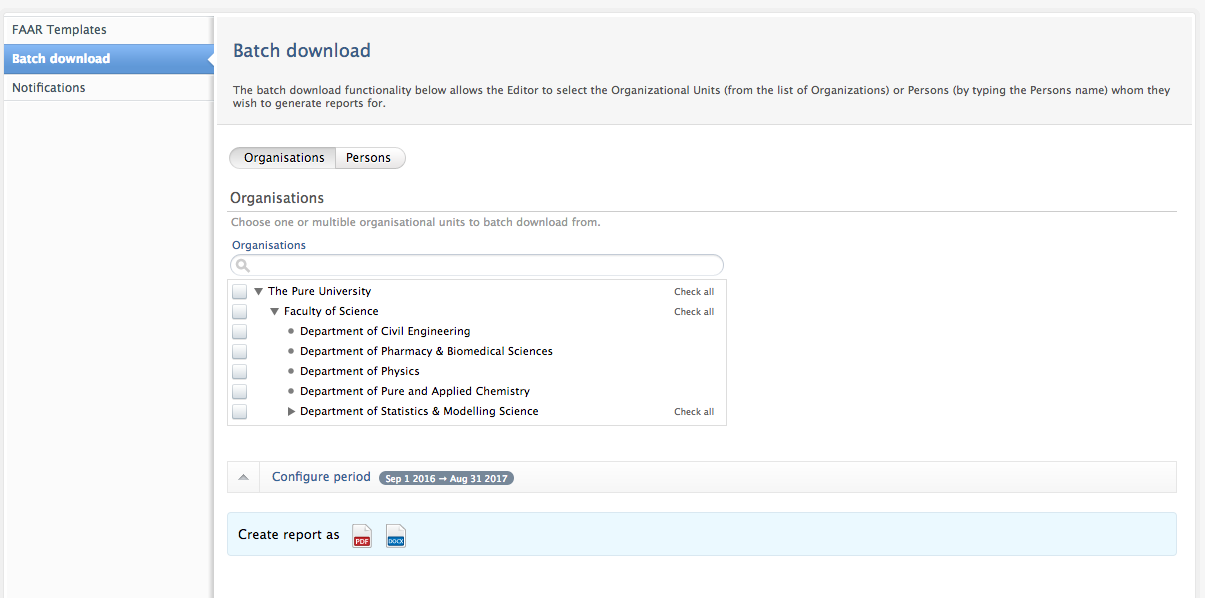
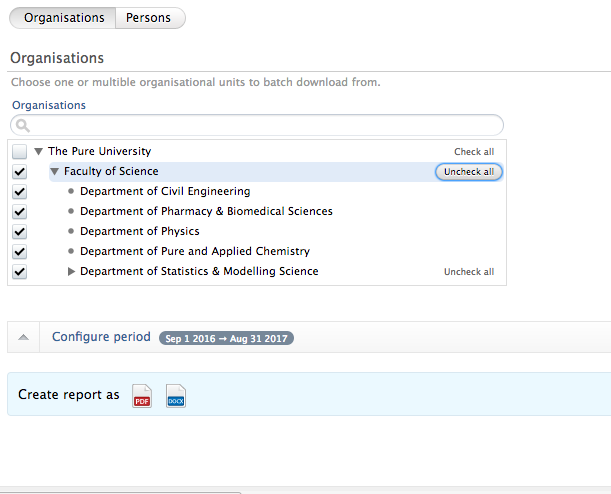
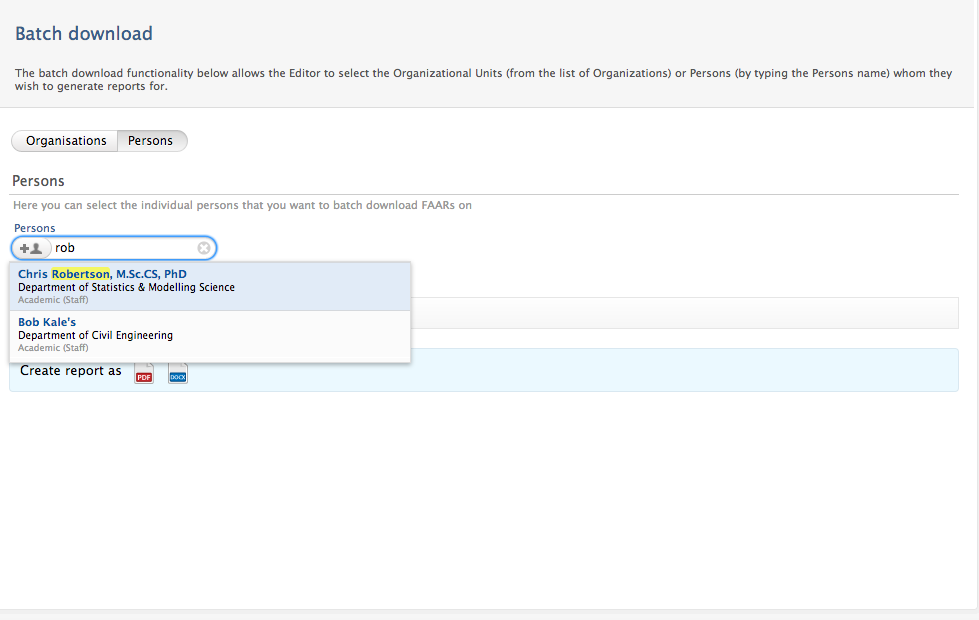
- batch download functionality of FAAR reports for entire organizations, groups of organizations, and groups of individuals
- the ability to set up and send out automatic e-mail alerts pertaining to due dates for FAAR
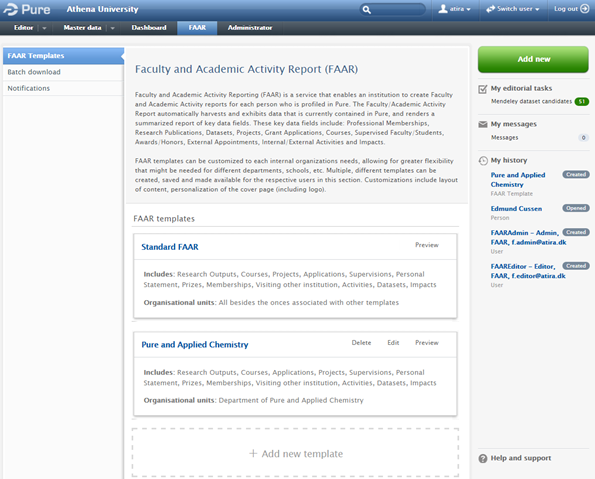
- the addition of a new FAAR navigation menu item, enabling Editors and Administrators of FAAR to manage custom templates, batch downloads, and notifications
In order to use FAAR, the Report module must be enabled.
Click here for more details on FAAR...
New menu item |
|---|
FAAR has been added as a new menu item at the top of the screen for Editors and Administrators of FAAR
|

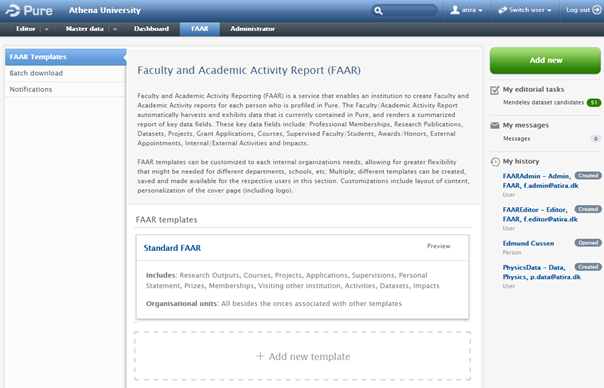
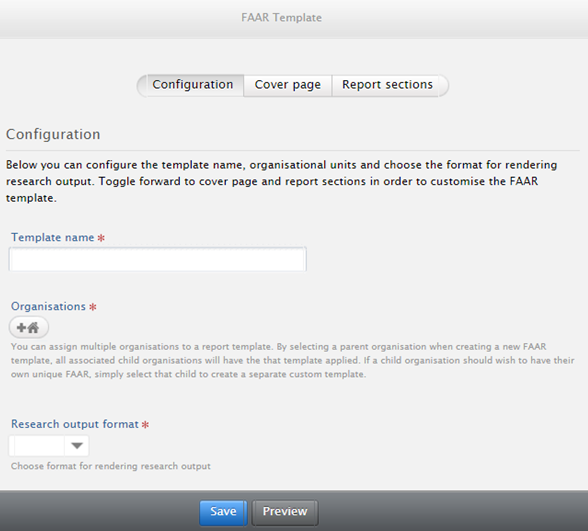
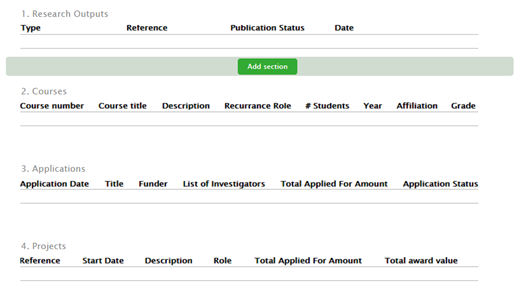
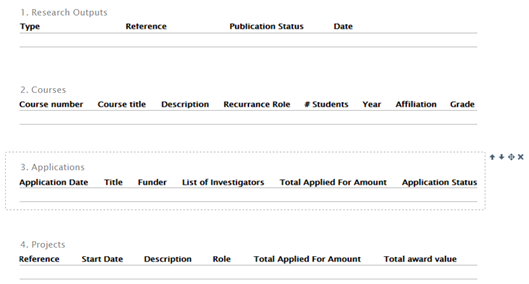
Customized templates | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
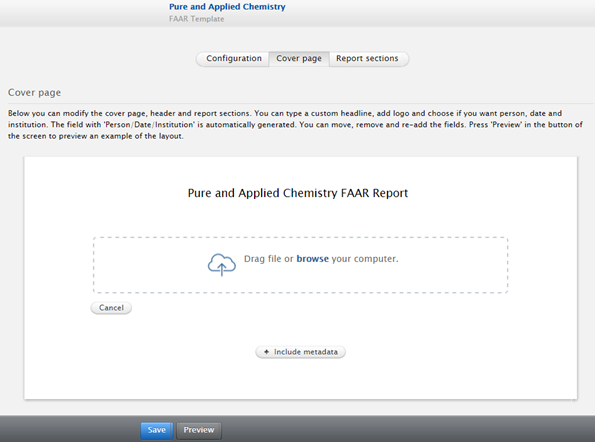
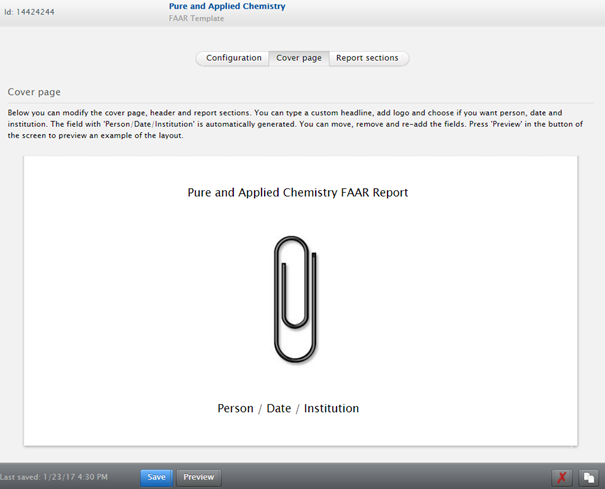
Editors and Administrators of FAAR can create custom templates, and assign them to specific schools, departments and affiliations. To create a custom template, enter the FAAR menu, click on 'FAAR Templates' in the left-hand navigation, then click 'Add New Template':
A wizard guides the Editor / Administrator through the necessary steps to create a custom FAAR template.
