
How Can We Help?
5.19.05.19.0
Highlights of this release
 Open Access enhancements
Open Access enhancements
With expanded Open Access (OA) policies from governments and funding agencies, there is a need for researchers and institutions to be able to easily find, manage, and report on their OA research output. In line with these needs, we have been working hard on improving existing options and functionalities in Pure related to Open Access, as well as adding new OA import sources and expanding our model to capture relevant information.
We have introduced additional ways of communicating OA information on content including details related to journals, publishers and/or institution's own preferences, and the new Sherpa Romeo recommendations.
We have also completed the integration with Unpaywall and CORE, two large OA databases, and bioRxiv, a pre-print server focusing on publications in Biological Sciences.
 Reporting on organisational hierarchy
Reporting on organisational hierarchy
Pure 5.19.0 comes with a brand new feature: reporting on the hierarchy of an organisation. This means that you are now able to report not only on a single organisational unit, but also on the organisational hierarchy above or below.
You can now:
- roll-up of information in a hierarchy
- drill down a hierarchy
- summarize each level of a hierarchy
Similarly, when filtering, you can now choose to filter on the selected organisational unit itself, or on the entire organisational hierarchy below.
You can access this feature where you normally choose your organisational values and filters in a report.
 Pure Portals multimedia integration
Pure Portals multimedia integration
The Pure Portal serves to promote your research and help your institution put its "best foot forward" at every level. Doing this effectively means going beyond the article, and using multiple types of multimedia to contextualize and showcase your output.
In this release, we've taken some big steps to expand the capabilities of the Portal to keep up with the modern research landscape. Please share with us your feedback on what you'd like to see next!
Watch the 5.19 New & Noteworthy seminar
We are pleased to announce that version 5.19.0 (4.38.0) of Pure is now released.
Always read through the details of the release - including the Upgrade Notes - before installing or upgrading to a new version of Pure.
Release date: 5 October 2020
Hosted customers:
- Staging environments (including hosted Pure Portal) will be updated 7 October 2020 (APAC + Europe) and 8 October 2020 (North/South America).
- Production environments (including hosted Pure Portal) will be updated - October 28th 2020 (APAC + Europe) and October 29th 2020 (North/South America).
Advance Notice
The new Personal User Overview will become the standard overview with the release of 5.20.0. Due to REF, UK customers will have the choice to delay this until 5.21.0 at the latest.
Download the 5.19.0 Release Notes
last updated 7 October 2020
1. Web accessibility
We continue to work towards being fully WCAG 2.1 AA compliant by February 2021 by ensuring accessible design in new features. In addition, we implemented the following improvements to existing features:
1.1. Pure Portal accessibility improvements
With this release, we have made Portal navigation even more inclusive. These improvements bring us within touching distance of our goal of achieving WCAG 2.1 AA compliance in the first half of next year. To talk you through the main changes, our lead accessibility designer Mike Bertelsen made a video review. You can also read the summary below.
Click here for more details...
Some of the changes include (but are not limited to):
- Better HTML tags. Correct tags make it possible for keyboard and/or screen reader users to interact and understand the various Portal features we have.
- Landmarks with correct tags and aria-labels. This allows screen reader users to quickly navigate by section and better understand what is available on the page.
- Improved headline order. All headlines appear in the correct order to allow screen reader users to quickly navigate by headline; this also improves SEO.
- Field labels. Input fields have labels that describe their purpose.
- HTML5 tags and roles applied in several areas.
- Fully supported keyboard navigation.
- Improved color contrast of links, buttons, text and other interactive elements.
Other minor improvements include:
- Accessible tooltips.
- Search results shown as a lists rather than block elements.
- Search result count on a content type is announced to the screen reader.
- Applying filters is announced to the screen reader together with the search result count.
- Text spacing has been improved.
- For most components, we no longer rely on sensory characteristics such as shape or size.
2. Privacy and personal data
The protection of privacy and personal data is extremely important to Pure. Based on guidance provided by GDPR (and similar frameworks), we continually add improvements to how Pure handles sensitive data, and we continually provide tools for users to manage their own and others' data in Pure. In this release, no specific new features have been added. We expect subsequent releases will contain improvements, and critical issues reported by our customers will always be addressed immediately.
3. Open Access
With expanded Open Access (OA) policies from governments and funding agencies, there is a need for researchers and institutions to be able to easily find, manage, and report on their OA research output. In line with these needs, we have been working hard on improving existing options and functionalities in Pure related to Open Access, as well as adding new OA import sources and expanding our model to capture relevant information.
3.1. Open Access guidance section
We have introduced additional ways of communicating Open Access (OA) information on content. This includes details related to journals, publishers and/or an institution's own preferences. In the newly added 'Open Access Guidance' section of the Journal and Research Output editors, Administrators can now control what OA information is shown, presenting users with the most relevant OA references and guidelines at the right moment in their workflow. The section also includes Sherpa Romeo recommendations.
Click here for more details...
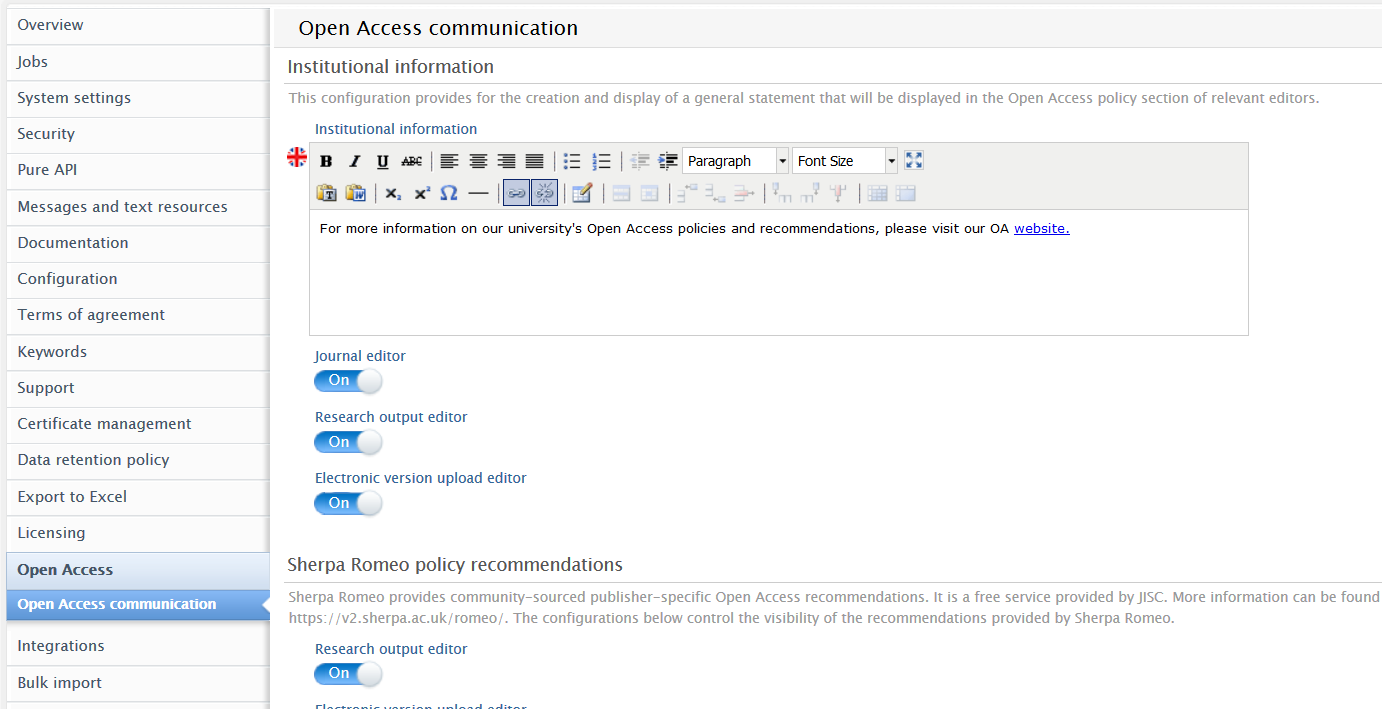
To configure visibility options for OA guidelines, Administrators can navigate to Administrator > Open Access > Open Access communication.
Institution's Open Access recommendations
Administrators can create an Open Access-specific message with hyperlinks to their institution's resources, and toggle the display setting to activate it on specific editors.
This message can be shown in the Journal editor, Research Output editor and the Electronic version upload editor.
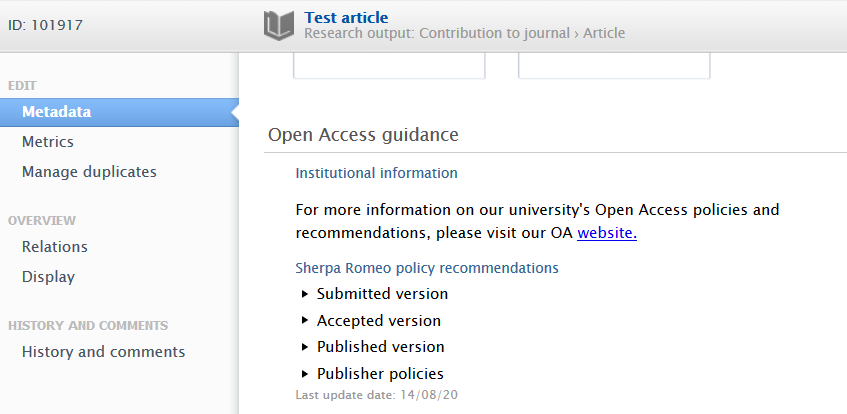
Sherpa Romeo recommendations
Sherpa Romeo (SR) information has been updated (see the Sherpa Romeo section in these release notes for more information) and is now part of the 'Open Access guidance' section. Administrators can toggle the display setting to activate it on specific editors.
Sherpa Romeo information is always shown in the Journal editor, with control on visibility limited to the Research Output editor and the Electronic version upload editor.
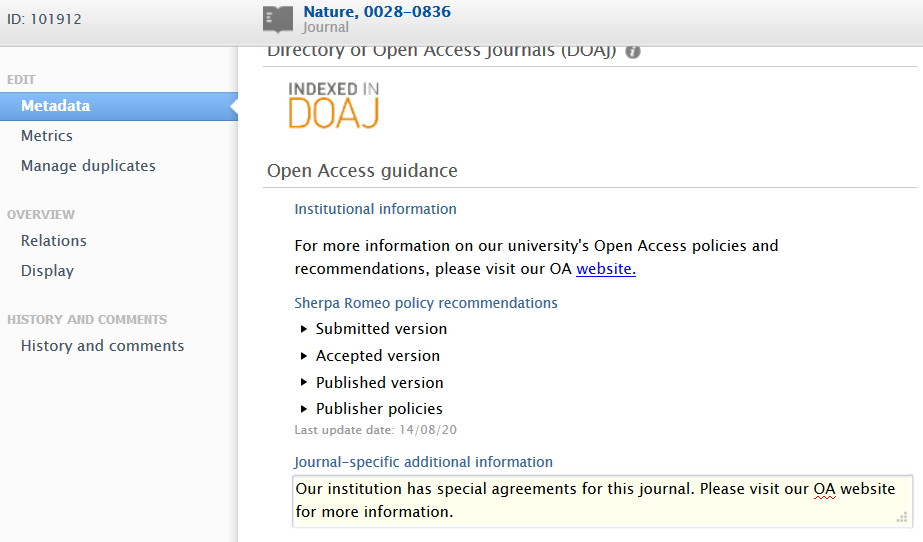
Journal-specific additional information recommendations
Users with rights to edit journal metadata can add journal-specific OA information in a dedicated text field.
Journal-specific information is always shown in the Journal editor, with control on visibility limited to the Research Output editor and the Electronic version upload editor.
Configuration of Open Access guidance message and visibility on editors
|
Open Access guidance in Journal editor Journal editor > Metadata
Open Access guidance in Research output editor Research Output editor > Metadata
Open Access guidance in Electronic file upload window
|
Sherpa Romeo and widgets
With the update to the Sherpa Romeo model, widgets that use SR information in the dashboard module will no longer function. Please contact Pure Support for help in configuring a widget that provides the same functionality.
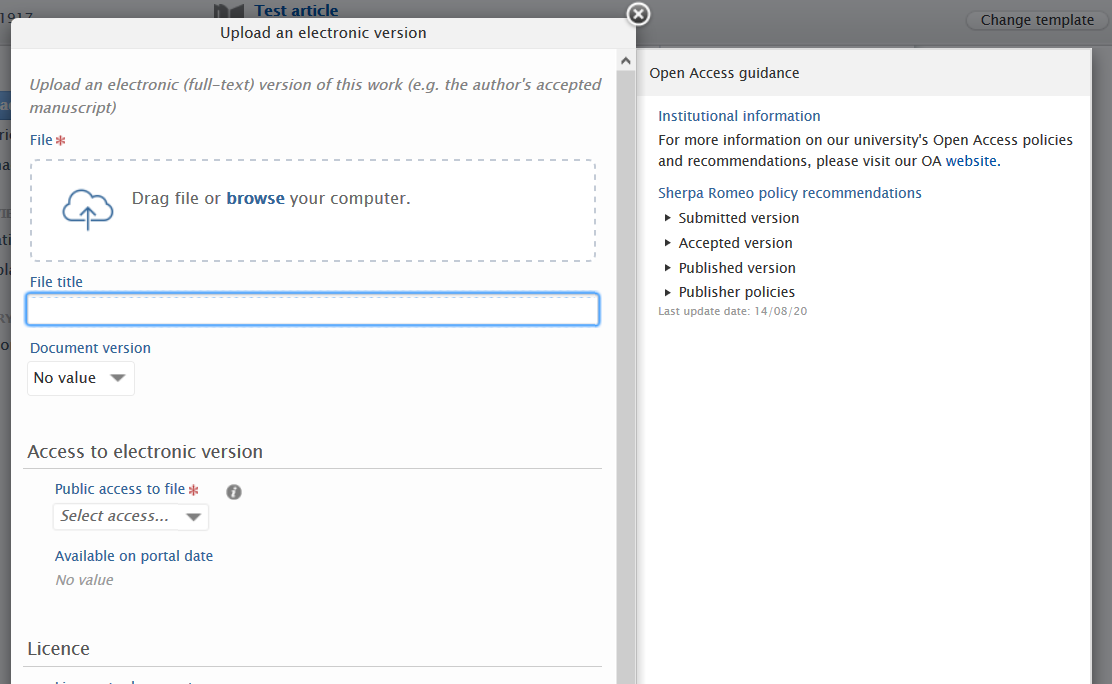
3.2. Open Access file upload reminder
This feature will be available in 5.19.1
To improve Open Access (OA) compliance, administrators can enable and configure reminder messages for users to add full-text files to content that is potentially OA. The reminder title and message body can also be customised to point users to their institution's own resources.
Click here for more details...
To enable the reminder
Administrators can navigate to Administrator > Open Access > Open Access communication and toggle on 'Set task and weekly digest email for personal users as default'.
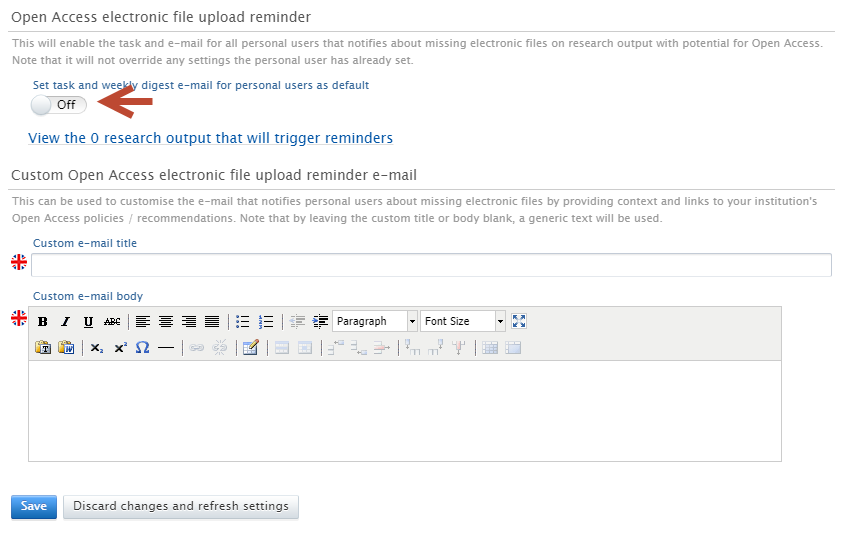
To configure the title and message body
The title and message body can be customised using the clearly labelled free text editors. Administrators can add URLs and rich text formatting to the message body if needed. If nothing is added to the title or description fields, an appropriate generic text will be added automatically.
Once the reminder has been enabled and configured, the configuration must be saved.
What triggers the reminder to be sent?
Reminders will be sent to internal authors on the content when the following research output conditions are present:
The Open Access status is:
- None or Indeterminate
The Open Access policy is:
- Any Open Access route (based on Sherpa Romeo information)
And the Publication status filter is:
- Published, E-pub ahead of print, and Accepted/In-press
Administrators can examine the specific content that these conditions apply to by following the link 'View the X research outputs that will trigger reminders'.

Note: even if reminders are configured to be sent by Administrators, Personal users can still disable the reminders in their user preferences.
3.3. Sherpa Romeo model and API updates
Sherpa Romeo (SR) is a free service by Jisc (https://v2.sherpa.ac.uk/romeo/) that provides community-sourced publisher-specific Open Access recommendations. SR has recently transitioned from their color scheme to a new format which provides more information per publication status. Coinciding with the model changes are API changes including the need for customers to register for API keys.
Click here for more details...
Model updates
We have updated the display of SR information in Pure to reflect the model changes. Administrators can now control the visibility of SR information for the Research Output editor and Electronic version upload editor (see Open Access guidance section). The new format of SR recommendations provides more detailed information for each publication state of an article, i.e. Submitted, Accepted, Published.
You can check this detailed information on Research Output, Journal and electronic version upload editors, by clicking to expand each of the article state sections in Open Access guidance>Sherpa Romeo policy recommendations. The details include prerequisites, embargo periods, locations of the document, conditions, and more.
Note: Visibility on each of the editors must first be enabled.

Sherpa Romeo filters
SR filters are now included in the Open Access policy filter set.
