
How Can We Help?
Fingerprinting - Core PrinciplesFingerprinting - Core Principles
Fingerprint Engine is a tool that automatically generates a ‘fingerprint’ of key concepts based on the available text data related to a piece of content in Pure (see the table below for details on what data is used for fingerprinting for each content type). These concepts provide a quick snapshot of the key themes / topics covered by the content and can be used during search and filtering. On the Portal, it can also be used for finding similar researcher profiles.
What does the Fingerprint Engine do?
Fingerprint as shown on a profile page:
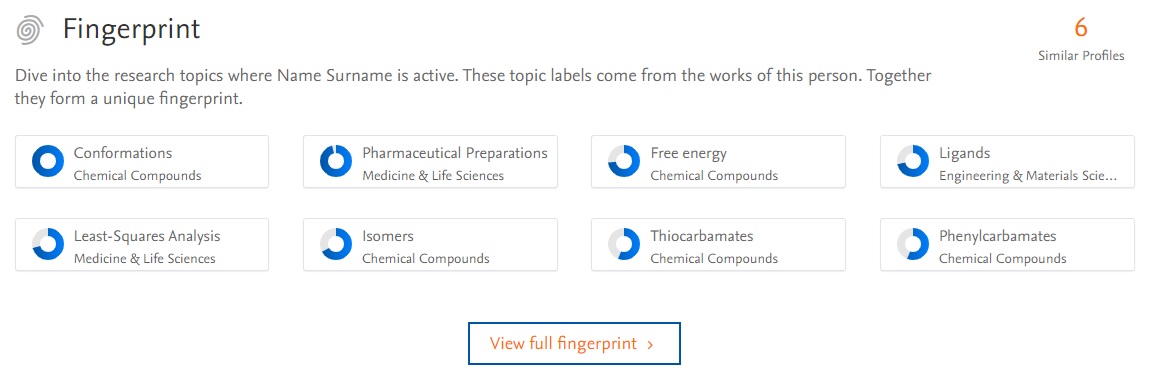
Quick navigation to content linked to a fingerprint concept:
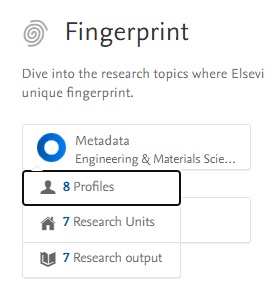
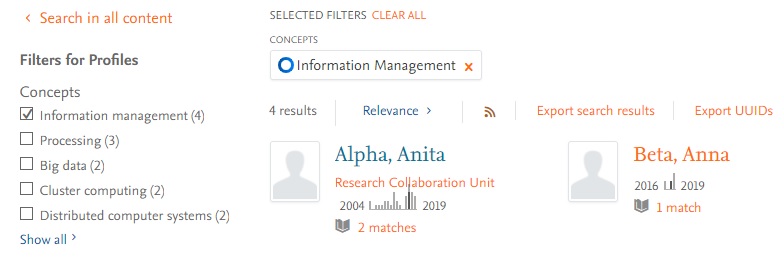
Fingerprint concepts as filters on the search page:
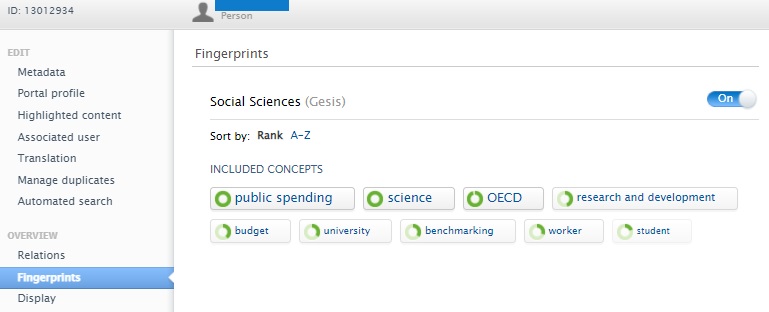
Fingerprints on the Person record in the Pure back end:
What concepts are applied through fingerprinting?
The Elsevier Fingerprint Engine applies concepts from two major sources, which can be configured under Administrator > Fingerprint > Vocabularies for fingerprinting service (see below), and include:
- OmniScience - this is the key thesaurus that contains a wide range of subjects and is the basis of fingerprinting technology.
- Keyphrases - this is an addition to the Omniscience thesaurus which includes multidisciplinary key phrases that make the fingerprint more specific. Please note: we do NOT recommend using the keyphrases thesaurus on its own, it works best combined with the OmniScience thesaurus.