|
Batch download | ||||
|---|---|---|---|---|
Via 'Batch download' in the left-hand navigation of the FAAR menu, Editors and Administrators of FAAR can now:
|
Notifications | ||
|---|---|---|
Via 'Notifications' in the left-hand navigation of the FAAR menu, Administrators of FAAR can now send out system-generated FAAR notifications:
|
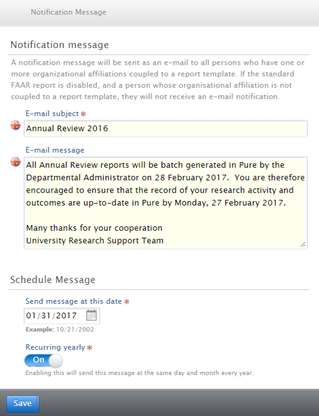
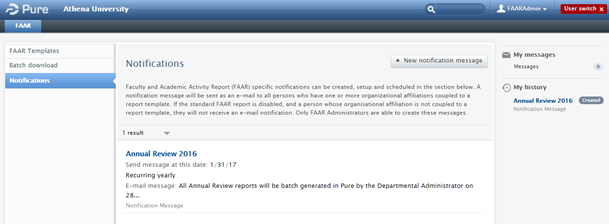
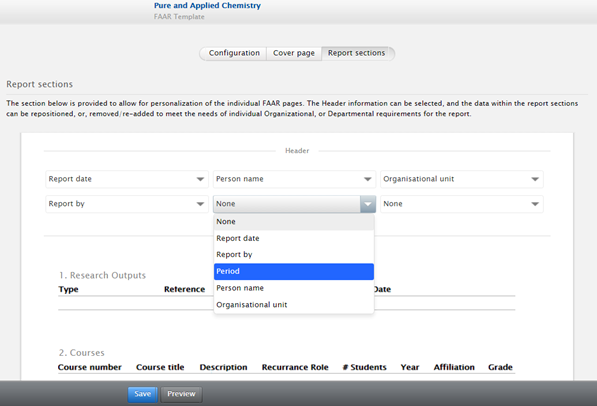
Note that the Pure Administrator continues to be able to set the global FAAR configuration for the following aspects, available at Administrator > Faculty and Academic Activity Reporting:
- enable FAAR
- turn on / off the standard FAAR template
- select time frame / year that the FAAR templates are to report on (e.g. calendar, fiscal, academic) (but this can be overwritten in individual templates by Editors / Administrators of FAAR)
- select Research Output render style (e.g. Harvard, APA, etc.) (but this can be overwritten in individual templates by Editors / Administrators of FAAR)
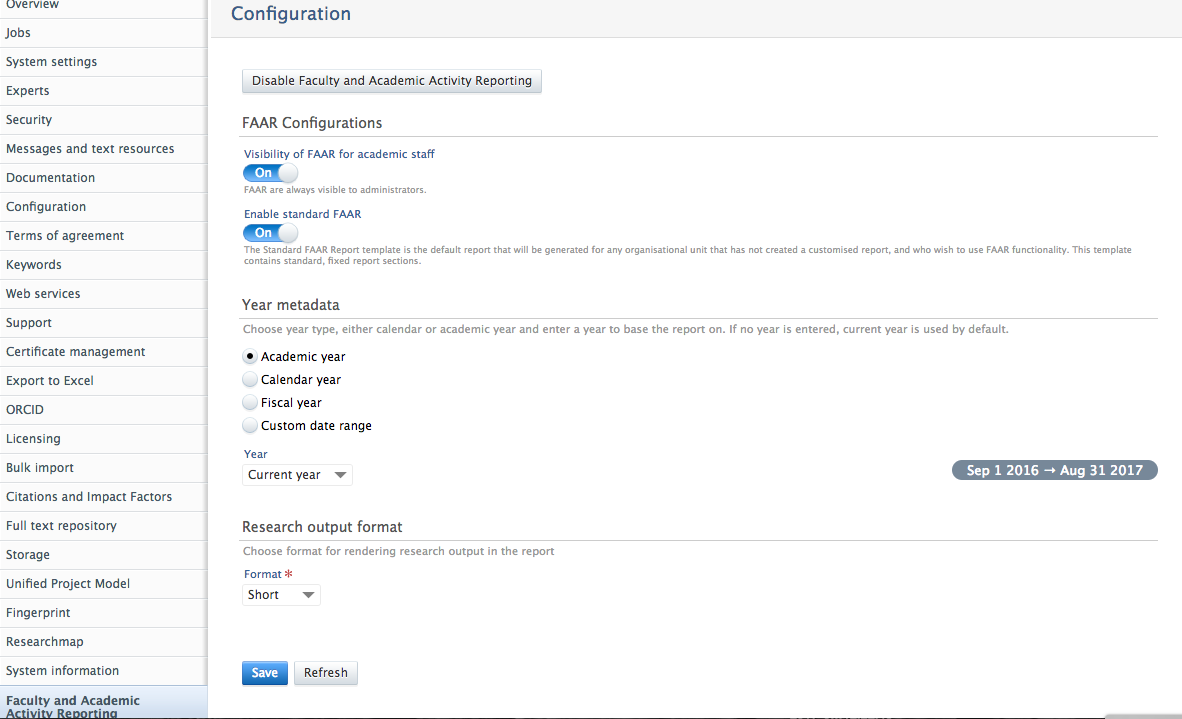
Roles affected: Administrator, Editor and Administrator of FAAR, Personal user
3. Pure Portal
3.1. Search enhancements
This release includes enhancement to the way visitors to Pure interact with Search.
Click here for more details on enhancements to the Portal Search functionality…
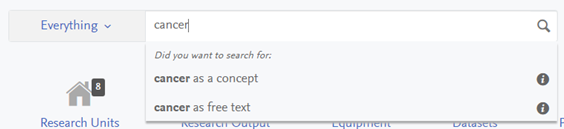
Search as a Concept or Search as Free Text | ||
|---|---|---|
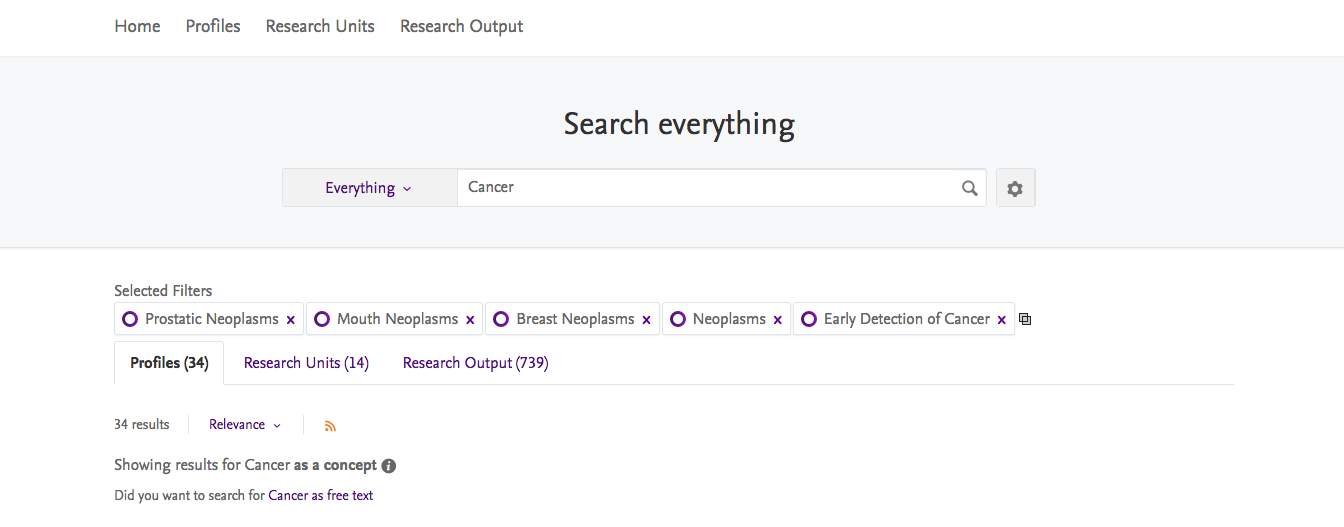
In the standard Search box, the visitor is now presented with two new options when entering text into the search box. A drop down menu will appear as the text is being typed, enabling the visitor to choose how they wish the search to proceed - either as 1) a Concept search or 2) as a Free Text search. If the visitor does not choose, the search will proceed as it always has.
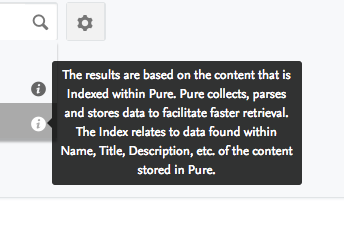
In addition, the two types of Search are further clarified by hovering the mouse over the information icon on the right, providing definitions for Concept search and Free Text search.
The search results are displayed in a tabbed format, each content that yielded results on separate tabs (i.e. Profiles, Research Units, Research Outputs, etc.). Once the results are produced, it is also possible to change to a "Free Text" search of the input text by simply clicking the highlighted text next to "Did you want to search for_______ as free text"
|

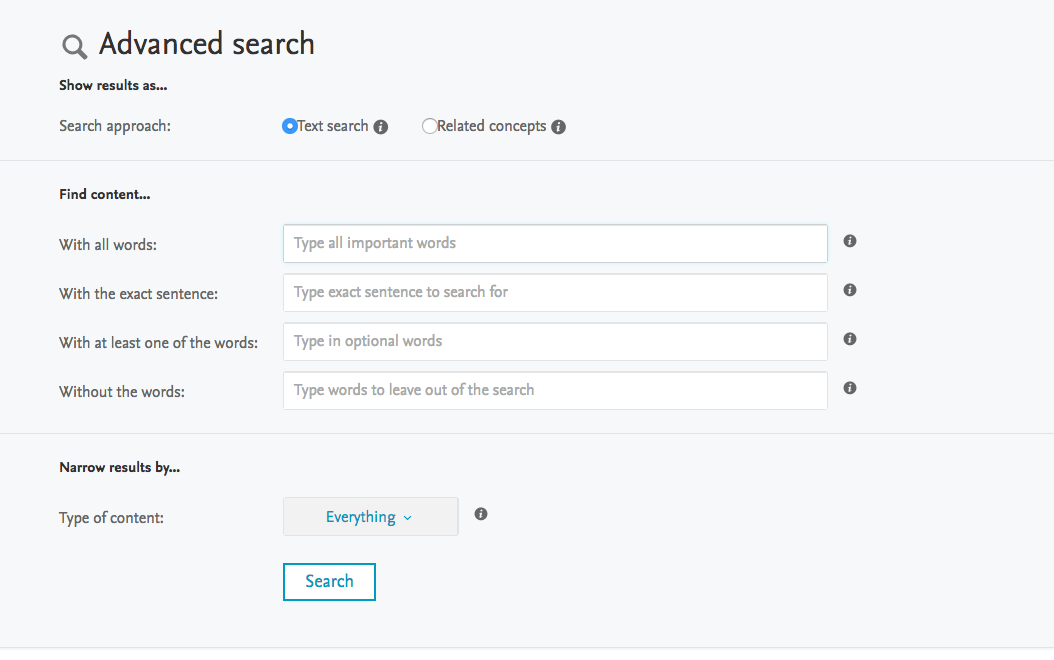
Advanced search |
|---|
An Advanced Search option has been introduced to the search capabilities in Pure, allowing the visitor to further refine their search results. The Advanced Search functionality is accessed by hovering the mouse over the "gear" icon to the right of the Search box.
A visitor can now enter text in the following ways:
A visitor can decide to search either as a Concept or Free Text, and narrow the results by the type of content available in Pure.
|

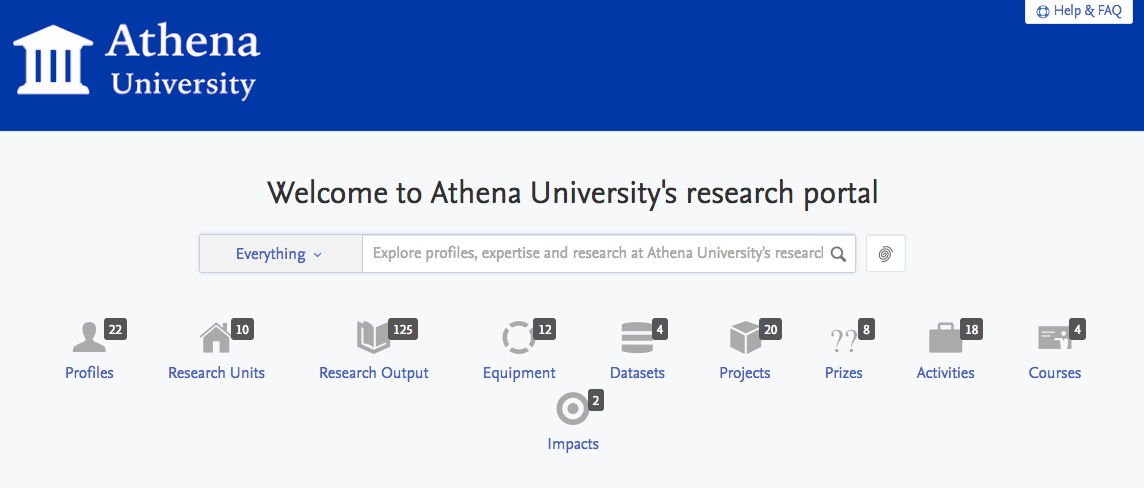
3.2. Content header improvements
This release includes a re-design of the appearance of the content type header. Prior to 5.8, if all content types were enabled for the Portal, the types would be displayed on multiple lines in the content header. This is now resolved; when more than six content types are enabled, a menu item for 'More' will be appear, and when hovered over, the additional types (and counts) are displayed.
Click here for more details on the content header improvements...