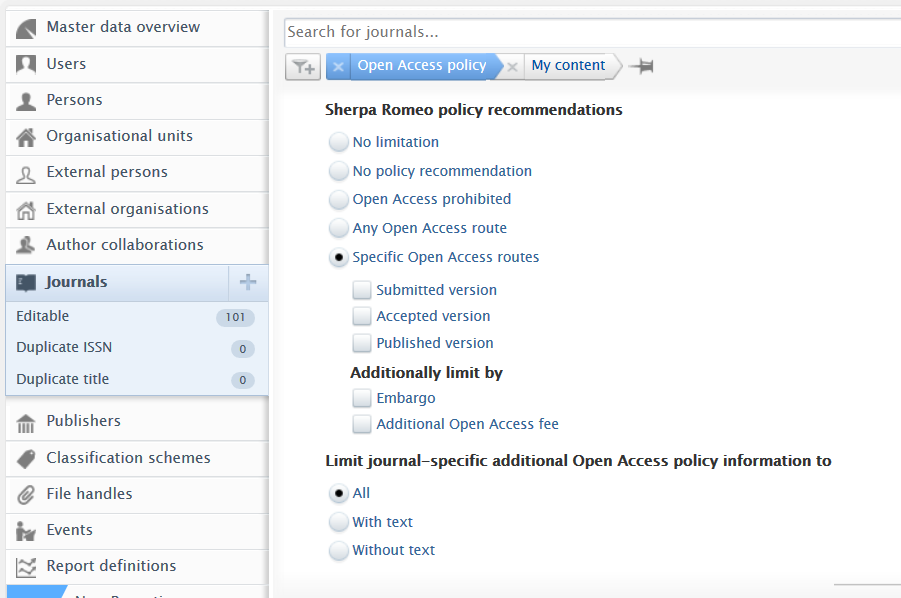 |
By default, the filter is set to No limitation, which means no specific SR filters are applied. Users can filter content by:
Note: The Limit journal-specific additional OA information filter will filter journals with or without user-provided additional OA information. This sub-filter does not directly affect SR data options. |
API updates
A major difference, besides the model changes introduced in their API, is the requirement for an API key. Sherpa Romeo now requires customers to generate their own key, which can be done by registering with SR via https://v2.sherpa.ac.uk/cgi/register.
Once you have an API key you will need to configure the SR job in Pure. The job, Sherpa Romeo Journal Synchronisation, can be found in Administrator > Jobs > Cron job scheduling:
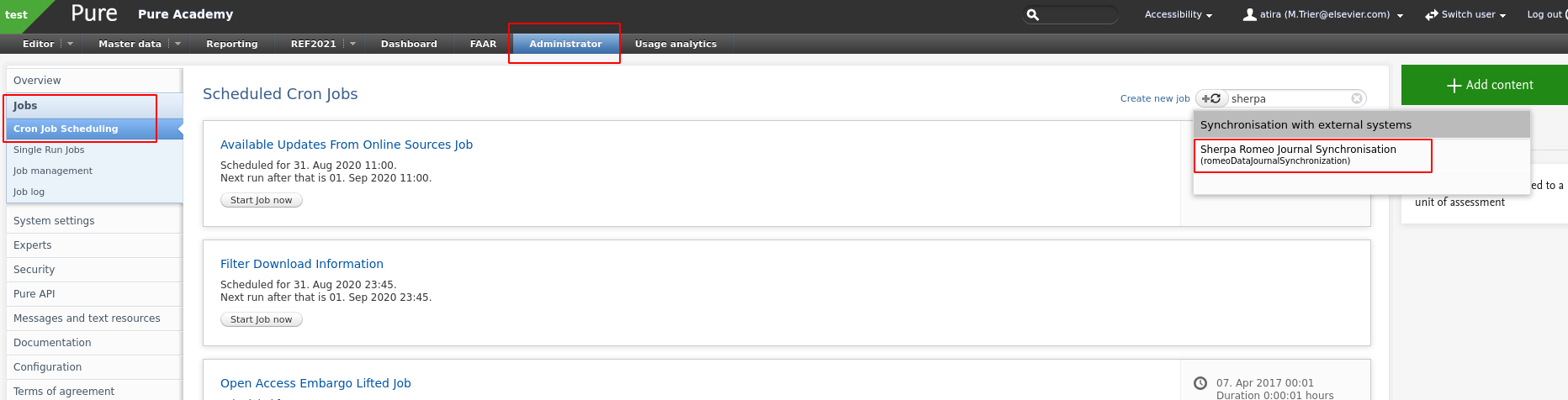
When you have found the job you will need to configure it accordingly.
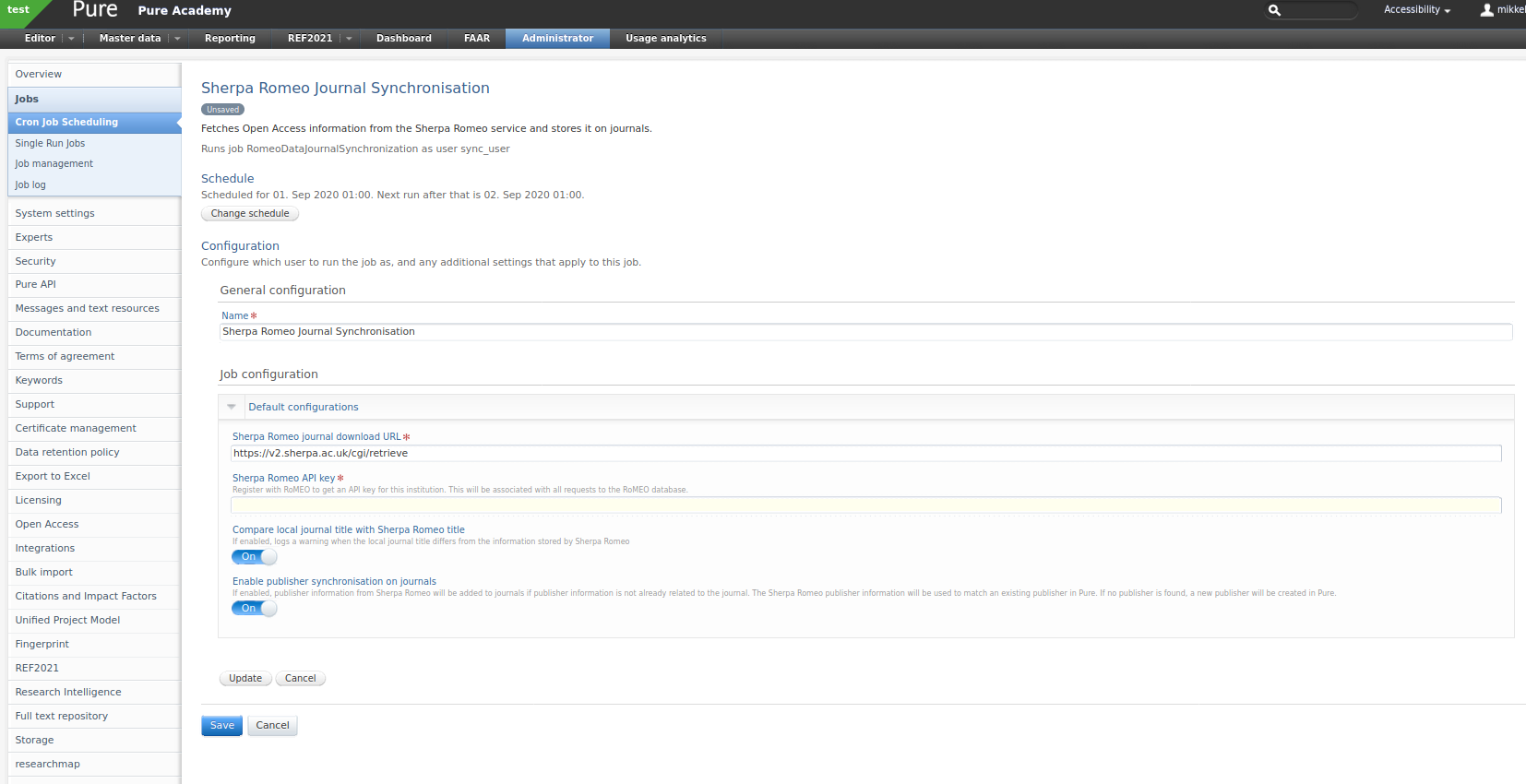
The following configuration values are available:
-
Sherpa Romeo journal download URL
- The URL used to retrieve data from Sherpa Romeo.
Sherpa Romeo API key
- Your institution's individual API key. You need to register for one (see above).
-
Compare local journal title with Sherpa Romeo title
- The job will match journals on ISSN. Enable this if you want the job to warn you when it detects a difference between the title in Pure and the one in Sherpa Romeo.
-
Enable publisher synchronisation on journals
- If enabled, publisher information from Sherpa Romeo will be added to journals if it is not already present. The Sherpa Romeo publisher information will be used to match an existing publisher in Pure. If no publisher is found, a new publisher will be created in Pure.
3.4. New Import Source: Unpaywall
Unpaywall (https://unpaywall.org/) is an Open Access database, harvesting content from more than 25,000 Gold OA journals, hybrid journals, institutional repositories, and disciplinary repositories.
The integration with Unpaywall supports researchers by expanding the range of available import data sources with an OA database indexing over 25 million publications, and providing researchers access to the best available online version of a record.
Click here for more details...
Instructions on how to enable, add and search for content from Unpaywall are shown below.
| Instructions | Screenshot |
| To enable Unpaywall as an import source, go to Administrator > Research Output > Import Sources | 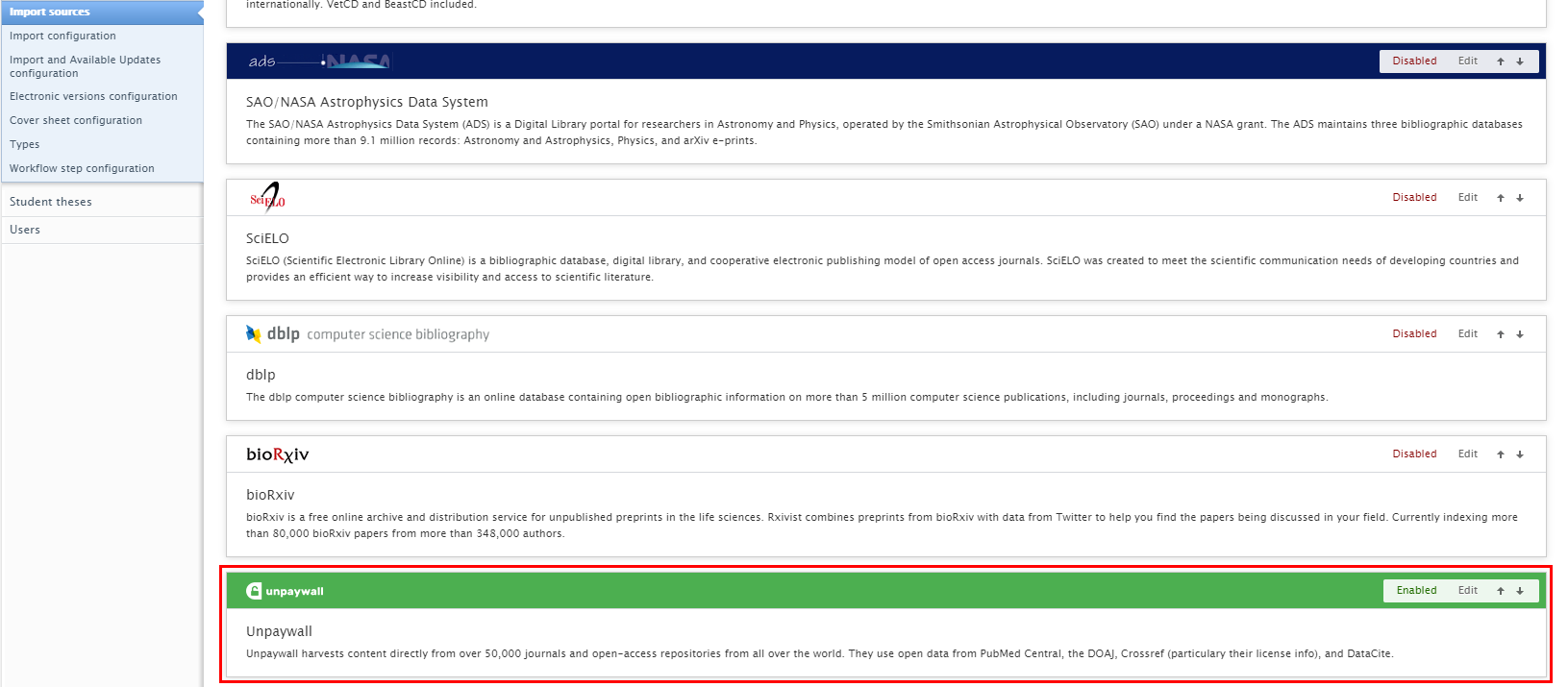 |
| To search and import content, go to ‘Add content’ and in Research Output > Import from online sources select ‘Unpaywall’. | 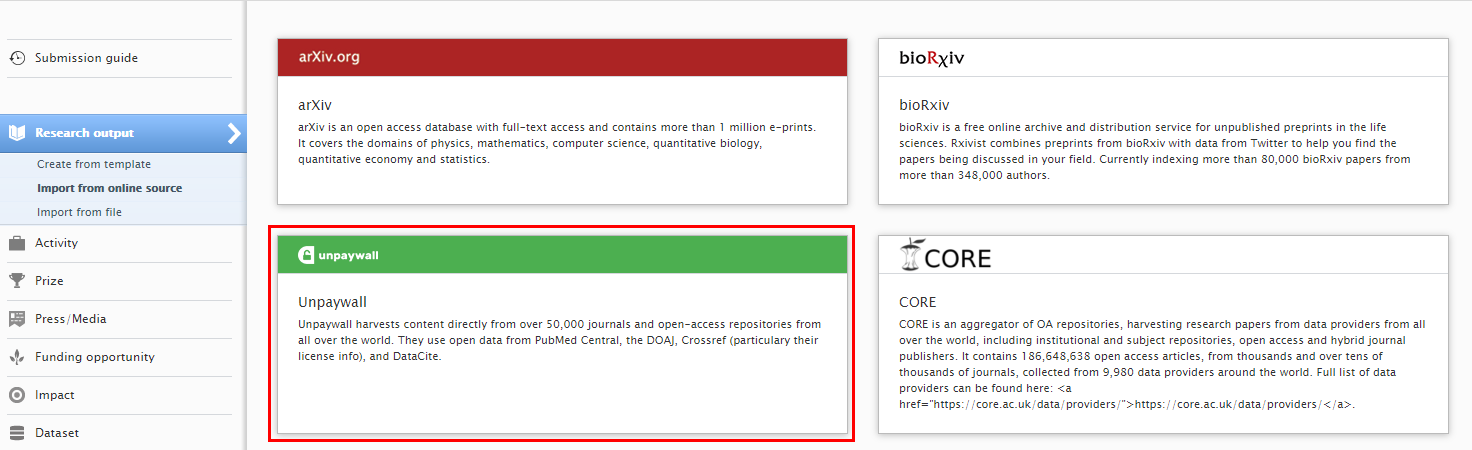 |
|
Search for content using the search bar. It is possible to search by the DOI of the Research Output. It is then possible to import or remove import candidates. |
 |
Instructions on how to add and configure Unpaywall as a source for Available Updates are shown below. For more general information on how to best configure rules for the Available updates feature, please read the Available updates section in the 5.13.0 release notes.
| Instructions | Screenshot |
| To enable automatic updates for Unpaywall, go to Administrator > Research Output > Import and Available Updates Configuration. | 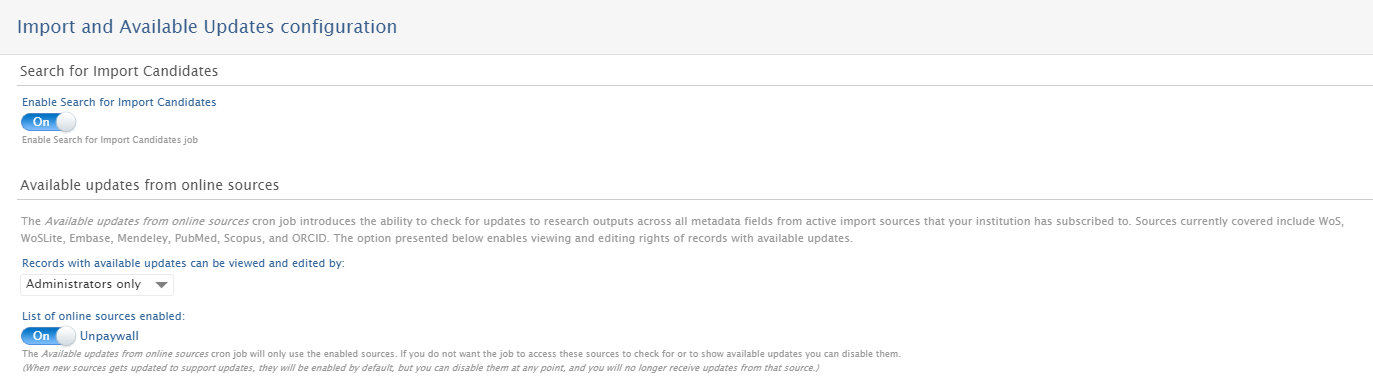 |
|
Update rules that determine how updates to specific metadata fields of a Research Output are handled, and Save configuration. Rules can be configured for Keyword Groups and URLs.
|
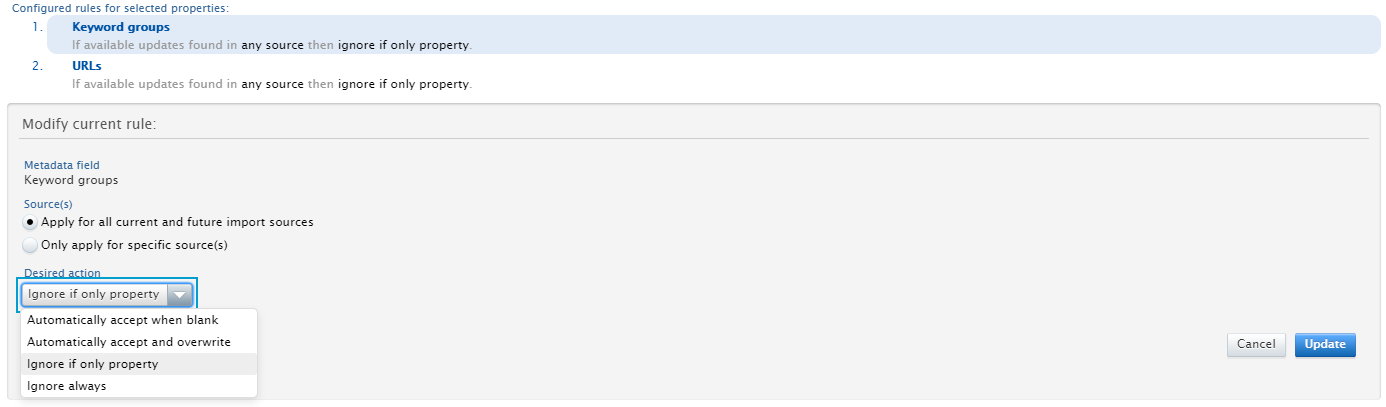 |
Note: By default, any available updates are highlighted in the Research Output Editor Window > Available Updates tab. You must manually select/merge the preferred options and save any changes.