- INIS thesaurus - thesaurus focused on the nuclear physics domain. It is created and maintained by the International Atomic Energy Agency and we recommend enabling it only if your institution is specialised in nuclear physics.
Details of these sources is available in this document:
I do not see the Omniscience, Keyphrase and INIS thesaurus in my settings - why is that?
If your institution has not yet migrated from the old fingerprint engine, we recommend updating to the new fingerprint engine (OmniScience) thesaurus as soon as possible.

Once updated, you will be able to select the preferred thesauri to apply in your Pure:

Please note: the fingerprint update typically takes 24 hours to complete.
What content types are fingerprinted?
Please see the table below for details on how the fingerprint is generated for each of the content types. Some of the fingerprints that are seen in Pure are aggregations, which means that they are recalculated and may change after a new piece of content is added.
Please note: we currently only fingerprint content in English (where the English-language description text is not available, no fingerprint will be generated).
| Content Type | What is the fingerprint based on |
|---|---|
| Research Output |
Title, subtitle and abstract.
Please note: by default, we only fingerprint content where both title and abstract are available. This can be changed in the settings, but we strongly recommend keeping the default approach to improve the accuracy of the generated results. |
| Person (Researcher) |
Aggregated: Research Interests and all research outputs and prizes, linked to the person.
When finding the related research outputs for a Person, it is possible to limit the start and end year of the publications taken into account in Pure settings. By default, no time limit is applied, but this can be changed through Administrator > System settings > Fingerprint service > Start and end year config options.
It is also possible to adjust whether research outputs, research interest and prizes are used as part of person fingerprints. To do this, go to Administrator > Fingerprint > Configuration. |
| Organisation |
Aggregated: all research outputs, linked to the organisation.
When finding the related research outputs for an Organisation, it is possible to limit the start and end year of the publications taken into account in Pure settings. By default, no time limit is applied, but this can be changed through Administrator > System settings > Fingerprint service > Start and end year config options.
Note: fingerprints from the research outputs produced by the persons within the organisation while they were outside the organisation will NOT be included into the aggregation. |
| Research Project |
Aggregated: Project descriptions and all research outputs and awards, linked to the project. Note: all the available descriptions are used for fingerprinting (i.e. if you add multiple types of descriptions, they will all be used for fingerprint generation). |
| Equipment |
Aggregated: Equipment descriptions and all research outputs and projects, linked to the equipment (each item is given an equal weight).
Note: all the available descriptions are used for fingerprinting (i.e. if you add multiple types of descriptions, they will all be used for fingerprint generation). If there is no Equipment description text, the fingerprint will be based solely on related research outputs, if any are present. |
| Prizes |
Prize title and description
|
| Awards |
Award description
|
| Research Institution (total, shown on the Portal Home Page) | Aggregated: all Research outputs from the past 5 years |
It is possible to choose whether fingerprinting results are shown in Pure and/or on the Pure Portal. You can also choose whether the fingerprint is shown on the individual page (i.e. on the Institution’s landing page).
While the fingerprint is generated automatically, it is possible to edit it, making the result more precise. Fingerprint concepts can be removed by going into Pure and reviewing the fingerprint on each content record. If you remove concepts from the list, they will no longer be shown on the given content piece. The content will also not be returned when a search is performed for a previously excluded fingerprint concept.
Please note: it is not possible to manually add concepts to the fingerprint. However, "Research Interests" can be expressed on the Person's profile page as a way of indicating further concepts that the Person is involved in.
Furthermore, content with all levels of visibility is fingerprinted and taken into account when creating aggregated fingerprints. This means that if a researcher has five research outputs, only three of which are public (i.e. shown on the Portal), ALL five will be taken into account when creating the researcher's fingerprint.
Where do the concepts shown in the fingerprint come from?
What is the Fingerprint Engine based on?
Elsevier's Fingerprint Service assigns fingerprint concepts to Pure records using NLP (Natural Language Processing) and ML (Machine Learning) techniques. This is done using the thesauri encompassing a wide range of scientific subject that Elsevier has created over the years and reviews continuously.
Customer data is NOT used to train Elsevier's NLP and ML matching routines. Only Elsevier's own test training sets are used. The assignment of Fingerprint to records in Pure is not "absorbing any learning benefit" from Customer's data.
This use of NLP and ML devised routines is not a Generative AI: we do NOT generate new documents or knowledge from your Customer Data. We also do NOT generate new terms to add to the thesaurus from the data submitted in for fingerprinting.