Before |
5.8 improvement |
||
|---|---|---|---|
 |
|
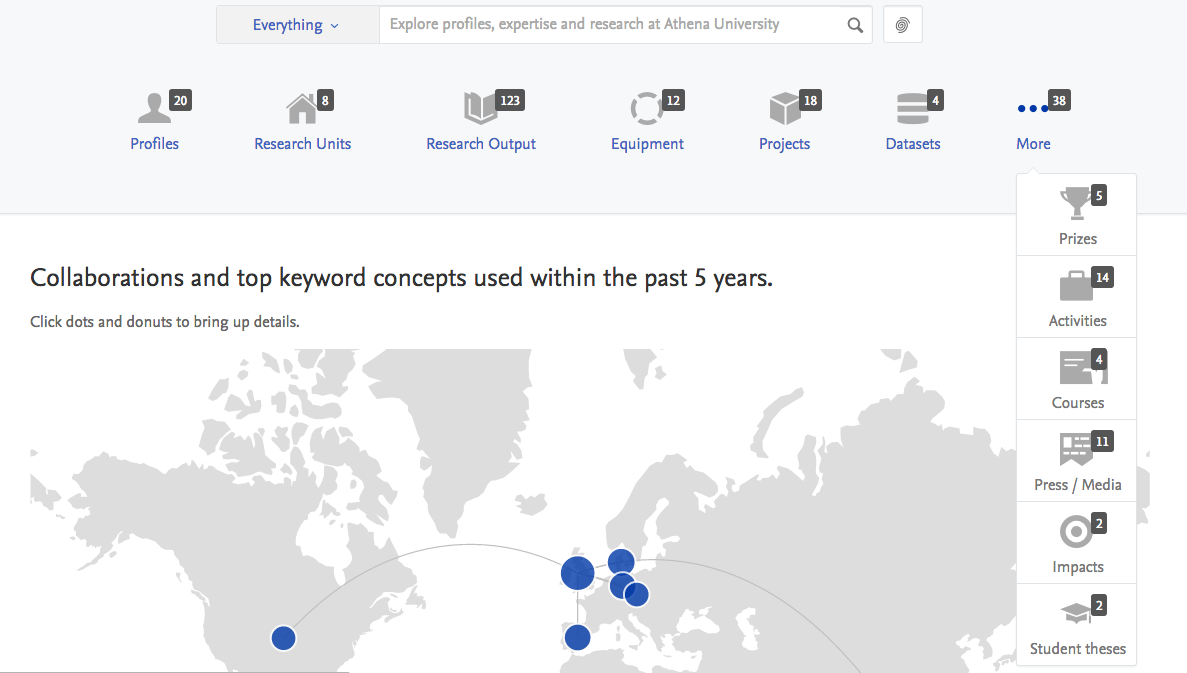
It is also possible for Administrators to edit the order that content types appear in the content type header. By default, the order is as follows:
- Persons (Profiles)
- Organizational units (Research Units)
- Research Outputs
- Equipment
- Projects
- Datasets
- Prizes
- Activities
- Courses
- Press / Media
- Impacts
- Student Theses
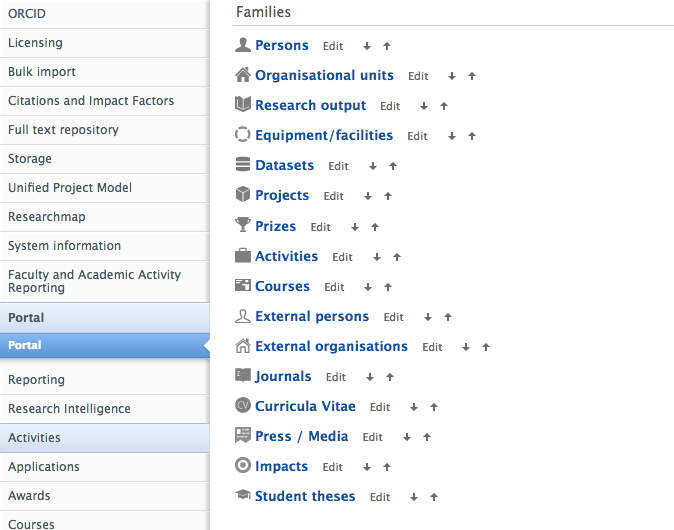
To edit the order of content types in the Portal:
- go to Administrator > Portal > Configuration
- scroll down to 'Families'
- to change the order in which content types are displayed in the content type header, use the up or down arrow next to the desired content type to change where it resides
- to add or remove a content type, please contact Pure Support via Client community
3.3. Portal footer and Contact page improvements
This release includes the removal of the RELX logo from the footer, the ability to include an institutional logo in the footer, and the introduction of an Institutional Contact.
Click here for more details ...
Portal footer | ||
|---|---|---|
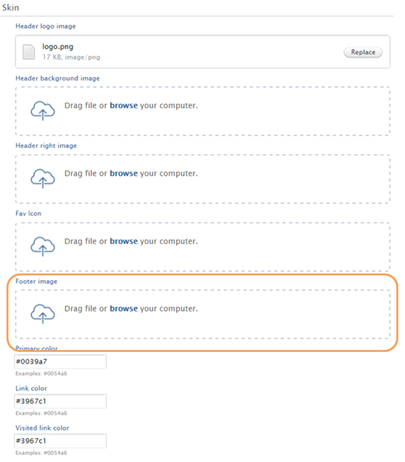
The RELX logo has been removed from the footer page, and the ability to add an institutional logo to the footer is now available, providing institutions with greater branding options in the Portal. To add an institutional logo to the footer, go to Administrator > Portal > Styling and layout tab, and scroll down to the 'Skin' section. Upload your logo file and save the configuration at the bottom of the page.
|
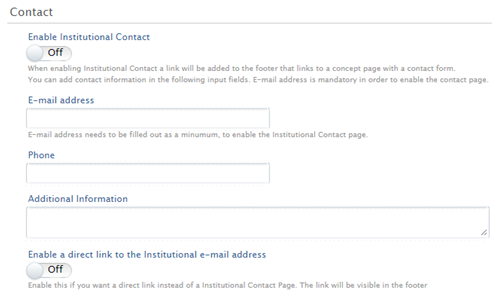
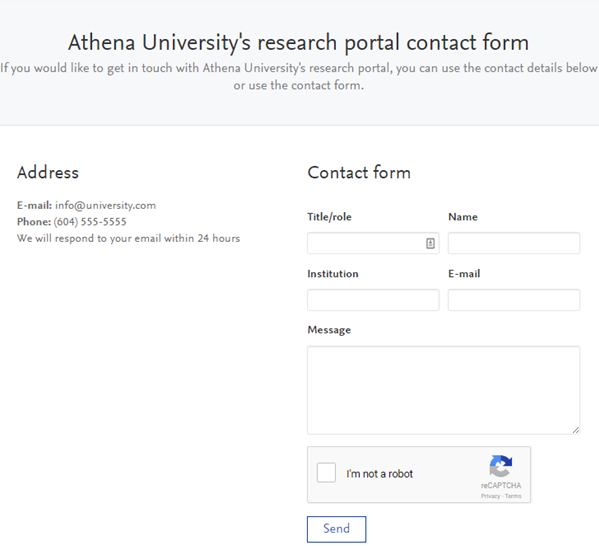
Contact page | ||||
|---|---|---|---|---|
You are now able to add institutional contact information in the Portal footer. To add institutional contact details to the Portal, go to Administrator > Portal > Styling and layout tab, and scroll down to the 'Contact' section. Enable Institutional Contact and provide the email address (mandatory), phone, and any additional information.
If you would prefer a direct link in the footer to the institutional email address, rather than to a contact form, enable the 'direct link to the institutional e-mail address'. |

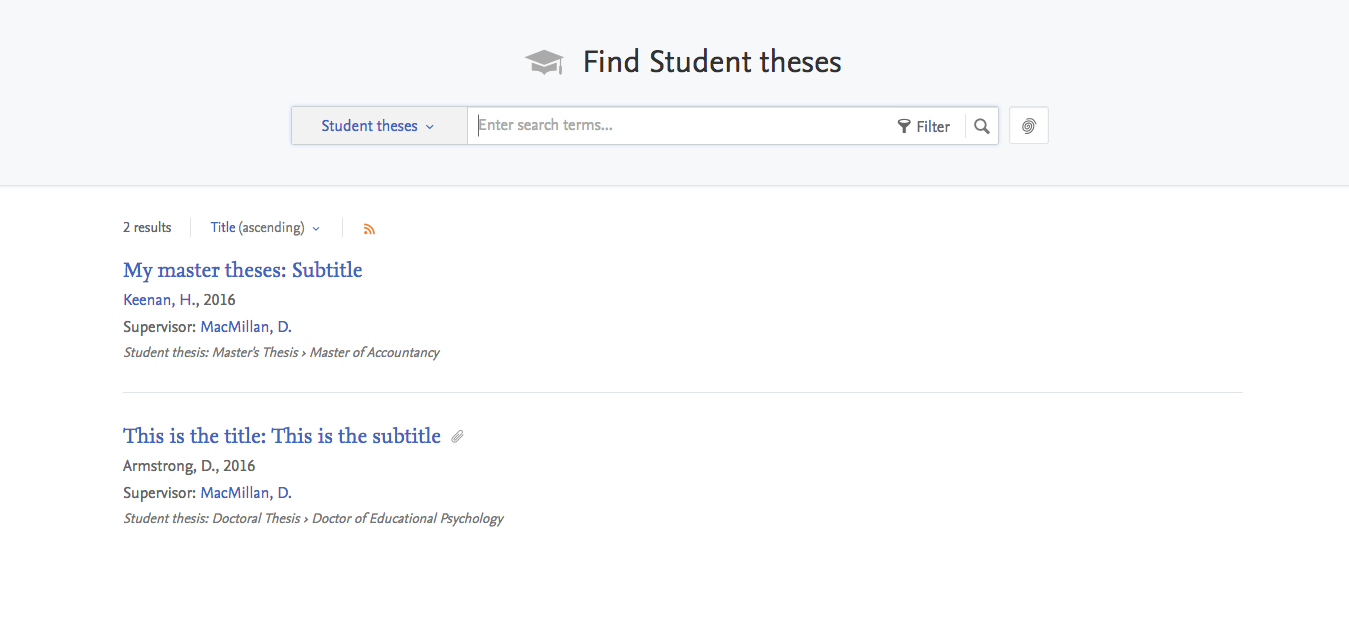
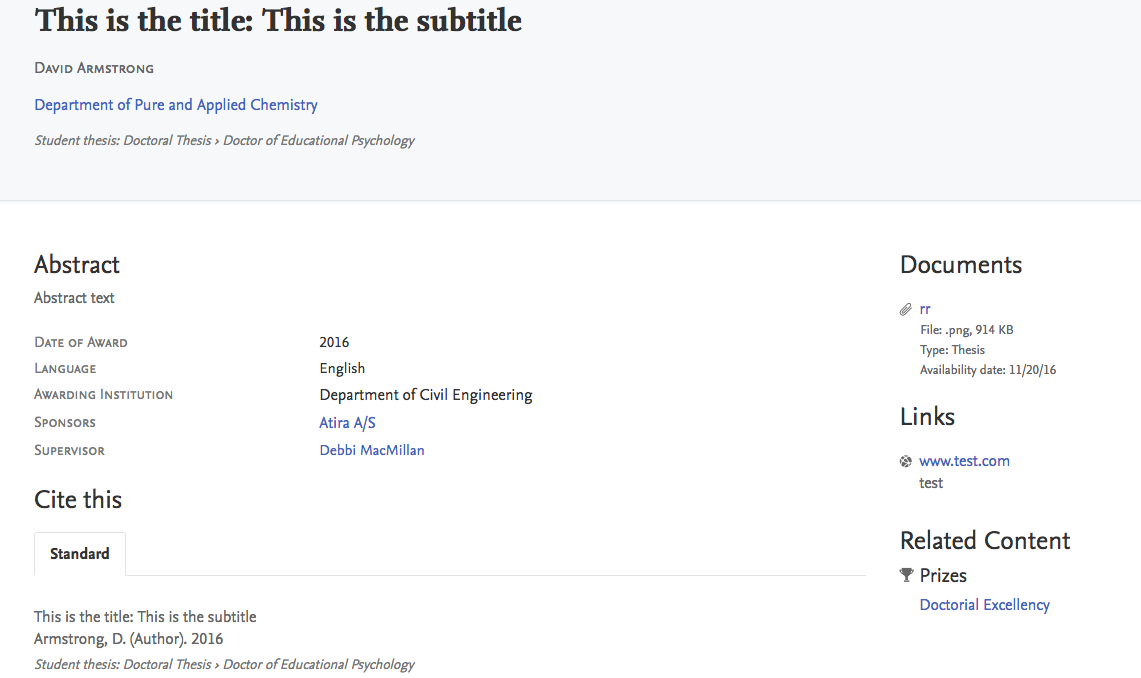
3.4. Student Theses content type added
This release includes the ability to display Student Theses as their own content type within the Pure Portal.
Click here for more details ...