3.5. New Import Source: CORE
CORE (https://core.ac.uk/) is an aggregator of OA repositories, harvesting research papers from data providers from all over the world, including institutional and subject repositories, Open Access and hybrid journal publishers. It contains over 186 million OA articles from tens of thousands of journals, collected from 9,980 data providers around the world. The full list of data providers can be found at CORE's provider listing. CORE will supply data for the UK REF 2021 Open Access Policy Audit to Research England, and the integration with CORE will make OA articles more easily accessible and more useful to researchers, and will allow institutions to monitor their OA output.
Click here for more details...
To enable CORE integration you will need to provide an API key, which can be requested at https://core.ac.uk/services/api/.
Instructions on how to enable, add and search for content from CORE are shown below.
| Instructions | Screenshot |
| To enable CORE as an import source, go to Administrator > Research Output > Import Sources | 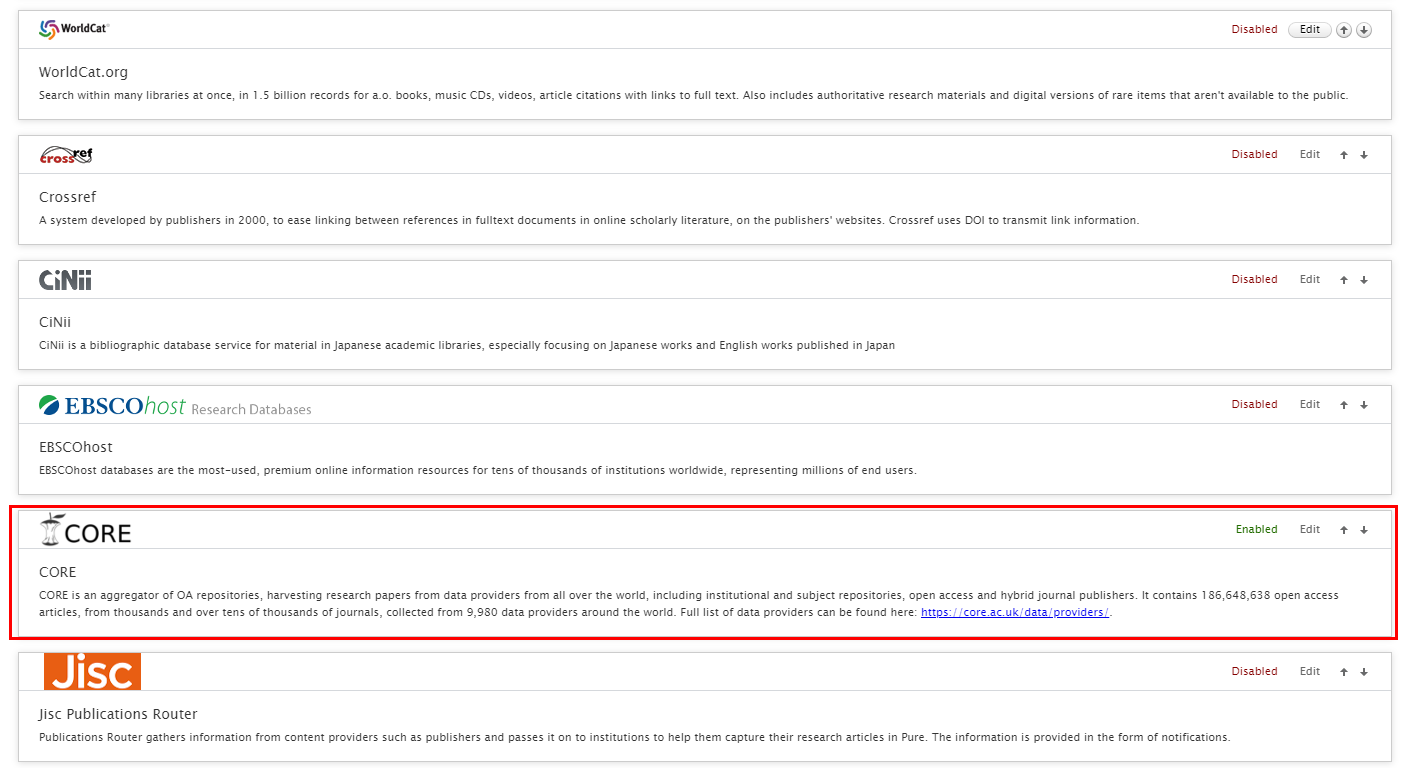 |
| To search and import content, go to ‘Add content’ and in Research Output > Import from online sources select ‘CORE’. | 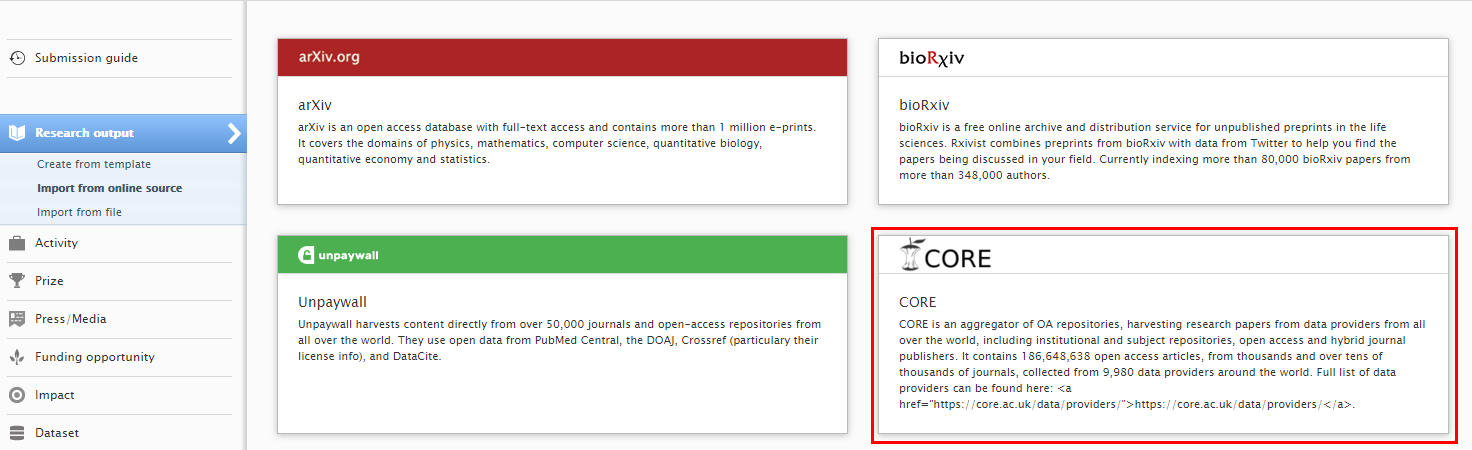 |
|
Search for content using the search bar. It is possible to search by author names, DOI and title. It is then possible to import or remove import candidates. |
 |
3.6. New Import Source: bioRxiv
bioRxiv (https://www.biorxiv.org/about-biorxiv) is a free online archive and distribution service for unpublished preprints in the life sciences, containing over 80,000 papers by more than 348,000 authors.
The integration with bioRxiv provides researchers and institutions with content in biological sciences, especially relevant when following latest COVID-related studies and results.
Click here for more details...
Instructions on how to enable, add and search for content from bioRxiv are shown below.
| Instructions | Screenshot |
| To enable bioRxiv as an import source, go to Administrator > Research Output > Import Sources | 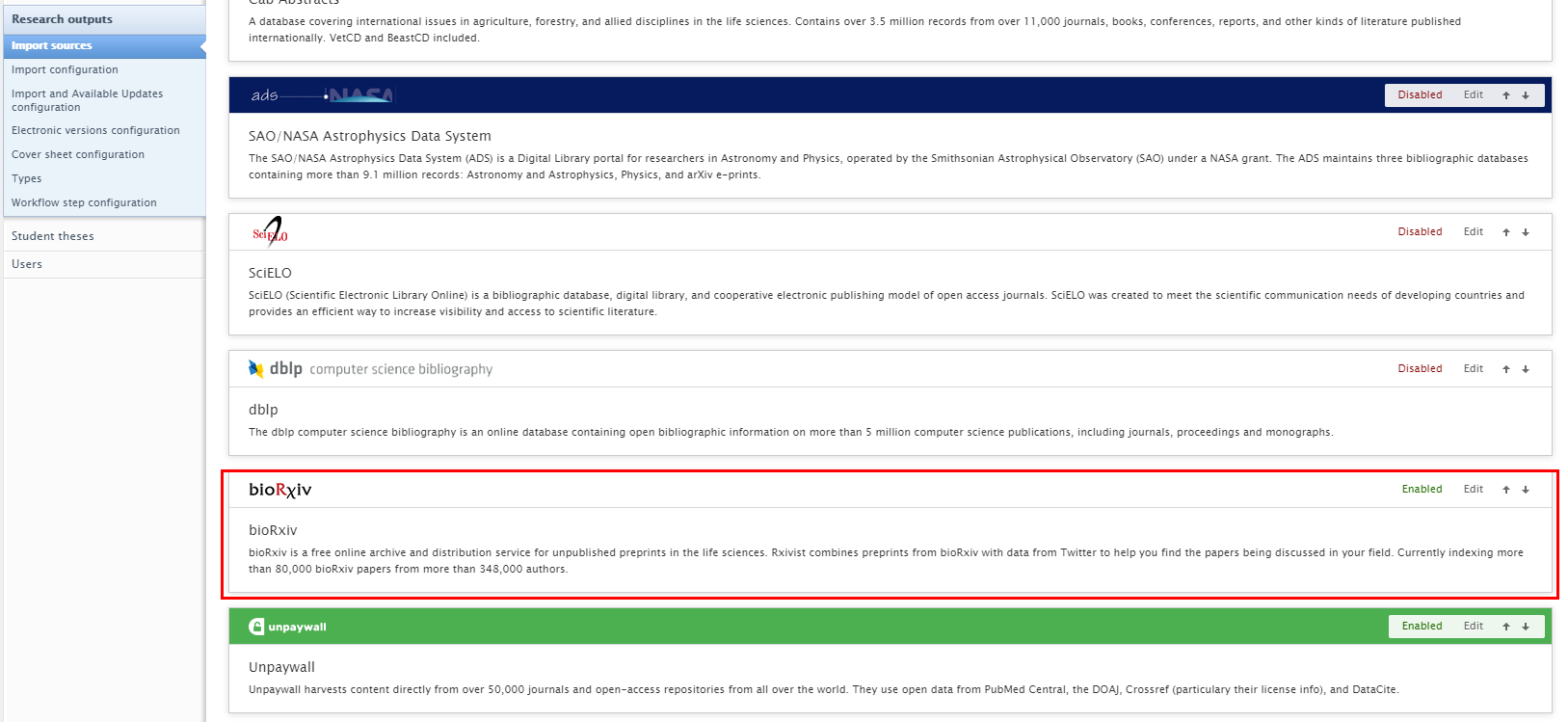 |
| To search and import content, go to ‘Add content’ and in Research Output > Import from online sources select ‘bioRxiv’. | 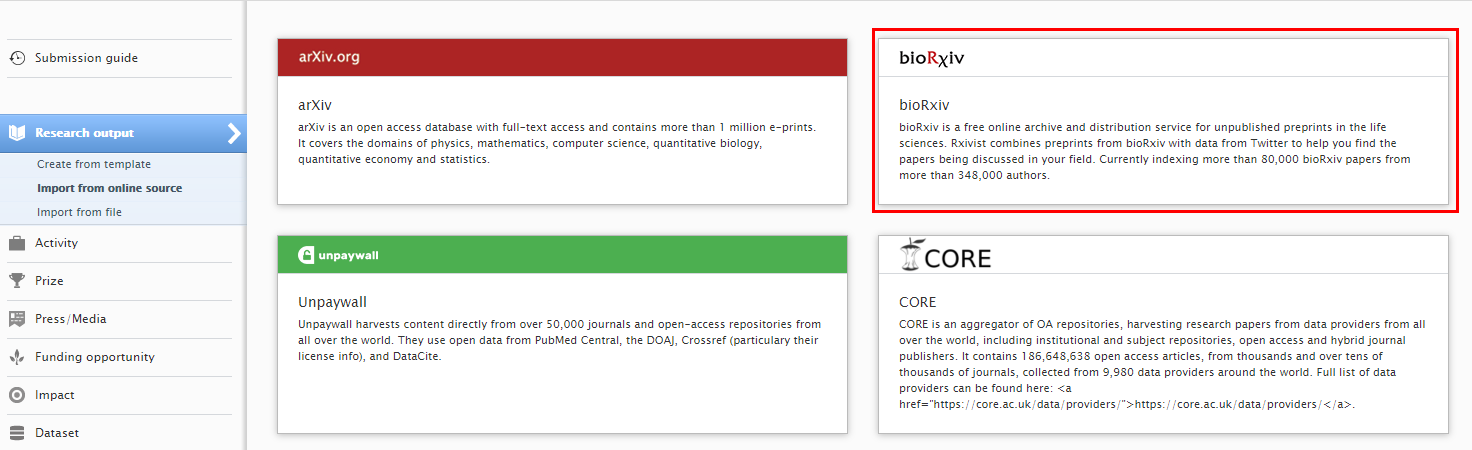 |
|
Search for content using the search bar. It is possible to search by author names, DOI and title. You can define the time frame and subject category in which you want to perform the search. It is then possible to import or remove import candidates. |
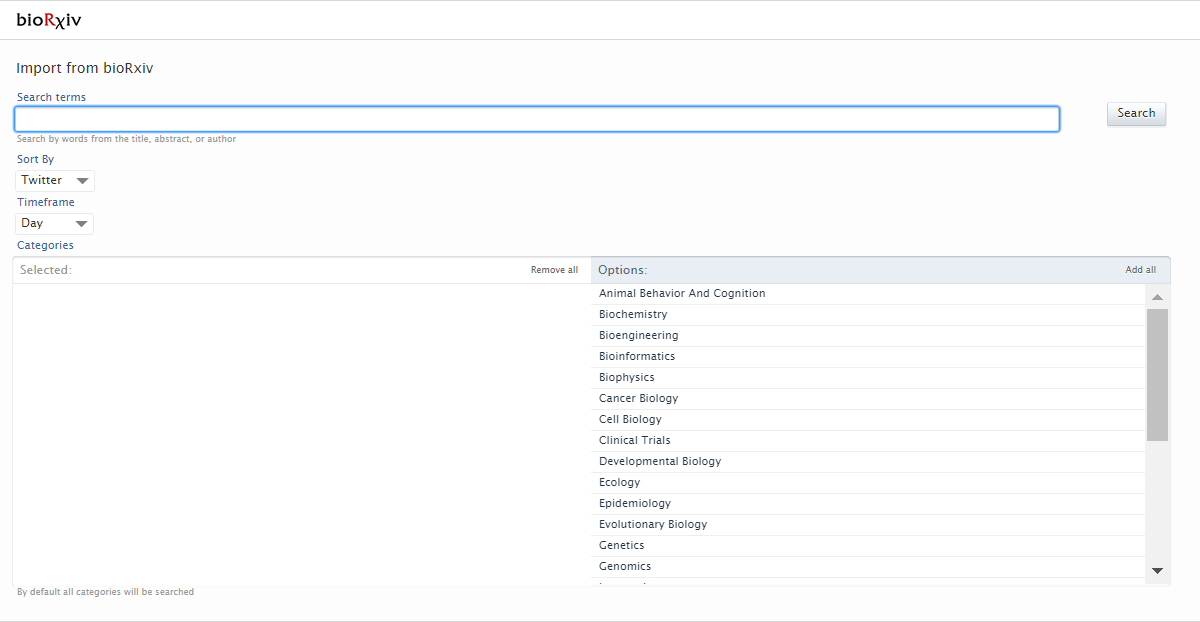 |
3.7. OA information for Scopus and CrossRef content
In this release, we have enriched the data of Research Outputs imported from Scopus and CrossRef by retrieving additional Open Access information.
Records imported from Scopus will now contain additional information on:
- Open Access status flag
Records imported from CrossRef will now contain additional information on:
- Open Access status flag
- License
Information on the Open Access status of a document is associated to the DOI, electronic version, or to a specific version (file) of the document.
4. Pure Core: Administration
4.1. Metrics
Pure customers use metrics to support research-based assessment and evaluations. As the number of metrics available to institution administrators is increasing rapidly, we are working hard to ensure that these new or newly-derived metrics are supported in Pure, and are easy to access and maintain. This release includes the following additions to the metrics suite.
4.1.1. Top percentile metrics on research outputs
Top percentile metrics are an article-level metric based on SciVal’s field-weighted version of the Outputs in Top Citation Percentiles metric. The top percentile is calculated based on the comparison of citation counts between articles within similar fields. Top percentiles are currently only available to SciVal customers.
Click here for more details...
This metric shows how citations received by a given document compare with the average for documents in the same publication year, normalized by subject area. 99th percentile is high, and indicates a document in the top 1% globally. The following criteria are used in the calculation:
- Publication year of the document + 3 years
- Compared to same document type
- Compared to same discipline
Citation benchmarking compares articles within a 36-month window. The Citation Benchmarking is only available when all three criteria are met. For more information please visit the relevant SciVal metrics section.
