
How Can We Help?
Repository integration guideRepository integration guide
When a full text file is attached to a Research output in Pure, it can be stored in a number of ways. The default behaviour is to store the file in the local Pure file store, from where it can be served to the Pure backend, Pure portal or Pure web services. If you use a repository system such as EPrints, DSpace etc it is also possible to use this as a file store, and thus let Pure transfer the file and its associated meta data to the repository rather than store it in Pure.
Integration from Pure to a repository
This is controlled in Pure using the Pure repository connector architecture. This handles the following:
- Converts meta data of the Research output from the Pure format to the standard format used by the repository
- Transfers the files and meta data to the repository
- Continuously monitors the content in Pure and overwrite/delete content in the repository accordingly
When using a repository together with Pure the repository needs to be used in a "read only" manner, i.e., users should not be allowed to enter or edit any of the "Pure" content in the repository. If someone edits a piece of content in the repository that has been synchronised to the repository by Pure, these changes will be overwritten by Pure the next time the publication is changed in Pure and thereby transfered to the repository.
Please also note that the integration functionality provided by the different repositories can be rather limited. Generally they only support create and delete operations, not update - and also the record as a whole. This means that we cannot just update parts of a record, but will always have to update the whole record, in essence overwriting the content.
How the connector works
When the connector is successfully set up, the so called Preserved content job is the (cron) job that actually transfers meta data and full text files to the repository.
It is recommended to set it to run every minute, because with each run updates and new items are pushed to the repository. These updates include modified meta data, like a changed subtitle, but also adding another or removing a full text from a Research output. Important here is, that only changes to content covered by the configured filter are reflected in your repository. Please see the section Configuration of filters for more information on the possible filters and settings.
Some scenarios how the connector works:
The repository ID of the Research output must be used as source ID when imported:
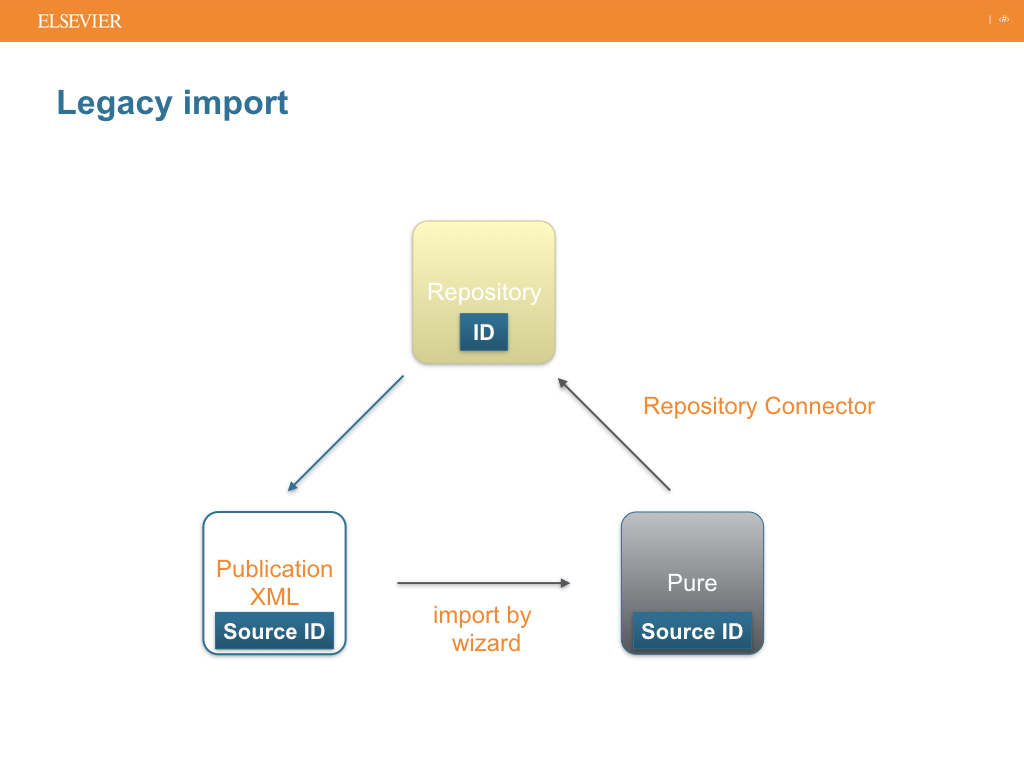
When a full text is deleted in Pure:

The Preserved Content Update job transfers Research output to the repository:

When visibility filter settings are modified:

Handling of full texts that are in the repository, but not in Pure:

Transfer of full text files
When a full text file is uploaded to Pure it will not be transferred to the repository right away. Instead the full text file is stored in a temporary space in Pure. As soon as the Research output is saved and the Preserved Content Job is run, the file is transferred to the repository and the copy in Pure's temporary space is deleted, when the transfer was successful.
