
How Can We Help?
5.25.05.25.0
Highlights of this release
 Update to the Web of Science integration and new request tracking pages
Update to the Web of Science integration and new request tracking pages
We have made several updates to Pure's integration with Web of Science to improve the way requests to WoS are made. This resulted in better handling of requests and quota limits, optimizing the import of the total and yearly number of citations on publications.
To make it easier to monitor the usage of different sources and the performance of different import jobs, we have started working on a set of tracking pages for integrations in Pure, with the aim of creating a space where research administrators can easily get an overview of the usage of import sources, both for requests made from Pure, and for imported content. The first pages of this new tracking space are made available with this release: you can now monitor requests and quota usage for Web of Science.
 OpenAIRE required fields and status check on datasets
OpenAIRE required fields and status check on datasets
In line with Pure's 5Cs data quality framework, we have expanded the model for dataset records in Pure to align with OpenAIRE guidelines for dataset interoperability. Users can add license information at a record level, and an OpenAIRE compliance check has been implemented to encourage enrichment of the record by users and to improve OA compliance monitoring and management of datasets.
 Actionable tasks (milestones) for award management content types
Actionable tasks (milestones) for award management content types
We are steadily moving towards the goal of an integrated task and workflow management solution that supports the needs of the research office. With milestones now available for the Ethical review, Application and Project content types in the Award Management module, the first phase of the strategic redevelopment of milestones is now complete. The phase 2 development will commence in 2023, as we revisit the AMM data model and build in further automation and process management together with a new focus on action-oriented overview screens.
Reminder: Update to sub-processors
We would like to notify customers about the addition of a new sub-processor for Pure, as per the advance notice that was earlier communicated on the Pure Client Space: Additional sub-processor notification.
Entity Name |
Location |
Service |
|---|---|---|
| Elsevier Colombia at LexisNexis Risk Solutions SAS Company | Colombia |
Implementation Consulting Services (Implementation consulting services refers to paid for services subject to agreement with client) |
Advance notice: Change to supported system requirements
This is an advance notice of changes to the supported system requirements for running Pure. The current combination of system requirements has become increasingly difficult to maintain with regards to security and the performance of Pure. We are therefore planning to drop support for the following:
- Authentication mechanisms: drop support for all except SAML2-based authentication mechanisms.
- Operating systems: drop support for all except Linux (specifically dropping Windows and UNIX).
- Databases: drop support for Oracle and SQL. Maintain only Postgres.
We understand that it is not possible for on-premise customers to immediately adjust to meet the updated system requirements. This notice is an invitation to start a dialogue with us to determine the timeline and alternative solutions available to be able to continue running Pure securely. Please refer to Information on change to supported systems for details.
If you have questions on this notice, or would like to start the dialogue with us, please contact Brian Plauborg (b.plauborg@elsevier.com), Henrik Kragh-Hansen (h.kraghhansen@elsevier.com), or Davina Erasmus (d.erasmus@elsevier.com).
If you would like to discuss moving to hosting, please take up contact with your sales representative or customer consultant.
We are pleased to announce that version 5.25.0 (4.44.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 10 October 2022
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 12 October 2022 (APAC + Europe) and 13 October 2022 (North/South America).
- Production environments (including hosted Pure Portal) will be updated 26 October 2022 (APAC + Europe) and 27 October 2022 (North/South America).
Advance notice
Pure 5.26.0 (February 2023) will require Java 17.
Pure 5.26.0 (February 2023) will no longer support PostgreSQL 10.
With Pure 5.26.0, we will be discontinuing our Long Term Preservation connector to Fedora. We suggest that you get in touch with pure-support@elsevier.com in case this can cause any issues for your Institution.
Upcoming changes to the release notes format
Over the next few releases, we will introduce an updated format of the release notes. The goal is to provide a clearer, more concise overview of the changes introduced, with focus on the value they may bring to your institution.
See the changes to the release format wiki for more details.
Download these release notes
last updated 7 October 2022
1. Web accessibility
We continue to work towards being fully WCAG 2.1 AA compliant by ensuring accessible design in new features. In addition to this, we implemented the following improvements to existing features:
1.1. Pure Portal accessibility updates
The Pure Voluntary Product Accessibility Template (VPAT) report has been updated. The Pure Portal underwent accessibility testing on the 25th of July, 2022. You can access full results of this assessment through a link included in the 'About web accessibility' section found in the footer of the Portal.
The analysis and results showed:
- Portal accessibility fully supports 43 items and partially supports the remaining 7.
- Partially supported areas are primarily due to external dependencies like Altmetric and PlumX widgets, which the Pure team is not in control of.
- The UN Sustainable Development Goals (SDG) official logos do not have high enough color contrast. Although a black and white alternative is available, in this particular case a decision was made to promote recognizability over accessibility.
All of the partially compliant areas were reviewed by our accessibility experts. While most areas cannot be fully fixed in the current setup (primarily due to external dependencies), we managed to make one of these areas (1.3.1 Info and Relationships) fully compliant.
2. Pure Core: Administration
2.1. Security: antivirus scan, status badges and download blocker
To increase the security within Pure, we are now scanning files for viruses. While the actual scanning of the files is performed outside Pure, you can now decide to show the status of files as a badge, and to block the download of infected and/or unscanned files. This feature will be enabled by default for all Elsevier-hosted customers. Self-hosted customers will need to follow a dedicated guide on our Antivirus integration confluence page to take advantage of the feature.
Impact on Pure Portal
The status badges can only be visible in Pure, and not on the Pure Portal. However, the files themselves can be accessed from the Portal if their visibility is set to 'Public'. The feature is by default set to block the download of infected files, so the users of Pure Portal should not be able to download any files that are visible on the Portal but are infected.
Click here for more details...
What is scanned?
Elsevier-hosted clients: Only files that are transferred to cloud storage are scanned. Files only linked from Pure (e.g. with DOI) are not scanned. When a file is added to Pure, it is transferred to storage by the Preserved Content Update job.
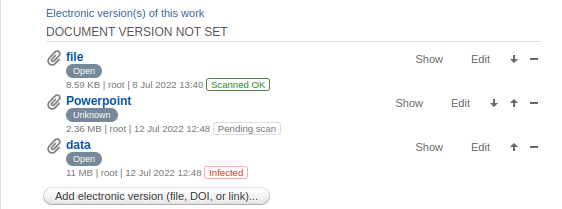
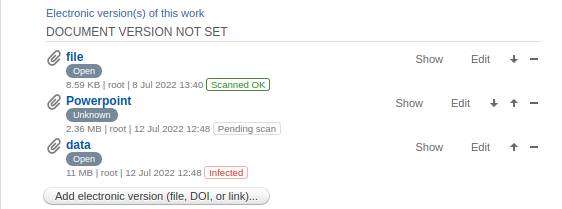
Badges in the files list
When the feature is enabled, the scan result is shown as a badge next to each file in all file sections of the editors:
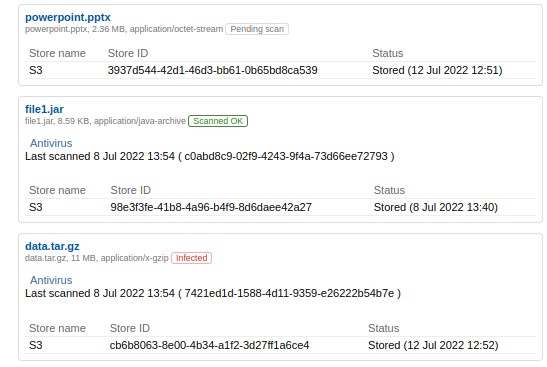
Details in History and comments
More detailed information is available in the 'History and comments' tab of the editor:
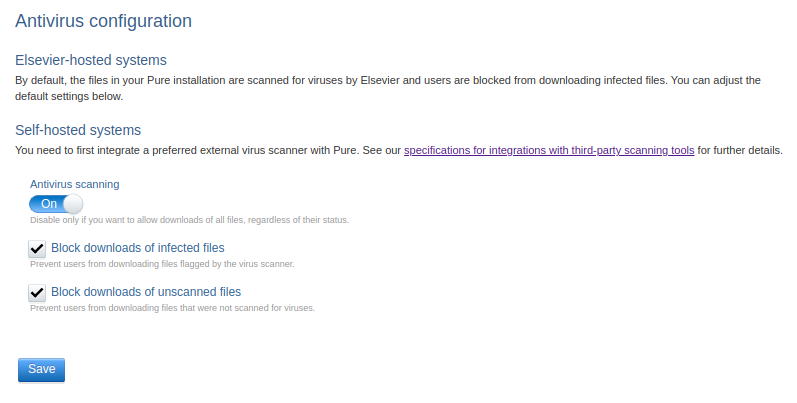
Limiting the download of infected and unscanned files
Administrators can configure whether files marked as "Infected" and/or "Pending scan" can be downloaded by users of Pure or the Pure Portal in Administrator > Storage > Antivirus. The download of infected files is blocked by default, and we strongly recommend to not change that setting.
2.2. Datasets: OpenAIRE-required fields and status check on datasets
In line with Pure's 5Cs data quality framework, we have expanded the model for dataset records in Pure to align with OpenAIRE guidelines for dataset interoperability (https://guidelines.openaire.eu/en/latest/data/index.html). To facilitate the enrichment, monitoring and management of datasets for OA compliance, including all mandatory OpenAIRE fields, it is now possible for users to add License information at the record and file level. The users can also get an easy overview of whether a particular dataset is OpenAIRE-compliant through the newly added OpenAIRE compliance check.
Click here for more details...
License information on a record
Users can specify a data-specific license on the dataset, with values provided in the modifiable classification 'Datasets: Document licenses' (/dk/atira/pure/dataset/documentlicenses).
Example:

License information is available in:
- Dataset editor
- Reporting
- OAI-PMH via CERIF XML. If there is a license set on the dataset, this will now be exposed as part of product set (see CERIF XML mapping for more details).
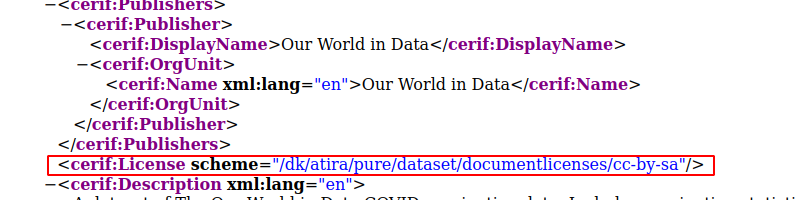
License information can now be added via:
- Synchronization/import
- The configurable dataset synchronization now supports synchronizing the license information if data is provided for it in the XML.
- The dataset bulk import functionality now supports importing in the license information if data is provided for it in the XML.
- Data Monitor
- If datasets are imported from Data Monitor, license information is added directly to the new license field at the record level and the access is set based on the license provided.
OpenAIRE compliance check
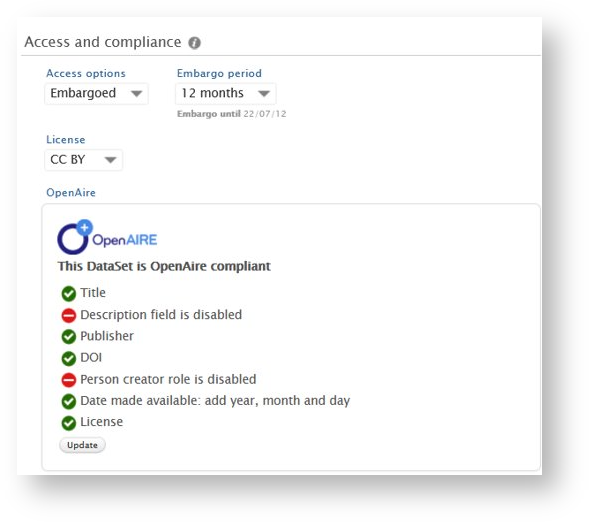
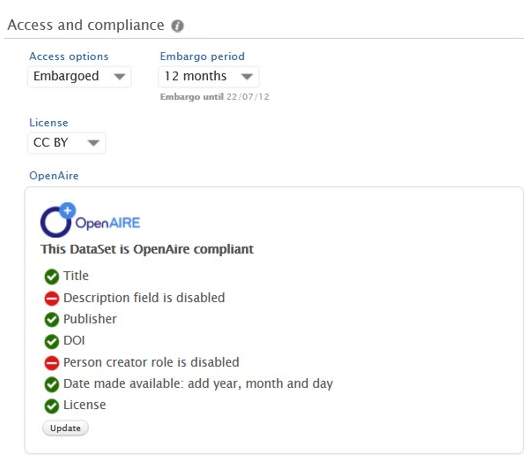
To help users identify which fields are required, an OpenAIRE compliance check can be displayed on the dataset editor in the Access and Compliance section.
|
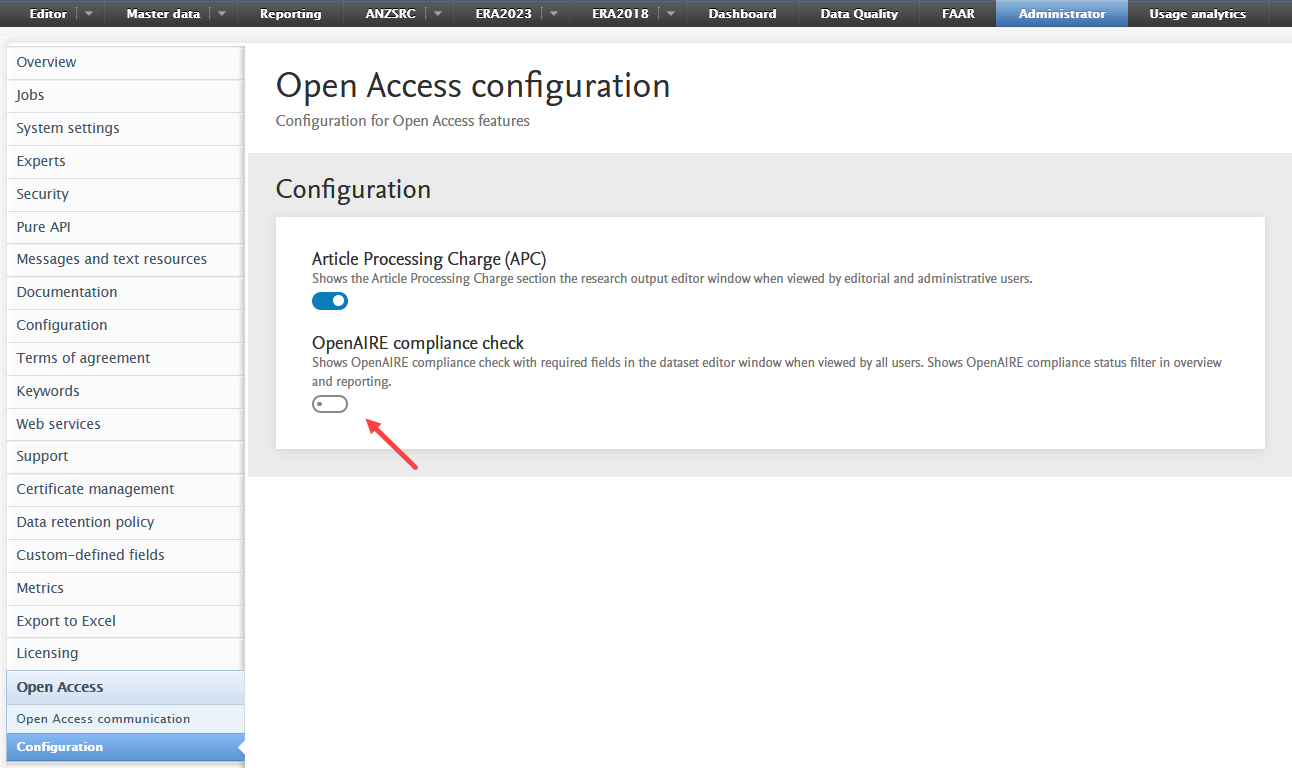
Enabling the check You can enable the check in Administrator > Open Access > Configuration > OpenAIRE compliance check. |
 |
Updating values in some fields will not trigger immediate updates to the compliance check, but users can click the Update button to trigger an update. |
 |
Filters and availability of compliance status in reporting
The OpenAIRE compliance status can be used elsewhere in Pure to help identify records that need enrichment.