Enable top percentiles for research output
- Navigate to Administrator > System settings > Metrics
- Toggle Enable Scopus Percentile Measurements provider to ON.
- Save your settings.
Note: You may need to log out and back in for the settings to take effect.
The SciVal Metric Syncronization job will need to be run once the metrics are enabled.
View top percentiles
Paper percentiles and Top x% brackets can be viewed on the Metrics tab of a Research Output.

Top percentiles in Reporting
Top percentiles will soon be available in reporting.
4.1.2. Citescore metrics on Journals
We are happy to announce that with release 5.19, Pure users will be provided with new Citescore and category journal metrics from Scopus. In addition to the existing job providing journal Citescore, SNIP, and SJR, new journal and category metrics are being imported through the integration with the CAFE service.
Click here to expand...
To import Scopus journal metrics go to Admin > Cron job scheduling, and select the job Scopus: Update/Create Journals and Metrics. Once you have selected this, it is possible to schedule the frequency at which the job runs and the roles who can manage it.

The new metrics from Scopus are displayed together with other journal-related metrics in Journal > Metrics.
| Citescore metrics |
New journal-level metrics imported through CAFÉ include:
Metrics are shown per year. |
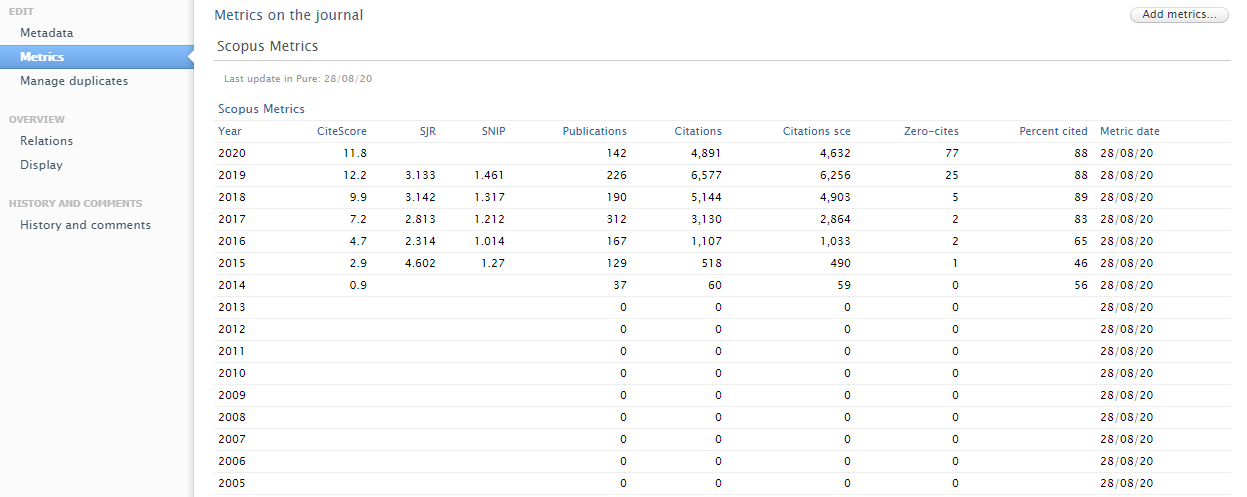 |
| Citescore category metrics |
New subject category metrics imported through CAFE include:
|
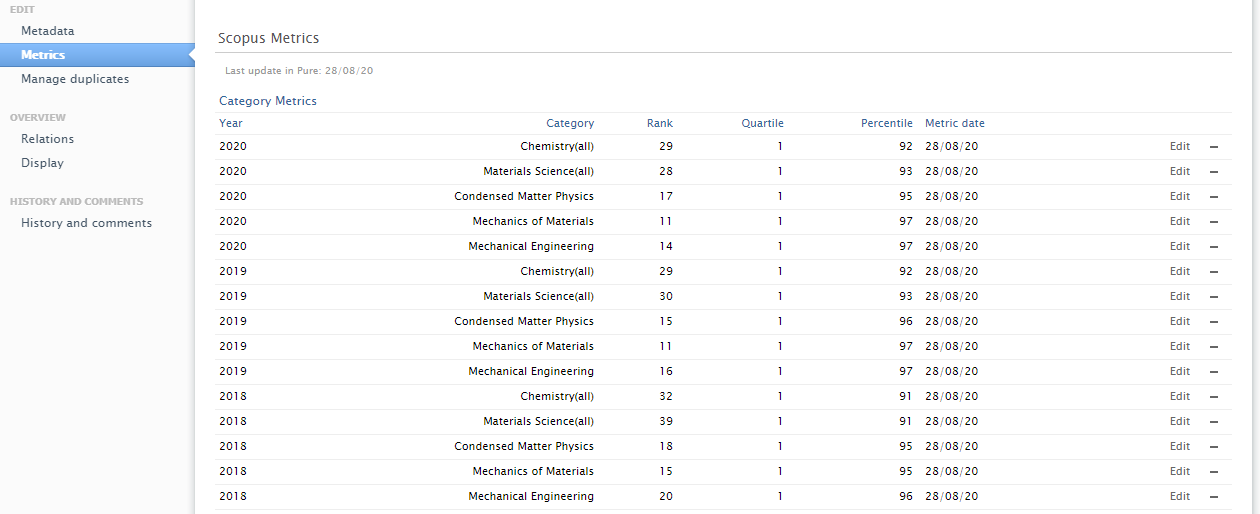 |
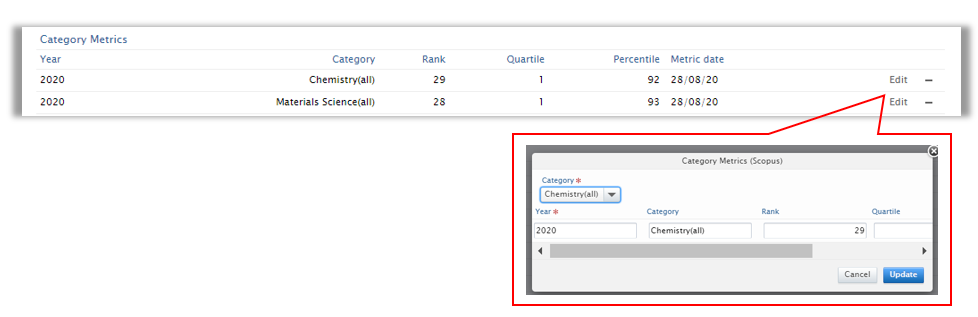
It is possible to add or edit category metrics by clicking Edit and updating the desired fields.
4.1.3. Field-Weighted Citation Impact available to all customers
We are happy to announce that the Field-Weighted Citation Impact (FWCI) is now freely available to all customers. FWCI is the ratio of the total citations received by a publication, and the total citations that would be expected based on the average of the subject field.
Click here for more details...
To enable the import of SciVal metrics for Research Output go to Administrator > System settings > Metrics, enable Enable SciVal Standard Metric, and Save.

By default, the SciVal Metrics Synchronization job runs on a daily basis. It is possible to start the job immediately by going to Administrator > Jobs > Cron job scheduling and clicking Start Job now.

The article-level FWCI will be imported to Pure even if you do not have a subscription to SciVal. FWCI can be viewed on the Metrics tab of a Research Output, as part of the SciVal Metrics section.
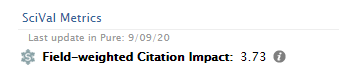
Article-level FWCI in Reporting
Article-level FWCI will soon be available in reporting. Update: Article-level FWCI available in 5.21.0. Please see 5.21.0 release notes for more details.
4.1.4. Fractional count metrics on research output
Fractional counts on Research Outputs provide a more nuanced view on contributions of individual authors to a publication. The calculation is simplified and assumes that each author contributes equally.
Click here for more details...
Enable fractional counts for Research Output
- Navigate to Administrator > System settings > Metrics.
- Enable Fractional count metrics.
- Enable Show fractional counts for all authors and/or Show internal-only fractional counts.
- Save your settings.
Note: You may need to log out and back in for the settings to take effect.
Values will be visible to all users on the Metrics tab of a Research Output. Fractional counts do not include author collaborations in calculations and are calculated only on the authors listed. With manually created or edited list of contributors, resultant fractional counts will be calculated and visible after the record has been saved.

Enabling Show fractional counts for all authors will provide equal fractions to all internal and external authors.
Enabling Show internal-only fractional counts will allocate equal fractions only to the internal authors.
View fractional counts
Fractional counts can be viewed on the Metrics tab of a Research Output.
In the screenshot below, both Show fractional counts for all authors and Show internal-only fractional counts have been enabled.

Fractional counts in Reporting
Fractional counts will will be available in reporting in 5.19.1. Pure will need to be restarted in order to have fractional counts in reporting.
4.2. New global role: Allow API access
A new global role has been added to allow user accounts with no linked persons/affiliations to access the web service (WS). Users with this specific role will be able to use the WS via basic authentication in the API call but will require additional roles in order to access the Pure content backend.
This feature will be available in 5.19.1
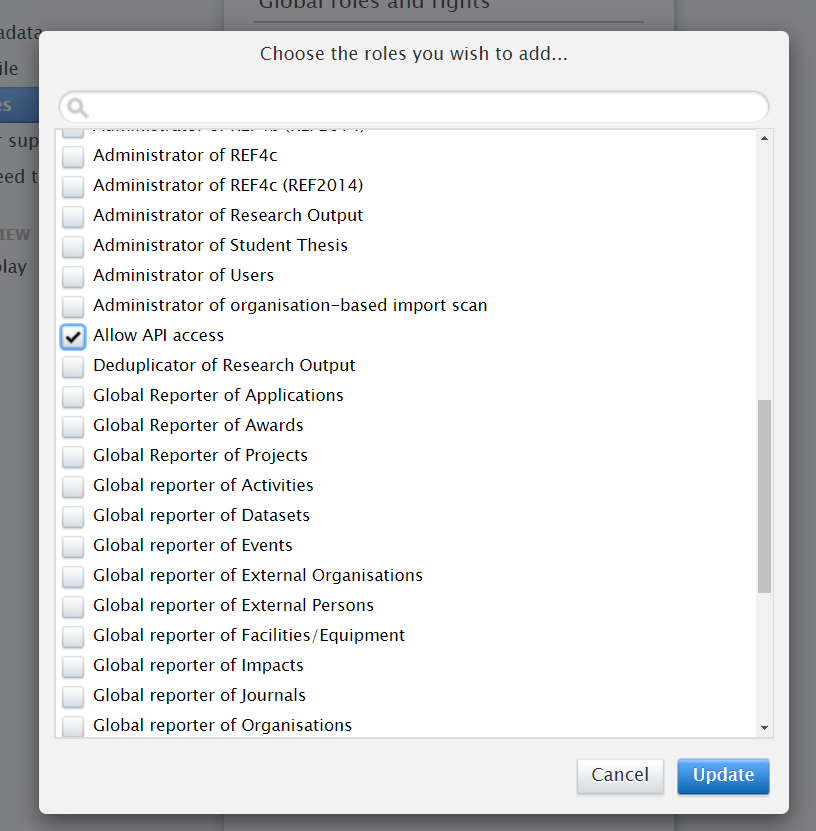
Click here for more details...
In 5.17, Pure updated the Person Maintenance job to ensure that users with no roles (i.e. were persons no longer affiliated with an institution) had limited access to Pure. This adversely affected some customers who required specific users, with no roles, to access the WS. The new global role, Allow API access, allows these users to continue accessing the WS.
4.3. Community Module
The Community Module helps effectively manage multi-institutional research projects, providing a shared reporting engine and a multi-institution portal that makes it easy to collate and aggregate the data, showcase the research assets and understand the contributions of each institution. As data is gathered from
several underlying Pure instances, a lot of effort has gone into improving data quality and transparency in this release.
In the following sections, the term Institution refers to a single Pure instance that is part of a Community. Community refers to the aggregating Pure instance running the Community Module with two or more Institutions.
Note: Some of the changes made in this release require a Pure Harvester upgrade. Pure Harvester is a service that makes data from the participating Pure Institutions available to the Community. Over time, we will migrate every Community to the new Harvester, but you can also reach out to us if you want to be migrated earlier. To be eligible for migration to the new Pure Harvester, all Pure instances in a Community must be upgraded to Pure 5.19.0 or higher.
4.3.1. Data retention improvements
Pure's rich data model allows for multiple dependencies between content types to unlock the research potential of an institution. When data from several Pure instances is combined in a Community, the network of relations becomes even more complex. This allows the Community to gain valuable insights, and showcase connections and collaborations.
However, removing pieces of such a complex dependency graph can be challenging. In previous versions of the Community Module, the content removed by one of the Institutions was not always removed from the Community. Instead, its visibility was set to 'Backend' to prevent it from showing on the Community Portal.
In 5.19, we have introduced support for a number of known scenarios, and we will also closely monitor the removal of data to ensure that the Community instance is always up-to-date.
Note: Some of the data retention improvements will only work with the new version of the Pure Harvester (see above).
Click here for more details...
Here are some scenarios supported by our deletion strategy:
- Content is only available in one Institution of the Community, and it is removed from that Institution:it will be removed from the Community
- Content has been merged in the Community and is removed from one of the Institutions: It will not be removed from the Community until it is removed from all Institutions
-
An internal person/organization is removed from an Institution:its type will be changed to external.
If some related content type does not support external entities, the reference will be removed.
If the reference is mandatory (e.g. managing organisation), the content will be deleted from the Community.
Note: It is already not possible to create content if a mandatory reference (e.g. managing organisation) is not visible to the Community.
Note: It may not be possible to clean up content that was not completely deleted (but only set to 'Backend' visibility) prior to 5.19.
4.3.2. Deduplication of new content types
Until now, automatic deduplication was only supported for Journals and Research Outputs. In this release, we expand the list with the following content types: Person, Event, Publisher, External Organization and External Person.
The deduplication jobs are available regardless of whether the Pure Harvester has been upgraded, but are automatically scheduled only with the new Pure Harvester.
Click here for more details...
Potential duplicates are identified in two steps:
- Candidate location: potential duplicates are located in the database using specific search criteria.
- Duplicate validation: potential duplicates are checked against a set of rules (different for every content type).
The table below specifies the criteria for deduplication for all supported content types.
Note: Deduplication is currently only possible for selected content types. All other content types are handled as unique records by default.
| content type | location: search criteria | validation: found candidates must match on | ||||
|---|---|---|---|---|---|---|
| Research output* | secondary sources, DOI, ISBNs, journals ISSNs, the aggregated title, publication year, authors, and pages | source/source ID combination* |
if not found, then | DOI* | if not found, then | title and subtitle* |
| Journal | ISSN | at least one title | ||||
| Publisher | publisher name | name | ||||
| Event | event title | title | if found, then also | city, country | if found, then also | period |
| Person* | Scopus ID, ORCID | at least one first name, one last name |
||||
| External Person | all names | full first/last name combination | ||||
| External Organization | name | name | if found, then also | type | if found, then also | country, subdivision(e.g. state), city and address |
*Research output: Title and subtitle with an high similarity score.
*Person: The more recent person, based on employment dates and whether each person has active employments, is used as the target of the merge.
4.3.3. Better visibility of data origin
With 5.19, content origin information is easy to see as it is included in the short render format used in content listings and search. For some content types, information about content origin is also available in the editor.
Note: This upgrade is only available when switching to the new Pure Harvester (see above).
Click here for more details...
| Information | Screenshot |
|
The following content types now have origin information in the short render:
Example: The red box contains the name of the Institution where the data originated from. If the content has been merged, it will be the name the primary contributor. |
|
|
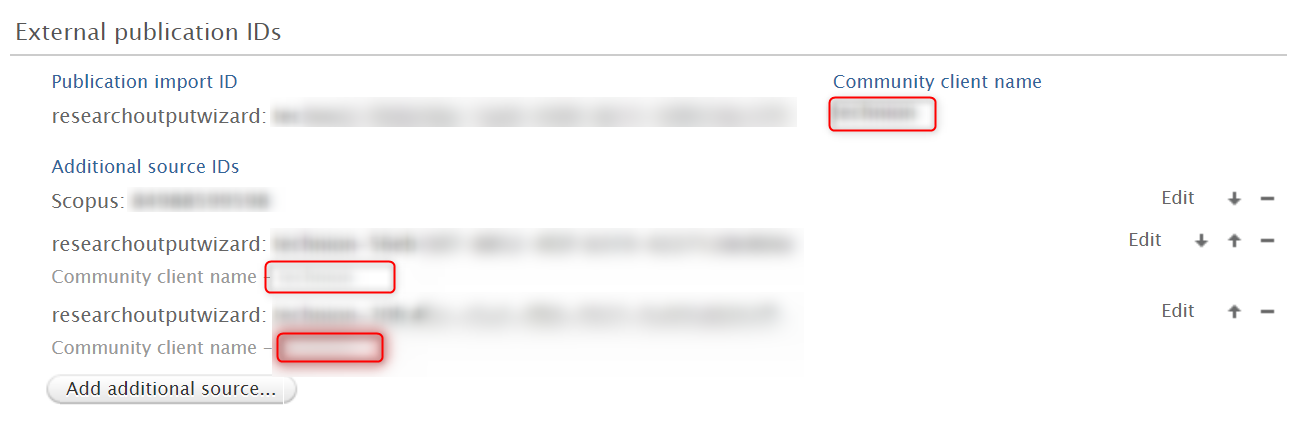
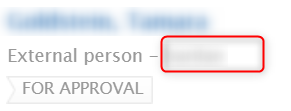
For Persons, Organisations and Research outputs this information is also visible in the editor. If content has been merged, you can see what Institution it originates from. This information includes source ID, with which you can either access the original content (if permitted), or reach out to the Institution that owns it to report data quality issues, or make other data-related queries. Example: The red box in the 'Publication import ID' section contains the primary ID. The red boxes in the 'Additional source IDs' section contain the secondary IDs. Contributor rank can be changed by switching the order of Institution IDs. As this is a manual task, it needs to be done with extreme caution so as not to corrupt the data. |
 |


5. Pure Core: Web services
5.1. Support for Journal, Publisher, and Event in Pure API
The early access Pure API now supports the management of Journal, Publisher, and Event in addition to Internal and External Organizations. As part of the implementation of the thee new models, we reviewed the previously released models, which has led to the following breaking changes in the API in version 5.19.0
Breaking change:
- Organization and External Organization field family has been renamed to systemName to reflect the meaning of the field.