Student Theses will be displayed for both profiled Persons who have authored a Student Thesis, as well as Student Theses that are supervised by profiled Persons in the Portal. This content is not displayed by default.
 |
 |
 |
Notes:
- Student Theses is an independent content type - Research Outputs of type 'Thesis' will continue to be listed in the Portal as Research Outputs
- Student Theses are disabled by default
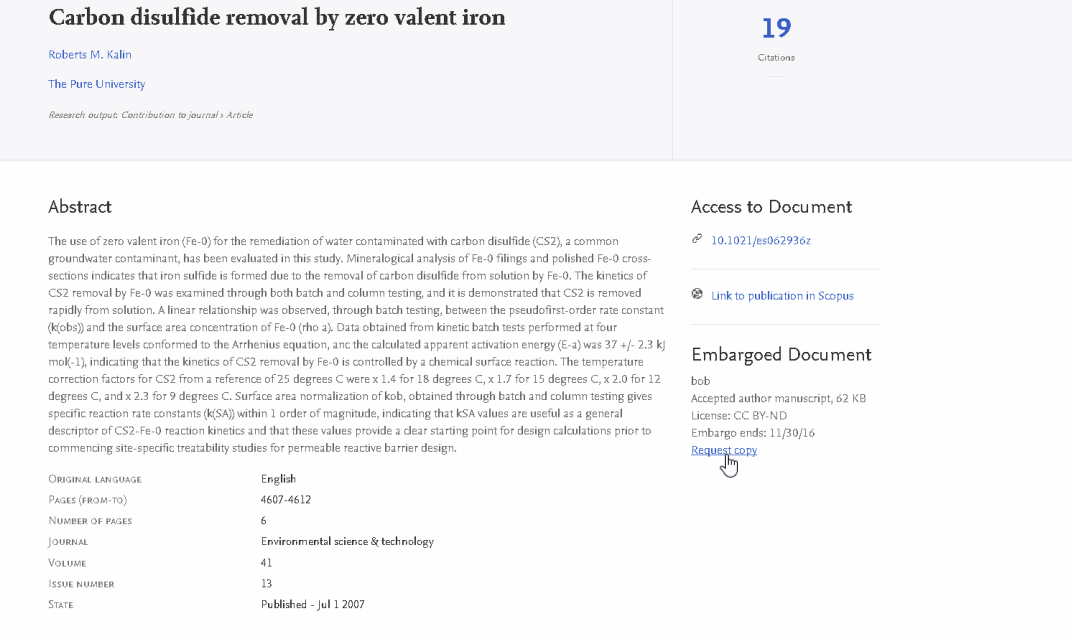
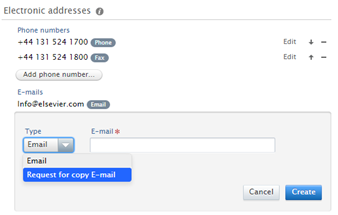
3.5. Request Copy functionality for embargoed electronic versions of Research Outputs
This release includes the ability to Portal visitors to request a copy of an electronic version of an output that is not displayed in the Portal due to embargo restrictions.
Click here for more details on Request Copy functionality ...
The purpose of this feature is to enable Portal visitors to request a copy of a full text document (e.g. Author's Accepted Manuscript) when the document cannot be made available for download via the Portal due to embargo restrictions.
| In order to offer this functionality for Portal visitors, the following must be actioned: | |
|---|---|
| 1. | Enable Request for Copy functionality in Portal configuration
|
| 2. | Add 'Request for copy E-mail' type to the University Organizational unit
|
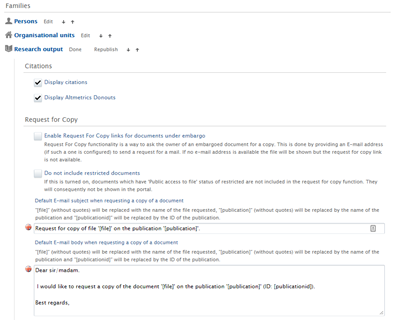
Once the Request for Copy functionality is enabled, all Research Outputs with status embargoed will have a Request for Copy e-mail link available. When the embargo passes, the Portal page will automatically update to make the file available directly in the Portal.
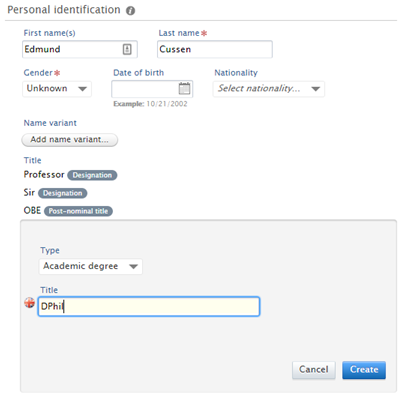
3.6. Display Person title(s)
We now display Person title(s) (e.g. Dr, Professor) in the Pure Portal.
Click here for more details ...
From 5.8, the Pure Portal now displays titles from the Person record. Where multiple titles have been input, they will appear in the Portal in the order they appear in the Person editor.
4. Import module
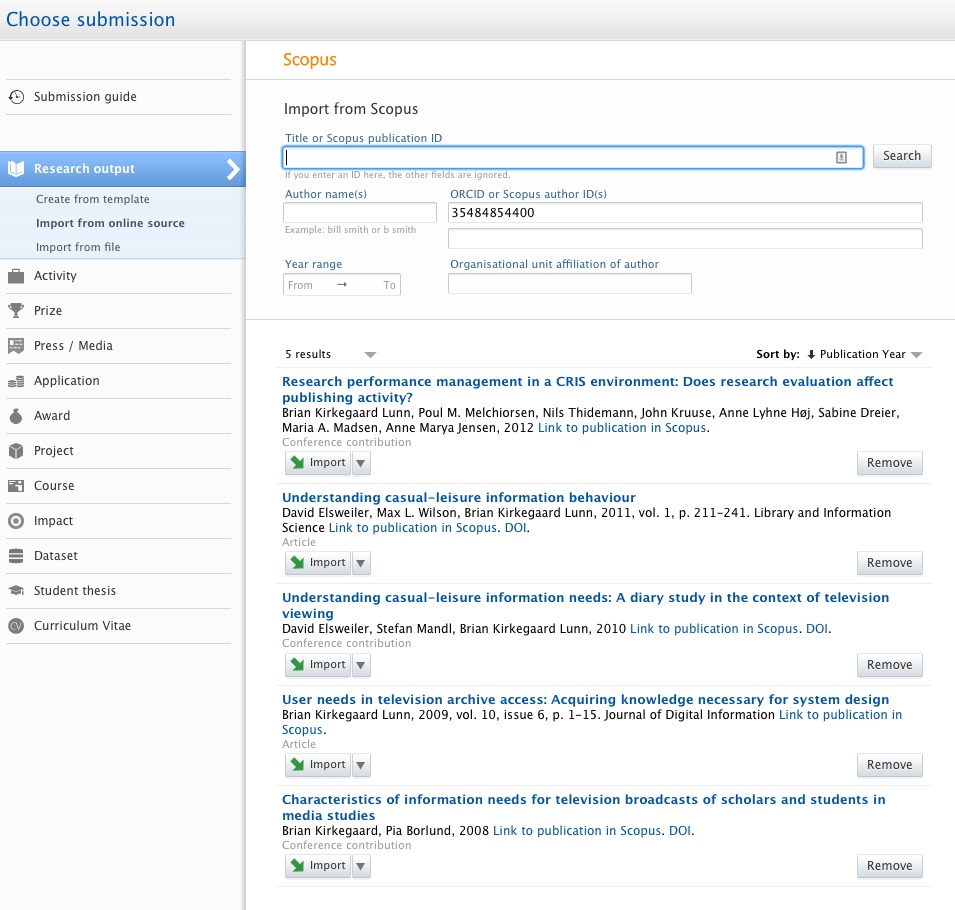
4.1. Search on Scopus Author ID when importing from Scopus
It is now possible to precisely search for all publications by one or more particular authors in Scopus, using Scopus Author IDs and/or ORCIDs in the specified search field.
Roles affected: Personal users, Editors of Research output, Administrators
4.2. Updated handling of author organisation associations in WoS importer
We have improved the Web of Science (WoS) import function to better handle multiple organisation names in the address tag, indirectly improving name matching during the import process.
Click here to expand…
When importing content from WoS, multiple organisations in the address tag would result in a single organisation with all the organisation names concatenated into one string (e.g. "Fac Chem, Dept Biochem, Univ Belgrade, University of Belgrade"):
This has been improved such that Pure interprets these as multiple organisation affiliations rather than one, indirectly improving name matching during the import process.
- Fac Chem
- Dept Biochem
- Univ Belgrade
- University of Belgrade
Roles affected: Editors of Research output, Validator of Research output, Administrators, Technical administrators
5. Web services
5.1. Early access to new Web service
Today's Pure Web service is a useful and powerful tool for many of our customers, enabling the extraction of Pure data for use in local web pages, local systems, etc. However, using the existing Web service is complex and there is a steep learning curve. Additionally, the maintenance required sustain the Web service is increasing.
Therefore, we announced in 2016 that we would introduce a new and improved Web service in June 2017 with Pure 5.9. The 3 main focus areas of the new Web service are:
- Developer-friendly design including better, more intuitive XML and newly added JSON output
- Content access control
- New delivery model where every new Web service version follows the Pure major releases starting with Pure 5.9
In order for you to get a technical preview of the new Web service, this release includes early access to the new Web service, due for full delivery in 5.9.0 (June 2017) (59_ea). The purpose of this early access is to provide a downsized preview of the version that will be released in 5.9.0. The existing Web service is not affected and will be available until June 2018.
Click here for more details ...
This early access to the new Web service is intended to provide you with:
- a better understanding of how the Web service will work from 5.9.0
- a look at the updated user interface
- a preview of the Web service content access control, which is set in the Pure backend
As we are providing early access to the new Web services prior to completion of the update, you should note that changes may occur prior to the full release in 5.9. It is not intended that Web service users will start programming using this early access version as a firm foundation.
We welcome any feedback you may have; please contact the Pure support pure-support@atira.dk
The early access is limited to include 2 endpoints:
- Organisational units
- Persons (limited to listing all Persons and details for a specific Person)
You can preview the new GUI designed for the Web Service. This new graphical interface is designed using Swagger.io and allows the developer to get an easy overview of the endpoints, the filters available, as well as the possible parameters that apply for every endpoint. An example is that it is possible to switch between the new XML and JSON output formats. Additionally, this graphical interface provides both "Request URL" and "Curl" when making a query.
In order to view the new graphical interface you need to go to this link https://your-path/ws/api/59-ea/apidoc/index.html
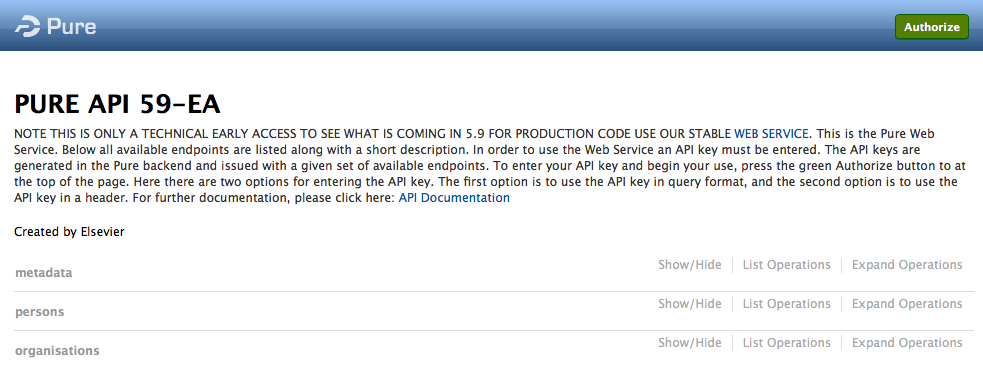
A key addition to this early access is the user access control that determines which endpoints a given Web service user is able to use. The setup of the access control is performed in the backend of Pure using API keys. An API key can be generated and setup to show all (admin), or one or more content types (check box), and it can also be temporarily disabled. Additionally, an API key can tagged with an expiration date.
Each API key has a description field allowing the Pure administrator full overview of the Web service users. Before the Web service can be used, the API key needs to be entered in the GUI shown above. This is done be clicking the green "Authorize" button.
Go to Administrator > Security > Api keys in order to create the API keys for web service. Click on the button "+ Add new API key".
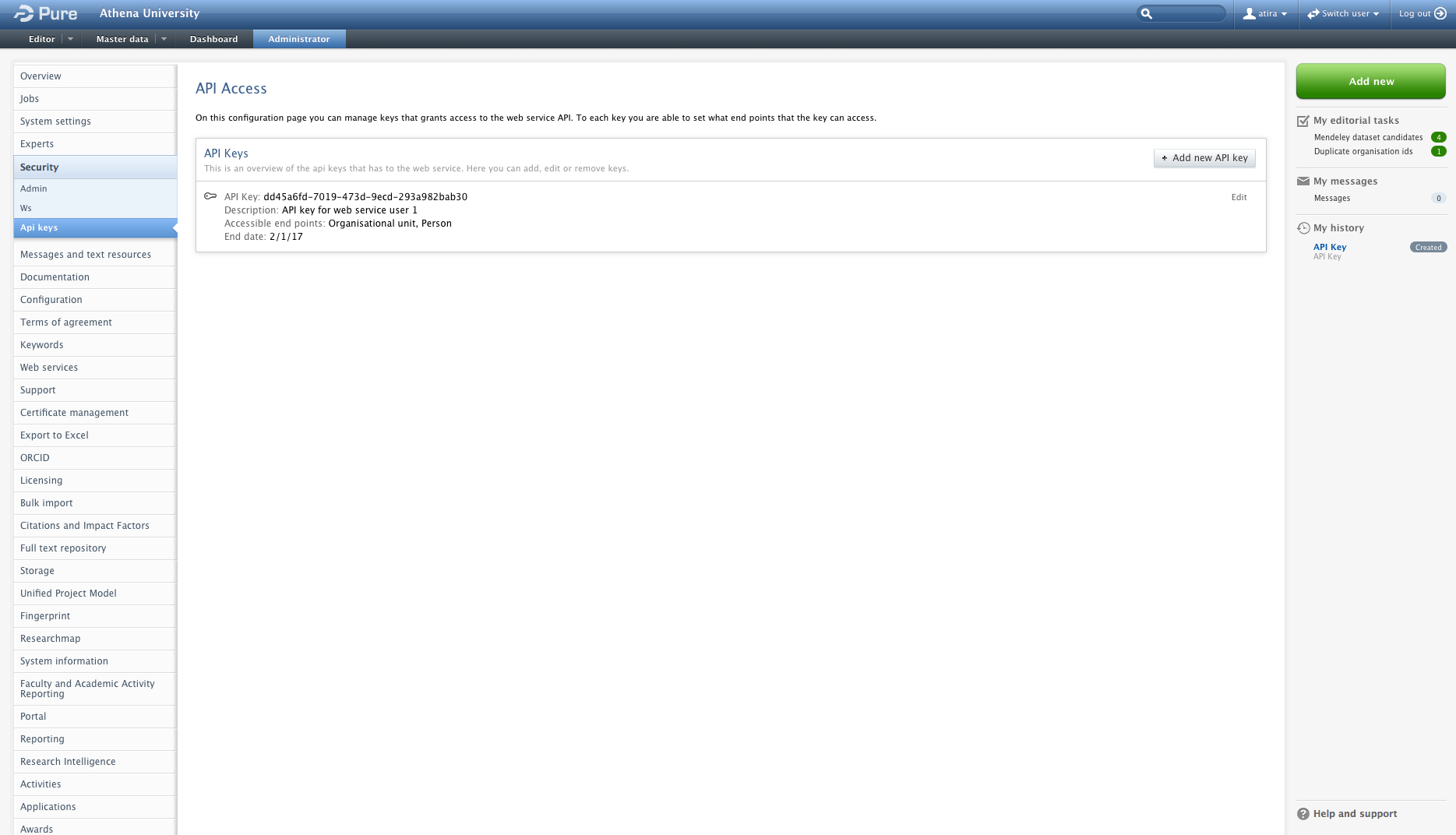
A new window will appear, in which the new API key is auto-generated, and where it is possible to set the individual rights for a given API key. For each API key a description can be added, along with the selection of which content end points should be visible. An API key can be temporarily locked if necessary or an end date can be set. Finally it is possible to create an API key with administrative rights which will have access to all end points.