|
OpenAIRE status filter When the compliance check is enabled, a corresponding filter in the dataset overview will become active, and each compliant record will be tagged with an OpenAIRE icon. |
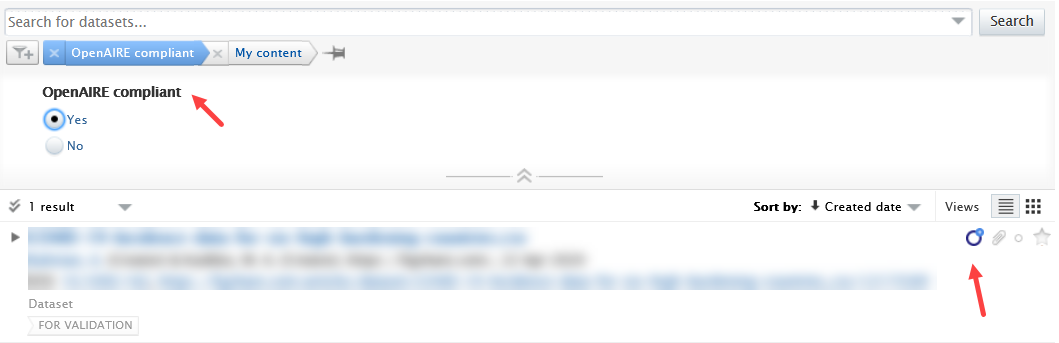 |
|
OpenAIRE status as column value in reporting The compliance status can be used as a column value in reporting. It can be found under the Access section. |
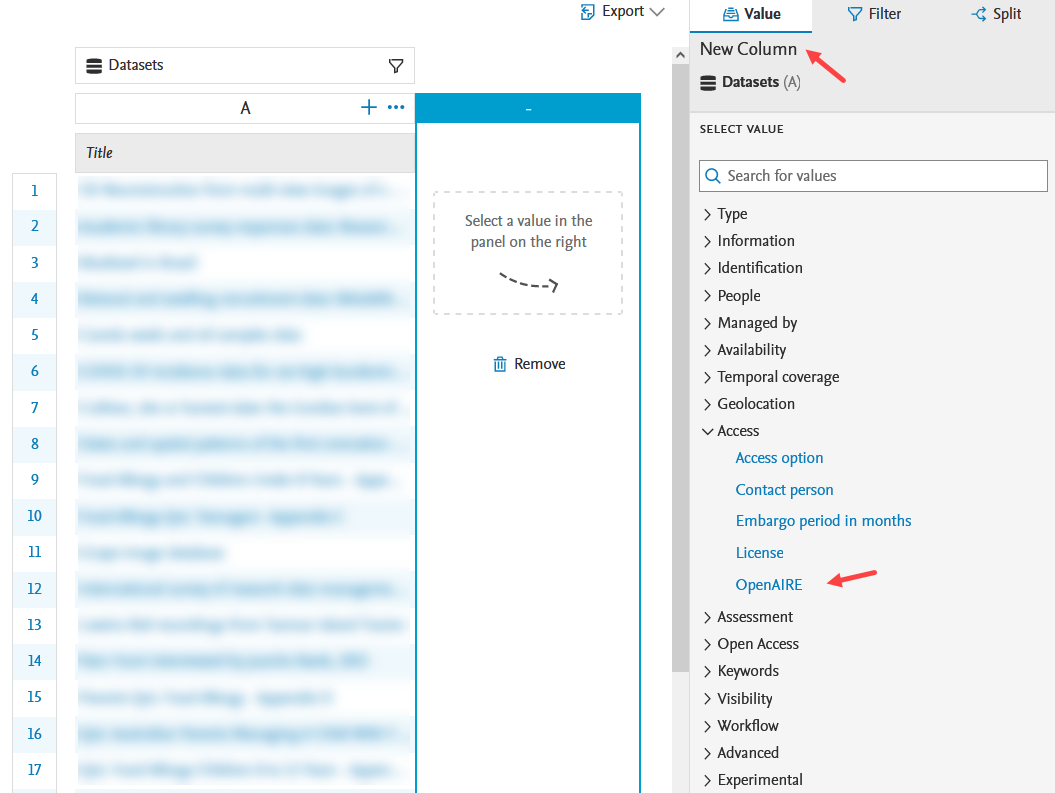 |
|
OpenAIRE status as filter in reporting Compliance status can also be used as a filter in reporting. |
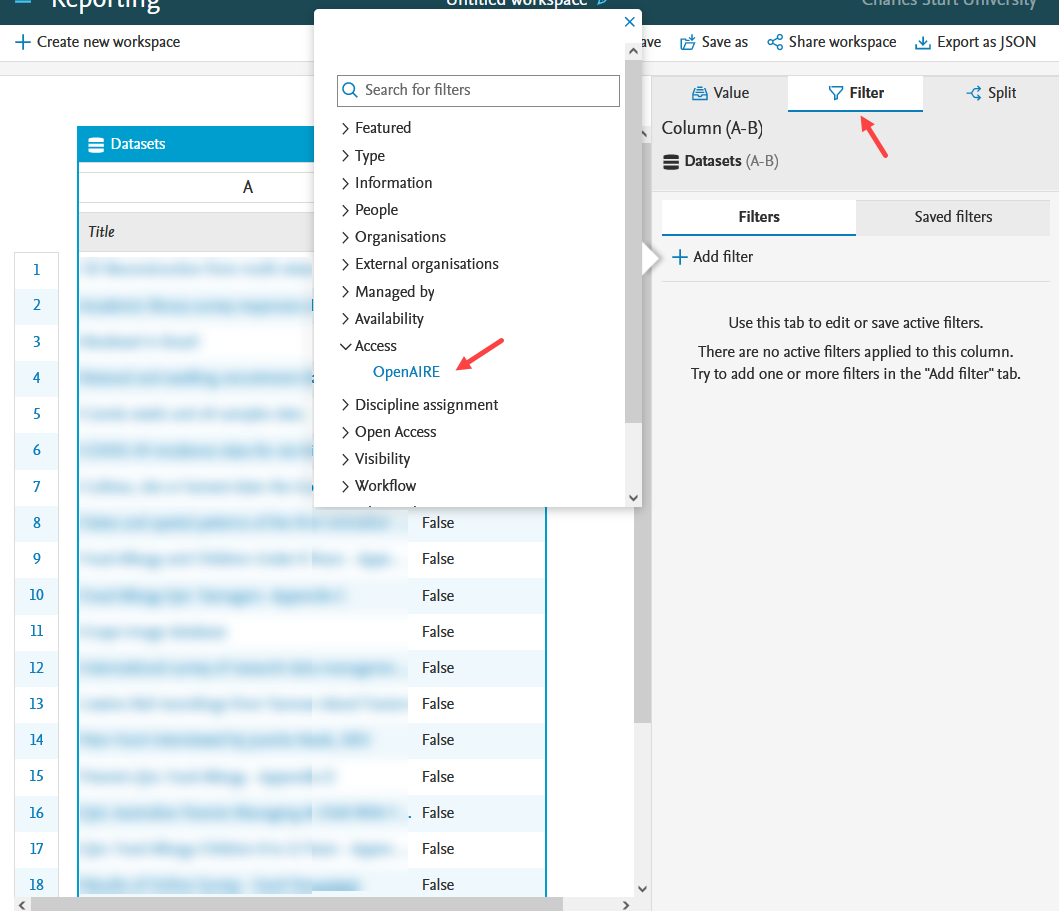 |
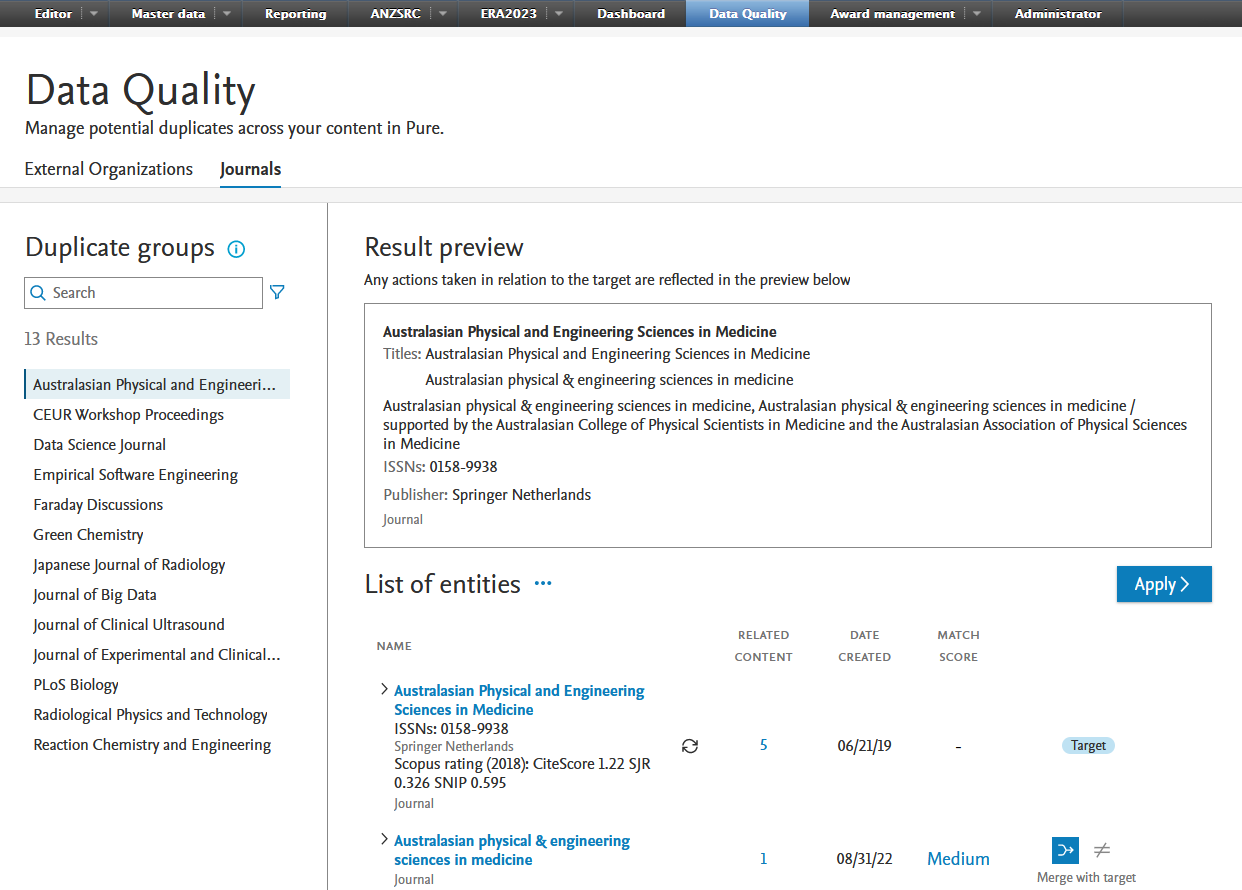
2.3. Journals: journal deduplication in the Data Quality interface
Deduplicating journals is now possible in the Data Quality interface. You can merge and set journals as distinct from each other using the same functionalities as for external organizations. See the Data Quality interface instructions for more details.
2.4. Research outputs: DOI and Scopus source links also available at the top of research output editor
The DOI and Scopus source links for research output (where provided) are now also available in the top right corner of the metadata section of the editor to provide easier and faster access to the source of record for checking and validation purposes.
3. Pure Core: Pure Web Service and Pure API
Pure Web Service is the read-only service available to all clients. See Administrator > Web services for more details.
Pure API is the read-and-write service currently under development and available to all clients. See Administrator > Pure API for more details.
3.1. Pure API: production-ready for available endpoints
From 5.25.0 we consider the Pure API stable, and no longer in early access. While the Pure API is not fully featured yet, we are confident that the implemented endpoints are ready for production use. This means that backwards compatibility of the contract will be guaranteed for the implemented endpoints intended for management of resources. The only exception is the /search endpoint which is a carry-over from Pure Web Service, and will likely be changed when we define how the query model for the Pure API.
3.2. Pure API: application, award/grant and project added
Pure API now supports the management of Application, Award/Grant, and Project outputs. CRUD (Create, Read, Update, Delete) operations on these content types are now available.
Most metadata fields are supported, except for milestones and budget/expenditure.
Use cases catered for in the current release:
- Legacy import as an alternative to the current bulk upload functionality
- Enrichment of existing entities with additional metadata
- Full extraction of all entities in a Pure installation, including confidential content, using Access Definitions introduced in 5.22.0
If your use case is not covered by this implementation, we would like to hear from you and add it to Use cases.
More details
In Pure API, each content type has a set of helper operations which are used to retrieve allowed values for the properties in the schema. These are typically values for a given classification scheme. The operation name of the helper method correlates to the path and name of the model property it is applicable for.
The application, award and project endpoints also support the custom defined field functionality introduced in 5.24.
3.3. Pure API: breaking changes introduced
As mentioned in the 5.24.0 release notes, some breaking changes have been introduced.
- The contributors field on research output will support three types instead of just one. This is to make it clear for the API user what fields are available/required, based on what type of contributor they are adding, i.e. internal person, external person, or an author collaboration.
- Organizations are sometimes spelled with an 's', both in the field and in the documentation. We updated this to be consistently spelled with a 'z'. This is to be compliant with Elsevier API standards.
In addition, we have made the decision to not include derived properties in the Pure API models, as these are not editable. This means that the following properties have been removed:
- The openAccessPermission and openAccessEmbargoDate properties on research output have been removed, as they're derived from the values on the associated electronic versions.
4. Integrations
4.1. Web of Science: switch to new API
We have used the API migration as an opportunity to optimize how requests to WoS are made and to better handle request quota limits. The improvements to the integration with the WoS Starter and Expanded APIs aim to facilitate their usage and to ensure that the number of requests that are sent from Pure is kept to a minimum. While the functionality of the integration remains unchanged for the end-users, the structural changes in Pure result in a smarter usage of API quotas. Additionally, it is now easier for the administrators to control settings for the two APIs as the source configuration is available on a single page.
Making the switch
Your current Web of Science integration in Pure will be disabled when you upgrade to Pure 5.25.0, and you will need to re-enable it. See more in documentation on how to make the switch.
Automated search
If you previously set up automated search in Web of Science, your search profile will be automatically migrated to the new API.