- KeywordGroupConfiguration field targetFamily have been renamed to targetSystemName.
Click here for more details...
The Pure API is an evolution of the existing REST Web Services to support a backwards-compatible read and write REST JSON endpoint for using and managing research information data in Pure.
In order to achieve these objectives, we have made several changes to how the Web Service endpoints are structured and to the format of the managed entities in the new API.
- The endpoints for an entity are structured so that it is clear where you can expect REST or RPC semantics. This should make it easy for developers to interact with the API with a minimal upfront time investment.
- The entity format is optimized in regard to JSON data modelling best practices and with an expectation of the model evolving in a backwards-compatible manner in the future.
- The API specification is defined and published as an OpenAPI 3 specification enabling service users to quickly generate a client while at the same time providing developers with useful documentation on the API and its semantics.
- The entity API includes several helper operations that return the allowed values for the different parts of the entity model where this is relevant - this should make it easy for developers to submit valid changes to the write portions of the API.
- All modification requests are made on behalf of a specified Pure user and clearly audit logged with both user and API key details.
- As we expect the API to be able to support older clients updating against a newer version of the API all PUT requests have JSON merge patch semantics - this ensures that older clients do not inadvertently clear new properties that they do not know about.
When the module has been successfully enabled, a Swagger UI representation of the OpenAPI 3 specification will be available at https://{your Pure hostname}/ws/api/api-docs/index.html?url=/ws/api/openapi.yaml. The latest API on the development community sandbox server can be found in this Swagger UI. A sample Java client that can be used as a starting point for developing a client can be found on the GitHub page.
| Information | Screenshot |
|
The early access Pure API can be enabled in the Pure administrator section. Please note that enabling or disabling the Pure API module requires a restart of Pure in order to take effect. |
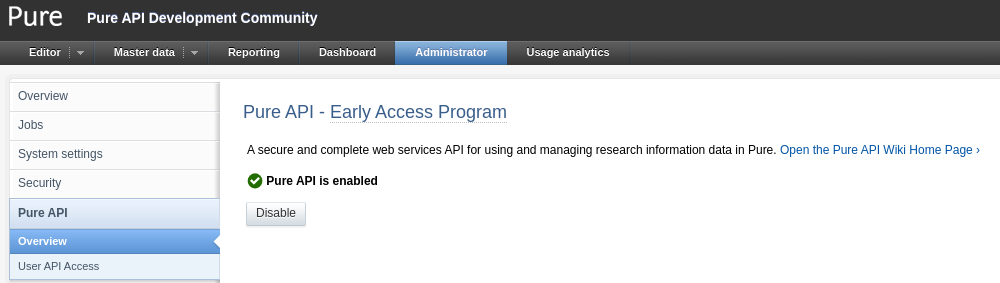 |
All use of the new endpoints requires an API key that is generated in Administrator>Pure API>User API Access.
In contrast to the current Web Service API keys, the new Pure API requires a user that the system using the API key acts on their behalf.
5.2. OAI-PMH improvements: Ability to configure exposure of internal keywords
We have improved our OAI-PMH integration by adding new configurations. It is now possible to configure the visibility of individual keyword groups in the Web Service and OAI, and to select whether a keyword is exposed in the WS and in OAI.
Click here for more details...
In 5.19, Keyword Group Configurations will have a new toggle: Show in WS.
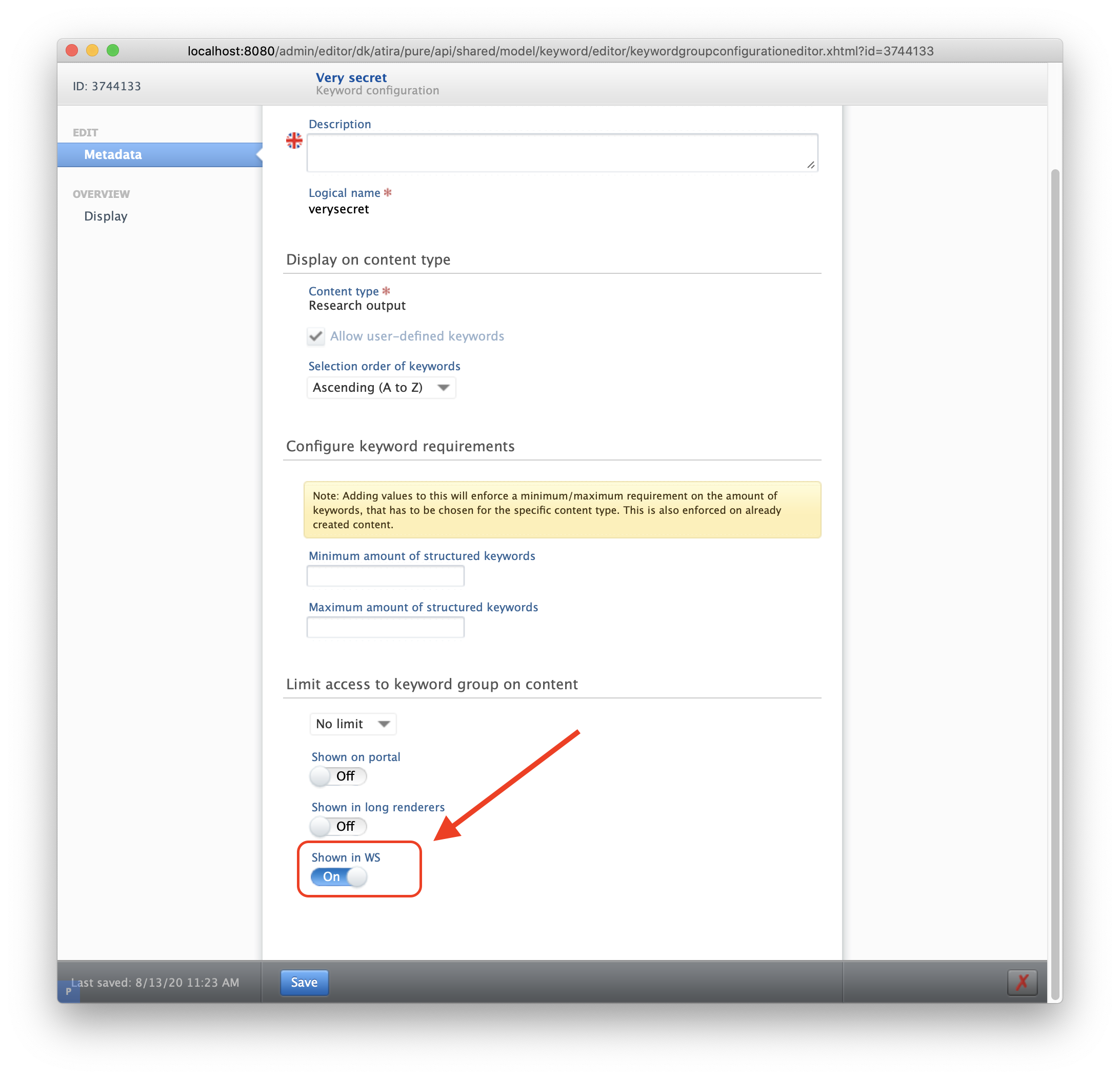
The toggle is enabled by default, which means that keywords will be visible in the Web Service and OAI.
This toggle can be switched to OFF if a keyword contains internal information that should not be exposed through the WS. 'Hidden' keywords will remain visible to administrator API keys, which are able to bypass this configuration.
5.3. Person Expertise added to Web Service
In this release, we have added the option to expose information on a Person's area of expertise through the Web Service. In order to make use of this functionality the Person Expertise module must be enabled.
Click here for more details...
An example of how the Person's Expertise is displayed on a personal profile is shown below:
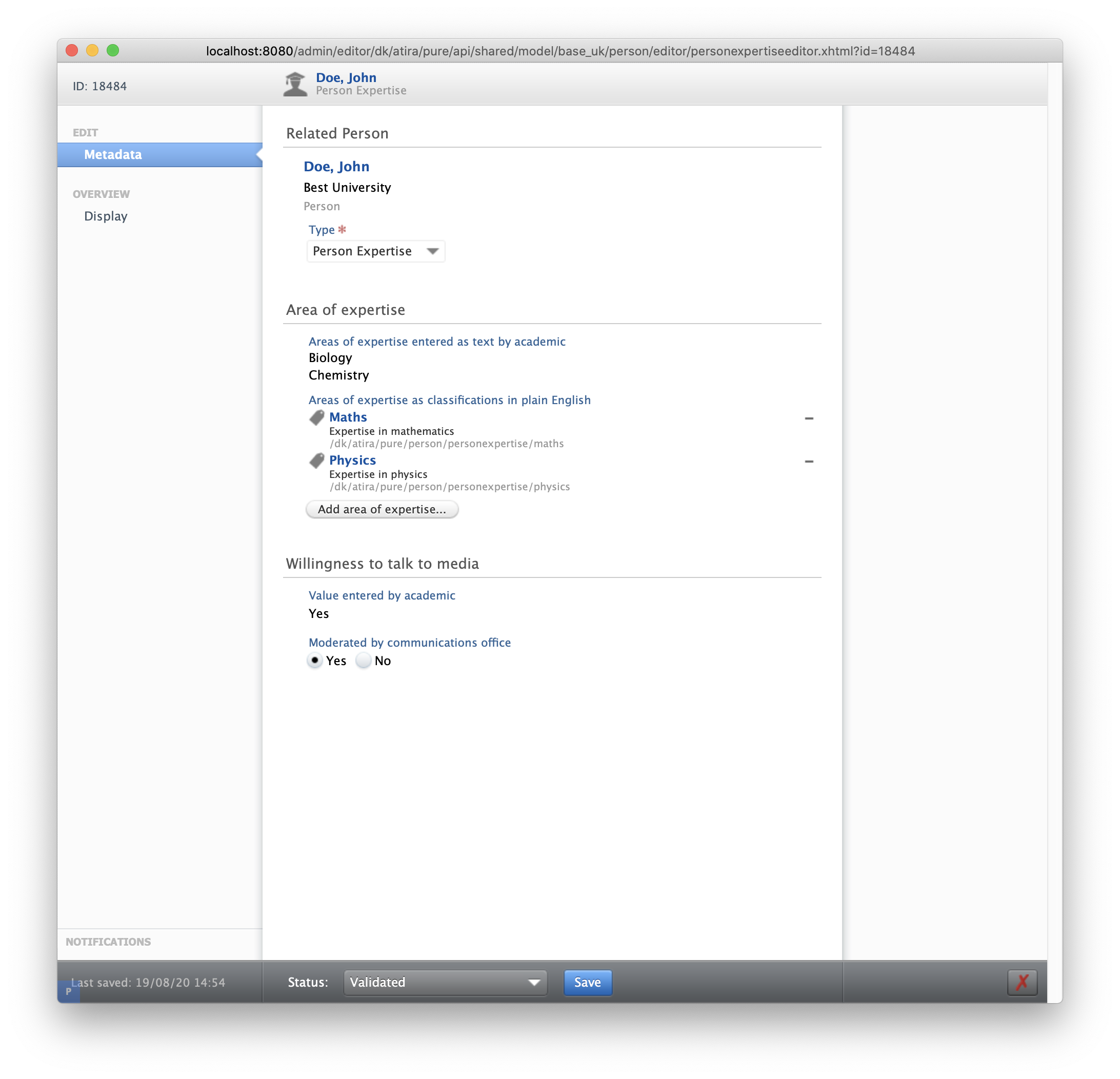
An (XML) example of how these areas of expertise are exposed through the Web Service is shown below:
<person pureId="18472" uuid="65c28253-a8a5-4a07-815e-d0378e811bad">
[...] <personExpertise pureId="18484">
<areasOfExpertise> <areaOfExpertise>Biology</areaOfExpertise> <areaOfExpertise>Chemistry</areaOfExpertise></areasOfExpertise> <areaOfExpertiseClassifications> <areaOfExpertiseClassification pureId="18478" uri="/dk/atira/pure/person/personexpertise/maths">
<term formatted="false">
<text locale="en_GB">Maths</text>
</term> </areaOfExpertiseClassification> <areaOfExpertiseClassification pureId="18480" uri="/dk/atira/pure/person/personexpertise/physics">
<term formatted="false">
<text locale="en_GB">Physics</text>
</term> </areaOfExpertiseClassification> </areaOfExpertiseClassifications> <willingnessToMedia>true</willingnessToMedia> <moderatedWillingnessToMedia>true</moderatedWillingnessToMedia> <type pureId="2361" uri="/dk/atira/pure/personexpertise/personexpertisetypes/personexpertise/personexpertise">
<term formatted="false">
<text locale="en_GB">Person Expertise</text>
</term> </type> </personExpertise> [...]</person> |
5.4. Funding value changed to string
Until now, currency values related to funding of awards were not human-readable after they reached a certain threshold.
In this release, the element types of the values have been changed to strings in order to improve value visibility. This means the value 3.45e8 will now be rendered as 345000000.
Click here for more details...
Example:
<awardedAmount>1E7</awardedAmount> <institutionalPart>1E7</institutionalPart>
becomes:
<awardedAmount>10000000.00</awardedAmount> <institutionalPart>10000000.00</institutionalPart>
The changes are:
ComplexType wsAward:
ComplexContent: Extension: Sequence: Element totalAwardedAmount: The type of element 'totalAwardedAmount' changed from xs:double to xs:string. Element totalSpendAmount: The type of element 'totalSpendAmount' changed from xs:double to xs:string. ComplexType wsAwardFundingAssociation: ComplexContent: Extension: Sequence: Element estimatedValue: The type of element 'estimatedValue' changed from xs:double to xs:string. Element awardedAmountInAwardedCurrency: The type of element 'awardedAmountInAwardedCurrency' changed from xs:double to xs:string. Element awardedAmount: The type of element 'awardedAmount' changed from xs:double to xs:string. Element institutionalPart: The type of element 'institutionalPart' changed from xs:double to xs:string. Element institutionalContribution: The type of element 'institutionalContribution' changed from xs:double to xs:string. Element institutionalFEC: The type of element 'institutionalFEC' changed from xs:double to xs:string.
6. Integrations
6.1. Enriched information for Scopus content
In this release we have enriched the data of Research Output imported from Scopus by retrieving information for two additional metadata fields.
Click here for more details...
Records imported from Scopus will now contain additional information on:
- Open Access status flag
- Acknowledgements to Funder
Information on the Open Access status of a document is associated to the DOI, electronic version, or to a specific version (file) of the document.
The text containing acknowledgements to the funder(s) is included in the bibliographical notes.
6.2. Data Monitor: Configuration Added to Switch Between Synchronization / Import mode
We have improved the integration with Data Monitor by making it possible for Pure users to edit the metadata of imported datasets. A new configuration has been added to the Data Monitor configuration page, giving users the option to run Data Monitor as a synchronization or import candidates manually.
Click here for more details...
Once the integration has been enabled in Administrator > Datasets > Data Monitor, you can select the preferred import mode by disabling Data Monitor Synchronization (by default, the integration runs as a synchronization).
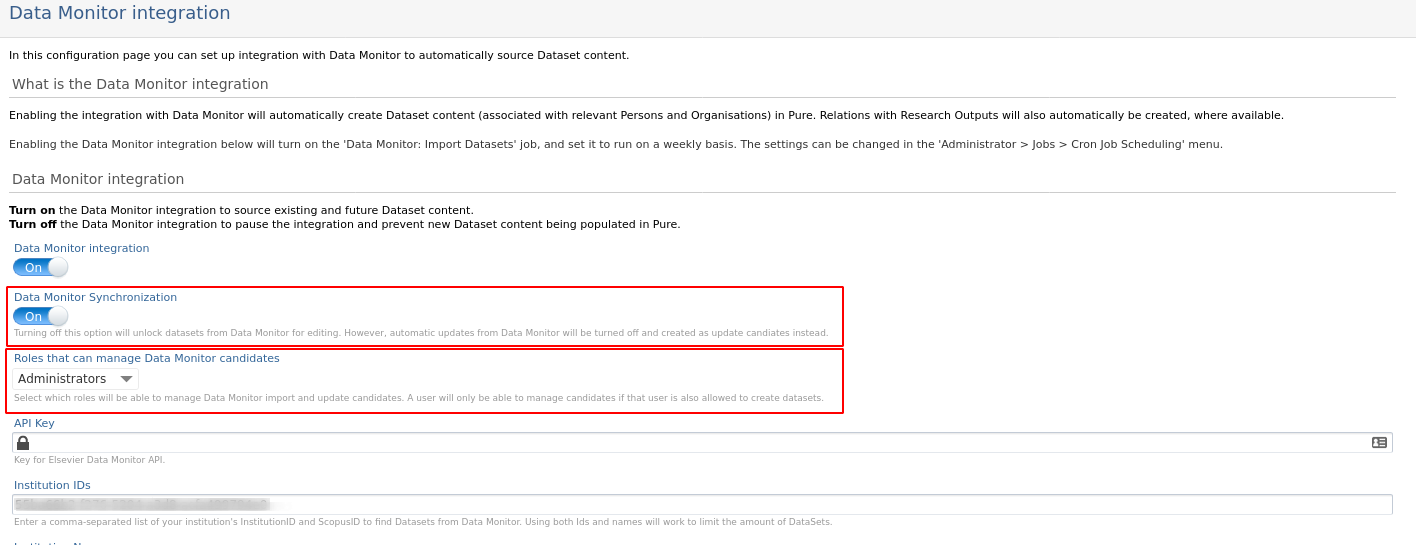
If Data Monitor Synchronization is disabled, imported datasets are presented as import candidates and it is possible to edit their metadata. It is possible to select which roles are able to manage import and update candidates. Note: in order to manage candidates, a user must have permission to create datasets.
With this configuration, existing datasets will no longer be automatically updated but will be presented as update candidates. The Automatic Import Criteria present on the Data Monitor configuration page can only be used if the integration is run in synchronization mode.