6. Country specific features
6.1. Denmark: BFI-integration updates
The integration between the BFI-system and Pure has been updated, mainly in response to changes in the BFI-system as well as an update to the MXD-format used for exchange in relation to BFI. With this update, Pure can now accommodate:
- the BFI-system's new identification of publication channels, whereby e.g., a Journal is not considered unique. As such, Pure will not have to import a version of a Journal for each year it has appeared on a BFI authority list
- update publication channels in accordance with the use of a merge functionality in the BFI-system. Hereby, publication channels (journals, publishers and conference series) are automatically updated if a merge is conducted in the BFI-system
- BFI-level on BFI-publications
- changes to BFI-endpoint configuration
- latest version of MXD (version 1.4.0)
Due to these changes Pure, will have to update all BFI publication channels as part of the upgrade. Consequently, you should expect additional downtime during the upgrade. While the length of downtime will depend on the number of BFI-publication channels in your system, we generally expect it to be approximately 15 minutes.
IMPORTANT NOTICE: The BFI-system expects to update to MXD 1.4.0 by February 1st. Harvesting publications from Pure to the BFI-system will fail until Pure is upgraded to version 5.8, which includes MXD version 1.4.0
Click here for more details on BFI-integration updates
Publication channel identification
The BFI-system has reverted the means of identifying publication channels (Journals, Publishers and Conference proceedings) to use BFI-number for identification, whereby Pure is not forced to have a version of the publication channel for each year it has appeared on a BFI authority list. In addition to changing the approach for identification, all duplicate BFI-publication channels will be merged upon an upgrade to 5.8.
Upon upgrade, there should only be one version of a publication channel independent of which years it has appeared on a BFI authority list.
Publication channel merge
The BFI-system has added a new feature whereby they can merge duplicate publication channels in the BFI-system. Consequently, the synchronisation of BFI publication channels in Pure will automatically update and merge Journals in Pure in accordance with a merge of publication channels conducted in the BFI-system. Pure will therefore reflect merging conducted in the BFI-system.
Merging of publication channels uses the regular merge functionality in Pure. This means that for Journals, any related content will maintain Journal title and ISSN since existing Journal title and ISSNs will be added as Title or ISSN variants. For Publishers and Conference series, the Publisher or Conference series name will be changed on all related content.
BFI-level on BFI-publications
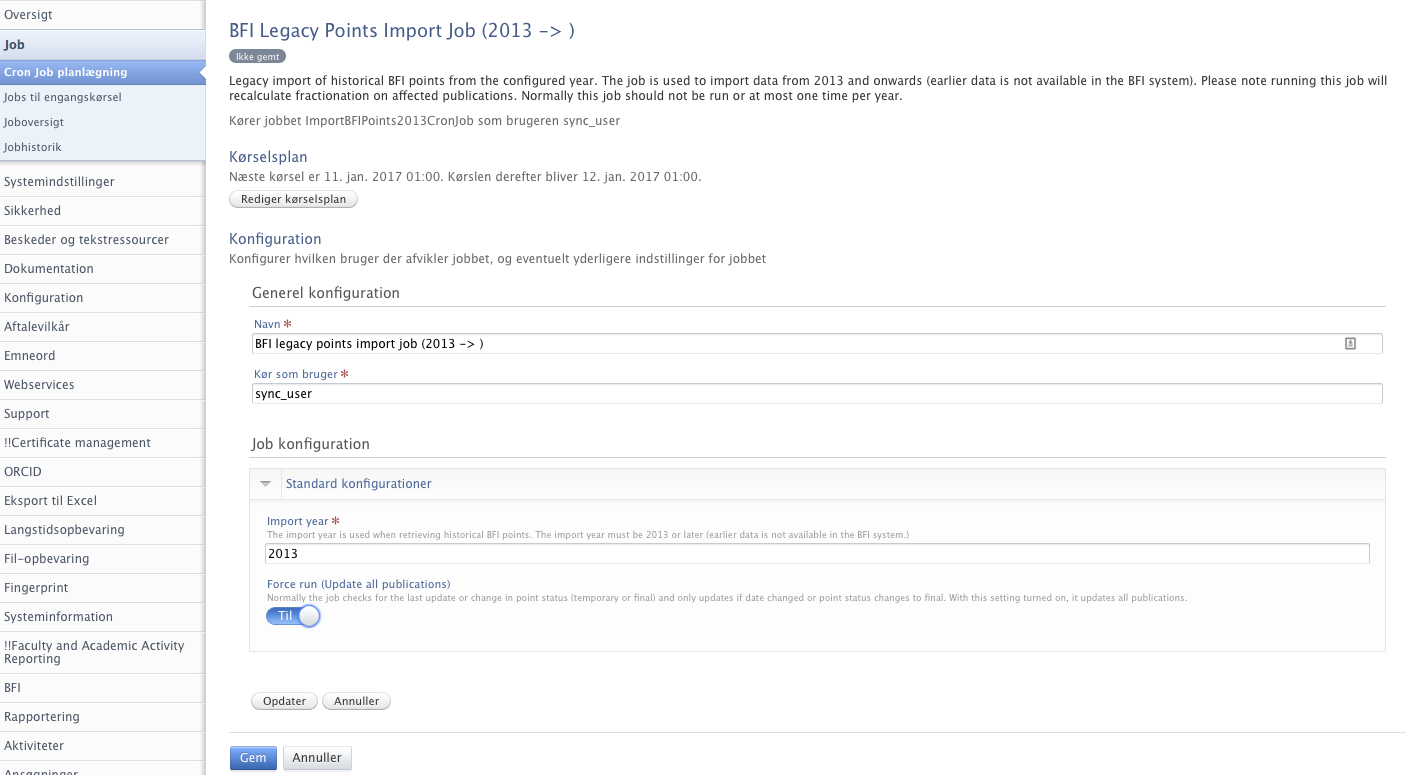
From 5.8 BFI-level will be synchronised to the publication in Pure when the level is available in the BFI-system. Hereby, each publication from current or last year will automatically have level added when new information is synchronised with Pure from the BFI-system. If BFI level is needed for publications from previous BFI-years you will have to run the job 'BFI Legacy Points Import Job (2013 ->)' which will re-import BFI-point for publications from the specified year. The setting 'Force run' should be enabled to update all publications even though no changes have appeared. NOTE : BFI-data will be updated for all publications, including BFI-points per person.
Latest version of MXD
Pure has been updated to support DDF-MXD version 1.4.0, which includes the following:
- Roles for persons on publications. MXD now holds a person role of 'Other'. If roles are added to the classification scheme for roles on publications, these will all be mapped to the 'Other' role which does not qualify for BFI-points.
- The 'Other' publication type in MXD has been updated with a field for Year. Pure will add current year to this field. The benefit of this new field is that the BFI-system is now able to process publication years for all publications, and hence you should see a big change in the number of publications that in the BFI-system marks as errornous due to an invalid publication year.
The new DDF-MXD format is available here: http://mx.forskningsdatabasen.dk/mxd/1.4.0/
6.2. Denmark: Update to import source Bibliotek.dk
The Danish import source Bibliotek.dk has been updated, so that it now uses the newest version available from DBC. This means that the content is now provided in danMARC2 (previous content was presented in MARC21). For the Pure users this will pose no significant changes, although a few additional search options have been added.
Before using Bibliotek.dk it is necessary to have your IP address opened. Please contact DBC service desk for further assistance.
Click here for more details on the bibliotek.dk import source
To enter the setup page go to Administrator > Publications > Edit (next to Bibliotek.dk).
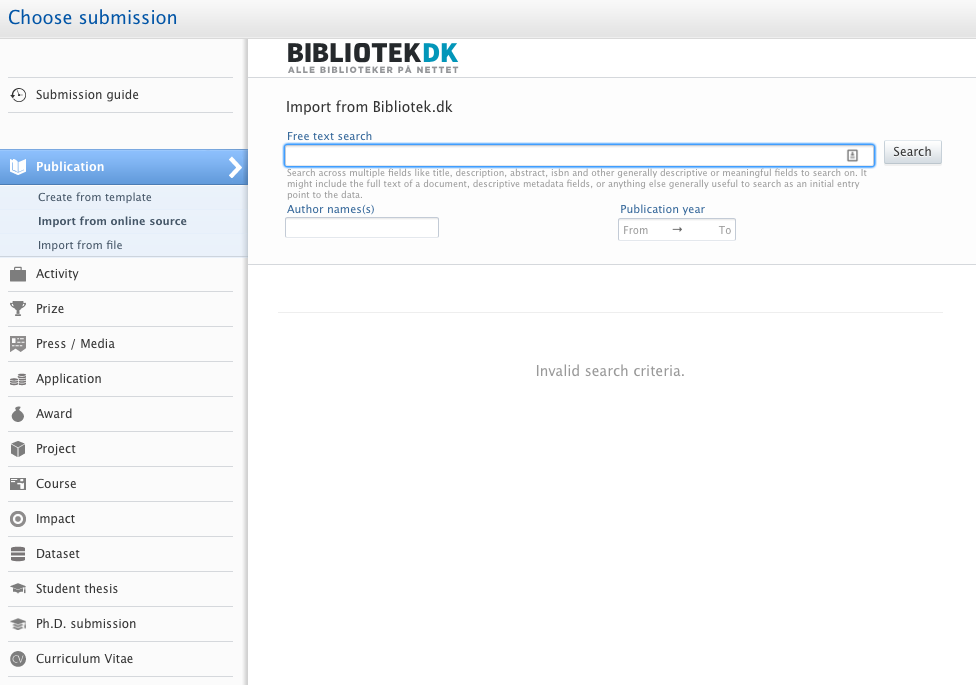
The following page will then appear. Check the "Enabled" box to activate the source and then press "Save"

When making a search from bibliotek.dk the window now looks like this:
Note
Due to an error at DBC, the indicated number of search results found, may differ from the actual number. DBC is currently correcting this.
6.3. Australia : ERA2018 module released
5.8 includes the release of the ERA2018 module, which builds on existing ERA2015 functionality and delivers:
- a 're-badging' of the ERA module as ERA2018
- appropriate updates to reference periods
- functionality enabling institutions to define their own mapping to ERA output types
Further details, including guidance notes, user guides, and reference material, are available in the ERA2018 wiki.
This first phase of ERA2018 module development will enable customers to begin ERA2018 submission preparation in Pure, with ERA Researchers and ERA Research Outputs functionality available for use. Future development plans are available at ERA2018 module development plans and timescales.
6.4. UK : REF2020 : REF1a/c bulk actions
We have expanded the number of bulk actions available for REF1a/c content, enabling more efficient use of the REF module.
Click here for more details on REF1a/c bulk functions ...
