
How Can We Help?
Data synchronisationsData synchronisations
Who is this page for?
This page is intended for clients who have recently bought Pure, or a new part of Pure, and are currently or will soon be working on an implementation project with a Pure Implementation Manager. It provides general information that is applicable to all Pures; your Implementation Manager will help you address the details specific to your individual case.
Introduction
Integrations with external systems (e.g. your HR system) are made using data synchronisation. To transfer data from an external system to Pure, you'll create a Custom Converter which converts the data to XML files and pushes them to an Intermediate Store. You can then schedule Pure to pull the XML files from the Intermediate Store, convert the data and store it in the Pure database. When data changes in the external system, the changes will be reflected in Pure after the next pull of XML files.
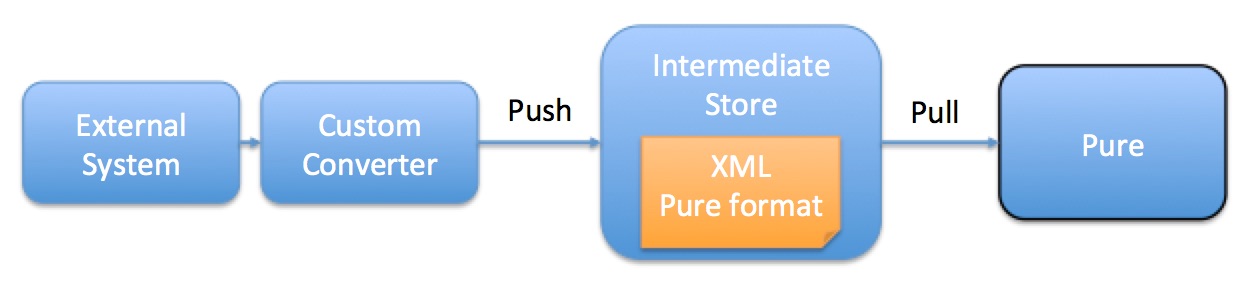
The process of copying your backend data to Pure via intermediate XML files accomplishes two things:
- It completes the mapping of your data to the Pure data model. After you have mapped the data from your external system to the Pure XML format to create the XML files, Pure can then map the data from the Pure XML format to the internal Pure data model.
- Since it does not couple Pure to your external system in any hard way, the data model of your external system and the internal Pure data model can change without the other end needing to adjust (though the Custom Converter may need to be updated if either of these events occur).
The intermediate store in the image above is a web server hosted by you. Pure must be able to pull the full XML file from a URL. The XML Pure format is defined by schema files (XSD) provided by Elsevier.
For Pure to pull data on a regular basis from the intermediate store, Pure has a synchronisation job for each content type.
Goals
- Introduce you to the process of setting up a synchronisation
Implementation steps
To set up Pure to synchronise data from your external system you will have to follow the steps described in the table:
| # | Step | Description |
| 1 | Decide what data to synchronise | The order in which you initially synchronise content into Pure matters. Organisations have to be added to Pure first. Depending on the chosen authentication method, you may benefit from importing Users as the second content type followed by Persons as the third. Both Organisations and Persons are related to every other content type and must therefore be added to Pure before other content types. Pure has a rich data model, but only a part of the metadata on each content type is mandatory. Please consider which metadata (besides the mandatory) you want to synchronise. |
| 2 | Create Custom Converter | You will create a Custom Converter to extract data from your external system and convert it to the Pure XML format for the chosen content type. |
| 2.1 | Set up Intermediate Store | You will set up an intermediate store which will make the XML file accessible for Pure, either as a web server or via a web service. The intermediate store can be built together with the Custom Converter. |
| 3.1 | Set up synchronisation job | For each content type, identify the synchronisation job to use. You can find the jobs in Pure under Administrator > Jobs > Cron Jobs Scheduling. |
| 3.2 | Edit job configuration | You will need to apply the settings needed for Pure to locate your XML file (in the section "Dataprovider configurations"). You can also apply general settings to the synchronisation (in the section "Synchronisation configurations"). |
| 3.3 | Specify what to synchronise | For each field in Pure's data model, you will decide if and how the field should be synchronised (in the section "Synchronisation view/field configuration"). Look through the specifications in Pure and compare them with the data in your external system. It may not be possible for you to provide all the data that Pure's data model can include for a specific content type; this is not a problem. Note: A synchronised field (value: "Sync") is read-only in the Pure editor window, while the other options for importing data leave the field editable in Pure. |
| 3.4 | Trigger the job | You can schedule the synchronisation job to run on a regular basis, but you can also manually trigger the job to start on your request. |
| 4 | Validate |
You can review the result of the job execution from two angles:
|
Classification schemes and synchronisations
The values in a classification scheme can be managed from within Pure. When developing the data extraction and transformation, you must therefore take special notice of the fields that are marked with ‘classification’ as their type. Pure comes with default values for all of these classifications, but you will most likely want to change some of them. For example, when you develop the Organisation synchronisation you must also specify the types of Organisations (Faculty, School, College and so on). All classifications should generally be well specified at the time the synchronisation jobs are configured, since they will have to be used during the synchronisation. When you specify classifications, you specify a key for each one. This key is an identifier for the classification and you must provide this key when assigning a classification to a field. If a classification key is provided that cannot be mapped to a classification value, the synchronisation job will report an error.
Synchronisation job execution
All synchronisation jobs in Pure are executed following the same pattern. This pattern is outlined below using an Organisation synchronisation as example:
- Extract a list of all the Organisation IDs from the synchronisation data - this will be the list of Organisations that should be synchronised
- For each ID:
- Retrieve the data for the ID from the synchronisation data
- If the Organisation does not already exist, then create it with the data retrieved from the synchronisation data
- If the Organisation already exists in Pure, then update the data in Pure with the data retrieved from the synchronisation data
- For each Organisation in Pure which where previously synchronised, but no longer exists in the synchronisation data:
- Set the end date of the Organisation in Pure to the current date, identifying it as a historical Organisation, and mark it as not synchronised
The synchronisation jobs for the other content types follow this same execution pattern, i.e. first retrieve all IDs for the records in the given content type, then create or update them in Pure. For Persons, this includes creating and updating relations to affiliated Organisations (basic employment data).
In Pure you can relate the same Person to multiple Organisations and also to historical Organisations, thus making it possible to have historic data. If you do not have historic data in your external system, the data in Pure will start out reflecting the current state. Pure will automatically record historic data as a consequence of the changes happening over time.
Further documentation
For each content type in Pure there is a synchronisation job. They can be found in Administrator > Jobs > Cron Job Scheduling. With each job configuration you will find:
- PDF documentation describing both the process of performing a bulk import in general, as well as anything requiring special attention for the given content type
- XSD files which define and describe the required format of the XML files and related technical details
- XML examples for inspiration
Deliverables
After completion of this task you will be able to provide the following deliverables:
- XML(s) containing metadata for the content to be synchronised into Pure (e.g. for Organisations)
- Configuration of relevant synchronisation job(s)
Published at April 03, 2024