WoS metrics
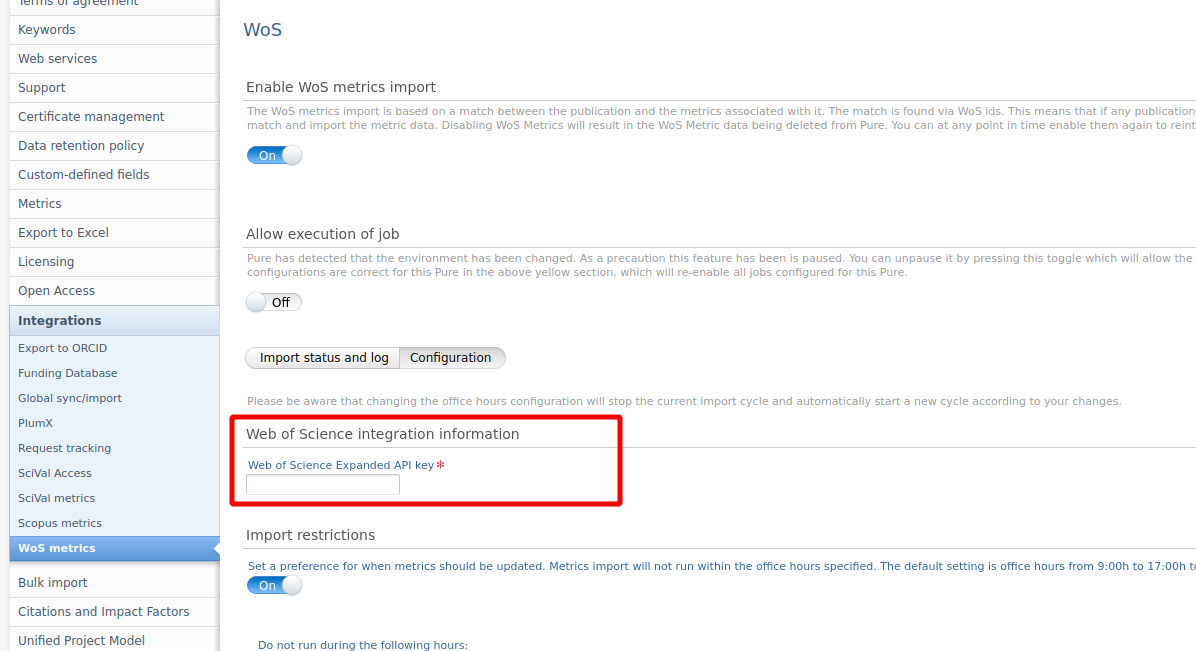
If you already import metrics from WoS, you will need to re-configure their import separately in Administrator > Integrations > WoS metrics > Configuration, where you will need to provide the WoS Expanded API key.
Previously, the API key details from the import source configuration were used for the import of metrics. In 5.25.0, this is separated to make it possible to import metrics without having to configure the import source.
Click here to expand...
Find out more about the original feature in Web of Science metrics integration (5.17.1).
Find out more about the original feature in Web of Science metrics integration (5.17.1).
Available resources
Pure Client Space > Import sources > Setting up online sources gives details of license/subscription requirements and instructions on how to activate the WoS integration.
More details
There are two separate subscriptions to Web of Science:
- Web of Science Starter (required): This API replaces the existing integrations with Web of Science Lite. Subscribing to the WoS Starter API allows for the search and import of publications from WoS.
- Web of Science Expanded (optional): This API replaces the existing Web of Science API. Subscribing to the WoS Expanded API enables the import of publications containing additional metadata, such as affiliations and citations.
Note: You must subscribe to the WoS Expanded API in order to enable available updates and import the total number of citations for a record. This is not possible if you only subscribe to the WoS Starter API.
Each WoS API has a different licensing scheme. See details at https://developer.clarivate.com/apis/wos.
API Quotas
There are quotas on the total number of requests that are sent to the WoS Starter and Expanded APIs. Details are listed in the table below:
| API | Limit | Description |
| Starter |
Daily quota of 1,000 requests Note: There is a possibility to increase this limit for Pure clients, depending on usage. Contact Clarivate for more details. |
The Starter API will be used to facilitate initial searches through the self- and automatic import, and exposes enough metadata for Pure to provide a sensible import result. You can then choose to fully import the proposed records. If you do not have a subscription to WoS Expanded, the record will be imported with the (limited) metadata from the Starter API. If you have WoS Expanded, Pure will make a request to get the full metadata from there, and then import the record. |
| Expanded |
Yearly quota The number of documents that can be retrieved from WoS per year depends on your specific subscription plan. For more details on WoS subscriptions and plans, contact Clarivate support. |
Automatic updates and WoS Metrics will only be supported if you have WoS Expanded as this API allows us to make an initial 'free' request to check if a publication or the metrics have been updated. If the publication/metrics have been updated, we will then use a real request to retrieve the update, subtracting from your quota. This will run on a weekly basis as usual but being able to make the free request will most likely allow us to minimize the impact on your quota. |
Type and field mapping
This can be found and referenced on the Pure Client Space > Web of Science
Enable, add and search for content from Web of Science
Instructions |
Screenshot |
|---|---|
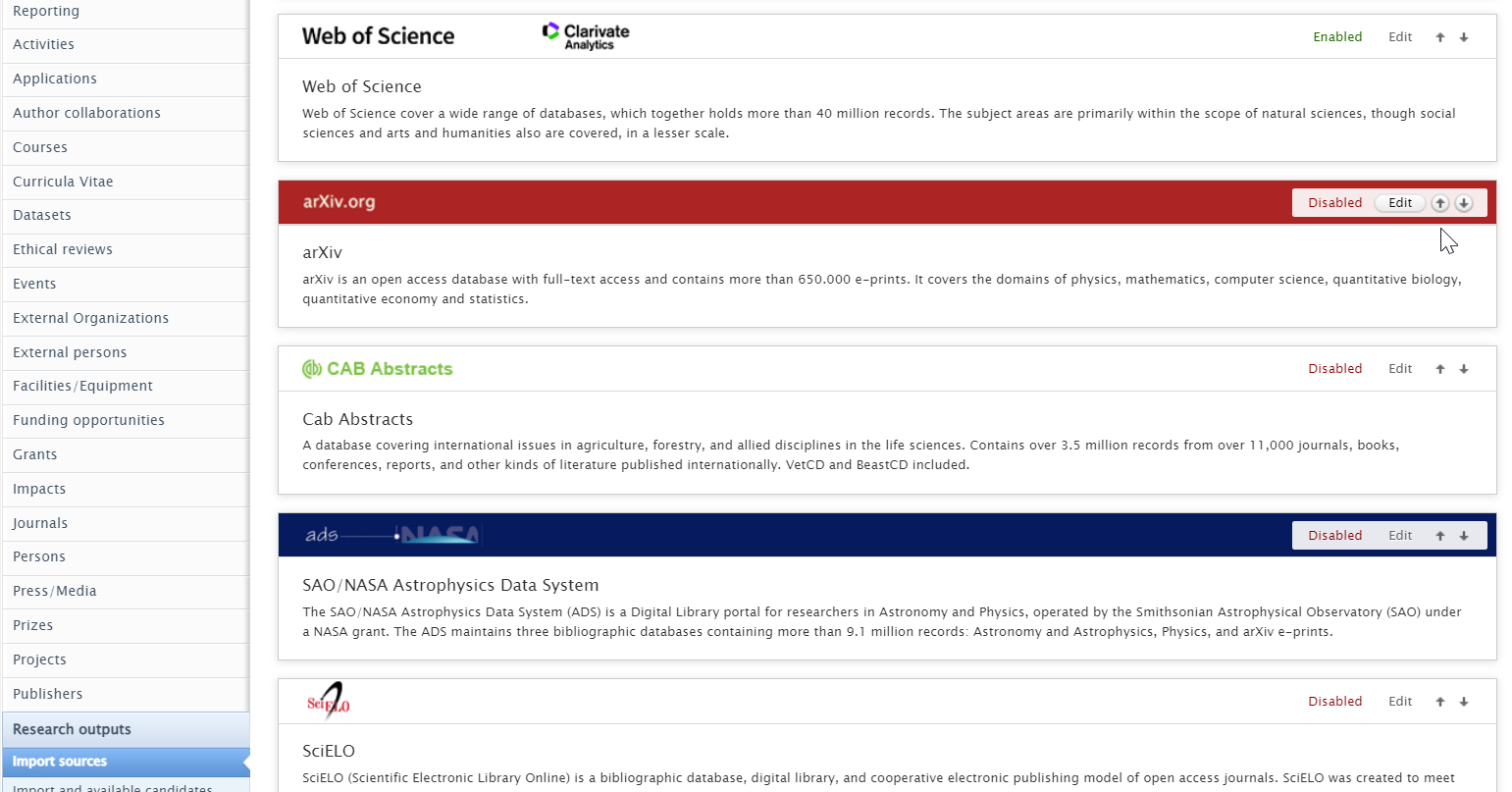
Enabling the integration To enable the integration with Web of Science, go to Administrator > Research Output > Import Sources > Web of Science |
|
|
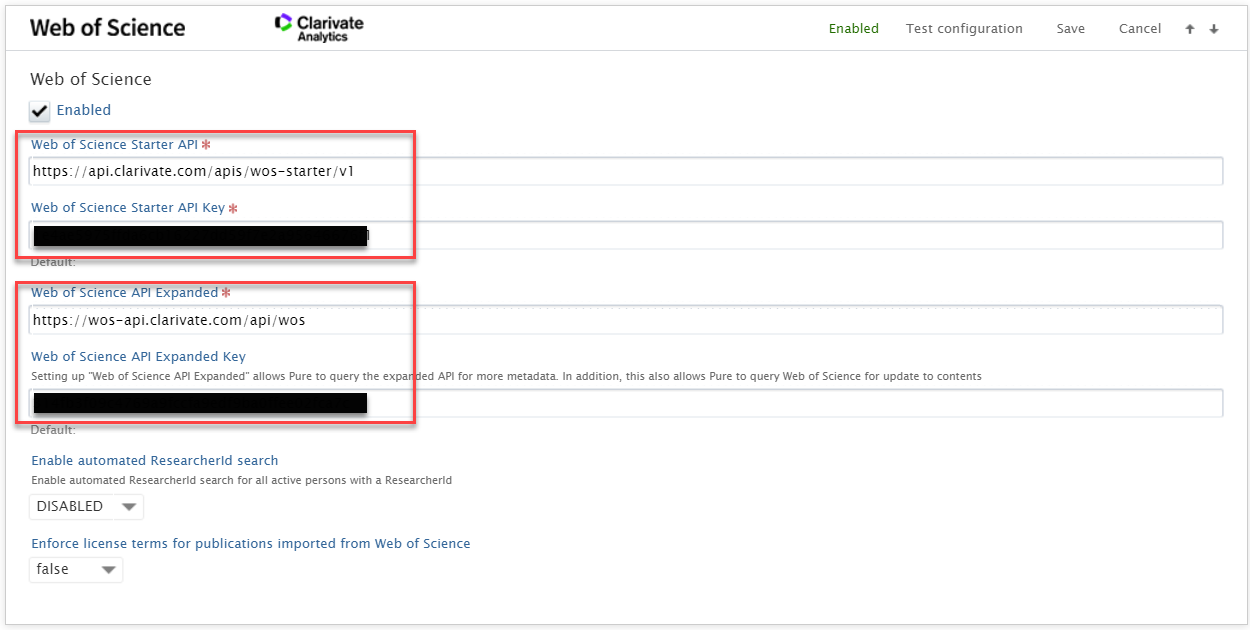
Configuring source The source configuration page includes settings for the WoS Starter API and the WoS Expanded API. The Starter API key is required to enable WoS. After inserting the API key(s), enable the source and click Save. The Starter API will be used to facilitate initial searches through the self- and automatic import, exposing enough metadata for Pure to provide a sensible import result. You can then choose to fully import the proposed records. If you do not have a subscription to WoS Expanded, the record will be imported with the (limited) metadata from the Starter API. If you have WoS Expanded, Pure will make a request to get the full metadata from there, and then import the record. In case you have a subscription to WoS Expanded, it is possible to subscribe to the Starter API with no additional cost. For more details on WoS subscriptions and to register for an API key go to Clarivate support. |