6.3. Improved matching on Scopus IDs for publications
We have improved the 'Match Scopus IDs For Publications' job so that false or incorrect matches will no longer be created. With this improvement, incorrect Scopus IDs will no longer be assigned to publications.
Click here for more details...
The Turn on strict matching configuration, that previously had to manually be turned on, has been made the default configuration. In this configuration, the title of a publication is matched when both the publication in Pure and that in Scopus have the same ISSN and DOI.
In addition, we have improved our algorithm to optimize the matching on the title of existing content in Pure.
If you still experience incorrect matches, please submit a support ticket so that we can review these cases and further improve matching on research output in Pure.
6.4. SciVal Partner API
In release 5.19 we have revisited the existing Scival integrations in Pure and switched to SciVal's new API, as the current API will be deprecated.
Other than a change in endpoints, this has no implications for existing integrations. Functionality will remain the same. The affected integrations are the following:
- SciVal External Organisation Synchronisation
- SciVal Scopus Author ID Import
- SciVal Metrics Synchronisation
- Export organisations to Scival
More information on the new API can be found at SciVal's partner API description.
6.5. CVN Import from FECyT
In release 5.19, Spanish customers can import their Research Output directly from their CVN. In order to import content from CVN, the FECyT module must be enabled (see release note 5.17 for details).
Click here for more details...
To import your Research Output into Pure, go to Research Output > Import from file and select import from FECyT.đ
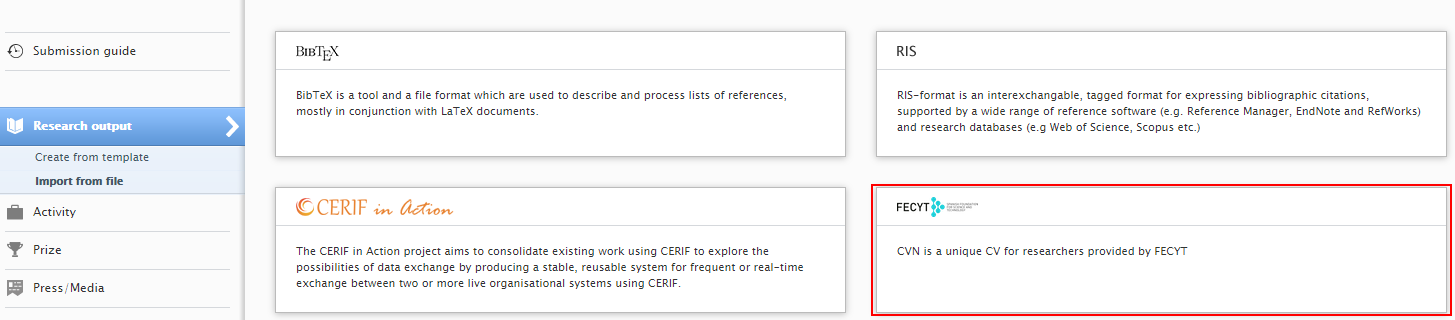
It is then possible to upload you CVN (in PDF format) to import Research Output included in your CV.
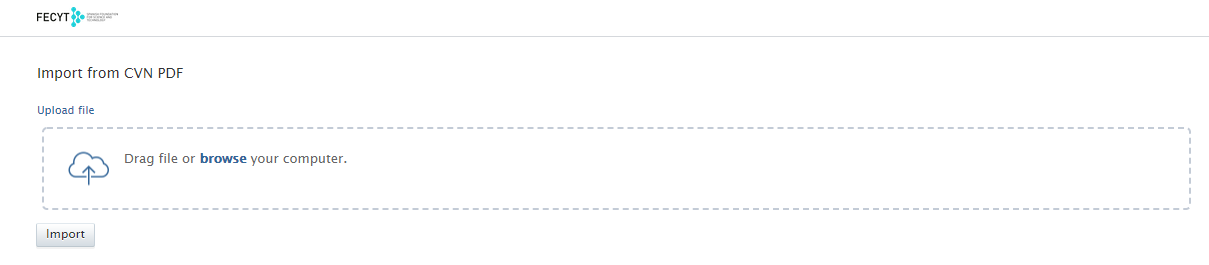
Records are presented as import candidates, and it is possible to preview, import, or reject candidates.

If an import candidate is rejected, it will be removed from the list. If an import candidate already exists in Pure, it will be presented as a duplicate.
6.6. Publications bulk import: author collaboration & group author
In this release, the field groupAuthor has been replaced by the field authorCollaboration, as the groupAuthor field is being deprecated.
Although the new field authorCollaboration should be used going forward, groupAuthor will still be supported for some time.
If both fields are present, the field authorCollaboration will be used and a warning will be displayed in the job log.
6.7. Master List: Export with or without former Organisations and Persons
A new configuration has been added to the Master List data import, making it possible to select whether to export your current master list with or without former Organisations and Persons.
To make use of the Master List to export your data from Pure, a Master List needs to have been previously uploaded in Pure. The new configuration can be found in Administrator > Bulk Import > Masterlist.
Note: the Master List data import is only available for customers with the Author Profile module.
7. Pure Portal
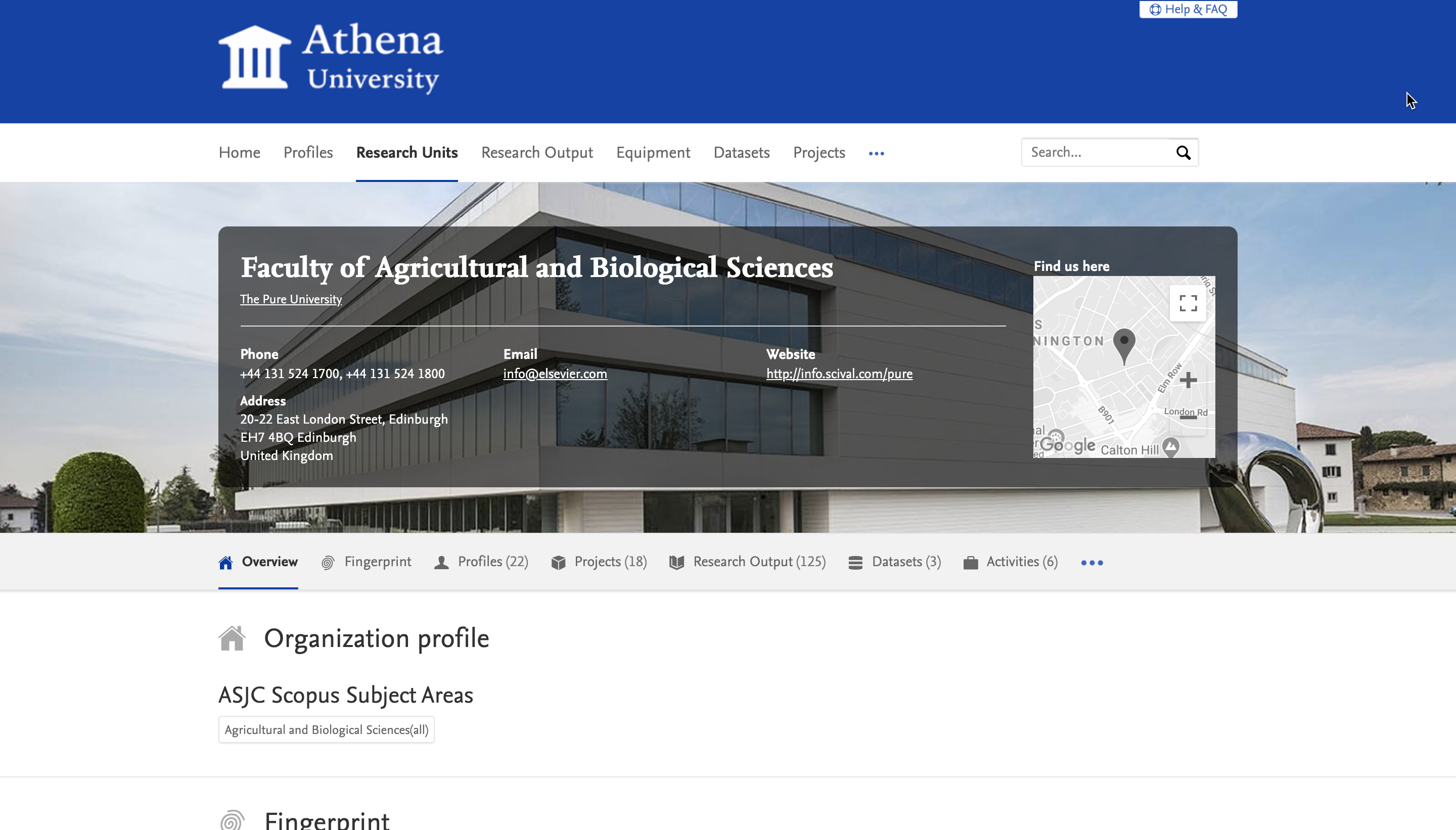
7.1. Hero images on Research Unit (Organisation) pages
In the previous major release (5.18), we introduced large hero images on Portal homepages. With this release, we have enabled hero images on Research Unit (Organisation) pages to help you better showcase organisations within your institution.
Click here for more details...
Adding a hero image
Adding a hero image to an organisation in Pure is easy.
First, find the Organisation Unit you want to add an image for in Master Data and open the editor.
Next, find the 'Photo' section and select 'Add file...'. Upload your chosen image, select Hero image from the dropdown, click Create, the save the record.
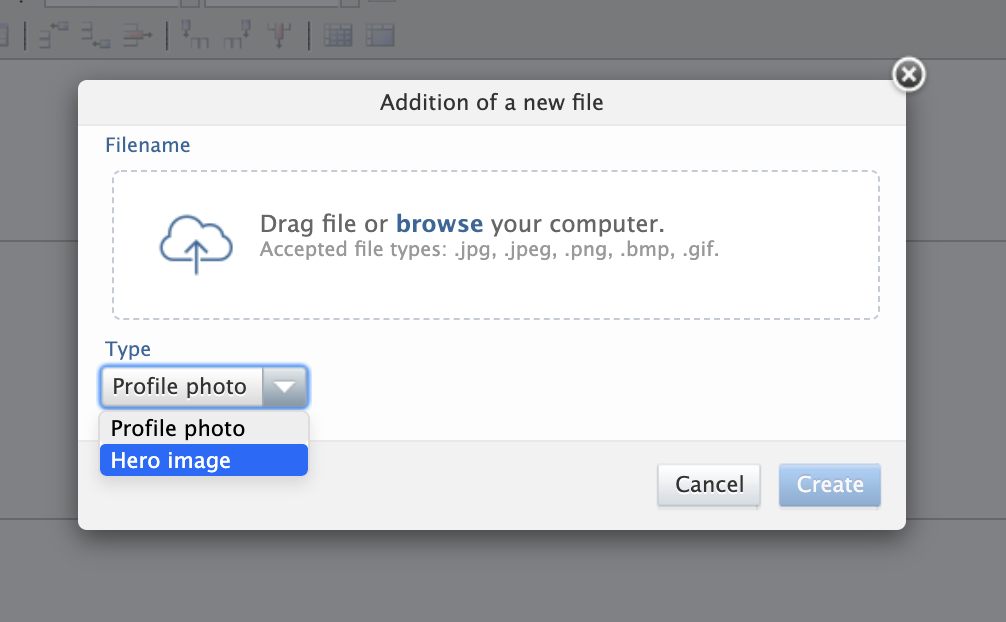
Since the hero image has a fixed height of 300 pixels, we advise a size of 300 (height) by 1920 (width) pixels. The image layout is designed to be responsive, so you will notice the dimensions will shift somewhat according to the size of the screen available.
Note: Large files could add noticeably to the page load time.
Additional changes on the Organisation Unit page
We made a few extra styling changes to the look of the Organisation Unit pages on the Pure Portal. When a hero image is present, the title card for the organisation will be shown in a semi-transparent box overlaying the image. As before, the box includes the Google maps view if a location address is provided for the organisation. We changed the map view to use grayscale instead of colour so that it does not draw the attention away from the hero image.
7.2. Embedded media on Research Output and Research Unit pages: Youtube and Vimeo video players
We have taken our first steps towards supporting video content on the Pure Portal. To begin with, you can embed media content on Research Output and Research Units. YouTube and Vimeo are currently the two supported media platforms. We will be rolling out this functionality to cover other Portal pages types and other media platforms over the course of future releases.
Click here for more details...
Getting the URL - YouTube
To embed a video hosted on YouTube, find the video on YouTube.com. From that page you can use one of these options:
- Copy the browser URL.
- Right click the video, and select "Copy video URL".
- Use the "Share"-button and click "Copy" in the dialog being opened.
Getting the URL - Vimeo
To embed a video hosted on YouTube, find the video on Vimeo.com. From that page you can use one of these options:
- Copy the browser URL.
- Click the "Share" button (or icon), and then click the link on the dialog to copy the address.
Adding media content to Pure
Once you have the URL, embedding a video in either a Research Unit or Research Output is very simple.
Just open the record you want to add the video to, paste the video link in the Web address (URL) field, add an (optional) description, select 'Portals multimedia' from the dropdown menu, and click Save.
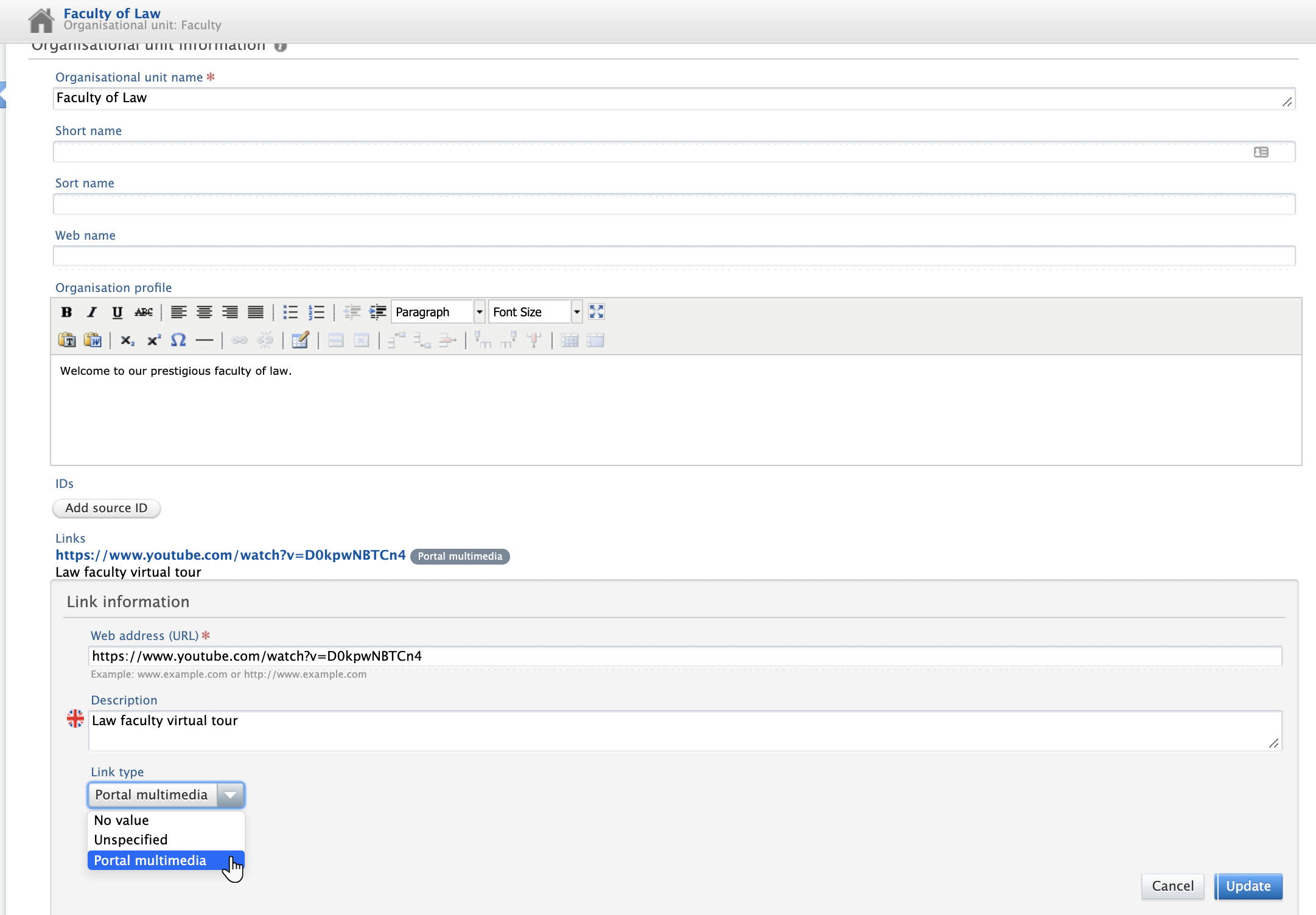
The content should then publish to the Portal within a few seconds.
