
How Can We Help?
Duplicate Research Outputs - "Duplicate Titles" vs "Possible Duplicates"Duplicate Research Outputs - "Duplicate Titles" vs "Possible Duplicates"
What
Within Pure, you might see a difference in the results of "Duplicate title" found in the submenu of Editor > Research outputs - and "View possible duplicates" in each Research outputs record. The background is that Pure has a few features to handle Research output duplicates and separate strategies drive them.
How
You can find Research output duplicates in three ways, below:
-
Duplicate titles: via Editor > Research outputs > Duplicate titles
The Duplicate title overview searches and finds elements where the titles are mostly identical - the rule is more than 80% match in the titles. Those highly likely duplicates are listed here.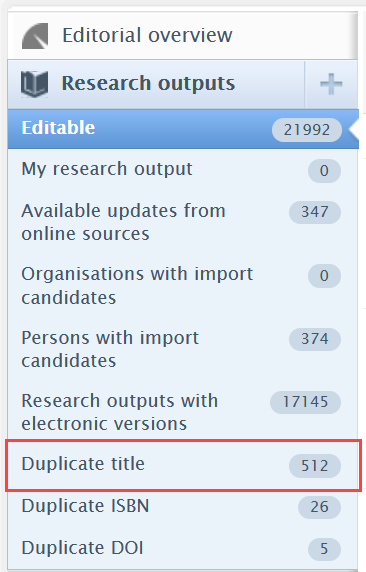
-
Manage duplicates tab: found on Research outputs record/editor
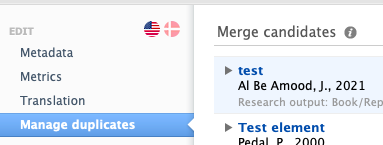
This option combines all the different "Duplicate" menus (duplicate title, duplicate ISBN, and duplicate DOI) used from the editor workspace mentioned above, and displays them into one single view for the specific record. This option performs a look-up to identify the records that have the same Title, ISBN, and DOI.
This is why the records shown as duplicates on the "Duplicate" menus might be different from the records listed in the "Manage duplicate" option. While the first one uses either the identifiers to find duplicates (e.g. ISBN and DOI) or titles that are 'somewhat' identical, this "Manage duplicates" option combines the 3 values. Thus, this uses a more complex look-up.Note: While the Data Quality tab does not support research output content type as of 5.25.0, this is the background for that we have introduced the Data Quality tab. It performs a more complex "title/name" check in advance, so as more and more content types get introduced in the Data Quality Tab, the fewer issues we should see with it being different from the results shown in 'Manage duplicates'.
-
"View possible duplicates" function: found on Research outputs record/editor
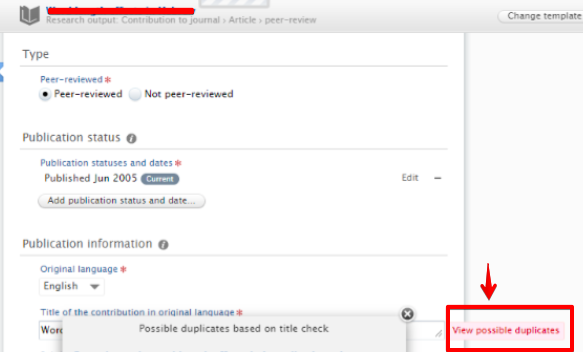
This feature makes a Lucene search based on the title. This does not really correlate with these "duplicate titles in the overview".
This feature is just extra help for users when a new research output is submitted, so they can discover if the content already exists in Pure. Still, because it is based on a Lucene search, it is not always so precise - that is why it's called possible duplicates.
If you'd like to know further, you'll see more details about automated deduplication Automated Deduplication Jobs. We'll continue improving how Pure finds potential duplicates and provide easier ways to mark entries as distinct.
Published at May 23, 2024