|
|
Searching for and importing content To search and import content, go toEditor > Research Output > Import from online source > Web of Science |
|
|
Searching for content You can now search for content using query text, article title, DOI, author names and IDs, or publication year. You can also combine the values. For instance, if you are interested in content with a certain title and author from a specific year, then you can fill out all of the fields and do a combined search. |
|
|
Viewing and importing content Search results are presented as import candidates and can then be previewed and imported (or removed). Records that already exist in Pure are shown as duplicates. |
|
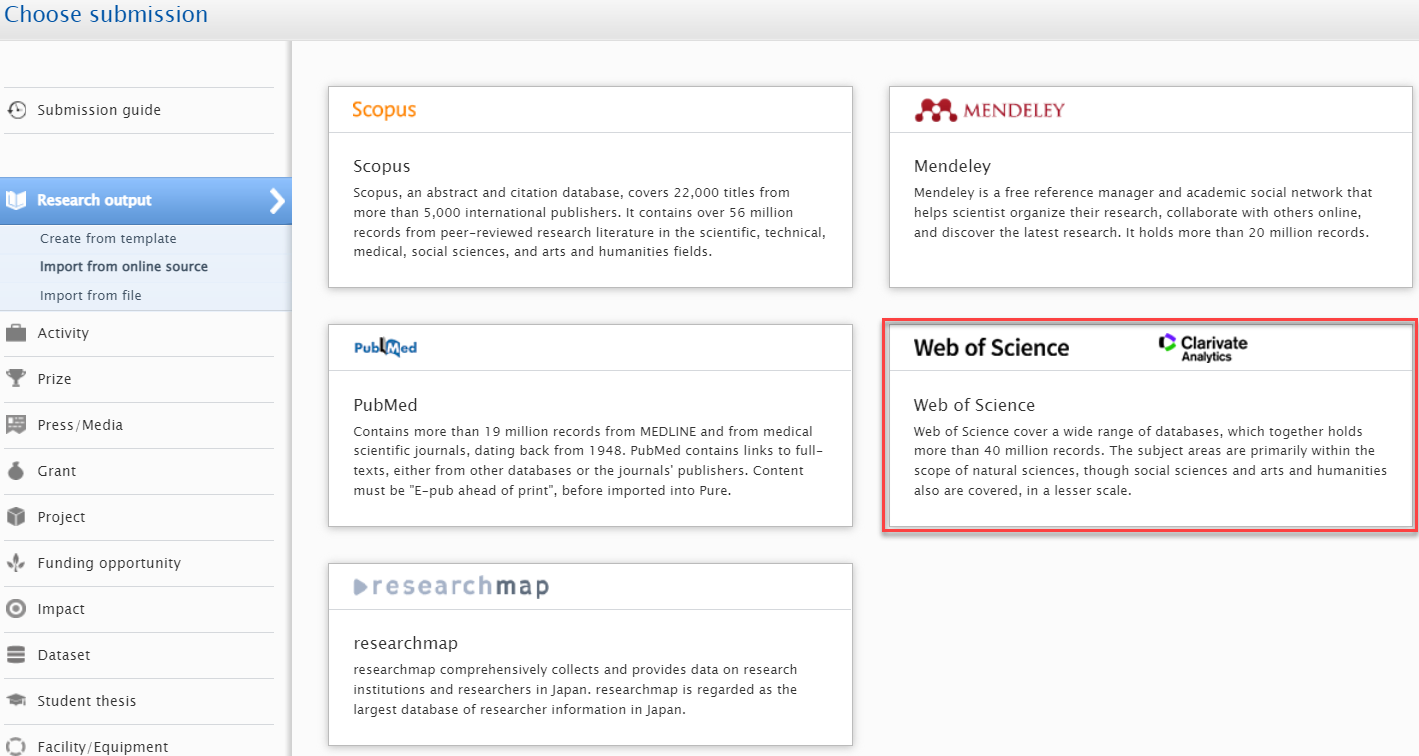
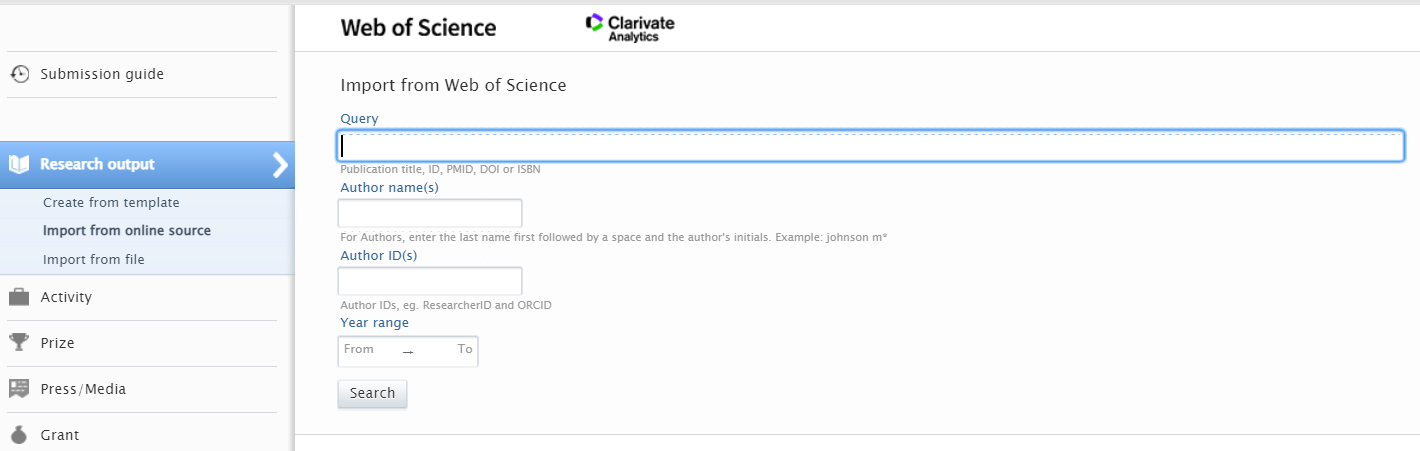
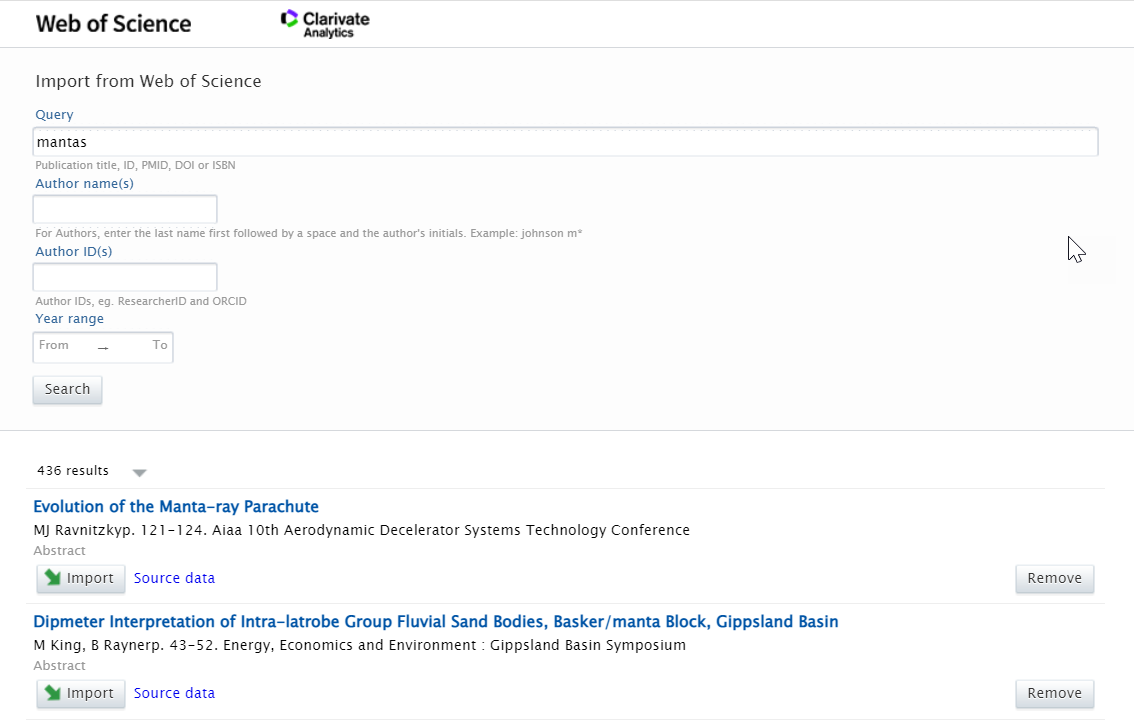
4.2. New overview pages: integrations request tracking (beta)
To provide you and your institution with a complete coverage of your data, we are continuously adding integrations and import sources that range over several content types and often have different data structures and requirements. We know that monitoring the usage of different sources and the performance of different import jobs is not always straightforward, which sometimes makes optimizing import processes (or identifying problems) challenging.
This is why we have started working on new set of tracking pages for integrations in Pure. These pages will be a space where research administrators can easily get an overview of the usage of import sources (both for requests made from Pure and for imported content), APIs and import jobs used by their institution and researchers.
We are happy to release the first pages that will make up this new tracking space, and we will continue working on adding functionality and additional APIs and sources over the next releases, so stay tuned!
Available resources
Pure Client Space > Webinars > Pure & Simple
Watch the Integrations (Request) Tracking webinar for an introduction to the functionality and its development plan.
Click here for more details...
In this first release, along with our update to the Web of Science integration, we have added tracking pages for requests made to Web of Science by different import jobs in Pure. This includes requests made to the Starter API and, when enabled, the WoS Expanded API.
The new tracking pages allow the monitoring of requests made to these APIs by the following import jobs in Pure:
- Self-import of research output
- Search for import candidates (research output)
- Available updates from online sources (WoS)
- Automatic import of metrics (total and yearly citations)
Instructions |
Screenshot |
|---|---|
|
Accessing the space To access the integrations tracking space, go to Administrator > Integrations > Request tracking |
|
|
Available tabs The request tracking space contains two tabs:
|
|
|
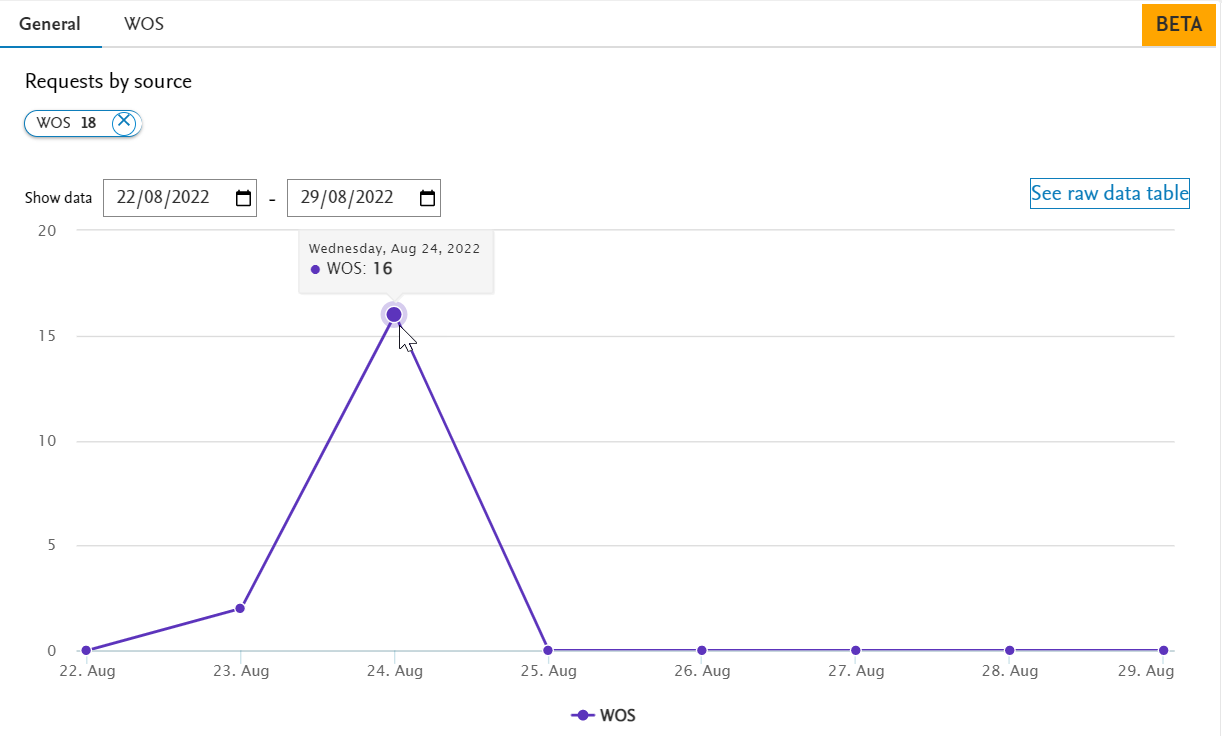
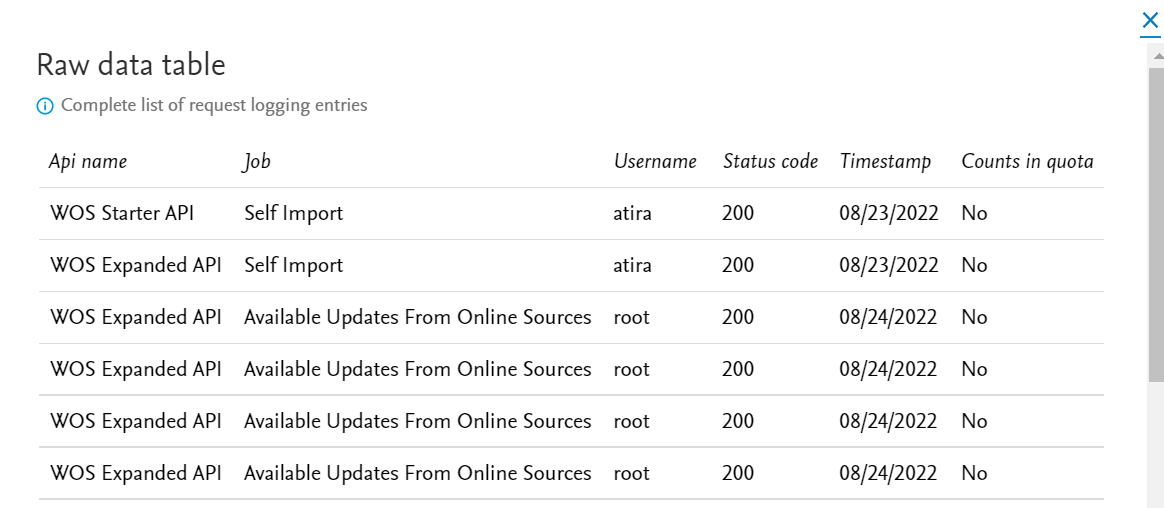
Viewing raw data In the general overview tab, select See raw data table in the top right corner to see further details of the requests made and their status. |
|
|
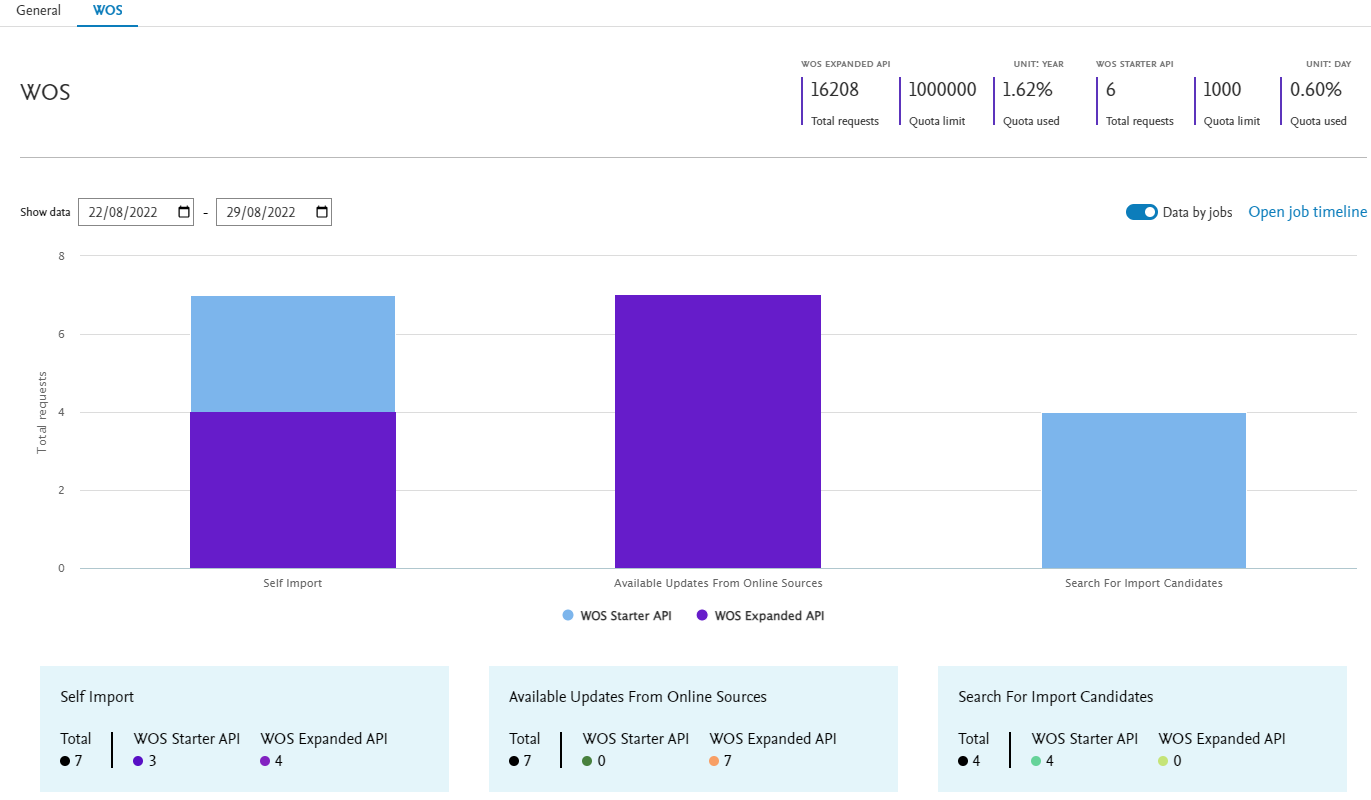
Source-specific tabs The source-specific tabs contain a detailed view of the total number of requests for the specific source. You can switch between two views:
The available quota for each API is shown at the top of the page. |
|
4.3. researchmap: automatic import
It is now possible to run an automated search based on the researcher's profile ID in researchmap, and configure the integration to either list records as import candidates, or automatically save the content in Pure. A number of configuration options let you determine the rules used for matching and enrichment of content in Pure.