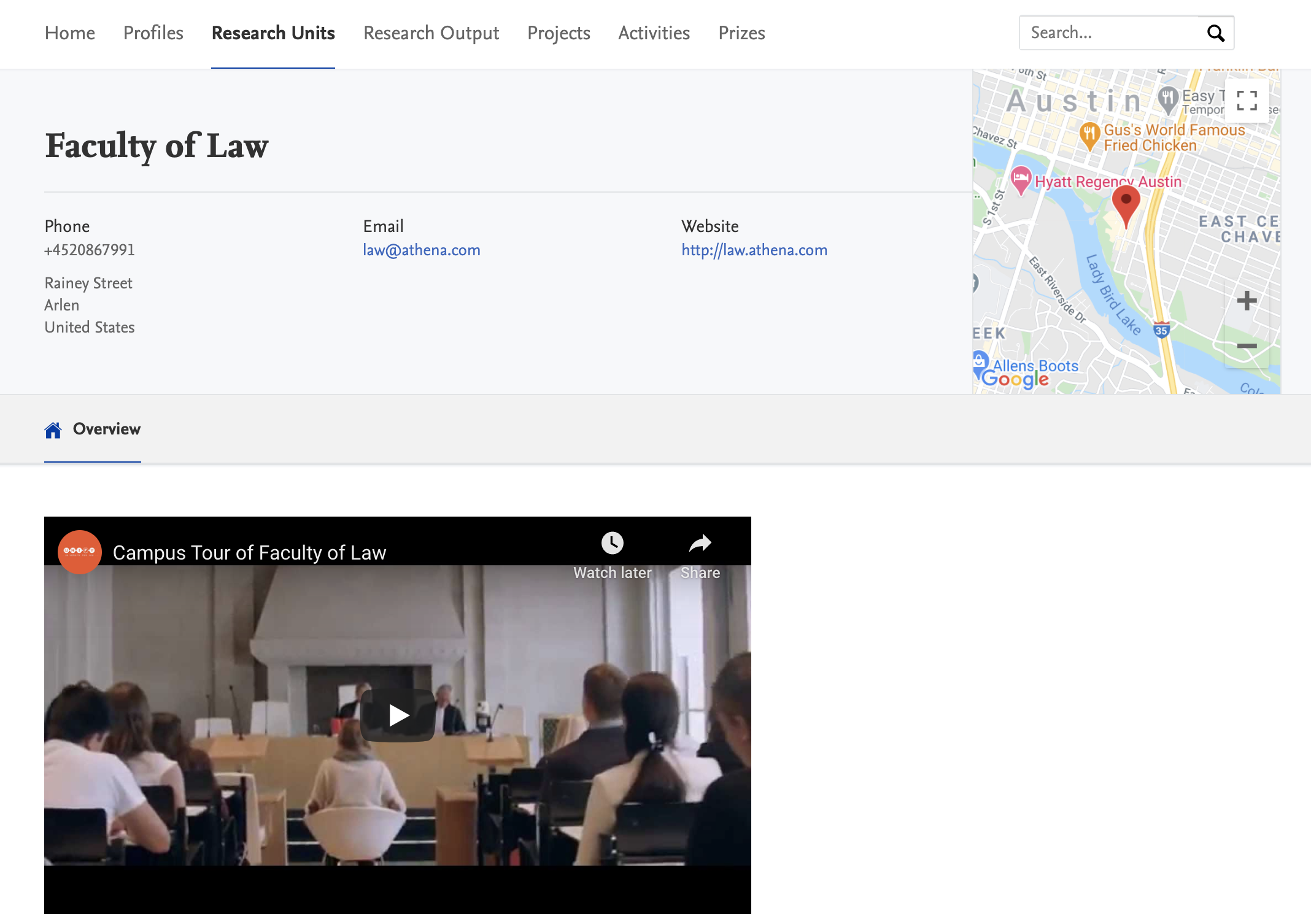
Note on URL shorteners
Shortened URLs are not supported by the embedded media feature on the Pure Portal. If you need to include a video where the URL has been shortened, please access the link in your browser, and then use the Share functionality on the video platform site to get the full-length link.
7.3. Graph of Relations no longer uses Flash Player (Custom Portal only)
Due to the impending discontinuation of support for Adobe's Flash Player, the Flash-powered Graph of Relations feature on all remaining Custom Portals has been updated to instead use a combination of HTML5 and Javascript. The functionality remains unchanged. There are no other Portal elements still using Flash Player.
7.4. Adding Internet Content Provider (ICP) license numbers for Pure and the Pure Portal (only for Pure clients hosted in Mainland China)
In order to comply with local regulations, we have added two new sets of fields to Pure for our clients hosted in Mainland China to add their governmental website registration numbers (Commercial ICP number and ICP Beian License).
Click here for more details...
Adding a Commercial ICP number and/or ICP Beian License number for Pure
To add an Internet Content Provider (ICP) number for your installation of Pure, go to Administrator>System Settings>ICP License Information
On this page, there is a separate field for each entry. Provide the relevant registration number(s), and click Save.
Your registration number(s) will now be shown in the footer of your Pure:

Adding a Commercial ICP number and/or ICP Beian License number for the Pure Portal
To add your license number(s) for the Pure Portal, go to Administrator>Pure Portal>Styling and Layout >ICP license information (Mainland China hosted clients only).
Provide the relevant registration numbers and click Save.
Your registration number(s) will now be shown in the footer of your Pure Portal:
8. Reporting module
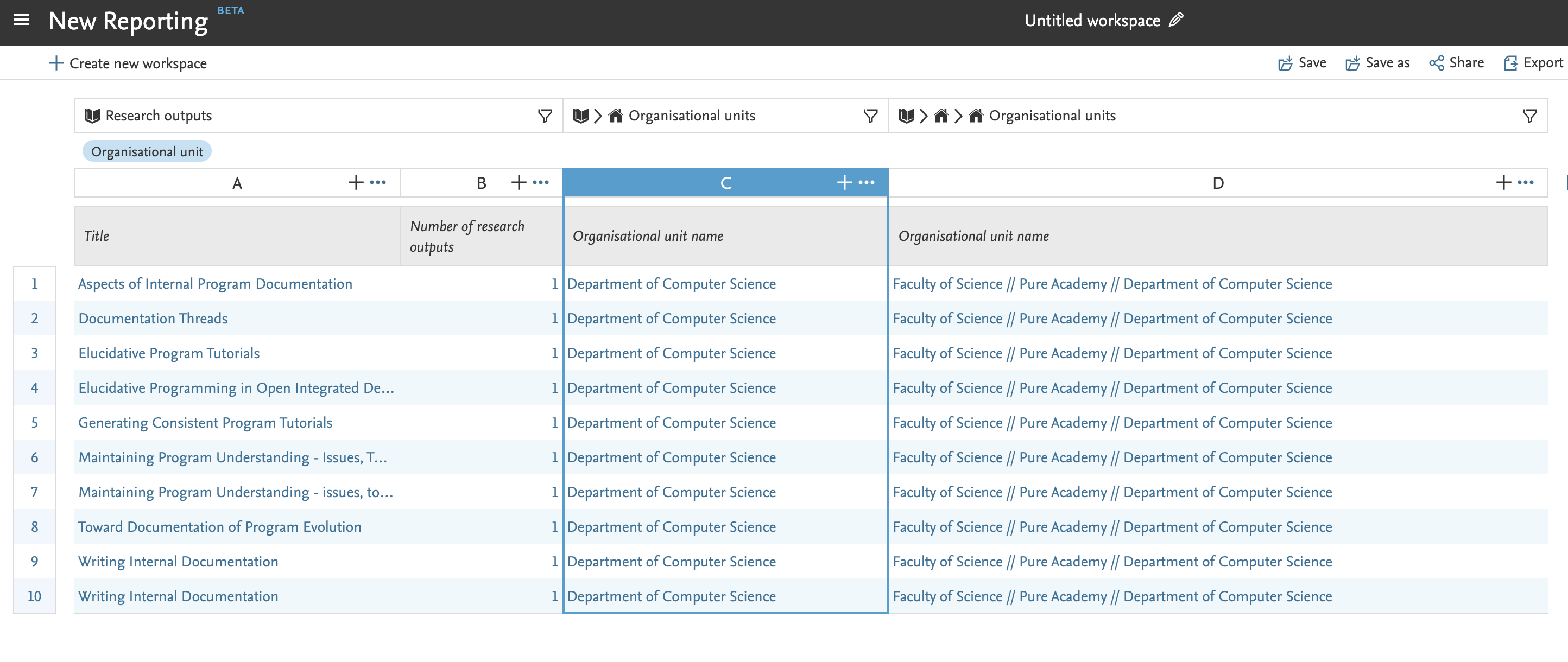
8.1. Reporting on organisational hierarchy
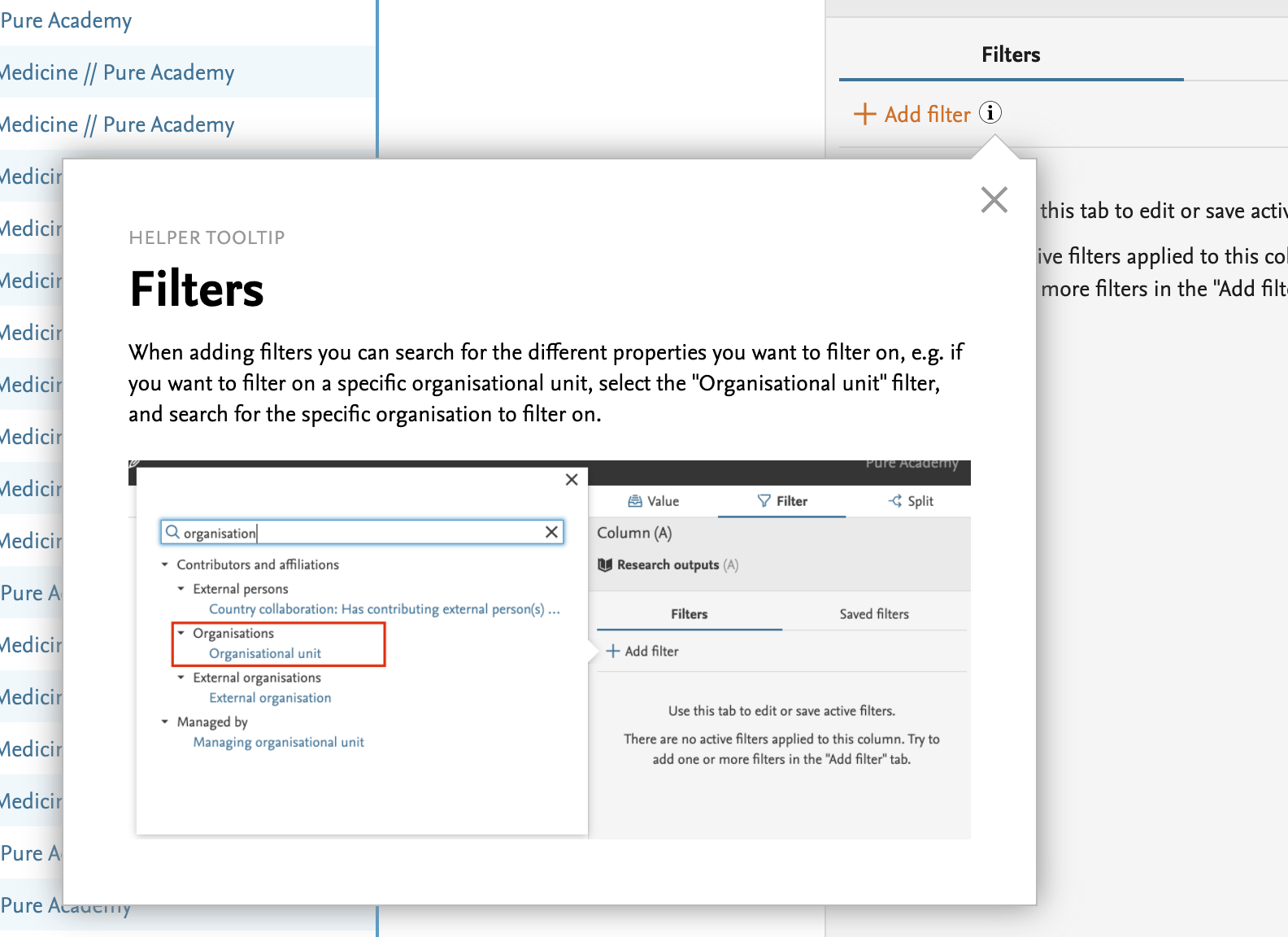
Pure 5.19.0 comes with a brand new feature: reporting on the hierarchy of an organisation. This means that you are now able to report not only on a single organisational unit, but also on the organisational hierarchy above or below.
You now can:
- do a roll-up of information in a hierarchy
- drill down into a hierarchy
- summarise on each level of a hierarchy
Similarly, when filtering, you can now choose to filter on the selected organisational unit itself, or on the entire organisational hierarchy below.
You can access this feature where you normally choose your organisational values and filters in a report.
Click here for more details...
8.1.1. Relations
We have added a new set of values for reporting relations on organisation. This makes it possible to include various parts of the organisational hierarchy in your report.
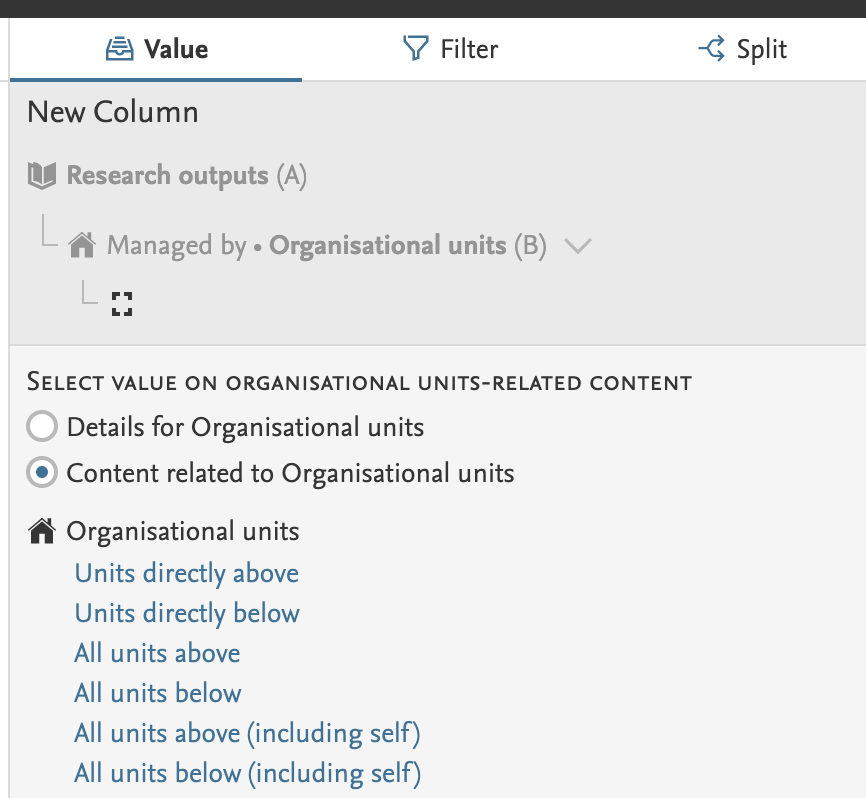
- Units directly above - only show the organisations that are placed directly above the current unit
- Units directly below - only show the organisations that are placed directly below the current unit
- All units above - show all organisations that are placed above the current unit in the organisational hierarchy
- All units below - show all organisations that are placed below the current unit in the organisational hierarchy
- All units above (including self) - show the current unit and all organisations that placed above it in the organisational hierarchy
- All units below (including self) - show the current unit and all organisations that below it in the organisational hierarchy
Example: Choosing All units above will give you a list of organisational units placed above the current unit.
8.1.2. Filtering
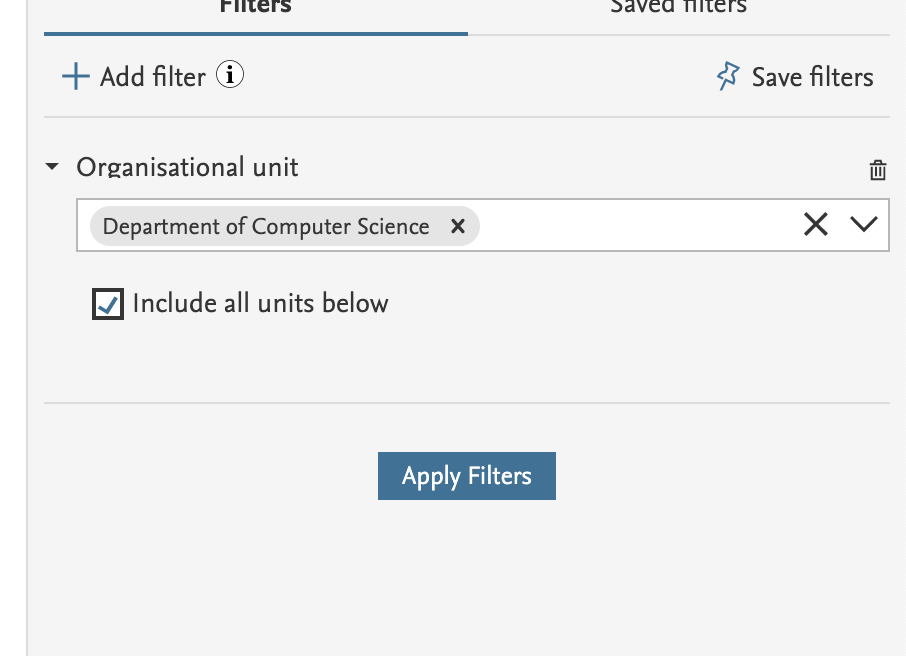
We have introduced the possibility to limit content to a subset that belongs to selected organisational units and all units below. This enables you to quickly find all content, for example, Research Outputs, that belongs to a certain part of the organisational hierarchy.
8.2. Reporting on metrics
As part of improving what can be reported on in the new Reporting Module, we have updated reporting on Journal metrics for this release. We have added the options to report on CiteScore metrics and Journal Impact Factor metrics.