If you have set up your connector to not transfer all full texts to the repository, Pure will move them to an internal permanent store instead, when the Preserved Content Job is run. In case you change your connector settings to also transfer these items to the repository, the connector will do this accordingly and delete the full text in the permanent store after a successful transfer to the repository.
Pure will show a link to the full text in the Research output editor in Pure, so that you can see the content of the full text file in Pure. Pure will also show this link in portal applications, but the file is never retrieved from Pure directly. Instead, every time a full text file is requested by Pure or the Portal, Pure will retrieve the full text from the repository each time. From the moment of a successful transfer to the repository the full text file is no longer stored in Pure, but only referenced and retrieved on demand from the repository.
Mapping of data from Pure to repository format
The mapping of data from Pure to the repository is handled by an XSLT stylesheet which transforms the meta data from a version of the MODS format used by Pure to the format used by the repository.
When you setup the connector you can use the default XSLT stylesheet for the mapping of Pure to the repository, provided in the configuration of the connector.
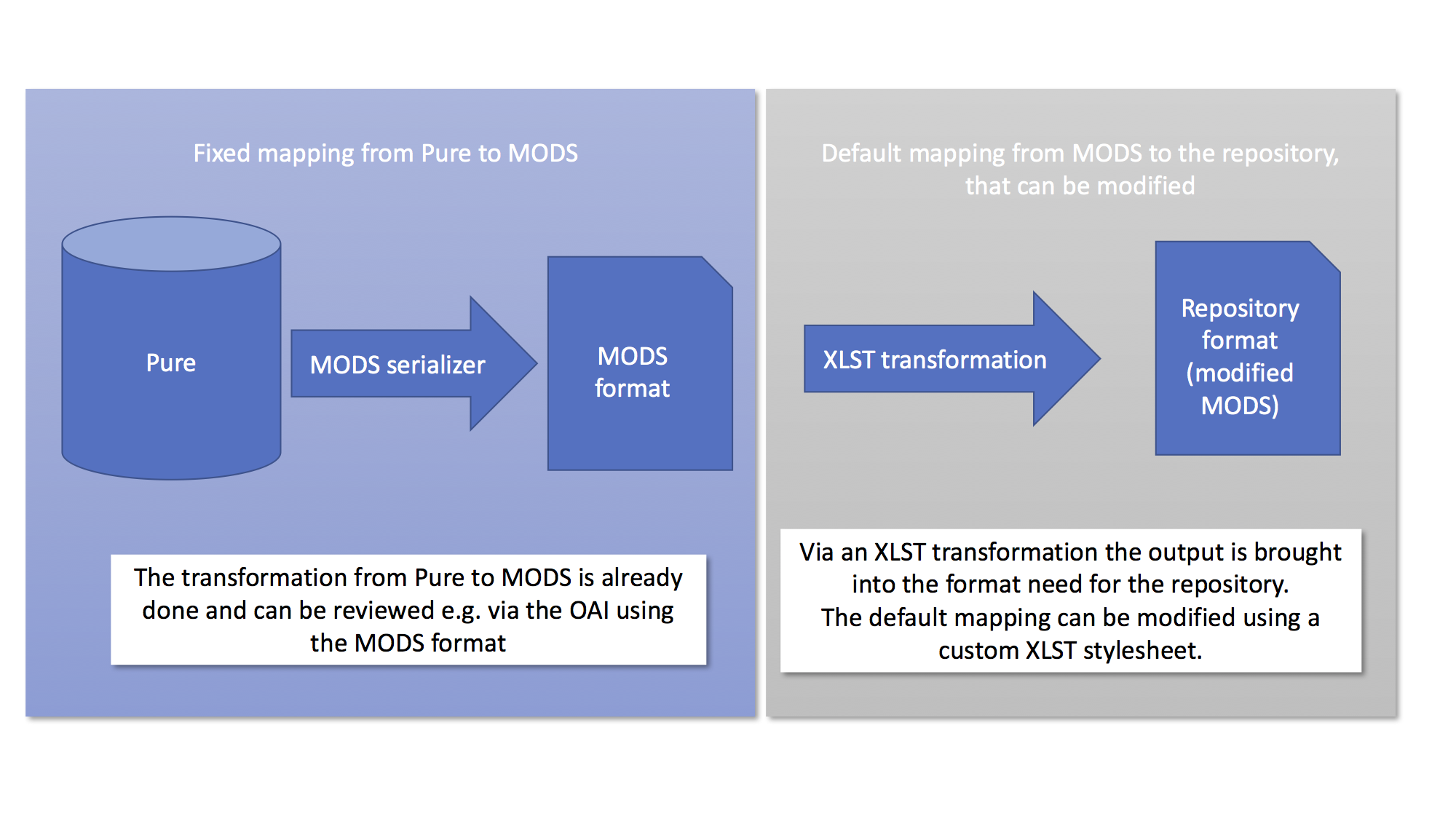
While we recommend that you use the default mapping between Pure and your repository system, it is possible to change this mapping by editing the XSLT stylesheet yourself. How to do this differs a bit from repository system to repository system. Please refer to the documentation of your repository, if you want to use a custom stylesheet to customise the output format.