Click here to expand...
Background
researchmap was first added to Pure in 5.21 as an import source, allowing researchers to manually search for and bring content into Pure. With this release, we have expanded this integration and added functionality to automatically import research outputs related to researchers at their institution.
The current configuration options for the automatic import of research outputs from researchmap are described below. The work to improve the automatic import configuration is ongoing and we are adding more configuration options and matching rules. Our goal is to optimize the automatic import configuration by making it possible to customize rules per import source.
Feature details
| Instructions | Screenshot |
|---|---|
|
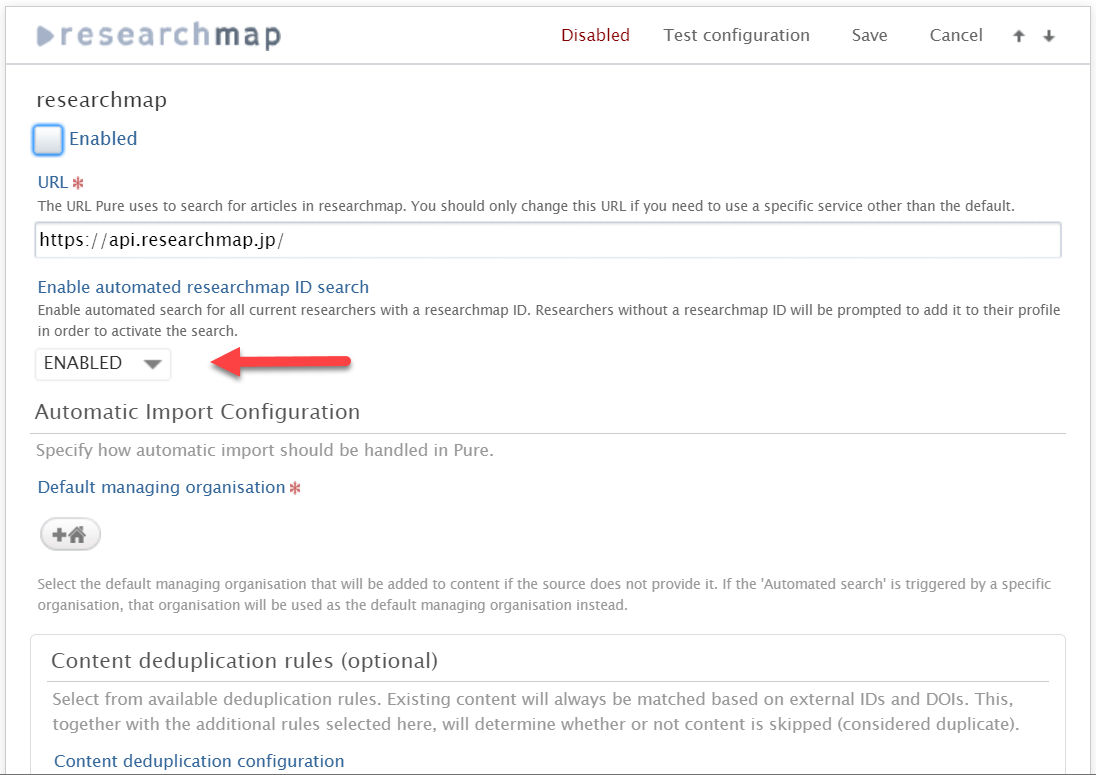
Enabling automatic import To enable the automatic import of research outputs from researchmap:
|
|
|
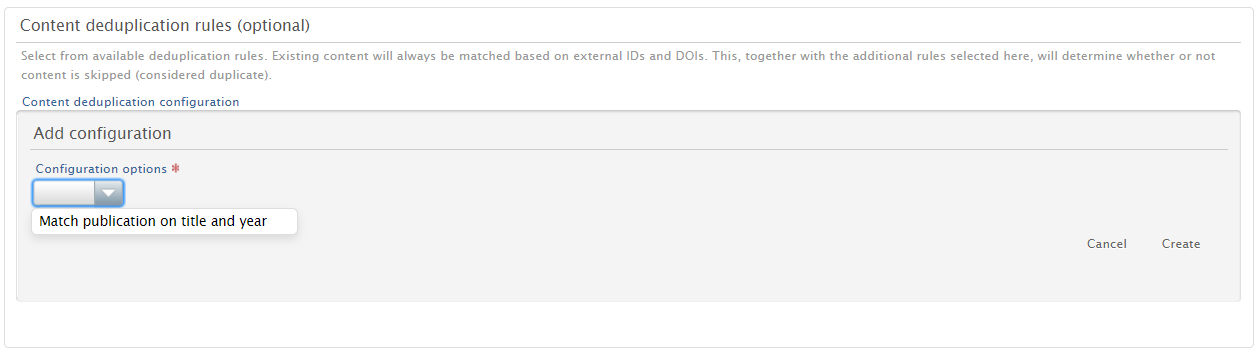
Setting deduplication rules It is possible to set rules for the deduplication of content. A description is shown when a rule is selected from the menu. |
|
|
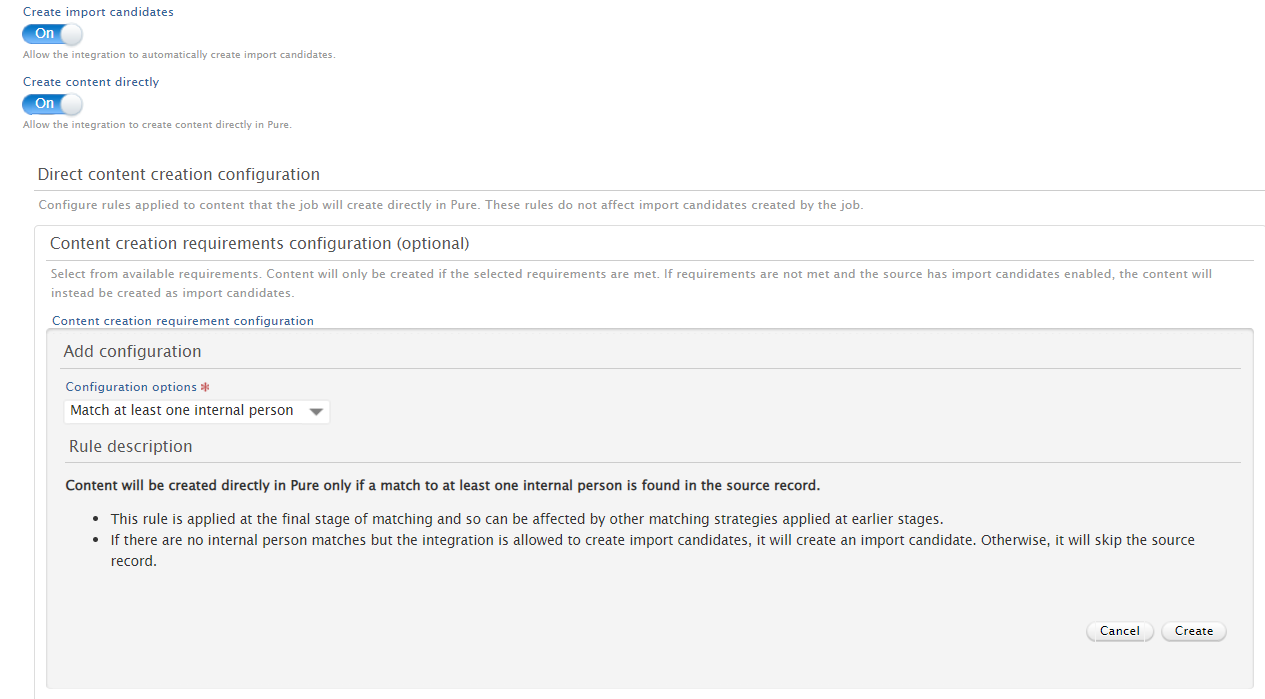
Setting import rules You can decide if you want to list records as import candidates or, based on configurable rules for the creation of content, automatically save the records in Pure. |
|
|
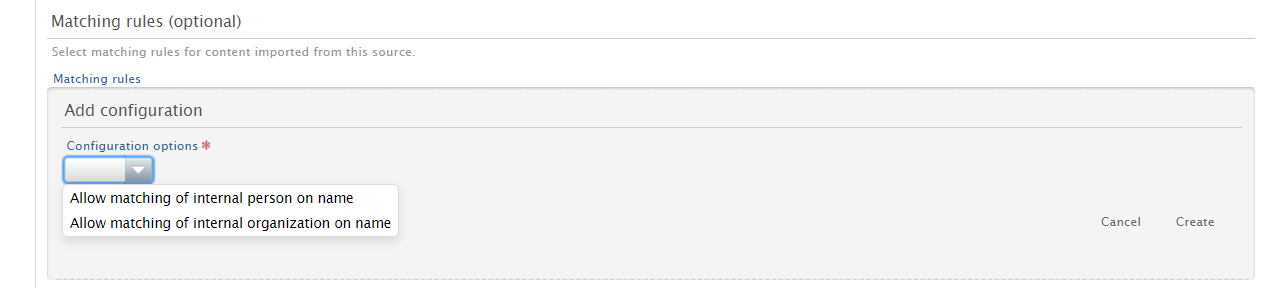
Setting matching and data enrichment rules In the 'Matching rules' section, you can set the conditions under which content is matched in Pure. In the 'Data enrichment rules' section, you can set the rules (and data) with which you want to enrich the new content imported to Pure. |
 |
|
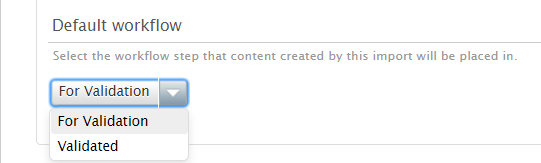
Setting workflow step for imported content You can also set the workflow step the imported content should be saved in to allow for a check on content that was imported directly. |
|
|
Importing content in bulk mode If you are enabling researchmap as an import source for the first time, you can select to import content in bulk mode. The job will check the import source for all content related to an organization, and all matched content will be imported into Pure in line with the configured import rules. |
|

4.4. JISC Publication Router: update to API v4
The JISC integration in Pure has been updated to the new v4 version of the API with no change to functionality. For more details on the integration see the 5.18.0 JISC integration release notes.
5. Unified Project Model and Award Management
5.1. Improved process support: milestones on projects and ethical reviews
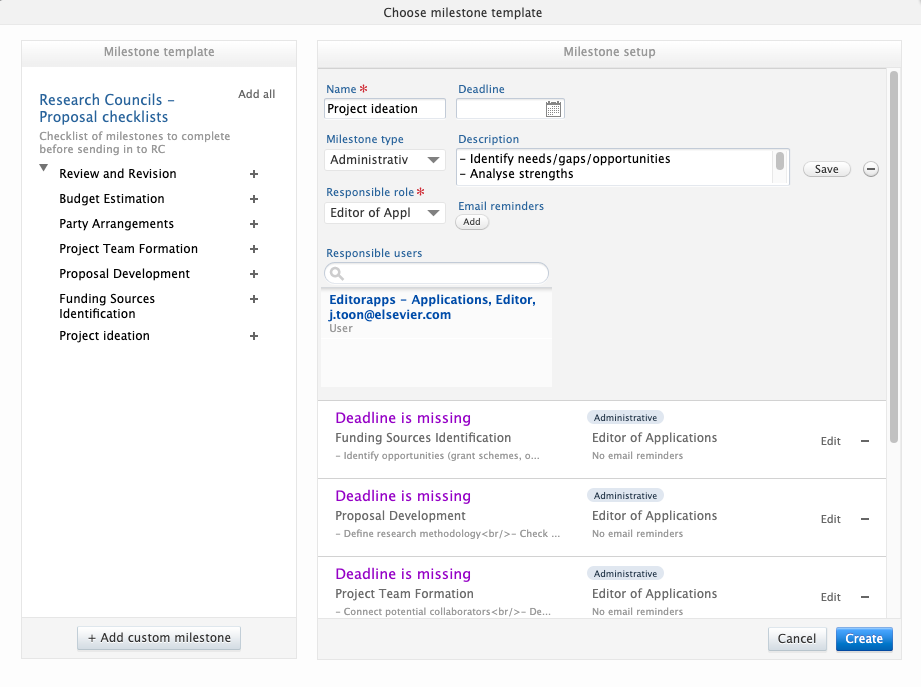
While previously milestones could be added to awards and applications, they can now be added to the project and ethical review content types as well. This allows for better support of task management across the award management life cycle. Milestones on projects and ethical reviews work similarly to milestones on awards and applications: you can create and specify details for custom milestones, or choose to create templates.
Milestone overview screens show what content family milestones are associated with, and milestone reporting includes support for all milestones types.
Available resources
Pure Manual > Award Management > Awards and Milestones > About Milestones
Click here for more details...