We have expanded the number of bulk actions available for REF1a/c content to include:
- Eligibility status
- Submission status
- UoA assignment
- Workflow (already available)
- Delete content (already available)
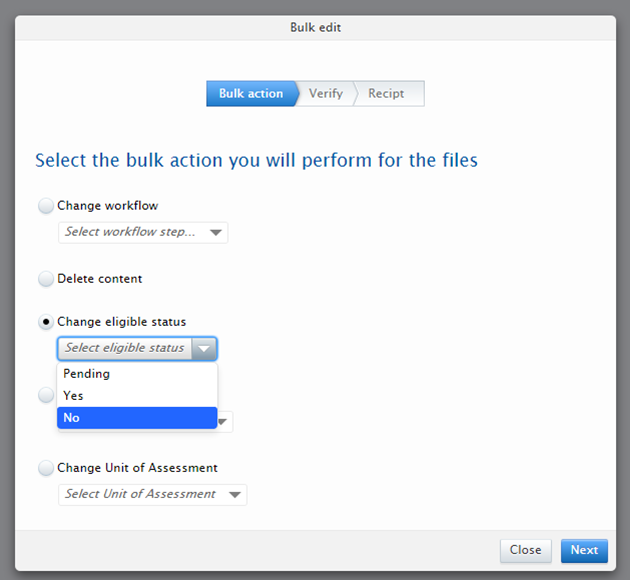
Roles affected: Administrator
Notes:
- As there is a relationship between Eligibility and Submission statuses, there is some logic in place that impacts on the bulk actions:
- If a group of REF1a/c records that are currently flagged as Not Eligible are selected to be bulk moved to Submission status = Yes OR Pending, this will not be actioned (because, if a REF1a/c is flagged as Not eligible, it cannot be submitted, therefore it will always have the Submission status = No)
- If a group of REF1a/c records are bulk moved to Eligibility status = No, the REF1a/c records will automatically also be moved to Submission status = No
6.5. UK : Enhancements to IRUS-UK integration
The IRUS-UK integration introduced in 5.6 (see 5.6 Release Notes) has been enhanced to include Student Theses and Datasets.
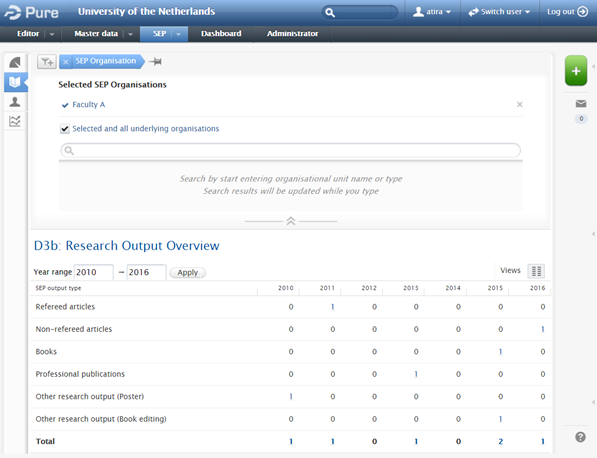
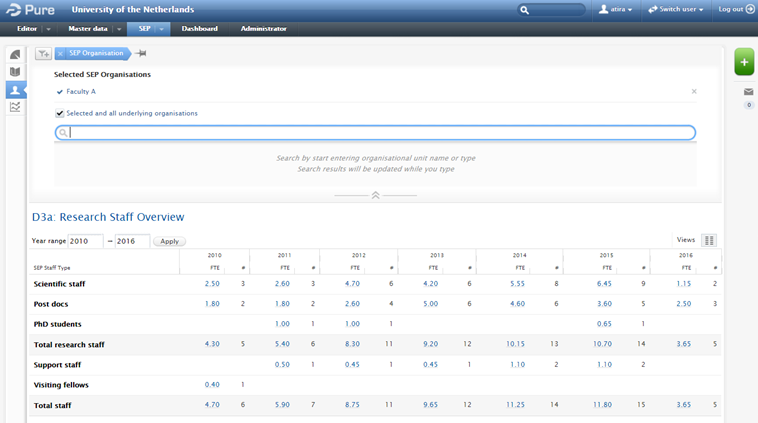
6.6. Netherlands : SEP : Re-introduction of 'selected and all underlying organisations’ function in Organisation filter in SEP summary screens
In response to customer feedback, we re-introduced the 'selected and all underlying organisations’ function in Organisation filter in SEP summary screens in 5.7.3 (4.26.3).
Click here for more details ...
When the function to enable affiliating PhD Theses to the Promoter(s)' Organisational Unit(s), rather than that of the PhD Candidate, was delivered in the 5.6.0 release, this significantly complicated the ability to report SEP content by organisation, such that we were unable to enable the function to filter by ‘selected and all underlying organisations’. This was resolved in the 5.7.3 (4.26.3) release and is now available both in the SEP Outputs table, and in the SEP Staff tables.
 |
 |
6.7. Finland : JUFO : Introducing the Finnish national metric for publishers and journals
In response to requests from our Finnish customers, we have now added the possibility to use the JUFO metric for Publishers and Journals. The JUFO metric has been in use since 2012 and this feature updates all Publishers and Journals since then. The metric is supplied by JULKAISUFOORUMI (JUFO).
Click here for more details on the JUFO metric in Pure
The JUFO metric is now available for Journals and Publishers:
- For Journals, the metric will be matched based on ISSN and subsequently added
- For Publishers, all Publishers available from the source are added in Pure with the corresponding metrics. If there is a 100% name match between a Publisher from the source and Pure, then only the metric is added and the Publisher is not created. Since it is the name alone that is being used for matching, then there is a possibility for Publisher duplicates after the job has run
Note
Some customers may have imported the JUFO metric manually. If this is the case, then both the manually and the auto-imported JUFO metrics will be shown. In order to remove the manually entered metrics, please contact the Pure support team via Client community..
The feature will be available as a cron job and set to OFF as default. In order to switch it to ON go to Administrator > Jobs and locate the job called "Import metrics from julkaisufoorumi (JUFO)"
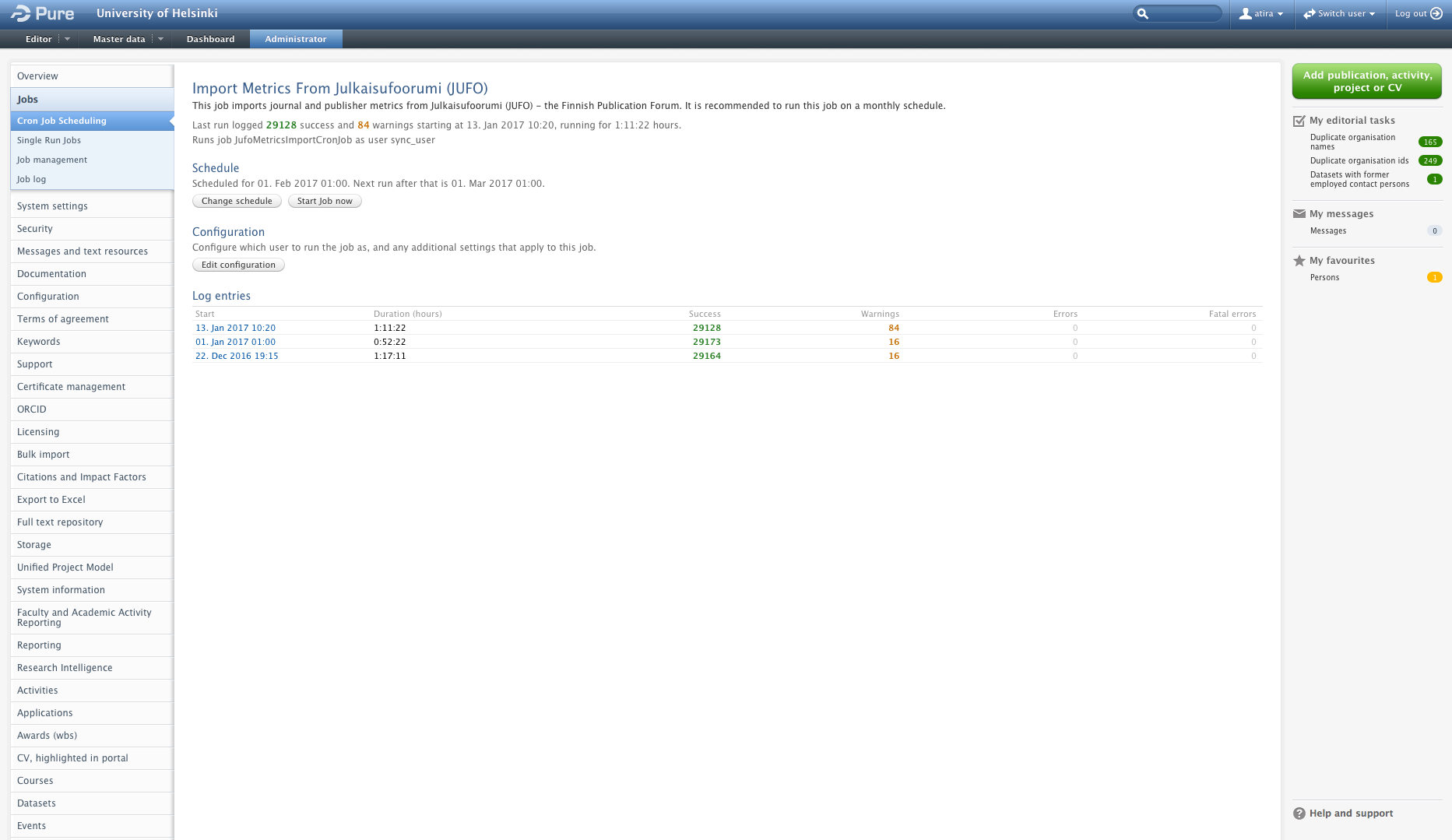
Set the desired schedule (it is recommended to run the job once per month) by clicking the "Change schedule" button. Click the "Update" button. and then the "Start Job now" to run the job.
The job will then run as described. Below is an example of a publisher with JUFO metrics added.
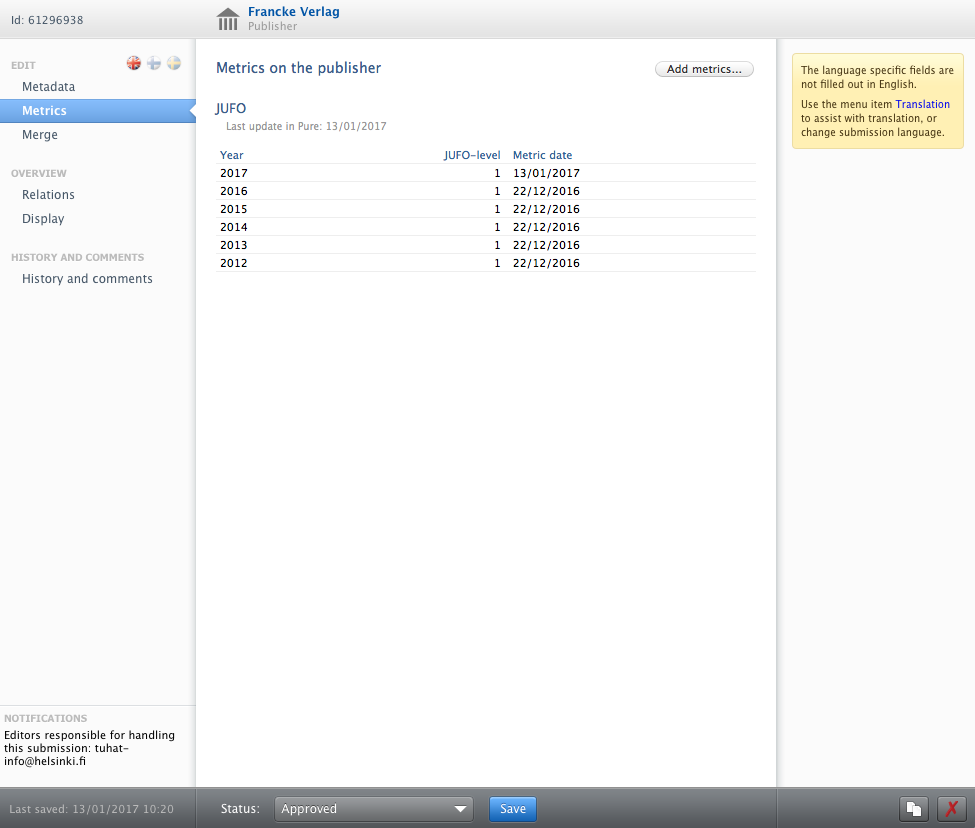
For journals the added metrics are displayed as shown below:
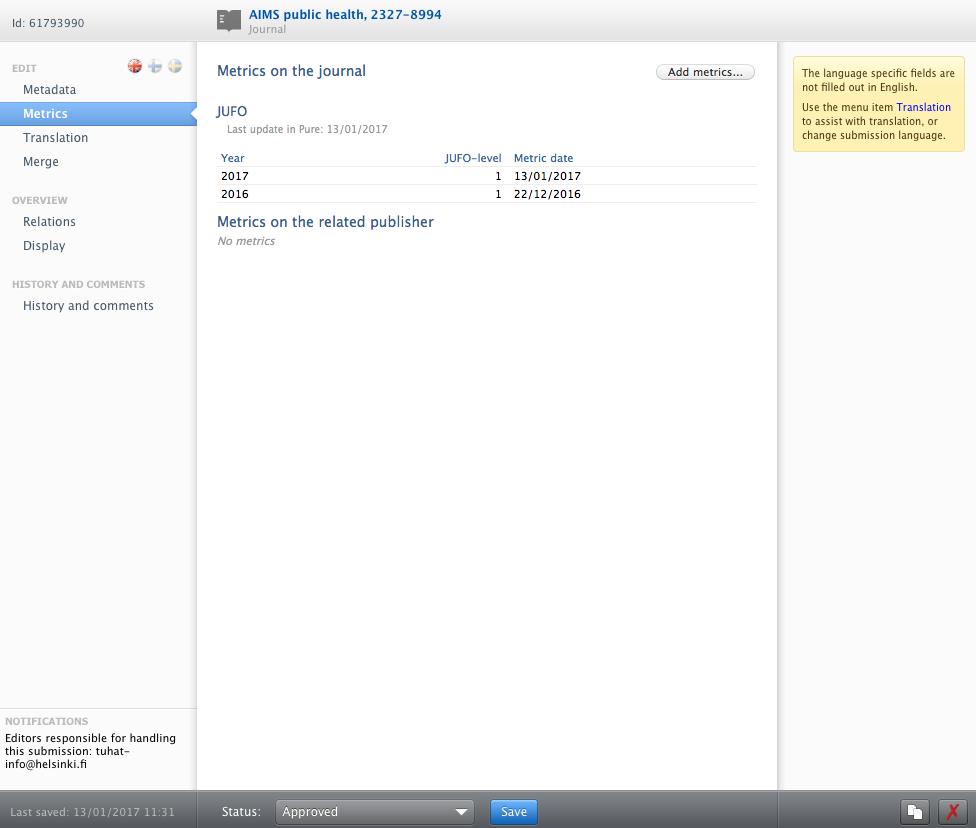
7. Additional features of this release
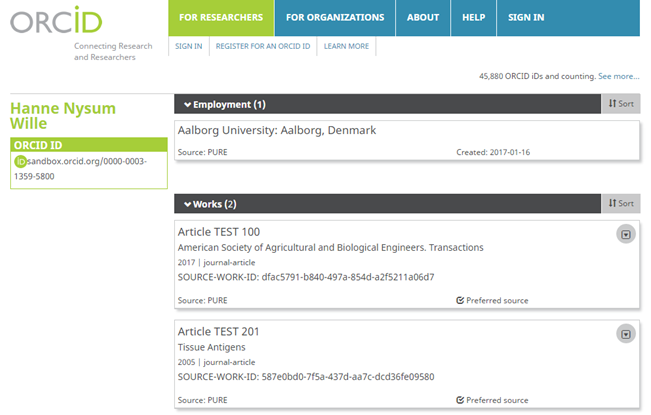
7.1. ORCID integration improvements
This release includes improvements to ORCID integration functionality, namely:
- The export to ORCID is now limited to only include content that has been modified since the last export (released in 5.7.1)
- The configuration to send / not Pure Portal URLs to ORCID has been updated to also include URLs for individual outputs
- Where an individual only has a student affiliation in Pure, this is now exported to ORCID as Education, rather than Employment (released in 5.7.3)
- The export to ORCID now includes all publications on a Person's record, including those wholly externally authored
Click here for more details on the ORCID integration improvements ...