Installation and setup of connector
The installation and setup of the connector consists of two parts:
- The connector needs to be turned on and configured in Pure.
- For most connector setups the repository needs to be patched in order to extend the API provided by the repository to support the operations needed by Pure.
You can find the information how to setup and install the connector here: File storage
Configuration of filters
Pure provides a number of options to control when and how data is synchronised from Pure to the repository. This is controlled using the standard filters:
- Visibility filter - Based on the visibility field in Pure, Research output can be transferred to the repository or not.
- Workflow filter - Based on the workflow step of a Research output in Pure, the Research output can be transferred to the repository or not.
The filter settings also include item for Research output that is set "for revalidation". - Electronic version - Pure supports synchronising both Research output that have a full text file attached and publications that have only meta data.
- Publication status - You can configure the connector to only transfer Research output that has a certain publication status, e.g. only published Research output.
- Type classification - It is possible to only transfer a subset of all Research output types to the repository. You can chose to e.g. only transfer journal contributions and books to the repository.
If you need assistance in setting up these filter, please contact your implementation manager.
Recommended test and implementation of a repository connector
In this section we assume that you will do a legacy import of Research output from your repository first, before the connector is set up.
Other scenarios are also possible, but uncommon, so we concentrate on the most common case.
If you plan to integrate with a repository, we recommend to start very early in the project. From our experience internal discussion and mapping decisions can consume an unexpected long time, to compensate this, we recommend to start in an early phase of your implementation.
To test the default mapping to your repository, it has proven to be a good method to create example cases in Pure and review how the result displays in your repository. In order to do so, you should create a complete example case for all Research output types you plan to use and transfer to your repository, there is no need to test research output types that you won't use or transfer to your repository. Make sure that you have filled all fields in Pure to create a full example, only this way you can review a complete case in your repository.
When this is done, create a test instance of your repository, cloning your existing one into a test instance will do best, so you can test on a repository that is as close to your production system as possible.
After that, configure the Pure repository connector and switch it on. When the Research output meta data and the full text files are available in your repository, review them. In case you would like to make changes, you can do so by making modifications to the connector configuration or by using a custom XSLT transformation file.You can now review the modified results in the repository, repeat this process, if necessary (always use a fresh clone from your repository for each trial).
When the configuration is finished, you should run a final test with the data from the legacy import data. Be aware that, depending on how you configure your connector, data will be modified in your repository and a lot of data might be transferred. We strictly recommend to run a test on a cloned repository and your intended configuration, before you use this in production.
At the point in time you want to go live with Pure, configure your repository connector as you have tested and verified and run the Preserved Content Job to transfer the Research output data to Pure
Important
- When using a repository connector Pure will become the single entry point to modify data.
- Modifying the connector configuration can result in huge data transfers and deletion of data in the repository (see Transfer of full text files)
Miscellaneous
- Please review Supported platforms to make sure your repository and its version is supported by Pure
- You can enable a Transfer to repository section in the Research output editor via Administrator > Full text repository, with it you can determine on a Research output level, if an output should be transferred to the repository or not. For further information please see Repository Settings: 'Transfer Publication to Repository'
FAQ
- How often is a publication updated?
- It depends on how often you set the Preserved content job is set to run, we recommend to run it every minute.
- When is a Research output created in the repository?
- It is created as soon as the Research output is created & saved in Pure and the Preserved content job is run after the time of creation.
Please make sure that you filter settings allow the creating of the Research output in your repository.
- It is created as soon as the Research output is created & saved in Pure and the Preserved content job is run after the time of creation.
- How does the XSLT transformation works?
- This is a generic method of transforming XML documents, please find an introduction here: https://en.wikipedia.org/wiki/XSLT
- Can more than one connector be set up?
- Yes, more than one connector can be set up at the same time. You need to create an external file store for each repository you want to connect.
Please see File storage for information on how to set up an external file store.
- Yes, more than one connector can be set up at the same time. You need to create an external file store for each repository you want to connect.
- What kind of repositories are supported?
- Please have a look at to see the supported repositories and versions.
Please note, that only stock repositories are supported by the connector.
A customised version of a repository or a repository that is based on one of the supported repositories is not supported by the connector
- Please have a look at to see the supported repositories and versions.
- Can I store full text files in the repository and in parallel in Pure as well?
- Yes, you will need to configure an additional file store, please Local file system for details
- Is only Research output data transferred?
- No, you can transfer Student thesis and Datasets as well. The Datasets option is not available for ePrints.
Published at March 25, 2025