Instructions |
Screenshot |
|---|---|
|
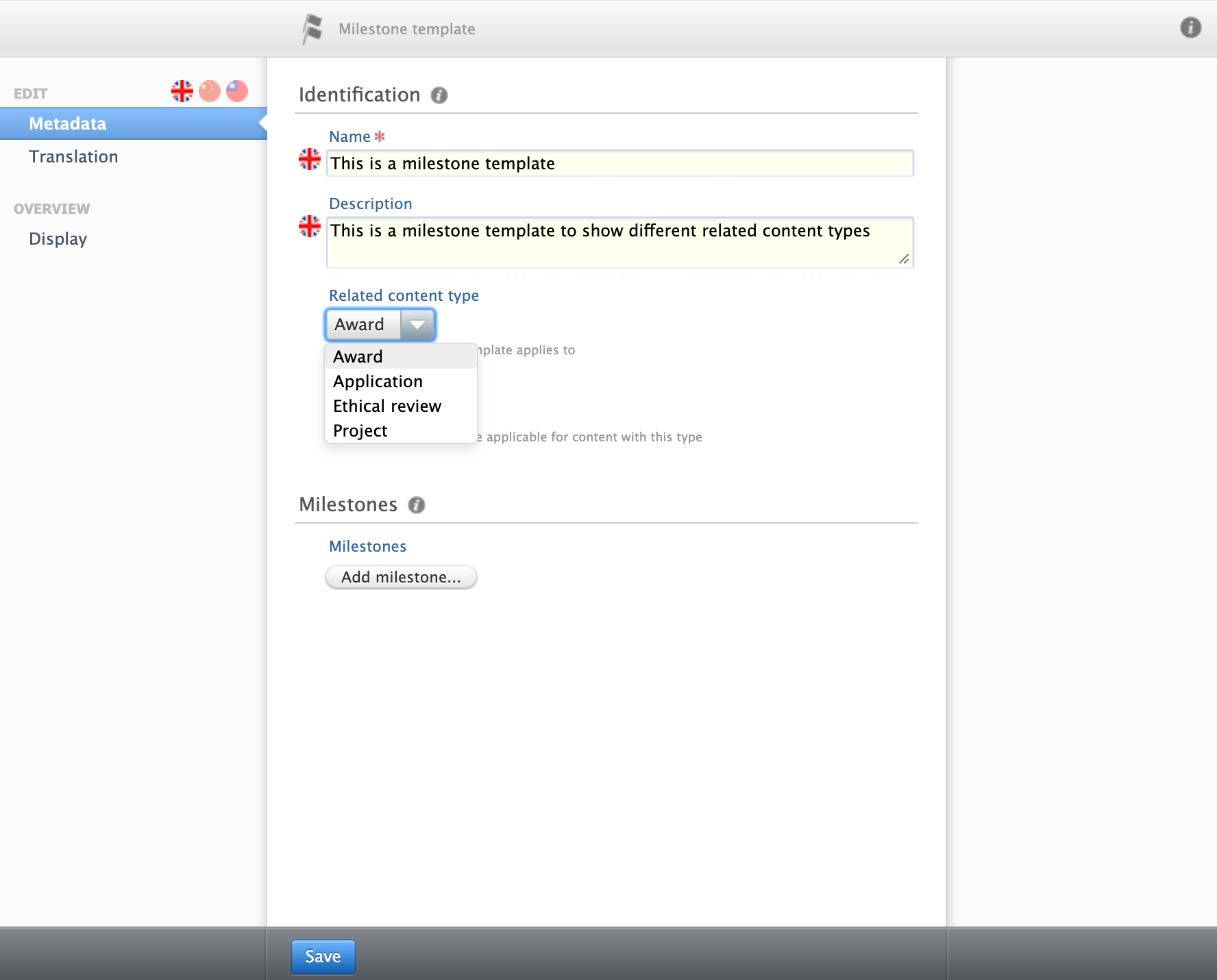
Adding milestone templates To add milestone templates for ethical review and projects:
|
 |
|
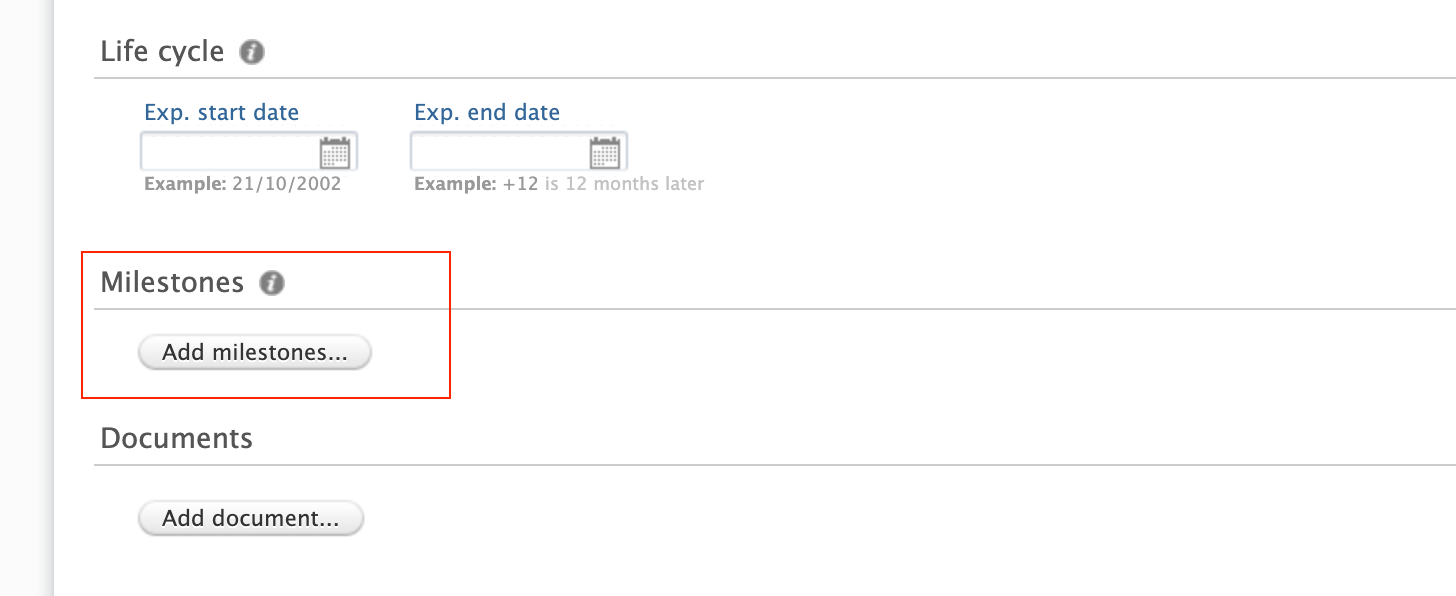
Adding milestones to content To add milestones on ethical reviews and projects:
|
|
|
Notifying users User notification options, including task and email settings, are in common with the existing milestone model. |
|
|
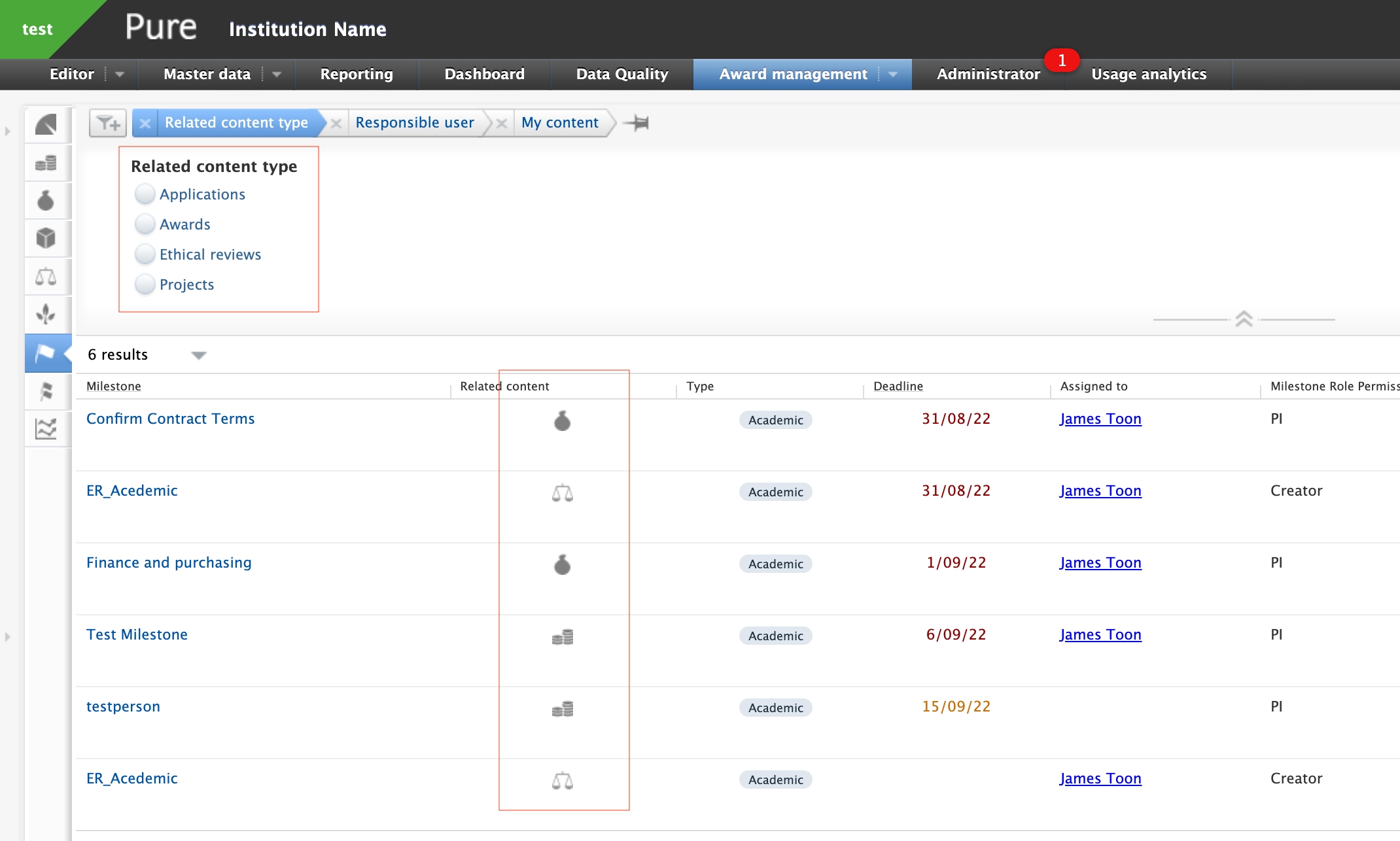
Milestones overview Milestone overview screens include an indicator of the content family the Milestones are associated with. You can also search by content family, and/or by content title. |
|
|
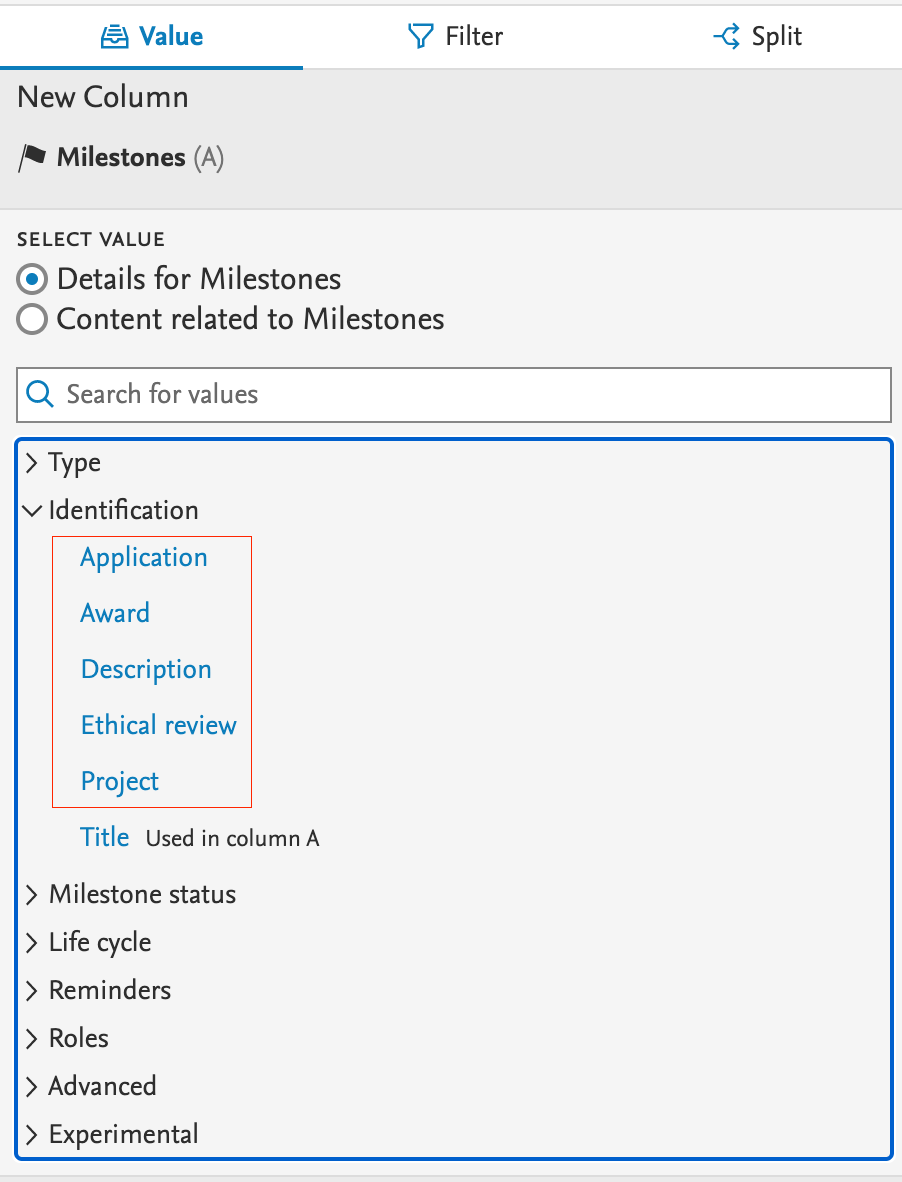
Reporting The Identification option lets you report on milestones by content type they are assigned to. |
|
6. Pure Portal
Pure version update and the update to the new fingerprinting service
The fingerprinting service will be updated on the 12th of October. As part of the update, the OmniScience thesaurus will include Arts & Humanities. However, this domain will be included only partially and we are still testing the update internally before we can recommend the switch to the updated service.
That is why we strongly recommend the clients who have enabled OmniScience, which was released as part of 5.24.0, to update to 5.24.4 or 5.25.0 before 24th of October.
Note: Hosted customers will be automatically updated to 5.24.4 on the 5th or 6th of October.
6.1. Added support for INIS thesaurus in fingerprinting
In addition to the new OmniScience thesaurus added in 5.24, based on client requests, we have added support for the International Nuclear Information System (INIS) Thesaurus. Maintained by the International Atomic Energy Agency, the INIS Thesaurus provides a classification scheme for institutions specialising in nuclear research. It can be used as the sole thesaurus applied to your content or combined with the OmniScience vocabulary, allowing for content to be fingerprinted against both vocabularies.
Upgrading to the new Fingerprint Engine (FPE)
The guidance provided on when to upgrade to the new Fingerprint Engine to the new thesaurus still stands, and we will release further communication later this year. Currently, it is not required to upgrade to the new OmniScience thesaurus, but the upgrade is available to those who wish to migrate.
Available resources
You can find out more about the Fingerprint Engine and the latest changes in Client Space > Fingerprinting. For an overview of the functionality, see Pure Manual for Technical Administrators > Fingerprint.
Click here for more details...
Instructions |
Screenshot |
|---|---|
Enabling INIS thesaurus Upgrading to the new Fingerprint Engine (FPE) To enable the INIS thesaurus, you will first need to have migrated to the new fingerprint service (see the 5.24 release notes for more details). Once your Pure is upgraded to the new FPE:
Note: Enabling/disabling a thesaurus will start full re-fingerprinting of content. |
|

6.2. Research outputs and projects: display of external organizations/collaborators
You can now enable the display of external organization relationships for both research outputs and projects on the Portal. For research outputs, this means showing the external organizations affiliated to authors on the output. For projects, this applies both to the external organizations affiliated to the project as well as any collaborative partners.
Click here for more details...
