
How Can We Help?
Use CDATA for Formatting in Abstract Field in XML ImportUse CDATA for Formatting in Abstract Field in XML Import
What
When importing content types with an Abstract field, they may require some formatting of parts of the text, for example in bold, italic, superscript or subscripts, or linebreaks.
Potential issues would be:
- the expected paragraph format is required to indicate some chemical component and formula: For example, placing some superscript e.g.
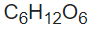
- paragraph may require some line break i.e. phrase or clause.
How
- The abstract field in Pure is a field that allows you to use markup and xhtml tags are accepted. Most tags are accepted, but some tags are excluded i.e. script tags etc. The ones that are used for presentation is preserved.
- The reason for the encoding of the <> is because the abstract is embedded into the XML document, because of that it needs to be escaped or the abstract text should be placed in a CDATA XML section.
- In documentation at Publication.xsd, the CDATA is enumerated.
XML
<xs:element name="abstract" type="commons:localized_string" minOccurs="0">
<xs:annotation>
<xs:documentation><![CDATA[
The publication abstract
It is recommended that this field is wrapped in a CDATA field and that < and > characters are encoded to > and < if they aren't a part of HTML markup in the data.
]]>
</xs:documentation>
</xs:annotation>
</xs:element>
Note:
- Webservice or integration processes may strip off the HTML tags if not encoded in CDATA.
- The symbols < > are not part of a HTML tag so "<" is encoded to be < (means less than) and ">" to be > (means greater than).
Please be aware that XML parsing in CDATA can get complicated and result in difficult troubleshooting.
More information
KB-373 How to add hyperlinks in text box
KB-470 Use HTML to get link color
w3.org on CDATA
Note: Some of this information is for internal use only and might not be accessible.
Published at October 24, 2023