We do not retain any customer data sent to the fingerprint and do not keep any statistics on which concepts are assigned.
How is the fingerprint for an individual piece of content created?
In a nutshell, the Elsevier Fingerprint Engine uses the following steps to create the fingerprint for an individual piece of content added into Pure:

Here is a more detailed view of how the Fingerprint is generated:
The Elsevier Fingerprint Engine applies a variety of Natural Language Processing (NLP) techniques to mine the text provided (i.e. description, publication title and abstract) for the key concepts. The key concepts that define the text are then identified in thesauri spanning all the major scientific disciplines, helping us to identify:
- the key scientific area(s) to which the content relates
- the main concepts (those achieving highest ranking) that should be included into the fingerprint for this content
Within each fingerprint, concepts are ordered and given a weight. This weight indicates how relevant each concept is to the text that was fingerprinted. They are calculated based on the frequency with which each concept is mentioned and based on where they are found (title or description). Please note that the highest weight is always given to concepts found in titles, and to the most frequent concept found in the remainder of a text; weights for the remaining concepts are calculated based on their relative frequency.
If needed, several fingerprints are aggregated. To do this, we follow the process below:
- All the individual relevant fingerprints are added together into one fingerprint with all the concepts and thesauri used by each publication combined.
- The ranks for reoccurring fingerprint concepts are added together (this would normally result in a ranking well over 100% for the most popular fingerprint concepts).
- The fingerprint is normalised, so that the highest ranked concept is now considered to be 100% and all other concepts are then compared to this concept.
The resulting fingerprint is then displayed on the Pure back end and Pure Portal (where relevant).
You can find out more about the technology behind the Fingerprint Engine here.
Frequently Asked Questions
How do I optimise my content for fingerprinting?
In order to generate the fingerprint, the content needs to have a title and a description (abstract) providing an overview of the content piece.
At the moment, there is no restriction on the number of words that must be included, but our tests show that a title of 5-15 words and a description (abstract) of 150–300 words would produce a good fingerprint. Please note that there is no need to shorten your description if it is longer and the system will take all of the available content into account (not just the first 300 words).
How can a fingerprint change over time?
Fingerprints shown in Pure can change over time for two key reasons:
- This is an aggregated fingerprint: when a new component for an aggregated fingerprint is added, the aggregation is recalculated. For example, the researcher’s fingerprint is an aggregation of the fingerprinting results for their research interests and all research outputs and prizes linked to the person. When a new research output is added, the fingerprint for the person is recalculated. This may lead to new fingerprint concepts appearing in the person’s fingerprint, a new subject matter area being added in, or some of the fingerprint concepts gaining more or less importance (weight). This is the most frequent reason for a change in fingerprint.
- There is an update in the thesaurus version: major updates to the thesaurus are not frequent, and are mainly focused on adding new terms or optimising the existing vocabulary (e.g. removing the terms that are no longer used, replacing terms with a better alternative). An update to the thesaurus may lead to a change in the resulting fingerprint.
Does Elsevier use my fingerprint in any way? Where is this data stored? Is it linked to any personally identifiable information?
Pure sends text fragments that describe subject matter (i.e. Title and Abstract for research output, research project description, researcher’s research interest descriptions) to the Fingerprint Engine, which returns sets of weighted concepts that were mentioned in those fragments (known as fingerprints). This fingerprint is then stored in Pure and can be displayed on the Pure Portal.
Where needed, fingerprints are aggregated to Researcher or Institution level. This process happens entirely within Pure and does not involve the Fingerprint Engine.
Please note: no personally identifiable information is passed on to the Fingerprint engine as it operates on research text fragments only. Information such as researcher names and titles, organisation and project names are NOT, therefore, submitted to the engine and are stored only in Pure. When aggregations are created, no personally identifiable information is used either.
Does Elsevier Fingerprint Engine store or use my data?
When text is sent to the Fingerprint Engine, the resulting fingerprint is returned without anything being stored by the Fingerprint Engine in the process.
The concept extraction by the Fingerprint Engine itself is periodically tested and improved using test data. This process is completely independent from Pure. Incidental extraction errors reported by Pure customers are much appreciated and allow us to deliver high quality fingerprints and further improve accuracy and quality. An error report (as submitted through JIRA) typically results in the Elsevier Fingerprints team adding an example sentence that triggers the extraction error to the evaluation set, to test whether subsequent engine improvements have resolved the error. For this evaluation set, no customer reference is stored, only the offending text fragment.
I want to exclude certain terms, how can I do that?