Research outputs
Instructions |
Screenshot |
|---|---|
|
Enabling collaboration display
This will trigger a republish of research outputs. The changes will be visible on the Portal when the republish is complete. |
|
|
Collaboration display on the Portal External organizations will be listed below the internal organizations. |
|


Projects
Instructions |
Screenshot |
|---|---|
|
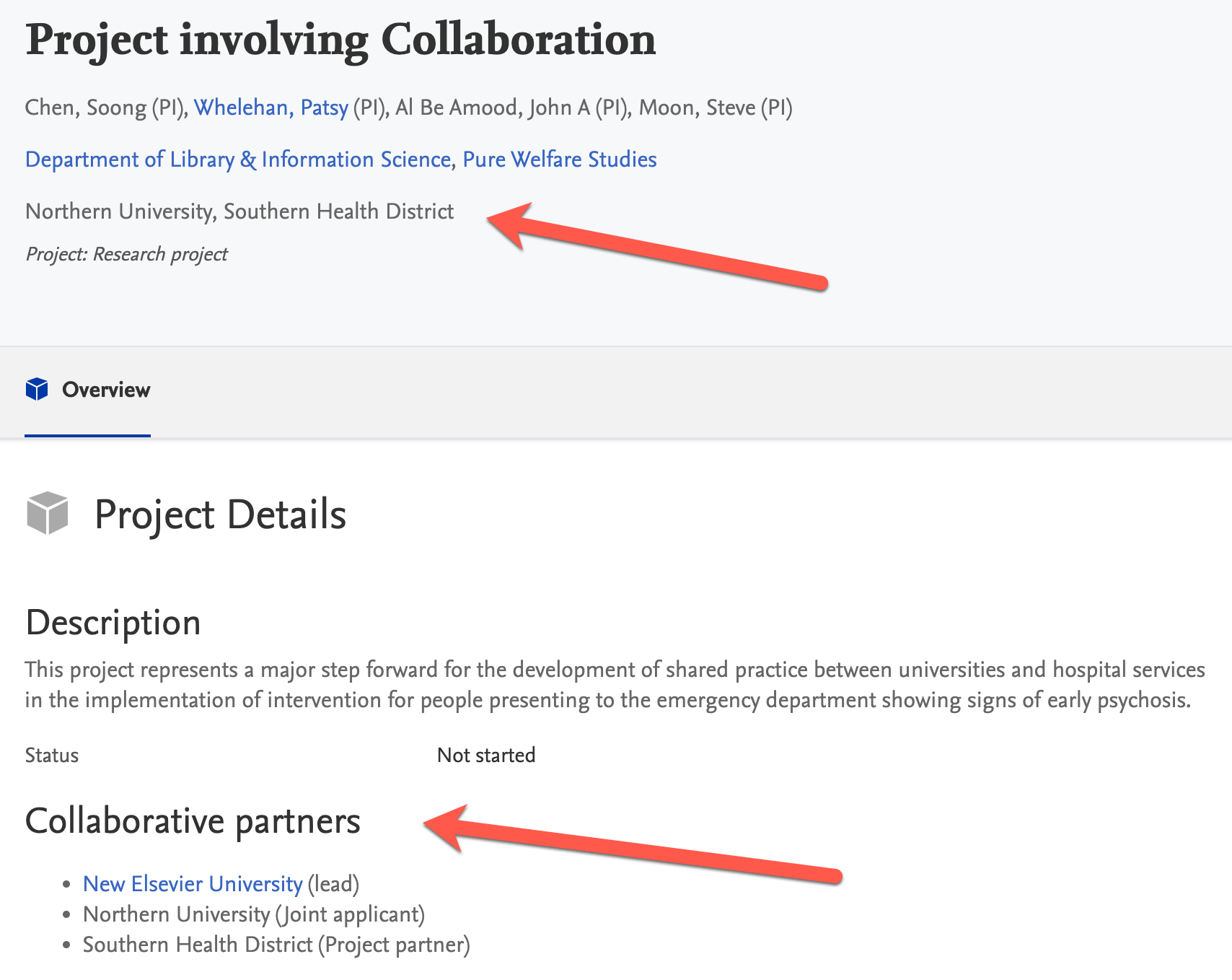
Collaboration display on the Portal External organizations will be listed under project participants, and collaboration partners will be listed lower on the page. |
|
|
Enabling collaboration display You can choose to show external organizations and/or collaboration partners.
Note: This will trigger a republish of projects. The changes will be visible on the Portal when the republish is complete. |
|

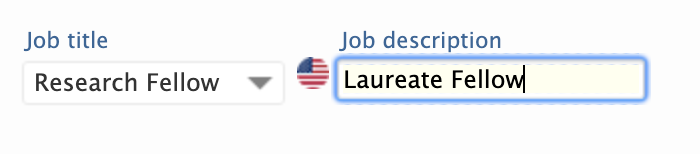
6.3. New configuration options: impacts and job title/description
With this release, you will have a number of new configuration options available on how the portal is rendered. These include choosing:
- which impact description fields should be displayed
- whether the status of the impact should be displayed
- what job information to show on a person's affiliation (e.g. job title or job description)
Click here for more details...
Impact configuration
Instructions |
Screenshot |
|---|---|
|
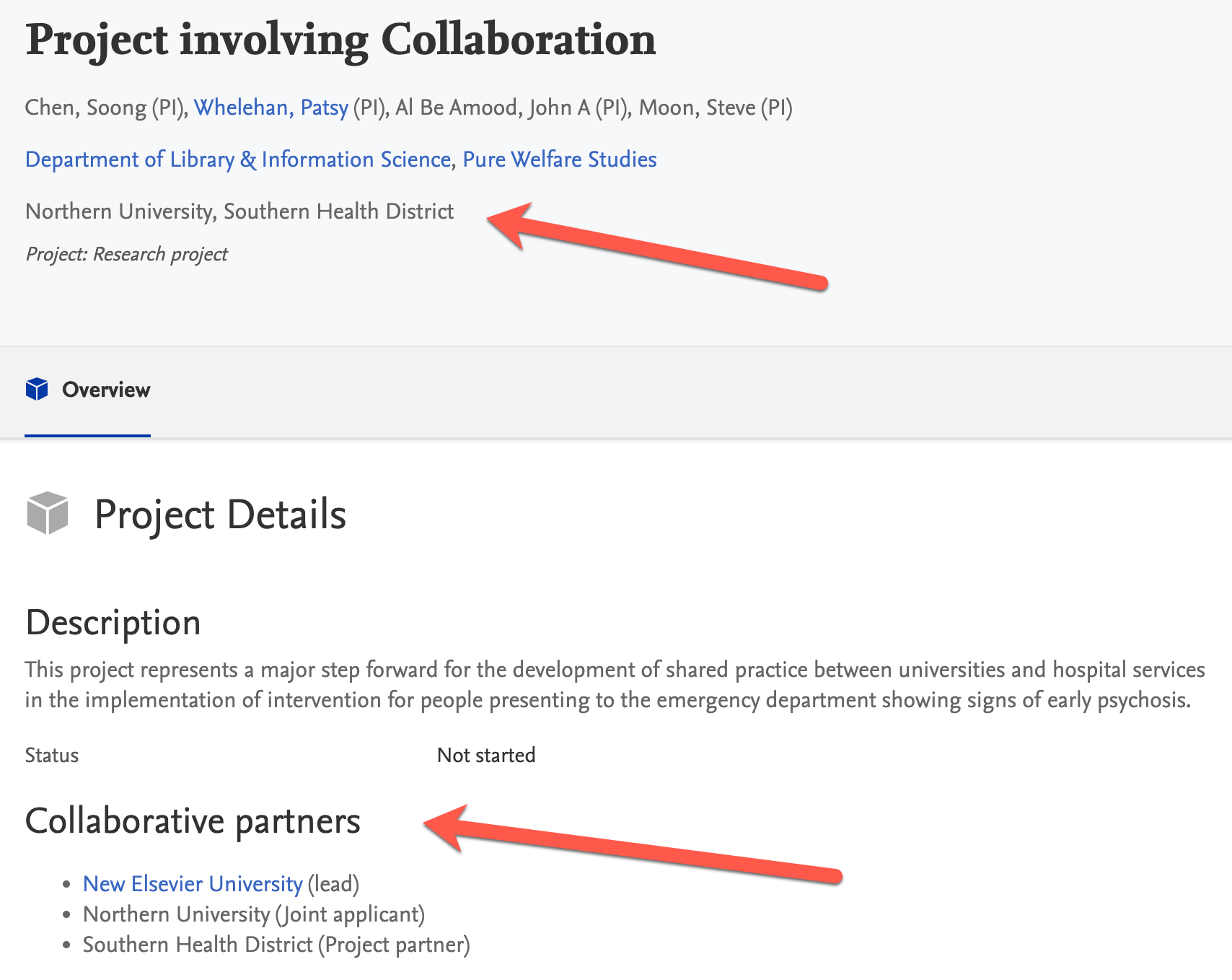
Configuring the display of impact status and description
Note: To see changes on the Portal, first save the configuration changes and then republish the impact content type inAdministrator > Pure Portal > Configuration > Impacts. By default, all descriptions and impact status will be visible on the Portal (as has been the case so far) unless these settings are changed. |
System settings:
Sample record in Pure:
Sample record in Portal:
|


Job information
Instructions |
Screenshot |
|---|---|
|
Configuring the display of person job information
Note:To see changes on the Portal, first save the configuration changes and then republish the person content type in Administrator > Pure Portal > Configuration > Persons. By default, the Portal will "Show job description (if not available, fall back to job title)". |
Configuration options:
Sample record in Pure:
Displaying job description:
Displaying job title:
|



6.4. hCaptcha: explicit opt-in
Update to 5.25.0 will automatically disable hCaptcha for all clients. The clients who wish to use it will need to re-enable it inAdministrator > Pure Portal > Configuration > hCaptcha.
Click here for more details...
Background
We were alerted to the fact that hCaptcha was implemented in Pure as a default functionality. This created the impression that hCaptcha was a new sub-processor of Pure. That is not the case. hCaptcha is an opt-in functionality to help manage possible spam through contact forms. If you wish to continue using hCaptcha as a functionality to stop or reduce spamming through the contact form, you must re-enable hCaptcha following the steps below.
Instructions |
Screenshot |
|---|---|
|
Enabling/disabling hCaptcha
|
|

6.5. Better navigation: organization hierarchy collapsed for large organizations
Until now, the organization hierarchy listing page of the Portal showed full hierarchy, which could become unwieldy for institutions with many organizational units. From this release on, institutions with more than 100 organizational units to be displayed in their hierarchy will not automatically expand beyond the first level. The hierarchy can be further expanded manually.
Click here for more details...
You can see in the example below that the Elsevier Research Groups is expanded, its child organizations are not, making the hierarchy page easier to navigate. Other aspects of hierarchy display remain unchanged.

6.6. Minor functionality and performance enhancements (OpenURL, GA4 and more)
As part of this release there are a number of small changes that have been made to support special use cases or to improve stability. To see more details of these expand the relevant section below.
Support for OpenURL Link Resolver
After the release of the SFX Link Resolver in 5.23, we received a number of requests to support different types of OpenURL Link Resolvers. With this release, we will be supporting the protocol more broadly.
Instructions |
Screenshot |
|---|---|
|
Enabling OpenURL Link Resolver
|
|

Added support for Google Analytics 4
As Google is transitioning from Google Universal Analytics to Google Analytics 4, we have added support for GA4 ID similar to the existing support Universal Analytics ID.
You can enter the GA4 ID inAdministrator > Pure Portal > Configuration > Google Analytics.
The ID will be applied to all Portal pages in the same way that that the current tracking ID is.

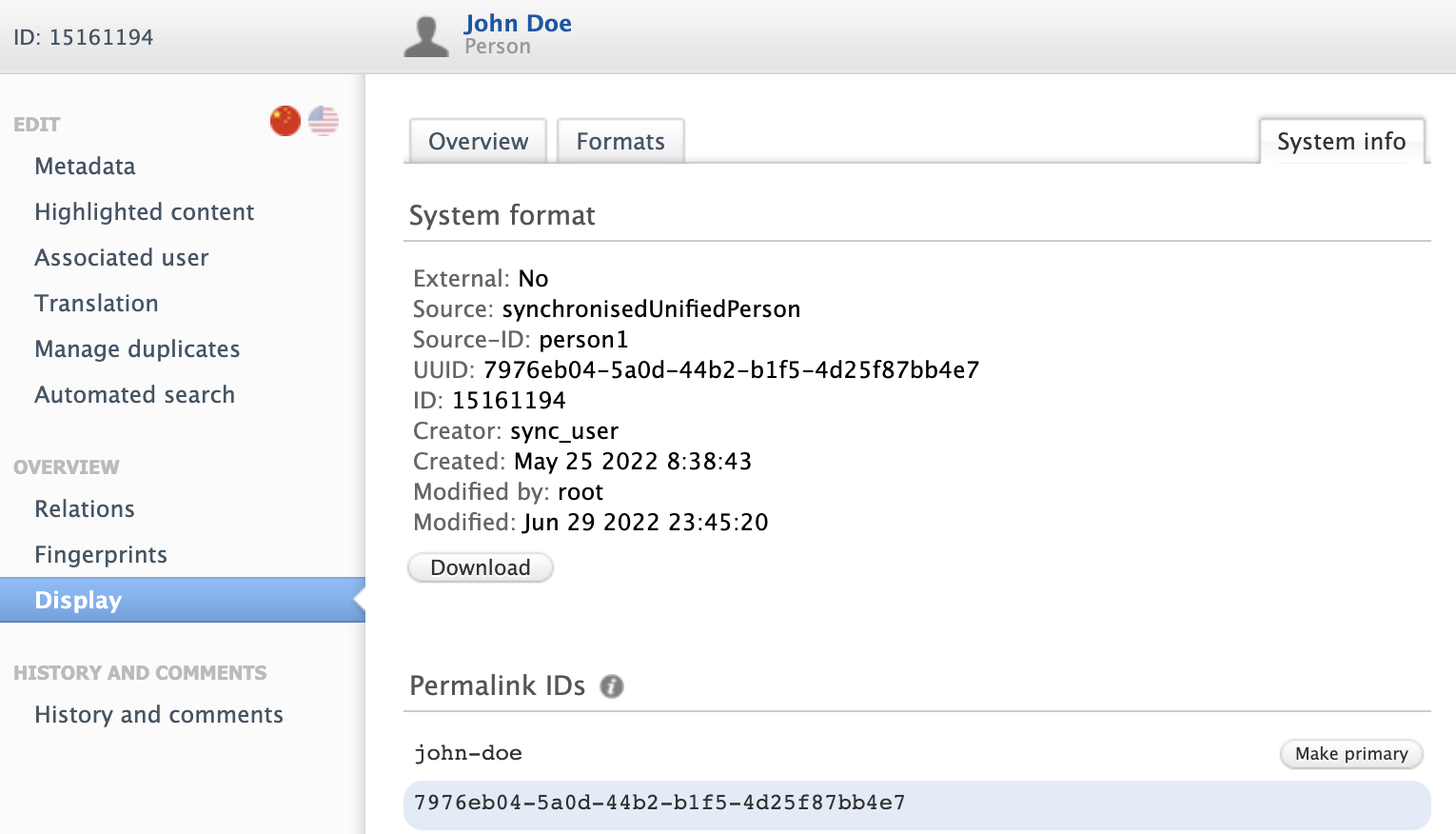
Improved human-readable URL generation
In this release we have made a number of improvements to how the human-readable permalink IDs are generated for Portal content. These changes include:
- Using the original title for outputs instead of translated titles
- Fixed edge cases where overlaps in parts of names was causing misallocation of IDs
- Stopped generating IDs for external organizations and external persons as these aren't displayed on the Portal
These permalink IDs are locatable under Display > System info on content editors
Fixed intermittent text resource editing issue
There has been intermittent issues with the authentication process for changing text resources on the Portal, with it often failing to activate on the first attempt. The process for activating the text resource editing has now been rebuilt so this issue should no longer exist.