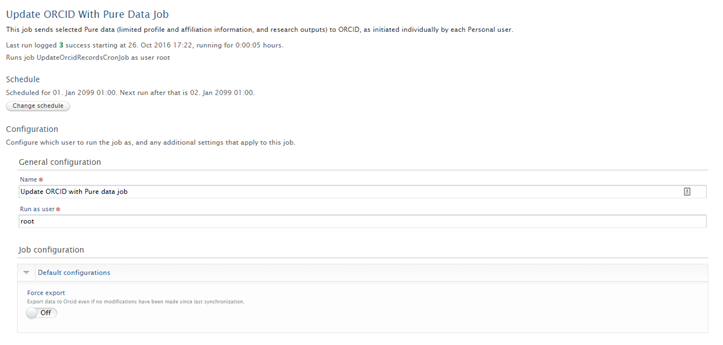
Limit ORCID export to only include content that has been modified since the last export |
|---|
The export to ORCID is now limited to only include content that has been modified since the last export. This then means that researchers will only receive notifications from ORCID when content has actually updated in ORCID, rather than 3 notifications every time the export was run. This is now the default functionality, but it is possible to manually override this by enabling the 'Force export' configuration in the 'Update ORCID with Pure Data Job' configuration. After the job is run, the 'Force export' configuration will automatically return to the disabled state (you may need to navigate away from the page and return in order to see this).
Notes:
|
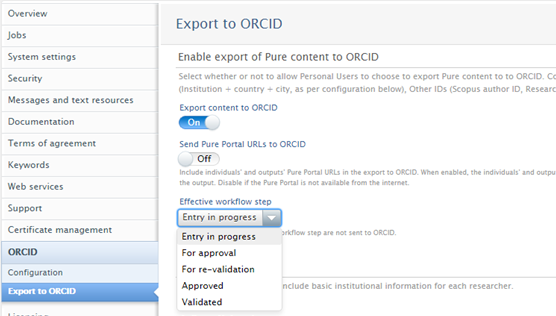
Configuration for Pure Portal URLs to ORCID | ||
|---|---|---|
The existing configuration for sending Pure Portal URLs to ORCID has been updated such that when disabled, not only will individuals' Pure Portal profile URLs be removed from ORCID, but also the Pure Portal output URLs. When enabled, the individuals' and outputs' Pure Portal URLs will be visible as hyperlinks in the individuals' ORCID page, thereby giving ORCID readers the opportunity to navigate to the Pure Portal for further information on the researcher and the output. This configuration should be disabled if a Pure Portal (whether a Custom Portal or the Pure Portal) is not available from the internet.
|

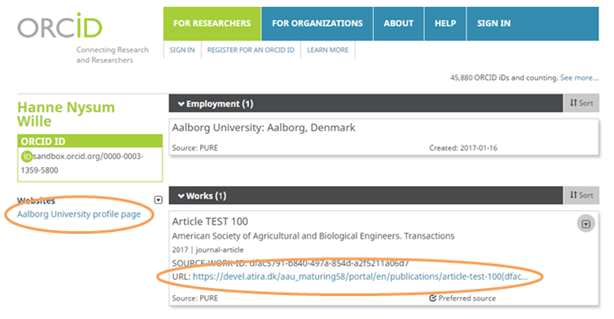
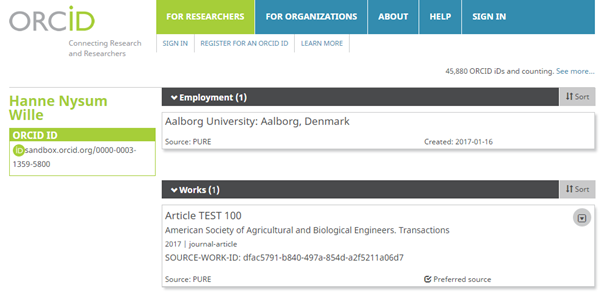
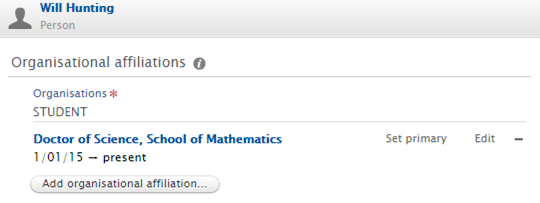
Student affiliations | ||
|---|---|---|
The ORCID integration has been updated to more accurately capture Student affiliations. Where a Person in Pure only has a Student affiliation(s), Pure now sends basic affiliation information across into the Education section, rather than the Employment section. Where a Person in Pure has both staff and student affiliations, no change has been made to the integration; the affiliations will continue to be captured as Employment in ORCID.
|

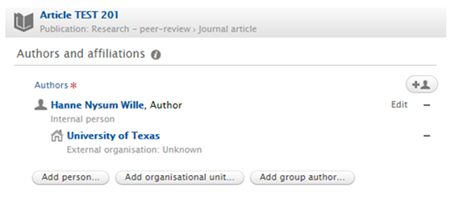
Externally authored publications | ||
|---|---|---|
The export to ORCID now includes all publications on a Person's record, including those wholly externally authored.
Notes:
|
Pure ORCID documentation has been updated to reflect these updates:
- ORCID : Admin Configuration
- ORCID : Functionality for Administrators and Editors
- ORCID : Functionality for Personal Users
Roles affected: Administrator and Personal user
7.2. Press / Media : Newsflo integration improvements
This release includes improvements to Newsflo integration functionality, namely:
- the introduction of new configuration options
- the inclusion of additional sources, previously restricted due to licensing
These improvements give you greater control over the public appearance of Newsflo content on the Portal, and expands the content available from the Newsflo integration to include more high quality, recognisable sources.
Click here for more details …
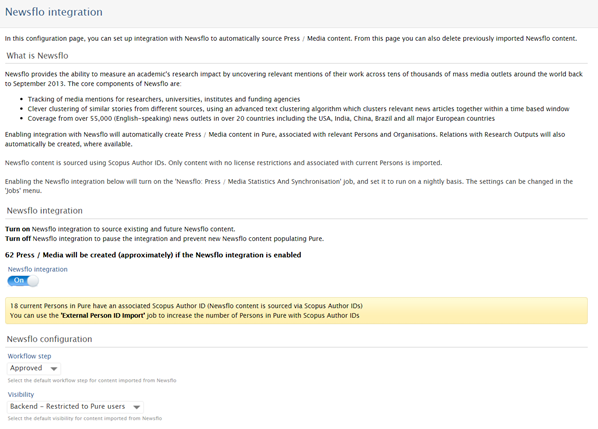
New configuration options |
|---|
In response to customer feedback on Newsflo content, we have introduced two new configuration options, enabling you to set the Visibility and / or Workflow states for Newsflo content upon import, enabling greater control over the public appearance of Newsflo content. These configurations are available at Administrator > Press / Media > Newsflo integration:
|
Inclusion of additional sources |
|---|
|
Newsflo includes a vast array of press / media content, some of which is only available by license. Through discussion with the Newsflo team, we have been able to secure additional content that was previously restricted due to licensing. Note that there are some restrictions placed on this new content:
|
7.3. Embedding Pure inside iframes on other domains
From 5.8, in order to prevent prevent Clickjacking, Pure can only be embedded in iframes running on the same domain as the Pure instance. For certain Intranet use cases, this new restriction may prevent access to Pure. If so, please contact Pure support via Client community for a work-around.
7.4. Change to 'User administrator' role user rights
The rights for the 'User administrator' (for organisations / educations / semesters) roles have been updated such that these roles can now only edit user roles, and no other content on the User record. Administrators continue to be able to edit all aspects of a User record such as editing email address, generating new passwords, etc.
Roles affected: User administrator for organisations, User administrator for educations, User administrator for semesters
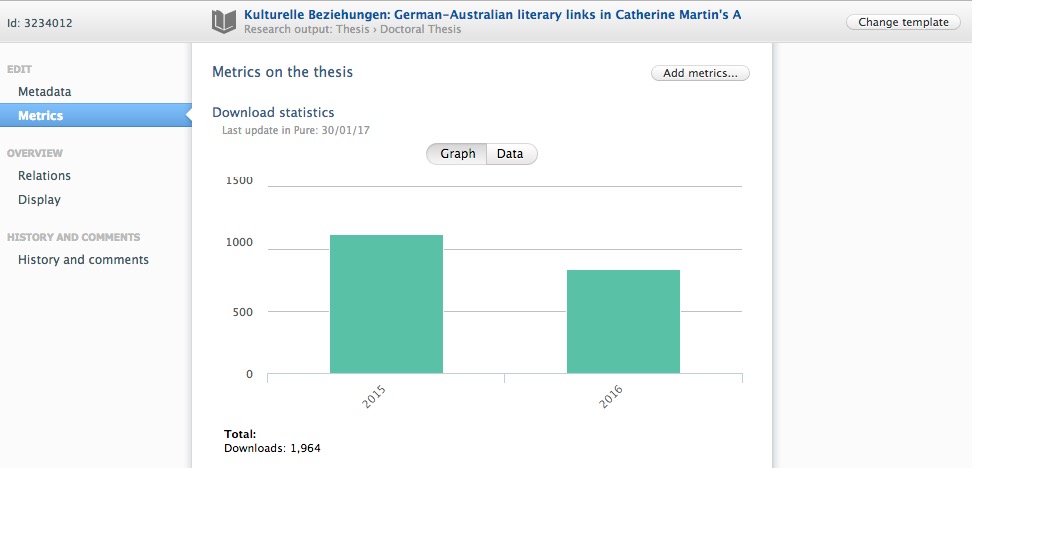
7.5. Number of downloads added as a metric on Research Outputs
Number of downloads has been added as a yearly research output metric, enabling you to report on yearly number of downloads for research outputs.
- The metric tab on research output now contains the number of yearly downloads where available.
- Hereby it is possible to report on yearly number of downloads of research output.