There are two ways in which you can exclude certain concepts from your results: exclude specific terms from an individual record or exclude word types from the entire Pure.
To exclude fingerprint concepts from an individual record, login to pure and edit the record you want to modify. In the Fingerprints section you can remove unwanted fingerprint concepts and they will no longer be shown for this record.
It is also possible to exclude certain types of fingerprint concept - for example, names of places or people - from ALL of your fingerprinting results.
We exclude generic terms from all Fingerprinting results by default. You do not need to do anything if you are happy with the results; however, we encourage all customers to review the exclusion list settings in case they would prefer to block some additional lists. You can do this at Administrator > Fingerprint > Configuration.
Please note: if you change the settings, the content will be re-fingerprinted and then re-published to portal, so it may take some time for the content to appear on the Portal.
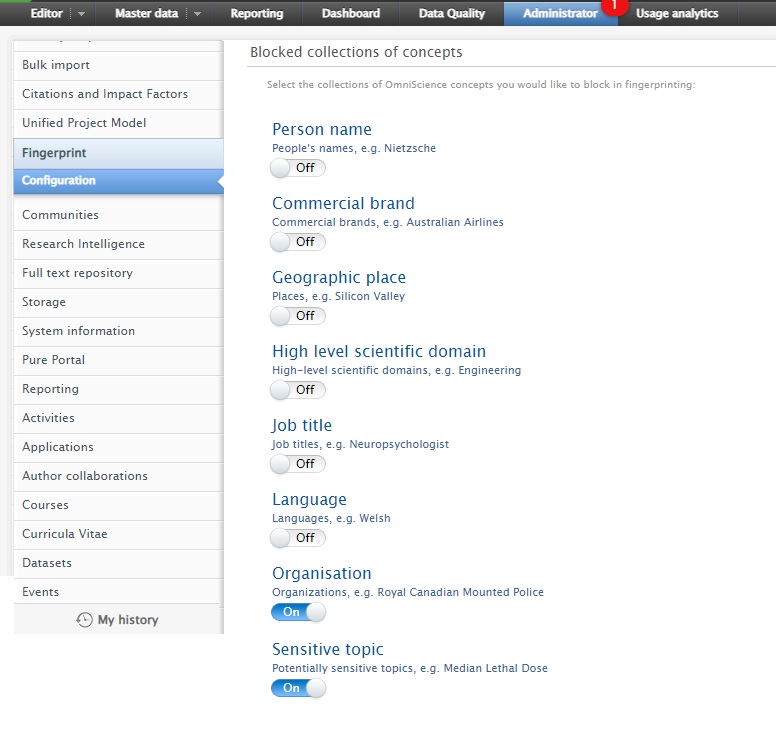
The lists of excluded terms are maintained by the Elsevier Omniscience thesaurus team. "Sensitive topic" simply means that the intended use may not be appropriate for all contexts and purposes globally, it is not a judgement about any topic.
You can view the latest version of the Sensitive Topics exclusion list (turned on by default) here
Please note: this list will go into effect from the 15th of October 2025. An earlier version of the list is applied before that.
The sensitive topic exclusion list is enabled by default allowing your institution to chose for itself whether to include and use these terms in the assignment of labels on individual records and persons. If you would like to adjust this and ensure previously excluded sensitive concepts are shown across all your existing content, please adjust the setting and then re-fingerprint all content (you can request the re-fingerprinting by submitting a ticket to Elsevier Support team).
What do the different terms on my fingerprint reporting mean?
Concept rank: When a concept is used more than once the ranks are added together, so when this process is done the rank of the highest concept is much more than 100% because they are added together.
We therefore normalize the fingerprint, so the highest ranked concept is now considered to be 100% and all other concepts are then compared to this concept. I.e. if the top concept has a rank of 1000% and another concept has a rank of 100%, then after normalization the rank of that concept would be 10%.
Concept weight: How does a term/concept get weighted?
The fingerprint engine computes (amongst other scores) absolute frequencies of concepts. These are calculated by counting how often the terms of a term of a concept appears in the text. For instance, “fMRI and functional Magnetic Resonance Imaging” would contain two terms of the same concept.
Concept weighted rank: After a fingerprint has been normalized (described above) we remove concepts with a weighted rank less than 5%.
How do I re-fingerprint all my content?
It may sometimes be necessary or advisable to re-fingerprint all your content in Pure. To do this, please raise the ticket with Elsevier Support.
Internal documentation on full re-fingerprinting is available here.
Published at October 27, 2025