7. Reporting
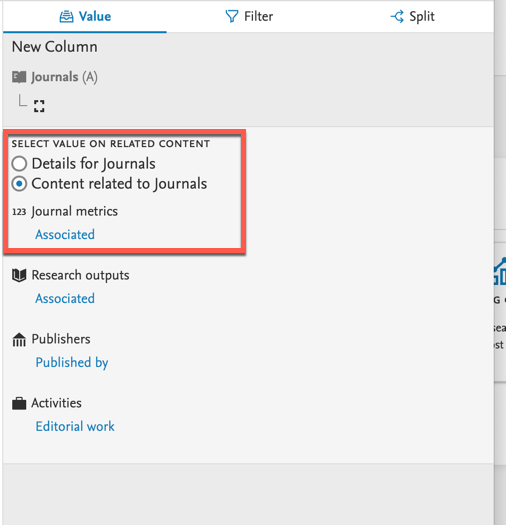
7.1. Reporting on metrics: metrics as related content
We have redesigned the way of reporting on metrics in order to improve the performance of the reporting module. In previous versions, metrics were selected as part of the details of the content, now this have been changed into a relation to the content. The data is now stored in a format optimized for reporting.
In this release, we have made the new improved way of reporting on metrics available for: Research Outputs, Journals, and Publishers. This is the first iteration of the improvement, and we are working on how to make the user experience even smoother and more efficient.
Available resources
Pure Client Space > Technical User Guides > Metrics in Pure > Metrics overview
Go to sub-pages for individual metrics to download .json workspace examples. Note: The pages will soon be updated to include examples of the new way of reporting on metrics.
Click here for more details...
Instructions |
Screenshot |
|---|---|
|
Adding metrics as related content To include metrics in your data table, add them from the related content section. Currently metrics are available as related content on:
|
|
|
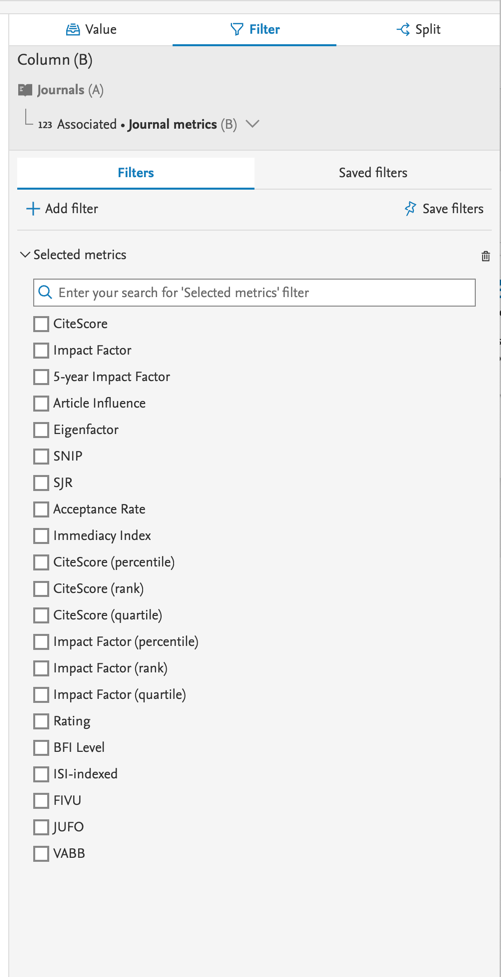
Filtering on metrics Once metrics are added to your data table as related content, you can limit what metrics to include by applying a filter on metrics. For example, if you are interested in reporting on the SNIP metric for journals, it is easy to filter on this metric, and include only that metric in your data table. |
|
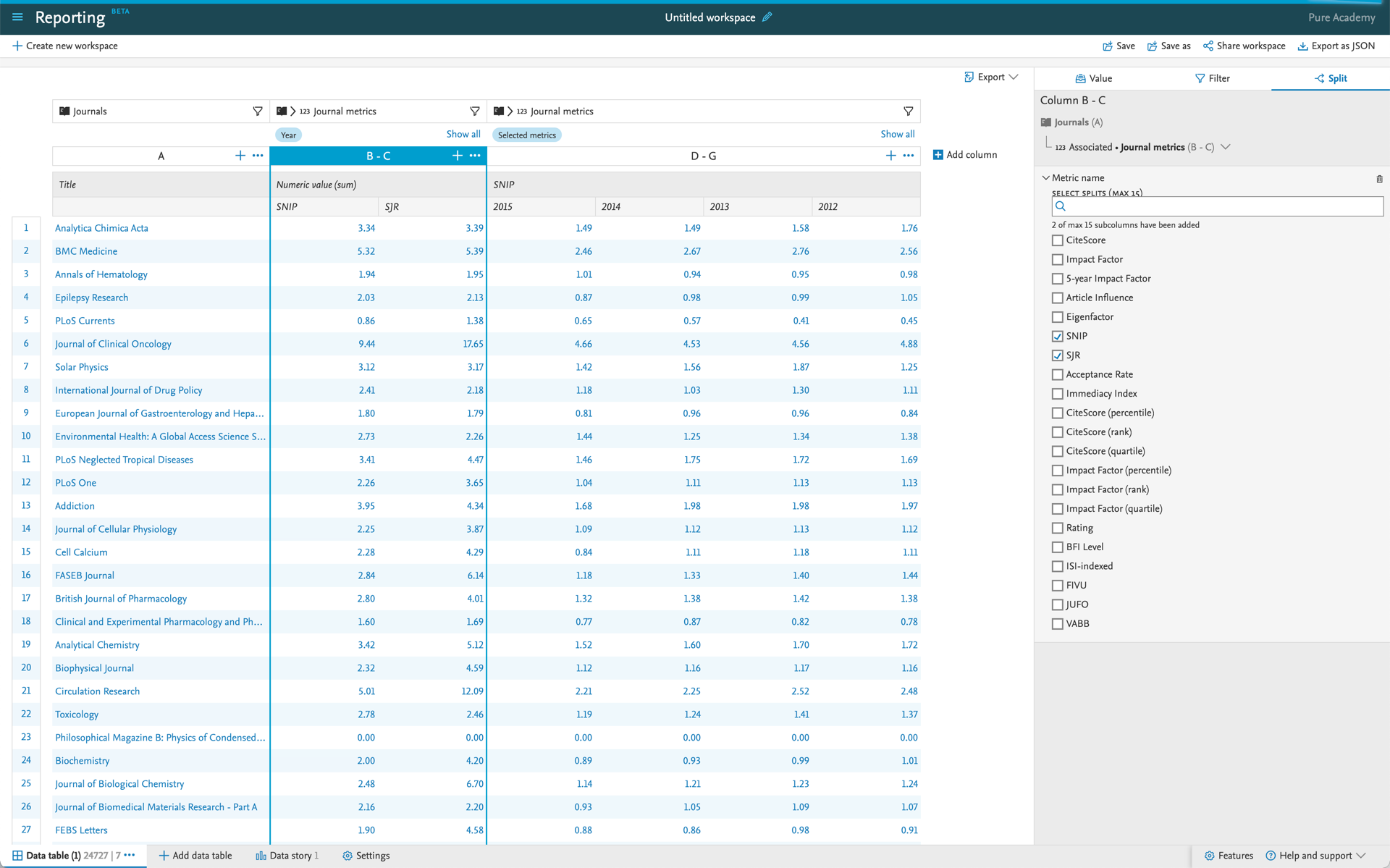
Tip: Tracking metrics over time If you want to view the progression of a metric over time, you can combine the usage of splits and filters to create that view. In this example, we are focusing on the years 2012-2015 for the SNIP on journals and we are comparing the SNIP and SJR for 2013 for journals as well. This is all done by using filers and splits to demonstrate how metrics can be included in your report. |
|
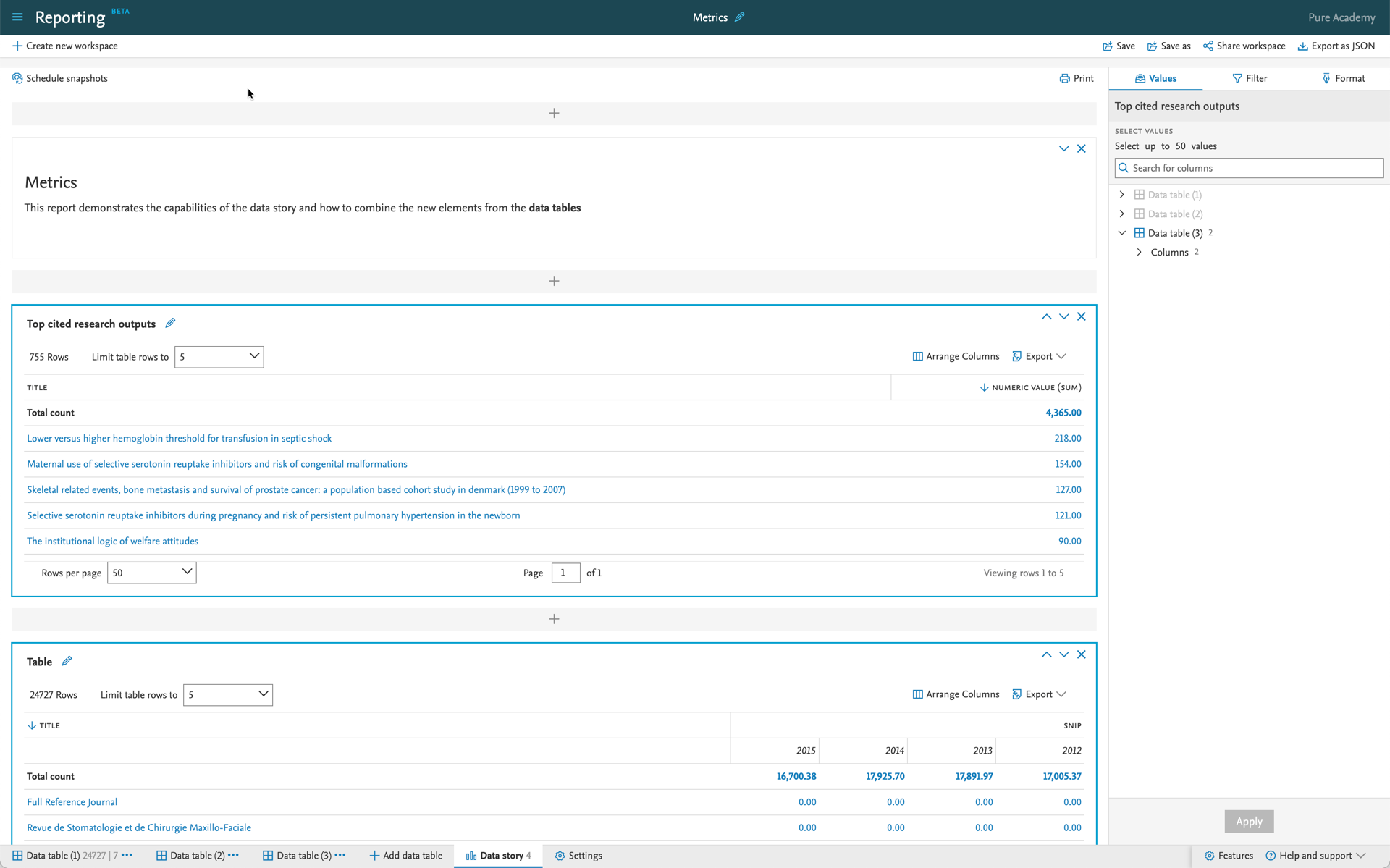
Data story: Telling your stories with metrics Once the data tables are built with the metrics needed for the narrative, metrics data can also be used in a data story. |
|
|
Data migration In order to improve the performance of the module, Pure will now run a job which maintains data in the new optimized format. As the first iteration of the job can take some time, we advise you to wait for the first couple of hours after the upgrade to give the job time to complete, and to not use reporting while the job is in progress. The actual time it will take to finish depends on many factors, such as the database type, and the amount of data, such as metrics, etc. You can check the status of the job under Administrator > Jobs > Job log. |
|

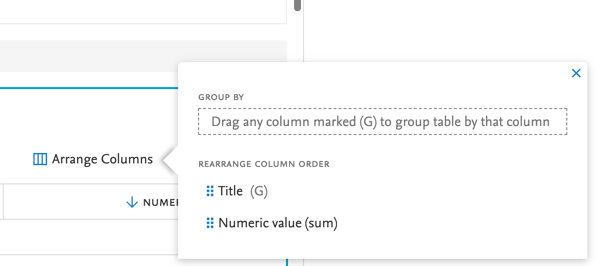
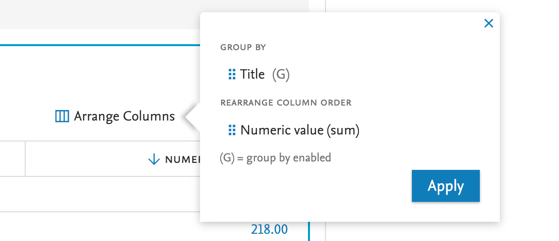
7.2. Data story: grouping table by a selected column ('group by')
You can now control the grouping of columns in the data table widget in the data story. Before, the table widget always grouped columns in order from left to right; from now on, you can define which columns, if any, should be used for grouping.
Available resources
Pure Manual > Reporting Module (Beta) > Data story
Click here for more details…
Instructions |
Screenshot |
|---|---|
|
Selecting columns To select which columns should be used for grouping in the table widget select Arrange columns |
|
|
Grouping by column To group by a column, simple drag and drop the column to the area. Any columns that can be used for grouping are marked with a (G) next to them. |
|
| Any columns that can be used for grouping are marked with a (G) next to the name. | 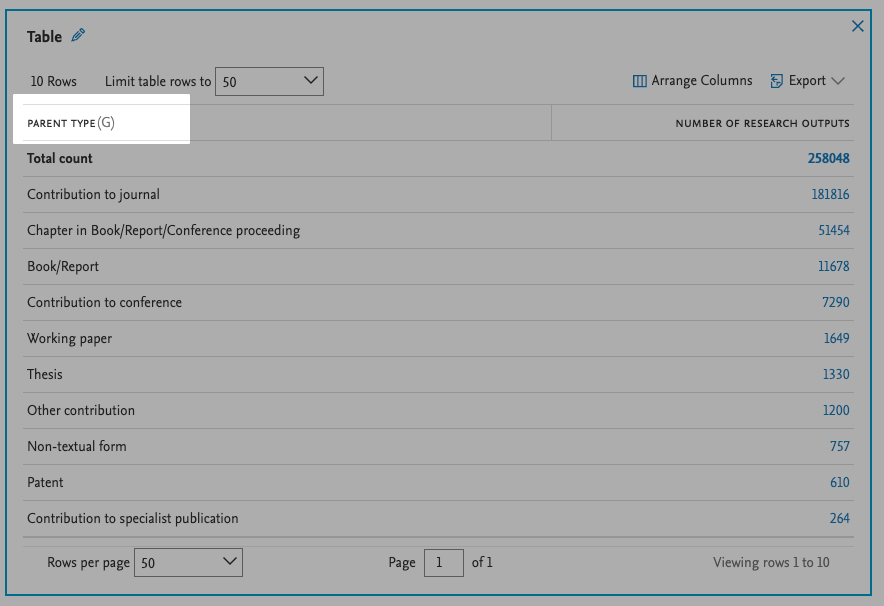 |
Published at August 20, 2024