Click for more details
The Metrics tab on Research Outputs now contains the number of downloads per year, where available. Details are as follows:
- the number of downloads includes downloads of Electronic version files from outside Pure's backend (e.g. from a Pure Portal)
- the number of downloads are filtered to generally omit downloads from robots as well as double downloads from one user (within 10 seconds)
- this option is by default enabled, but can be disabled in the 'Filter download information' job
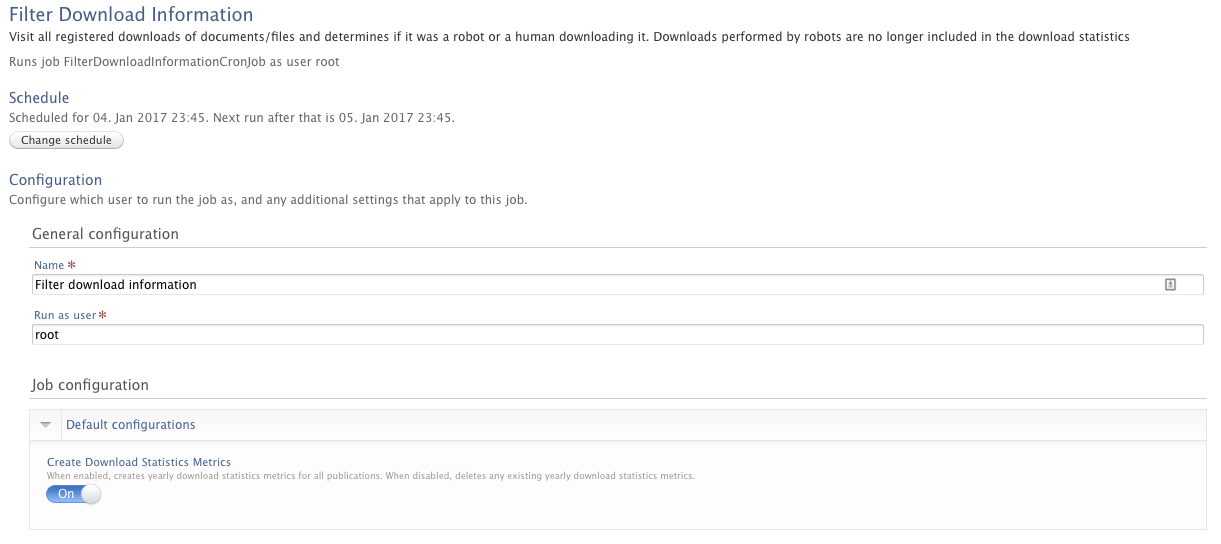
Roles affected: Personal users, Editors of Research output, Validator of Research output, Administrators, Technical administrators
7.6. Sort order for Organisation affiliations on the Person record
We have introduced a configuration that enables you to globally set the sort order of organisational affiliations for a Person. If any sorting is enabled, this will be be implemented for all persons across the whole Pure installation, reflected in both the backend, as well as the Pure Portal and Custom portals (unless customised ordering has been implemented in the Custom portal).
Click here to expand...
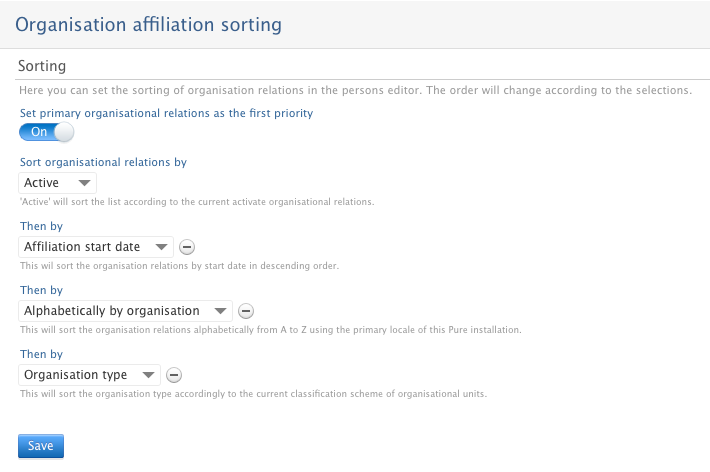
The Administrator can now define the order in which organisational affiliations should appear on the Person record, based on a set of 5 pre-defined sorting criteria.
- All organisations will be sorted as per the configuration - this includes synchronised as well as non-syncheronised organisations
- Sort order in synchronisations are removed, and all sorting is controlled by this configuration
Organisation affiliation sorting is configured via Administrator > Persons > Organisation affiliation sorting. The 5 sort options are
- Primary
- Active
- Affiliation start date
- Alphabetically by organisation
- Organisation type
All five criteria can be applied simultaneously by defining the order in which each criteria is to be used. If 'Primary' is used this criteria will always be the first.
Notes:
- Upon defining a sort order and saving the setting, a job will start that visits all Persons and saves the new sort order. Accordingly, the new sort order is not effective on each Person's record immediately, but will be reflected once the job has visited each Person.
- This sorting is by default be disabled. When enabled, the option to manually sort organisations on a Person is not possible.
- New organisational affiliations added to a Person will be sorted according to the configuration as soon as the changes made to the Person are saved.
- Synchronisation
- Sorting is no longer available in the synchronisation, but should be controlled via this setting.
- Further, if sorting has previously been used in synchronisations, they are no longer effective. If you want the same setting as was used in the previous synchronisation, you should select first 'Active', then second 'Affiliation start date'.
- The synchronisation only sorted synchronised organisations, whereas this setting will affect the sorting of all organisations related to a Person - sync'ed or not sync'ed.
7.7. Omit organisations from SciVal external organisation synchronisation
When synchronising with SciVal, all organisations from SciVal's curated list of organisations are created as External organisations in Pure, which includes your local institution. In this release, we have updated the 'SciVal external organisation synchronisation' job configuration to enable you to select one or more institutions which should not be created as External organisations in Pure.
Further details on omitting organisations from SciVal external organisation synchronisation ...
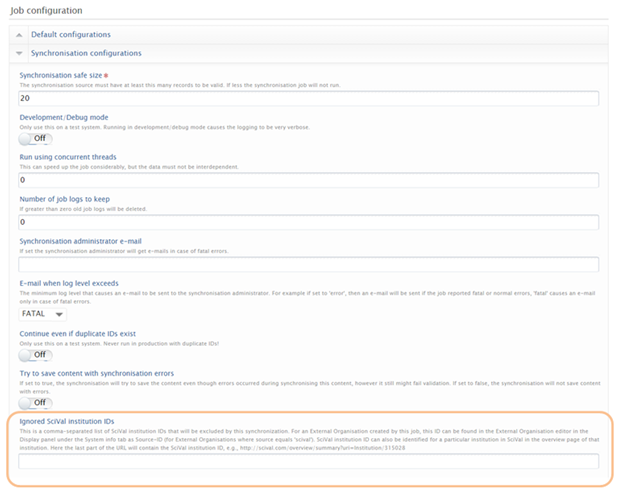
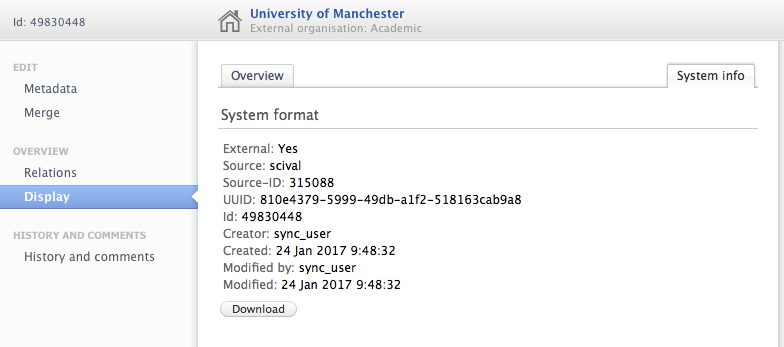
In the Job configuration of the 'SciVal external organisation synchronisation' job, a new field 'Ignored SciVal institution IDs' field has been added. Here you should add the SciVal institution IDs that should be ignored by the job. This is a comma-separated list of SciVal institution IDs that will be excluded by this synchronization. For External Organisations created by this job, this ID can be found in the External Organisation editor > Display panel > System info tab, available as Source-ID (where Source = scival). SciVal instituion ID can also be identified in the institution overview page in SciVal (the last part of the URL contains the SciVal institution ID (e.g. http://scival.com/overview/summary?uri=Institution/315028).
If organisations you wish to omit from the sync have already been imported to Pure, you must first input the IDs into the 'Ignored SciVal institution IDs' configuration and run the job. Once the job is finished, you can delete the affected External organisations from Pure, and they will not be created again the next time the job is run.
 |
 |
Roles affected: Administrators, Technical administrators
7.8. Select Outputs not to be matched by 'Match Scopus IDs for Publications' job
The 'Match Scopus IDs for Publications' job has been updated to allow Administrators to select individual Research Outputs which should be omitted from matching, necessary for those few cases where an incorrect Scopus ID has been assigned to a Research Output in Pure.
Click here to expand…
As the matching of Pure Research Outputs with Scopus publications is done algorithmically (via the 'Match Scopus IDs for Publications' job), in very few cases an incorrect Scopus ID can be assigned to a Research Output in Pure. If the Scopus ID is manually removed from the Output in Pure, it will simply be re-added the next time the job is run.
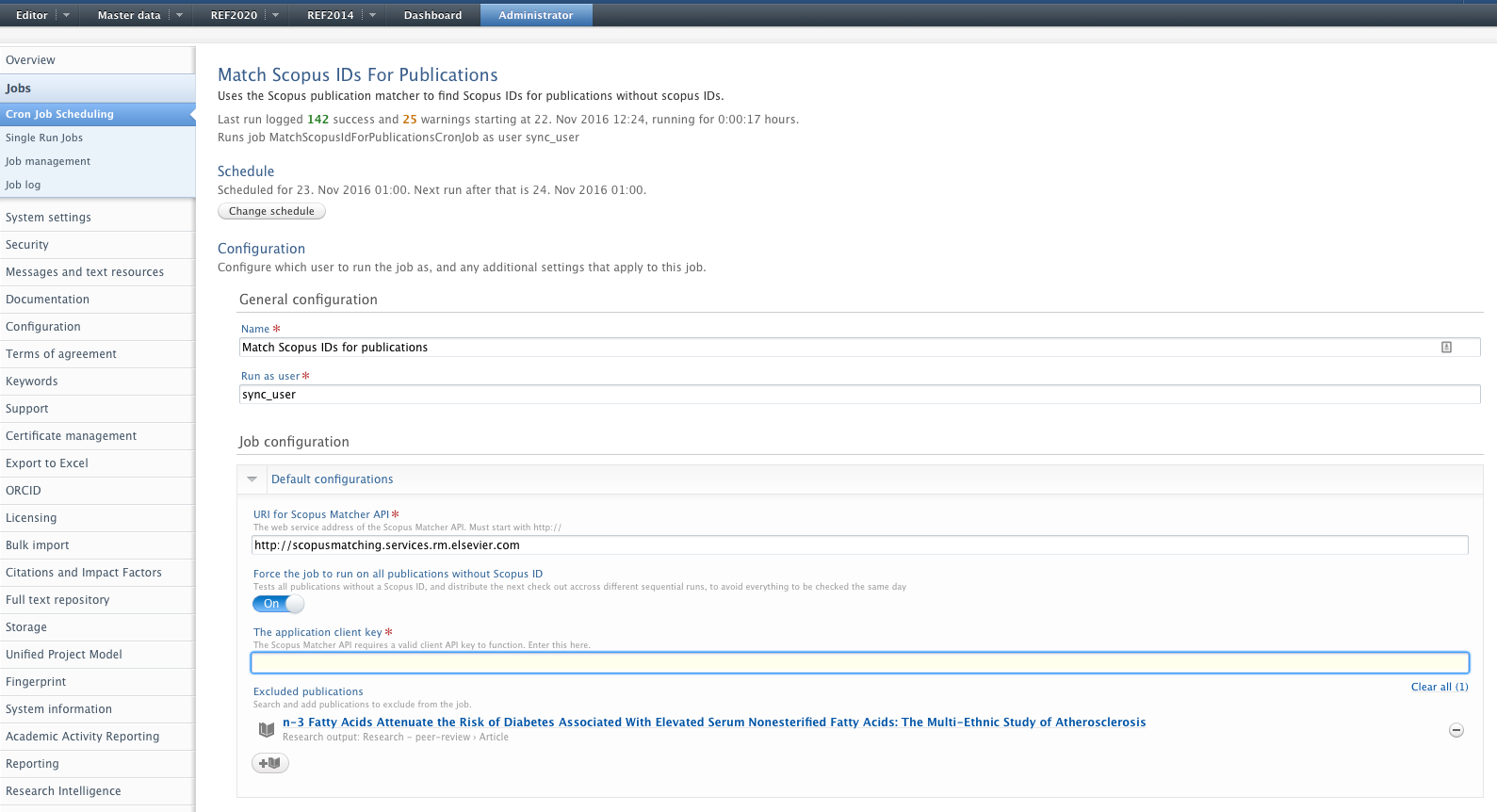
To avoid this scenario, it is now possible to configure the job to exclude such Research Outputs and make no further matching attempts. In the job configuration, there is a new field for 'Excluded publications' where Outputs can be added using a search field. If it is subsequently needed to remove an Output from the excluded list, it can be removed individually or it is possible to clear the list in full.
Note that the job does not remove Scopus IDs from the Research Output records of excluded Outputs; it simply un-syncs the content with Scopus. As such, following the addition of an Output to the excluded list, the Administrator should manually remove the incorrectly matched Scopus ID.
Roles affected: Administrators, Technical administrators
7.9. Update of Scopus Journal synchronisation
The synchronisation of Scopus journals has been updated to synchronise journals previously indexed in Scopus. Running the 'Scopus: Update/create Journals And Metrics' job now:
- updates Journals with previous titles and ISSNs
- automatically merges Journals when these are merged in Scopus
- uses Scopus Journal IDs for matching, which provides more precise matching when importing publications from Scopus
Published at January 11, 2024