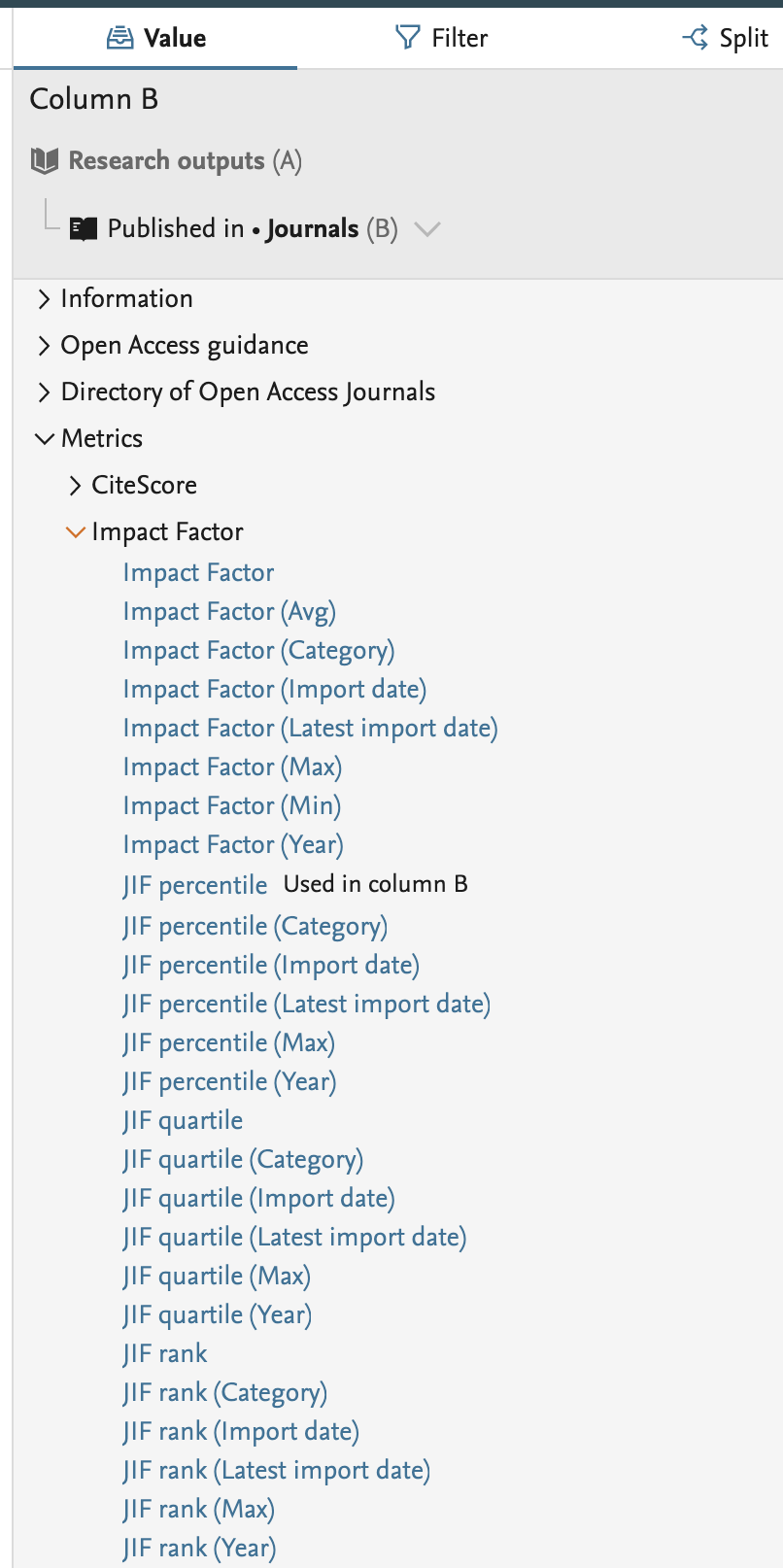 |
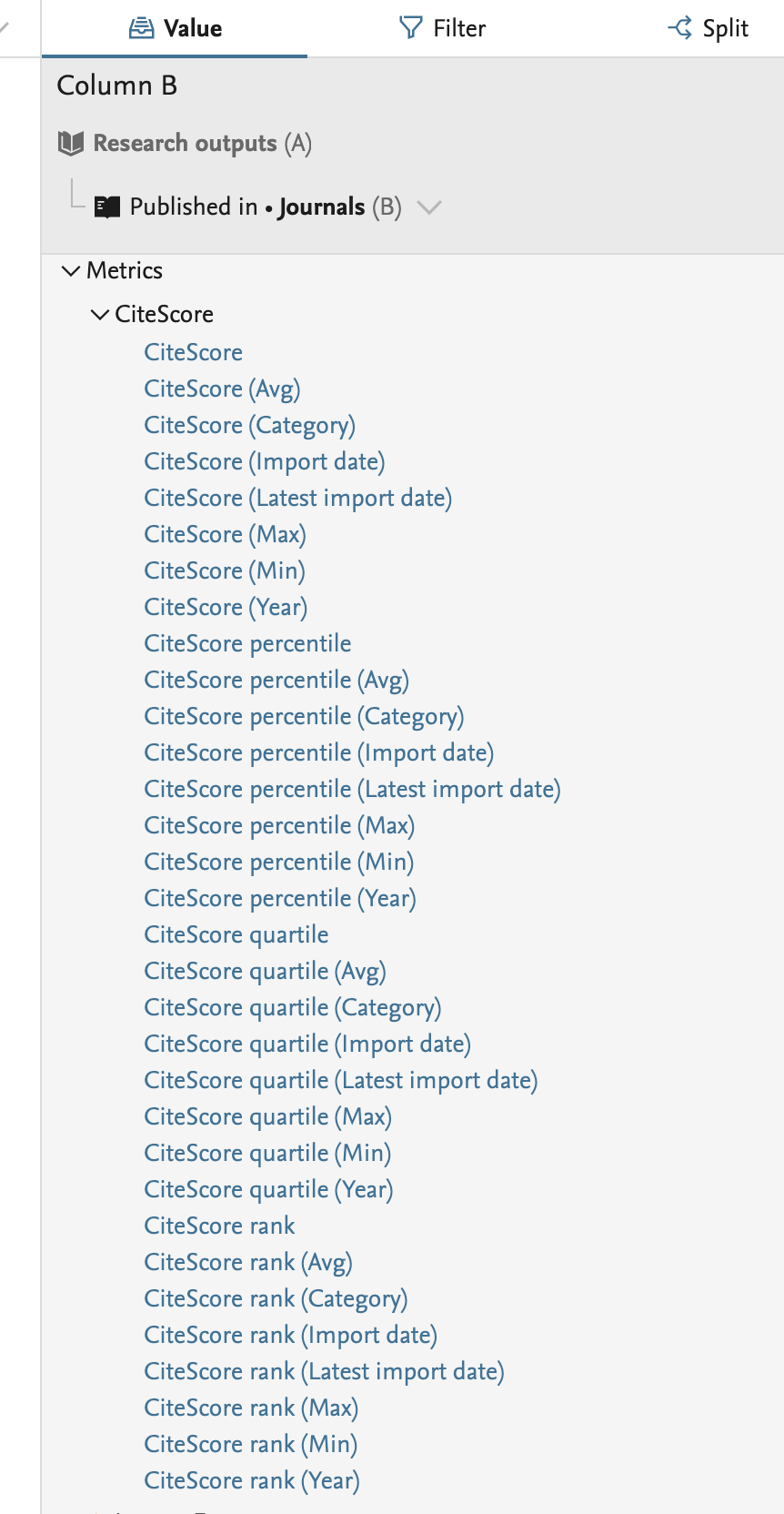 |
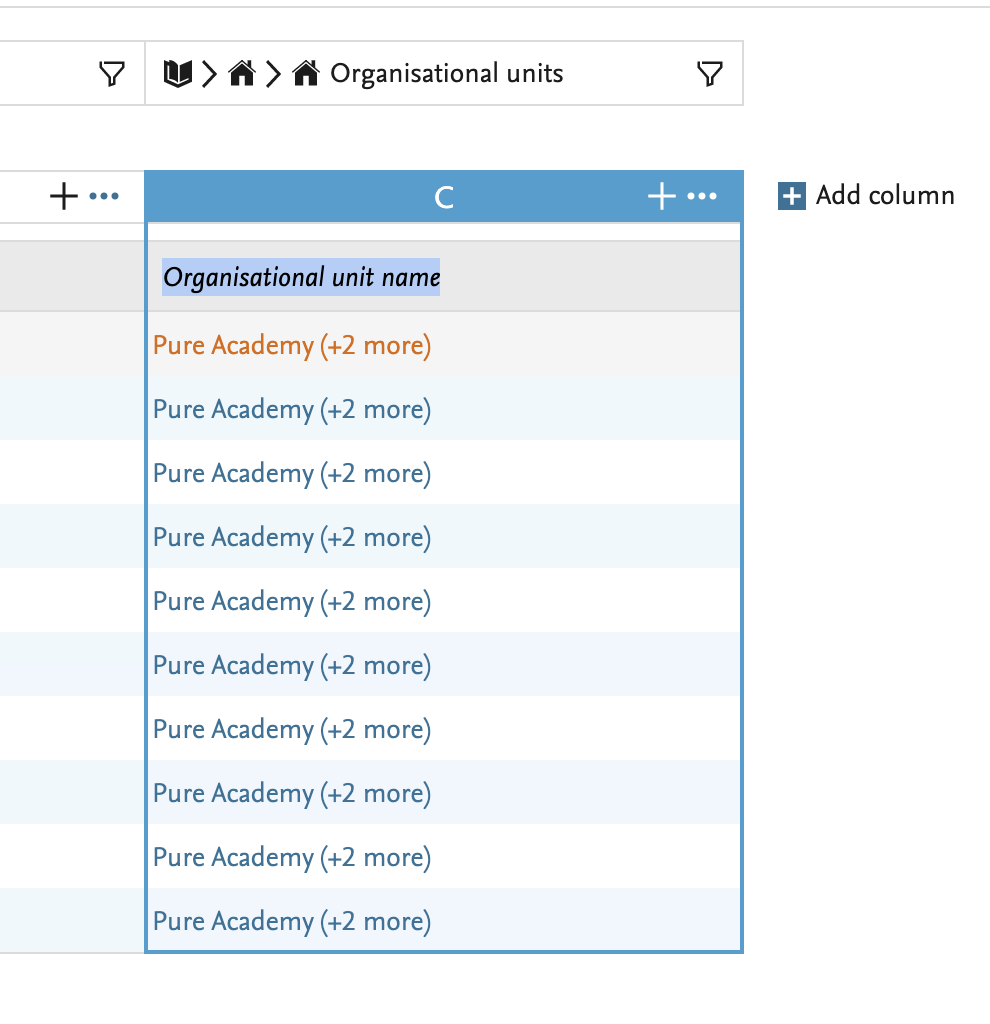
8.3. Wide preview: show more information in a column
We are happy to introduce an additional preview option: the wide preview. In columns where multiple values are listed in a cell, you can now choose to see all the data in list view, and select one of three separators (double slash, comma, pipe).
You can easily switch between the Default preview and the Wide preview (see below). The currently applied preview mode will be used when exporting data as Excel or CSV.
Click here for more details...
 |
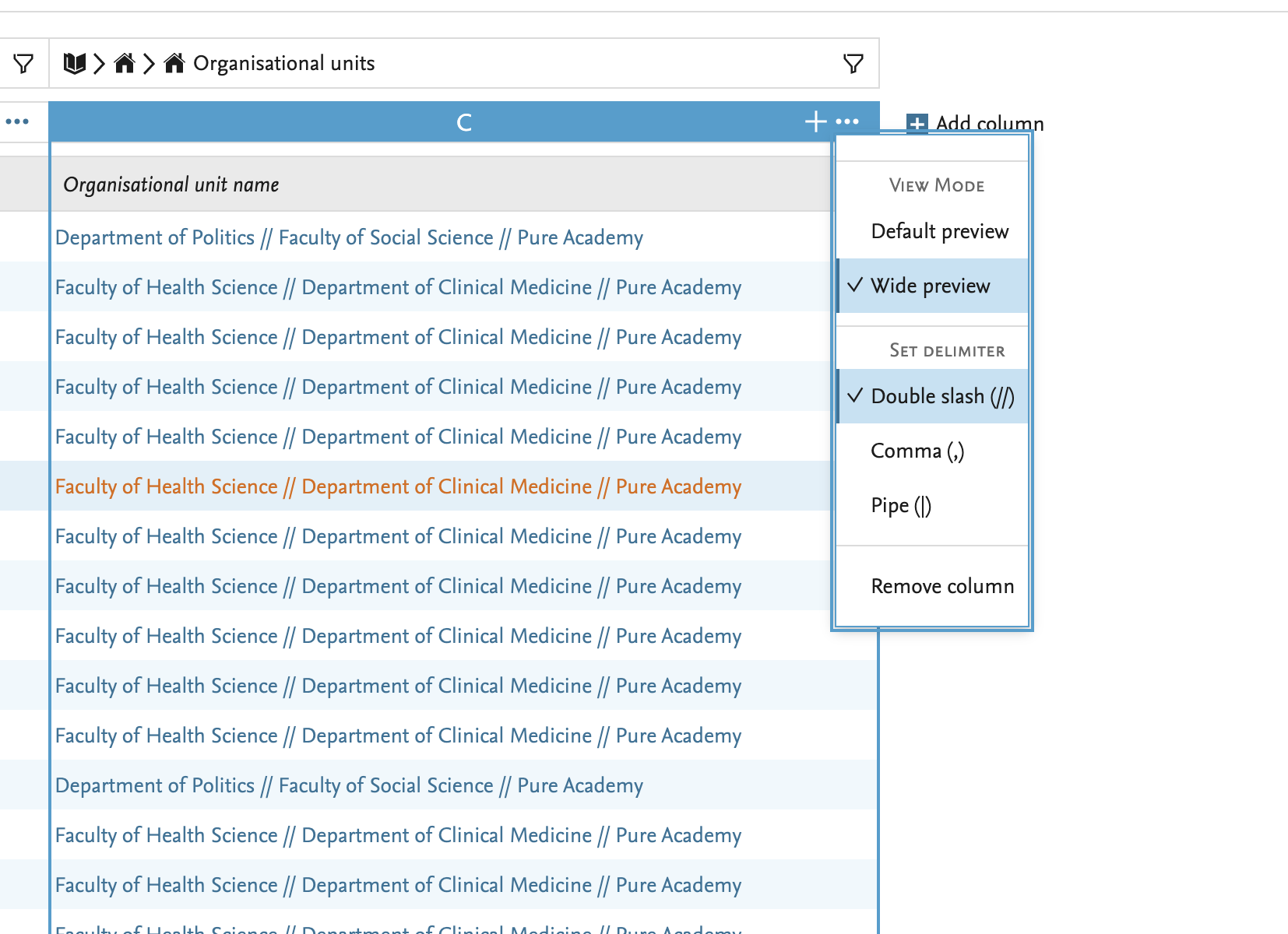 |
In 5.19, wide preview is possible for up to 100 items. Cells with more than 100 records can only be viewed in the default mode (parentheses).
9. Country-specific features
9.1. UK: REF
In this release, we have made a number of updates to the REF module:
9.1.1. Upcoming changes to REF submission from Pure
We have encountered an error with the submission system, where the submission system is not able to process large request. This means that when Pure is sending an entire data set including PDF files to the submission system, it cannot process the dataset. The REF team have acknowledged that the maximum request size (100MB) was inadequate, and they will increase it but even then they will not be able to process the entire submission. As a result, we need to update the way we are sending files to the submission system: we will first send all the meta data from the submission, and then separately send the PDF files for each REF content type that should have a file attached (REF2, REF3, and REF5).
We are currently working on this change and are targeting 5.19.1 as the release where we have made these changes.
In the interim, we have updated the submission from Pure to exclude all files so that it is possible to push the metadata to the submission system to test the integration and internal process with regard to sending data to the submission system.
9.1.2. Inaccuracies in REF4 data
We have found a problem regarding some of the REF4 data which makes a re-import necessary.
The problem would result in small errors in the resulting values. In order to be able to correct this we had to alter the used types in the database. As a consequence, all REF4 data will be deleted when upgrading and it is necessary to synchronize all REF4a, REF4b and REF4c data again. Also note that the data for all the modified values will be rounded to two decimals on import.
Click here for more details...
The REF4 values that could have the small rounding errors in them are:
- REF4a Details and REF4a Summary
- 2013/14
- 2014/15
- 2015/16
- 2016/17
- 2017/18
- 2018/19
- 2019/20
- REF4b Details and REF4b Summary
- 2013/14
- 2014/15
- 2015/16
- 2016/17
- 2017/18
- 2018/19
- 2019/20
- REF4c Details and REF4c Summary
- 2013/14
- 2014/15
- 2015/16
- 2016/17
- 2017/18
- 2018/19
- 2019/20
9.1.3. Update on additional fields relating to COVID
Research England has proposed a series of new fields relating to the impact that COVID-19 might have had on the REF for 2020. We have introduced the new fields (see the 5.18.3 release notes). Research England has confirmed that they will update the submission system to let us submit this information to the REF system. The update is planned for September 2020, and we will follow up with implementing the changes to Pure.
9.2. AU: Field of Research
In this release, we have made updates to the Australian and New Zealand clients relating to the updated 2020 Field of Research codes.
9.2.1. 2020 FoR codes
We have introduced the new 2020 Field of Research (FoR) codes with this release, so now you can add the new 2020 FoR codes to content in Pure. We have updated the Pure models to support the new FoR codes, and you can now add them to thirteen content types. We have also updated the new Reporting Module to support the new codes, and introduced new filters to help you find content that does not yet have a 2020 FoR code.
We have also changed the name of the existing FoR code to 2008 Field of Research to help differentiate between the old and the new codes. When adding the FoR codes, it is possible to add a percentage if there is more than one, just like it was possible with the 2008 FoR codes.
Click here for more details...
The list of content types where it is possible to add the new 2020 FoR codes is as follows:
- ResearchOutput
- Application
- UPMProject
- Award
- Person
- Activity
- Journal
- Event
- Prizes*
- Press/Media*
- Impact*
- Datasets*
- Student Thesis*
*new compared to the ERA 2018 module
9.2.2. 2020 Bulk upload of FoR codes
With the introduction of the new Field of Research codes, we have also created an bulk upload option to populate the content in Pure with these new codes. Read more about the job and how to create the bulk import file in the Field of Research discipline assignment bulk upload wiki, where you can also find the template file to be used for the bulk upload.
10. Additional features of this release
10.1. Pendo
We are excited to announce the introduction of Pendo.io to Pure. Pendo will allow us to provide additional help and gather user feedback without having to wait for a new release. With Pendo, we will be able to create new, more dynamic feature guides and tooltips to improve the product and new feature onboarding experience. We will gradually start using Pendo with the new Reporting Module, with the aim to use Pendo throughout Pure. The guides and tooltips will be used as an addition to the standard help texts in Pure.
Click here for more details...
Tracking users
Pendo tracks user behaviour in Pure in order to keep record of the guides and tooltips they have seen. The information we send about the users is limited to a unique ID (a hashed version of the Pure ID), user roles, their browser and institution (if available). This information is used only to provide the most relevant guides and tooltips.
If an institution disables tracking in their Pure installation, or if a user has disables tracking in their browser, we only send browser type information to Pendo. This means that Pendo will still work, but the users will be anonymous and as a result might be presented with fewer guides and tooltips.
Disabling plugins
Some browser plugins that block JavaScript may disable the Pendo integration. If you want the full benefit of additional user help we provide with Pendo, configure these plugins to allow JavaScript from Pendo.
Published at December 04, 2023